当前位置:网站首页>深潜Kotlin协程(二十二):Flow的处理
深潜Kotlin协程(二十二):Flow的处理
2022-07-07 22:17:00 【RikkaTheWorld】
系列电子书:传送门
我们将 Flow 描述为一个管道,值在上面流动,流动时,这些值可以以不同的方式进行更改:删除、相乘、转换或合并。这些在 Flow 被创建到终端操作之间的所有操作称为Flow的处理。在本章中,我们将学习用于此目的的函数。
这里提供的函数可能会让你想起用于处理集合的函数,这并不是巧合,因为都代表了相同的概念。不同的是 flow 上的元素可以按时传递。
map
我们需要学习的第一个重要函数就是 map。它根据转换函数对流动的每个元素进行变换。假如你有一个整型数据流,你的 map 操作是计算这些数字的平方,那么最终流上的数据会是这些数字的平方。
suspend fun main() {
flowOf(1, 2, 3) // [1, 2, 3]
.map {
it * it } // [1, 4, 9]
.collect {
print(it) } // 149
}
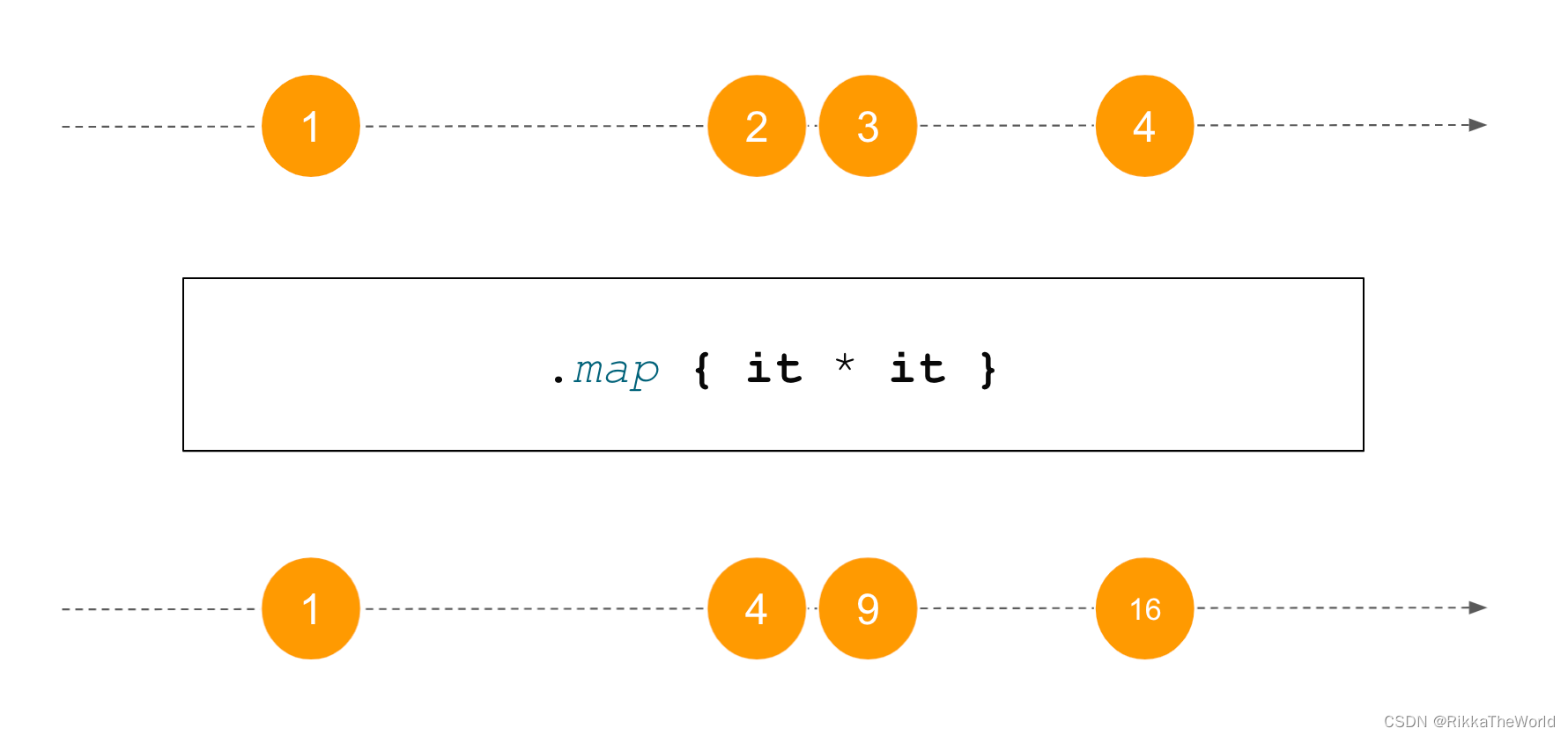
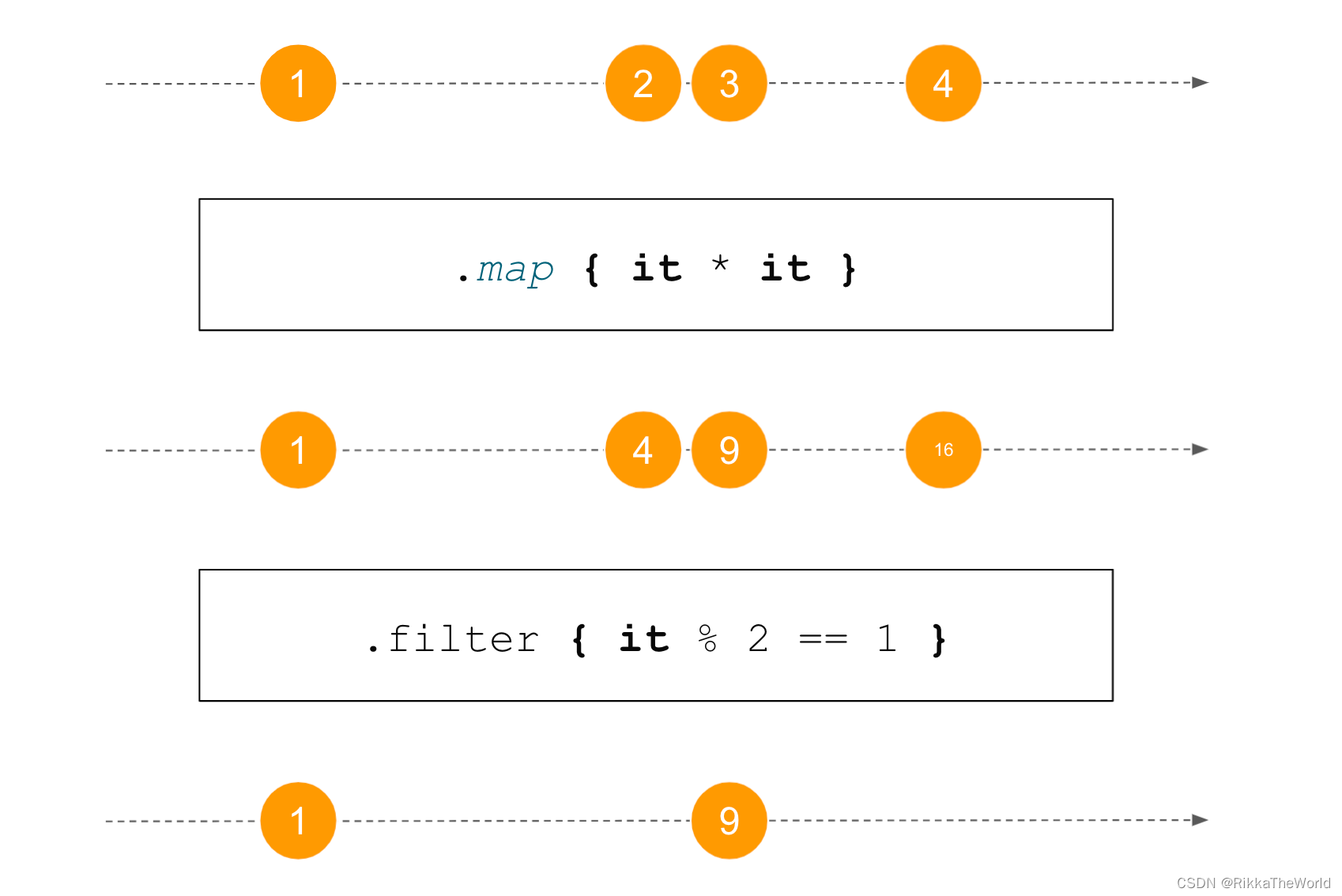
之后,我将使用上面所示的图片来可视化 flow 处理函数如何随时间改变元素。水平线表示时间,这条线上的元素是某个时间点该 flow 中被发射的元素。上面的一行表示操作之前的数据流,下面一行表示操作之后的数据流。这个图还可以用来表示使用多个操作,比如下图中的 map 和 filter。
