当前位置:网站首页>13.模型的保存和載入
13.模型的保存和載入
2022-07-08 00:54:00 【booze-J】
我們以保存3.MNIST數據集分類中訓練的模型為例,來演示模型的保存與載入。
第一種模型保存和載入方式
1.保存方式
保存模型只需要在模型訓練完之後添加上
# 保存模型 可以同時保存模型的結構和參數
model.save("model.h5") # HDF5文件,pip install h5py
這種保存方式可以同時保存模型的結構和參數。
2.載入方式
載入模型之前需要先導入load_model方法
from keras.models import load_model
然後載入的代碼就是簡單一句:
# 載入模型
model = load_model("../model.h5")
這種載入方法可以同時載入模型的結構和參數。
第二種模型保存和載入方式
1.保存方式
模型參數和模型結構分開來保存:
# 保存參數
model.save_weights("my_model_weights.h5")
# 保存網絡結構
json_string = model.to_json()
2.載入方式
在載入模型結構之前,需要先導入model_from_json()方法
from keras.models import model_from_json
分別載入網絡參數和網絡結構:
# 載入參數
model.load_weights("my_model_weights.h5")
# 載入模型結構
model = model_from_json(json_string)
模型再訓練
代碼運行平臺為jupyter-notebook,文章中的代碼塊,也是按照jupyter-notebook中的劃分順序進行書寫的,運行文章代碼,直接分單元粘入到jupyter-notebook即可。
其實模型載入之後是可以進行再訓練的。
1.導入第三方庫
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense
from keras.models import load_model
2.加載數據及數據預處理
# 載入數據
(x_train,y_train),(x_test,y_test) = mnist.load_data()
# (60000, 28, 28)
print("x_shape:\n",x_train.shape)
# (60000,) 還未進行one-hot編碼 需要後面自己操作
print("y_shape:\n",y_train.shape)
# (60000, 28, 28) -> (60000,784) reshape()中參數填入-1的話可以自動計算出參數結果 除以255.0是為了歸一化
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
# 換one hot格式
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
3.模型再訓練
# 載入模型
model = load_model("../model.h5")
# 評估模型
loss,accuracy = model.evaluate(x_test,y_test)
print("\ntest loss",loss)
print("accuracy:",accuracy)
運行結果:
對比首次保存的模型: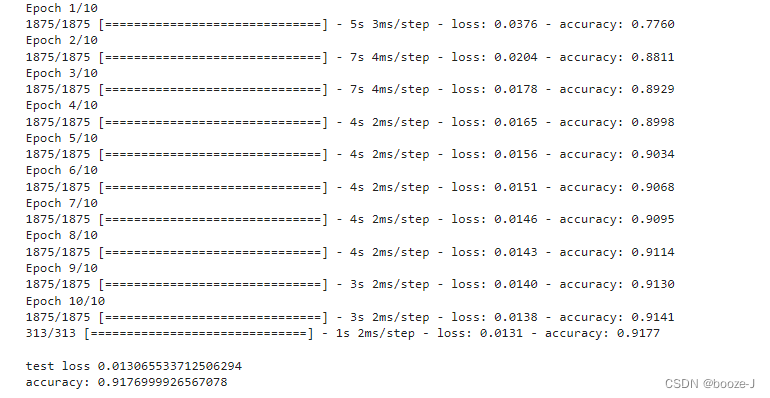
可以發現再訓練模型在測試集上的准確率有所提高。
边栏推荐
- Semantic segmentation model base segmentation_ models_ Detailed introduction to pytorch
- 大二级分类产品页权重低,不收录怎么办?
- 【obs】Impossible to find entrance point CreateDirect3D11DeviceFromDXGIDevice
- After going to ByteDance, I learned that there are so many test engineers with an annual salary of 40W?
- 玩轉Sonar
- DNS 系列(一):为什么更新了 DNS 记录不生效?
- Installation and configuration of sublime Text3
- Summary of weidongshan phase II course content
- 应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设
- 新库上线 | 中国记者信息数据
猜你喜欢
Installation and configuration of sublime Text3
从服务器到云托管,到底经历了什么?

51与蓝牙模块通讯,51驱动蓝牙APP点灯
玩转Sonar
Redis, do you understand the list
ReentrantLock 公平锁源码 第0篇
深潜Kotlin协程(二十二):Flow的处理
My best game based on wechat applet development
letcode43:字符串相乘

They gathered at the 2022 ecug con just for "China's technological power"
随机推荐
ABAP ALV LVC模板
从服务器到云托管,到底经历了什么?
Where is the big data open source project, one-stop fully automated full life cycle operation and maintenance steward Chengying (background)?
C # generics and performance comparison
Cause analysis and solution of too laggy page of [test interview questions]
ReentrantLock 公平锁源码 第0篇
华为交换机S5735S-L24T4S-QA2无法telnet远程访问
Password recovery vulnerability of foreign public testing
Experience of autumn recruitment in 22 years
Cancel the down arrow of the default style of select and set the default word of select
他们齐聚 2022 ECUG Con,只为「中国技术力量」
国外众测之密码找回漏洞
取消select的默认样式的向下箭头和设置select默认字样
丸子官网小程序配置教程来了(附详细步骤)
Which securities company has a low, safe and reliable account opening commission
【GO记录】从零开始GO语言——用GO语言做一个示波器(一)GO语言基础
SDNU_ACM_ICPC_2022_Summer_Practice(1~2)
Hotel
A network composed of three convolution layers completes the image classification task of cifar10 data set
Deep dive kotlin collaboration (the end of 23): sharedflow and stateflow