大多数 Flow 处理函数,都很容易通过我们前面章节学习的工具来实现。要实现 map,我们可以使用 flow 构建器来创建一个新的 flow。然后,我们可以从前一个 flow 中收集元素,并发射出经过转换的元素。下面的实现是来自于 kotlin.coroutines 库中 map 的一个简化版本:
fun <T, R> Flow<T>.map(
transform: suspend (value: T) -> R
): Flow<R> = flow {
// 这里我们创建了一个 flow
collect {
value -> // 这里我们从接收者哪里收集数据
emit(transform(value))
}
}
map 是一个非常受欢迎的函数。它的用法有解包或者将值转换成不同的类型。
// 这里我们使用 map 来从输入事件中获得用户操作
fun actionsFlow(): Flow<UserAction> =
observeInputEvents()
.map {
toAction(it.code) }
// 这里我们把 User 转化成 UserJson
fun getAllUser(): Flow<UserJson> =
userRepository.getAllUsers()
.map {
it.toUserJson() }
filter
下一个重要的函数是 filter,它返回一个仅包含原始 flow 中匹配了给定谓词的数据的 flow。
suspend fun main() {
(1..10).asFlow() // [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
.filter {
it <= 5 } // [1, 2, 3, 4, 5]
.filter {
isEven(it) } // [2, 4]
.collect {
print(it) } // 24
}
fun isEven(num: Int): Boolean = num % 2 == 0
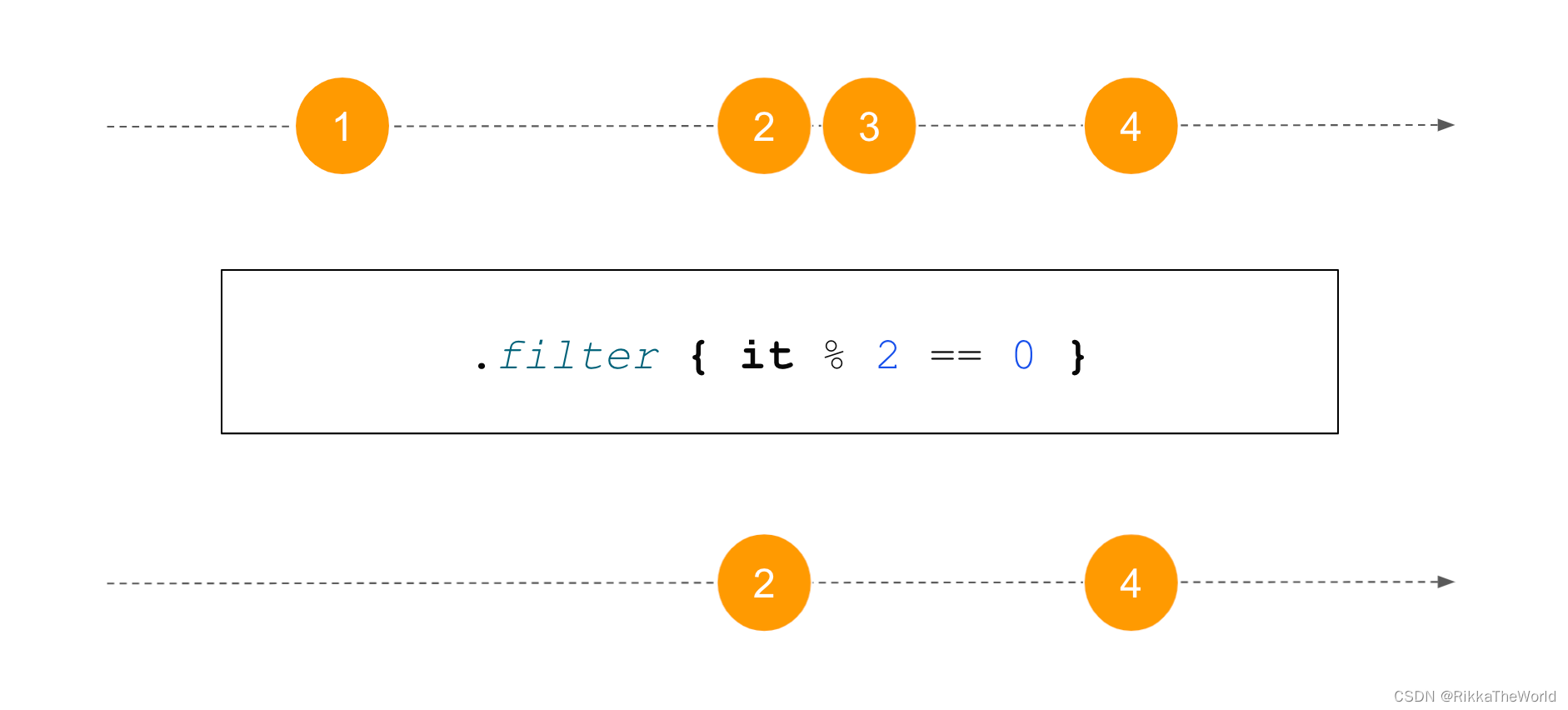
使用 flow 构建器也可以非常容易地实现此函数。我们只需要引入一个 if 语句和谓词(替代了转换)。
fun <T> Flow<T>.filter(
predicate: suspend (T) -> Boolean
): Flow<T> = flow {
// 这里我们创建一个流
collect {
value -> // 这里我们从接收者那里接收元素
if (predicate(value)) {
emit(value)
}
}
}
filter 通常用于排除我们不需要的元素。
// 这里我们使用 filter 去过滤掉我们不想要的元素
fun actionsFlow(): Flow<UserAction> =
observeInputEvents()
.filter {
isValidAction(it.code) }
.map {
toAction(it.code) }
take 和 drop
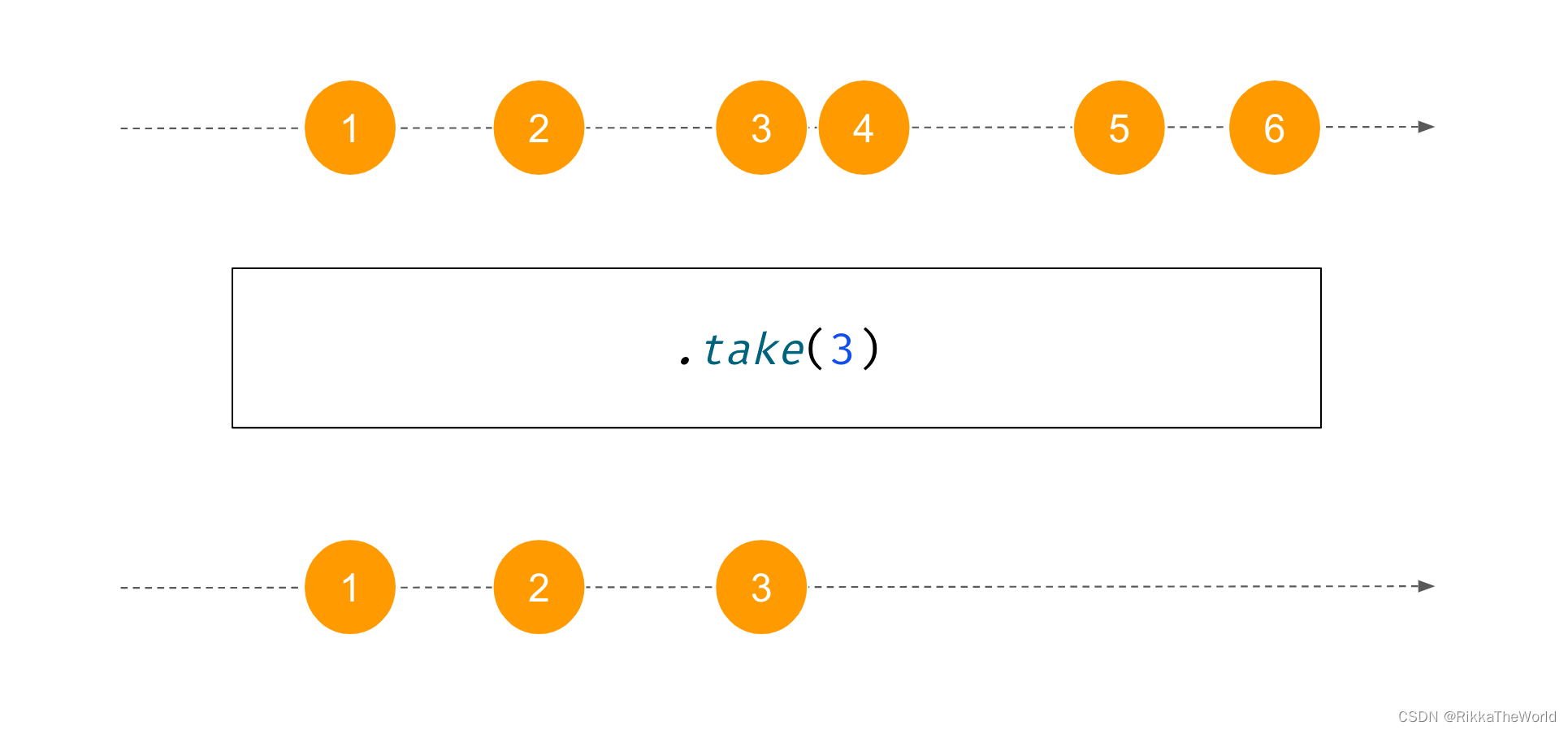
我们使用 take 来传递一定数量的元素。
suspend fun main() {
('A'..'Z').asFlow()
.take(5) // [A, B, C, D, E]
.collect {
print(it) } // ABCDE
}
我们使用 drop 来忽略特定数量的元素。
suspend fun main() {
('A'..'Z').asFlow()
.drop(20) // [U, V, W, X, Y, Z]
.collect {
print(it) } // UVWXYZ
}
它们低层是如何工作的?
我们已经看到了相当多的 flow 处理和生命周期函数。它们的实现非常简单,没有什么神奇的东西在里面。大多数这样的函数都可以用 flow 构建器,并用 collect 来实现。下面是一个简单的流处理示例,包括简化的 map 和 flowOf 实现:
suspend fun main() {
flowOf('a', 'b')
.map {
it.uppercase() }
.collect {
print(it) } // AB
}
fun <T, R> Flow<T>.map(
transform: suspend (value: T) -> R
): Flow<R> = flow {
collect {
value ->
emit(transform(value))
}
}
fun <T> flowOf(vararg elements: T): Flow<T> = flow {
for (element in elements) {
emit(element)
}
}
如果内联 flowOf 和 map 函数,你将得到下面代码(我在 lambdas 上添加了标签和带有数字的注释)。
suspend fun main() {
flow [email protected]{
// 1
flow [email protected]{
// 2
for (element in arrayOf('a', 'b')) {
// 3
this@flowOf.emit(element) // 4
}
}.collect {
value -> // 5
this@map.emit(value.uppercase()) // 6
}
}.collect {
// 7
print(it) // 8
}
}
让我们一步一步的分析。
- 我们在注释1处启动一个 flow,并在注释7处调用了其
collect函数 - 当我们启动收集时,我们会调用
@map(注释1)的 lambda 表达式,它在注释2处启动了另一个 flow 构建器,并在注释5处去收集。 - 所以此时,我们我们启动
@flowOn(注释2处)的 lambda 表达式,它迭代了包含 ‘a’ 和 ‘b’ 的数组。 - 第一个值 ‘a’ 在注释4被发射,发射到了注释5处,该 lambda 表达式将值转换成 ‘A’ ,并从 @map 的
collect函数中发射出去,从而调用到 7 处的 lambda 表达式, 该值被打印了出来。 - 注释7结束了,会在注释6处恢复,因为注释6没有别的内容,所以它也结束了,所以我们在注释4处恢复了
@flowOf。 - 我们继续迭代并在注释4处发射 ‘b’ ,因此我们调用注释5处的 lambda 函数,将值 转成成 ‘B’,并从
@map的collect函数中发射出去。该值就会在注释7处被收集,然后在注释8处被打印。 - 接着注释7结束,恢复到注释6处,也完成了。所以我们在注释4处恢复
@flowOf。它也完成了。由于没有更多的内容,我们到达了@map的结尾,这样,我们在注释7恢复,并到达了 main 函数的结尾。
在大多数 flow 处理和生命周期函数中也会是相同的情况,所以理解这一点可以让我们更好的理解 flow 是如何运作的。
merge, zip 和 combine
接下来学习将两个流合并成一个流。有几种方法可以做到这一点。最简单的方法是将两个流中的元素合并成一个。无论 flow 的元素源自哪里,都不用做任何修改,为此,我们可以使用 merge 函数。
suspend fun main() {
val ints: Flow<Int> = flowOf(1, 2, 3)
val doubles: Flow<Double> = flowOf(0.1, 0.2, 0.3)
val together: Flow<Number> = merge(ints, doubles)
print(together.toList())
// [1, 0.1, 0.2, 0.3, 2, 3]
// 或者 [1, 0.1, 0.2, 0.3, 2, 3]
// 或者 [0.1, 1, 2, 3, 0.2, 0.3]
// 或者其他的组合
}
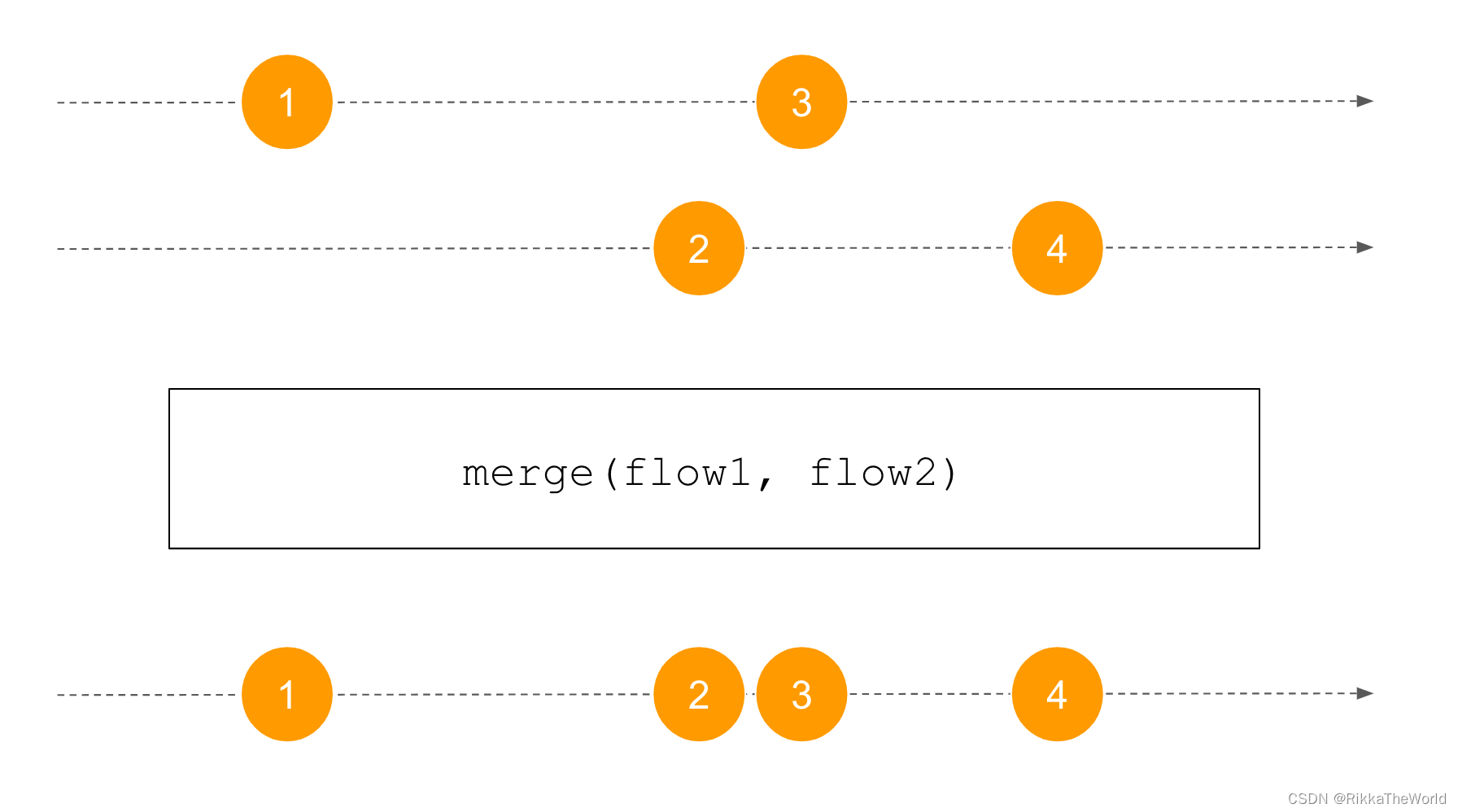
重要的点是,当我们使用 merge 时,一个流的元素不需要等待另一个流上的元素。例如,在下面的例子中,来自第一个 flow 的元素被延迟,但这并不会影响来自第二个 flow 的元素。
suspend fun main() {
val ints: Flow<Int> = flowOf(1, 2, 3)
.onEach {
delay(1000) }
val doubles: Flow<Double> = flowOf(0.1, 0.2, 0.3)
val together: Flow<Number> = merge(ints, doubles)
together.collect {
println(it) }
}
// 0.1
// 0.2
// 0.3
// (1 sec)
// 1
// (1 sec)
// 2
// (1 sec)
// 3
当有多个事件源都有相同的操作时,我们可以使用 merge。
fun listenForMessages() {
merge(userSentMessages, messagesNotifications)
.onEach {
displayMessage(it) }
.launchIn(scope)
}
下一个函数是 zip,它对两个 flow 进行配对。我们需要定义一个函数来决定元素是如何配对的(配对后结果将在发射到新的 flow 中)。每个元素只能是一对一的配对,所以它需要等待和它配对的那一个。没有配对的元素将会丢失,因此,当一个 flow 的压缩完成时,新的 flow 也将完成(其它 flow 亦是如此)。
suspend fun main() {
val flow1 = flowOf("A", "B", "C")
.onEach {
delay(400) }
val flow2 = flowOf(1, 2, 3, 4)
.onEach {
delay(1000) }
flow1.zip(flow2) {
f1, f2 -> "${
f1}_${
f2}" }
.collect {
println(it) }
}
// (1 sec)
// A_1
// (1 sec)
// B_2
// (1 sec)
// C_3
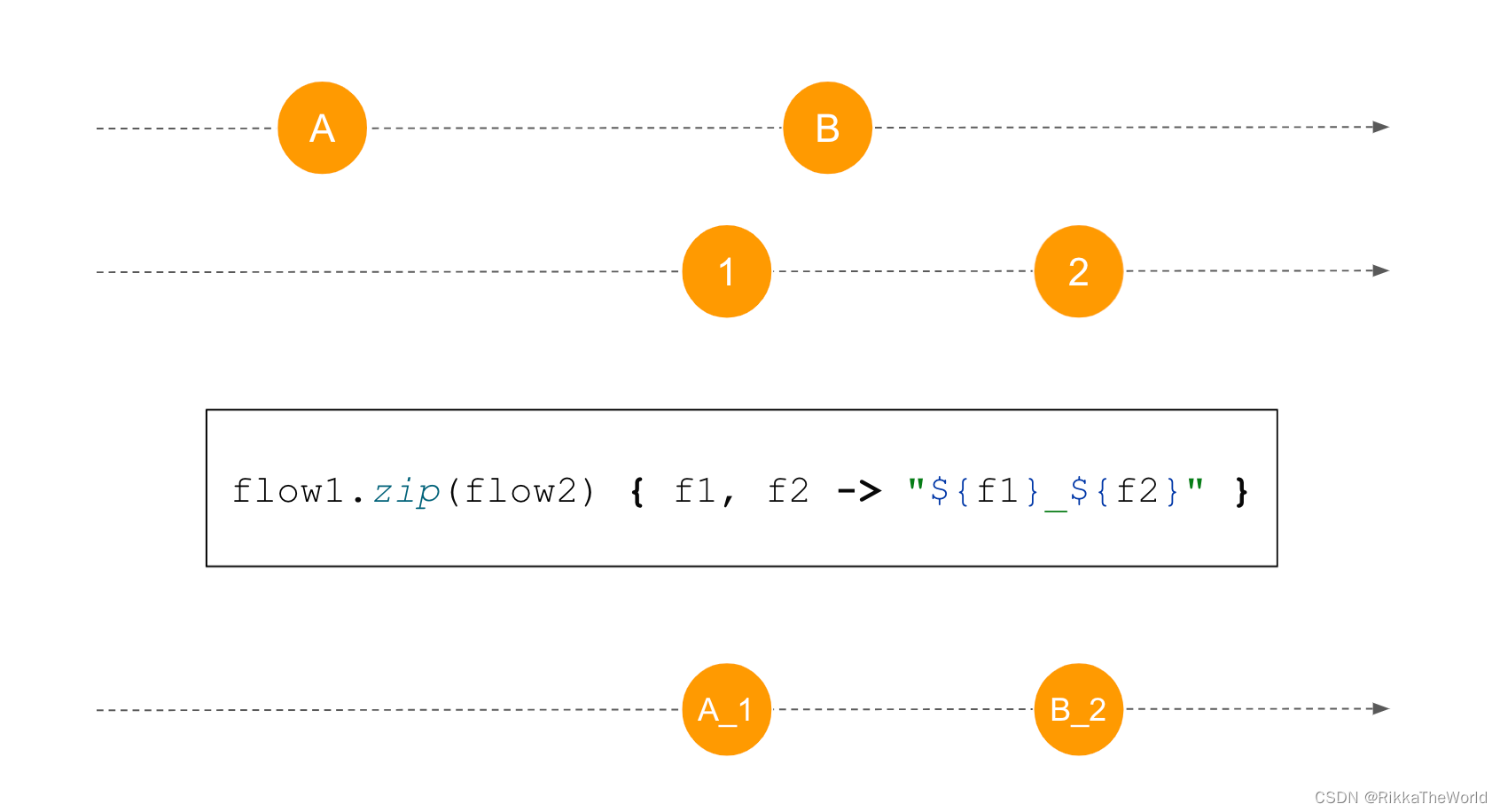
zip 函数让我想起了波兰的传统舞蹈 —— 波罗涅滋舞。这种舞蹈的一个特点是,一排成对的人从中间分开,然后他们再次相遇后会重新组合。

组合两个 flow 的最后一个重要函数是 combine。就像 zip 一样,它也是从元素中形成对,快的 flow 生成的元素必须等待较慢的那个 flow 生成的元素来产生第一对。然而,与波兰舞的相似之处到此为止。使用 combine 时,每个新元素都会替换它的前一个元素。如果第一对已经形成,一个新的元素将和来自另一个 flow 的前一个元素一起产生新的对。
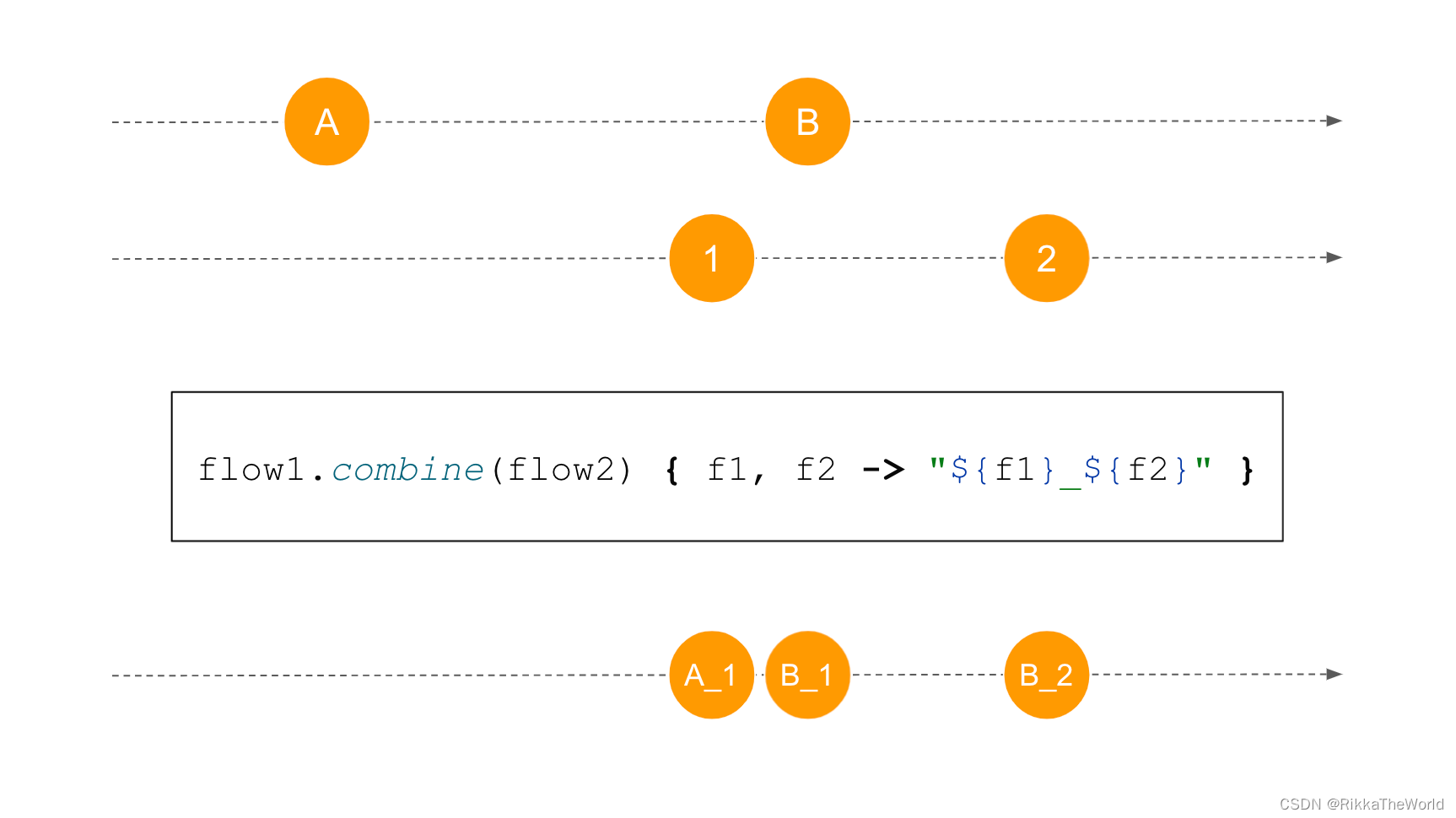
注意, zip 需要配对,所以当第一个 flow 关闭时,zip 就关闭了。 而 combine 没有这样的限制,直到两个 flow 都关闭前,它将一直发射数据。
suspend fun main() {
val flow1 = flowOf("A", "B", "C")
.onEach {
delay(400) }
val flow2 = flowOf(1, 2, 3, 4)
.onEach {
delay(1000) }
flow1.combine(flow2) {
f1, f2 -> "${
f1}_${
f2}" }
.collect {
println(it) }
}
// (1 sec)
// B_1
// (0.2 sec)
// C_1
// (0.8 sec)
// C_2
// (1 sec)
// C_3
// (1 sec)
// C_4
当我们需要观察两个来源的变化时,通常会使用 combine。我们还可以向每个组合的 flow 添加初始值(以获得初始对)。
userUpdateFlow.onStart {
emit(currentUser) }
一个典型的场景是当一个视图有两个数据源。例如,当一个通知同时依赖用户的当前状态和一些通知时,我们可以同时观察它们并结合它们的更改来更新视图。
userStateFlow
.combine(notificationsFlow) {
userState, notifications ->
updateNotificationBadge(userState, notifications)
}
.collect()
fold 和 scan
如果你使用过集合处理函数,你可能会了解 fold(折叠)。通过对每个元素(从初始值开始)应用将两个值合并为一个值的操作,将集合中的所有值合并成一个。
例如,如果初始值是0,操作是加法,那么结果是所有数字的和:我们首先取初始值0,然后,我们把第一个元素1加上去;在结果1上,我们加上第二个数字2;对结果3,我们加上第三个数字3;对结果6,我们加上最后一个数字4,这个操作的结果是10,也就是 fold 返回的结果。
fun main() {
val list = listOf(1, 2, 3, 4)
val res = list.fold(0) {
acc, i -> acc + i }
println(res) // 10
val res2 = list.fold(1) {
acc, i -> acc * i }
println(res2) // 24
}
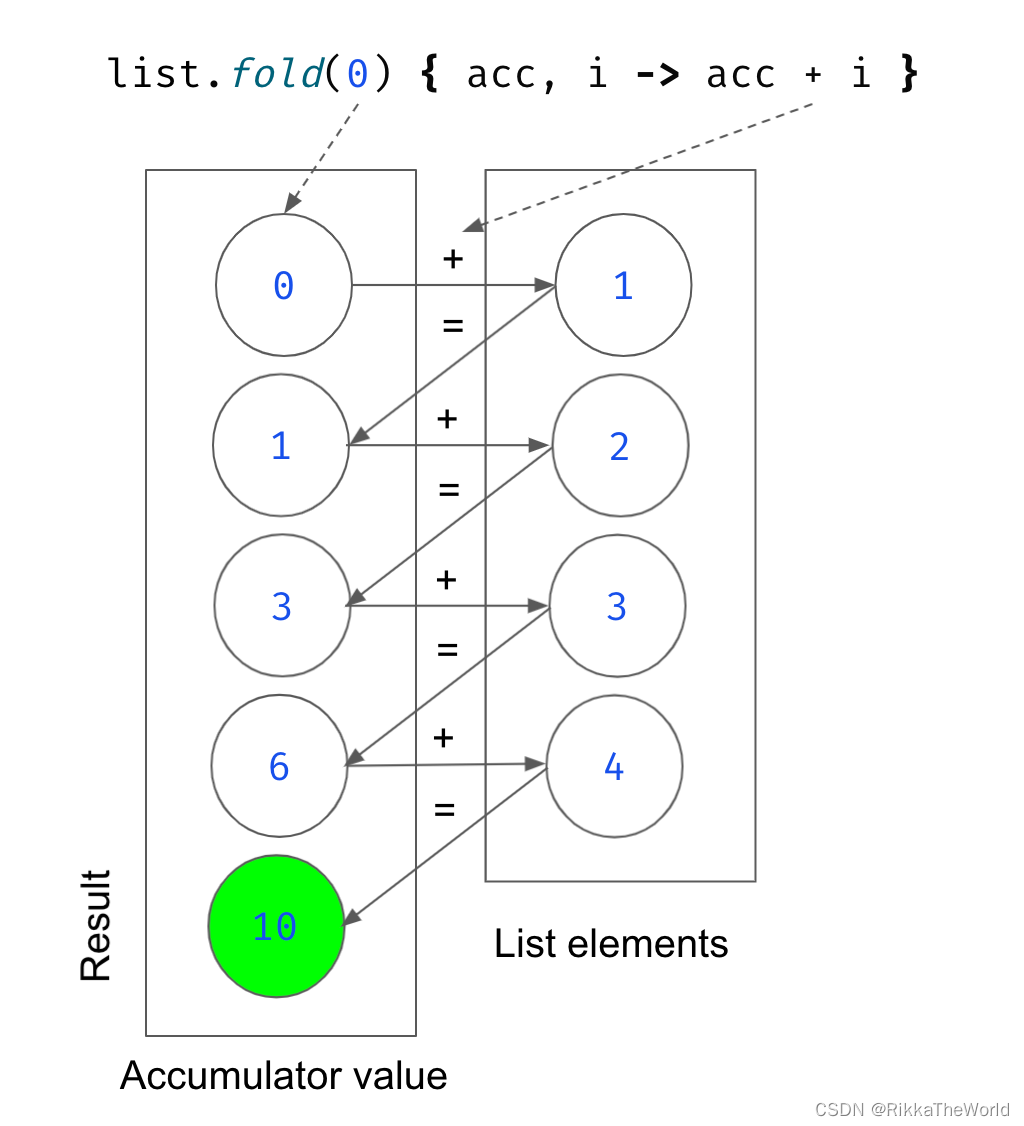
fold 是一个终端操作,它也可以用于flow,但是它会挂起直到 flow 完成(就像 collect)一样。
suspend fun main() {
val list = flowOf(1, 2, 3, 4)
.onEach {
delay(1000) }
val res = list.fold(0) {
acc, i -> acc + i }
println(res)
}
// (4 sec)
// 10
有一种替代 fold 函数是 scan。它是一个能产生所有中间值的中间操作:
fun main() {
val list = listOf(1, 2, 3, 4)
val res = list.scan(0) {
acc, i -> acc + i }
println(res) // [0, 1, 3, 6, 10]
}

scan 对于 flow 来说非常有用,因为它可以在接收到上一步产生的值后,立即产生一个新的值。
suspend fun main() {
flowOf(1, 2, 3, 4)
.onEach {
delay(1000) }
.scan(0) {
acc, v -> acc + v }
.collect {
println(it) }
}
// 0
// (1 sec)
// 1
// (1 sec)
// 3
// (1 sec)
// 6
// (1 sec)
// 10
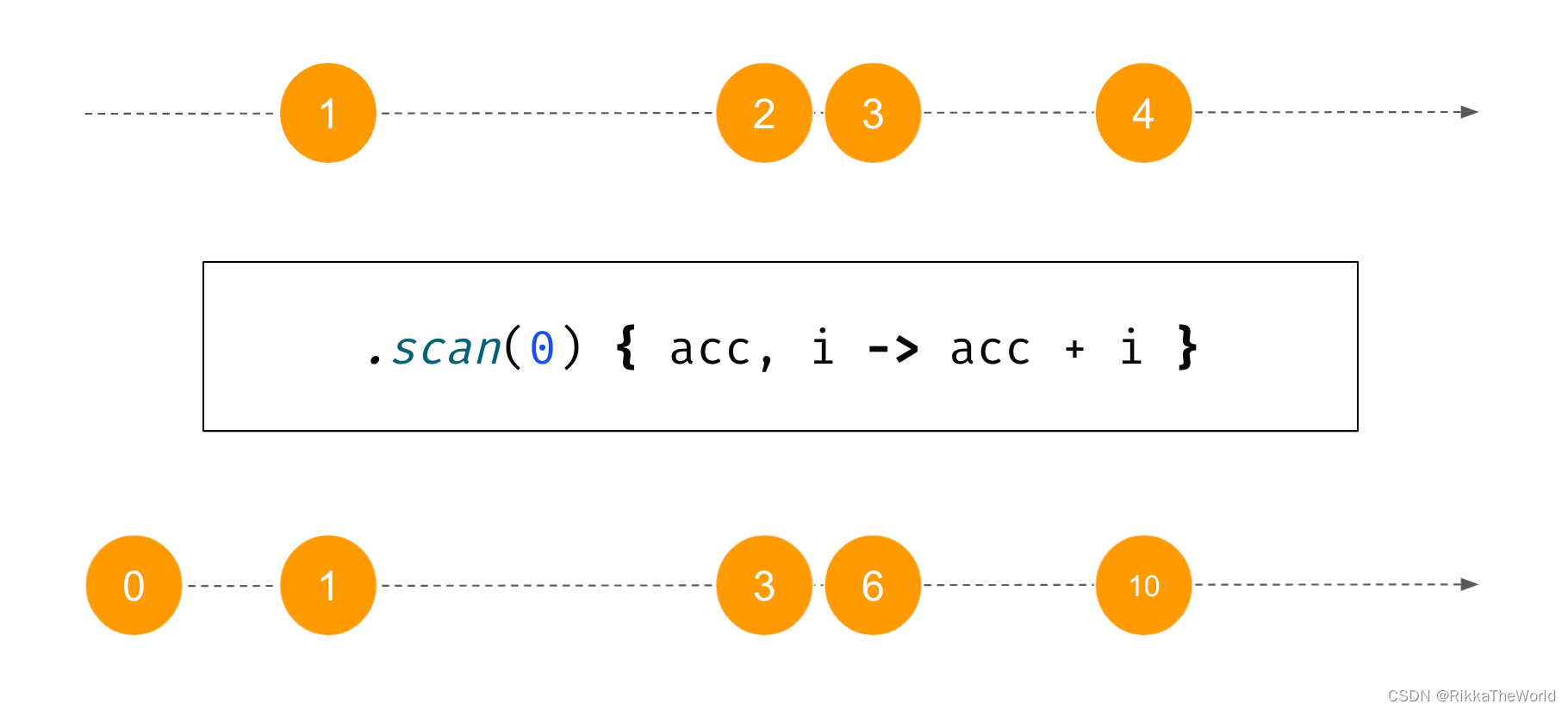
我们可以使用 flow 构建器和 collect 轻松实现 scan。我们首先发射出初始值,然后对每个新元素发出下一个值的累积结果。
fun <T, R> Flow<T>.scan(
initial: R,
operation: suspend (accumulator: R, value: T) -> R
): Flow<R> = flow {
var accumulator: R = initial
emit(accumulator)
collect {
value ->
accumulator = operation(accumulator, value)
emit(accumulator)
}
}
scan 典型的使用场景是当我们需要更新或更改 flow ,或我们需要一个对象,这个对象是这些改变的结果时。
val userStateFlow: Flow<User> = userChangesFlow
.scan(user) {
acc, change -> user.withChange(change) }
val messagesListFlow: Flow<List<Message>> = messagesFlow
.scan(messages) {
acc, message -> acc + message }
flatMapConcat, flatMapMerge 和 flatMapLatest
另一个著名的集合处理函数是 flatMap,它类似于 map,但是这个转换函数最终返回一个扁平化的集合。例如,你有一个部门列表,每个部门都有一个员工列表,那么你可以使用 flatMap 来列出所有部门的所有员工。
val allEmployees: List<Employee> = departments
.flatMap {
department -> department.employees }
val listOfListsOfEmployee: List<List<Employee>> = departments
.map {
department -> department.employees }
flatMap 是如何应用到 flow 上的呢?我们可以期望可以返回一个 flow,然后该 flow 应该是扁平化的。问题是流动的元素可以随时间扩散,那么,一个流上的元素是否应该等待另外一个流上的元素,还是应该同时处理它们?因为没有一个明确的答案,所以 Flow 没有 flatMap 函数,而是有 flatMapConcat、 flatMapMerge 和 flatMapLatest。
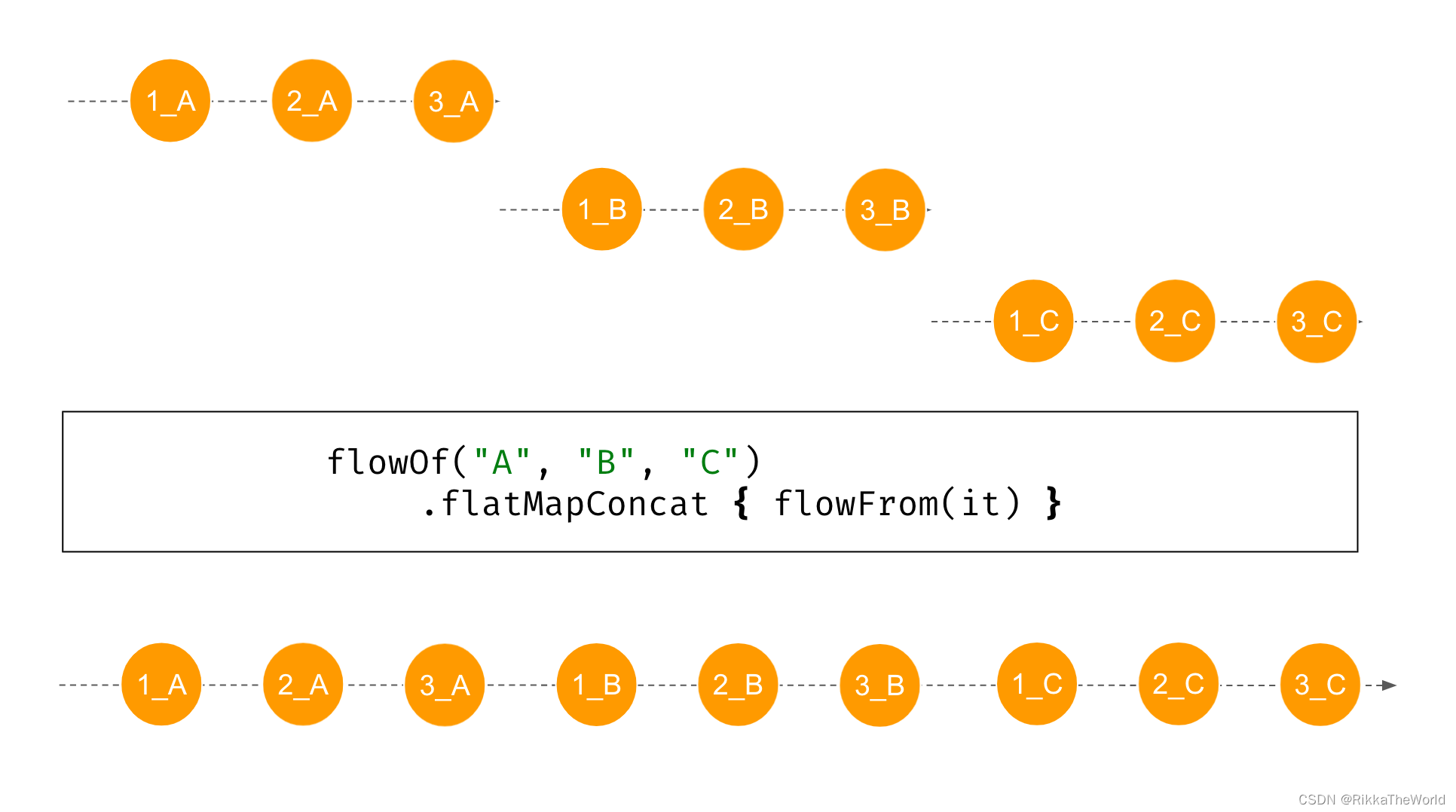
flatMapConcat 函数依次处理生成的 flow。因此,第二个 flow 可以在第一个 flow 完成时启动。在下面的例子中,我们使用字符 “A” “B” “C” 来创建一个 flow,它们产生的新 flow 会包括这些字符和数字,中间有1s的延迟。
fun flowFrom(elem: String) = flowOf(1, 2, 3)
.onEach {
delay(1000) }
.map {
"${
it}_${
elem} " }
suspend fun main() {
flowOf("A", "B", "C")
.flatMapConcat {
flowFrom(it) }
.collect {
println(it) }
}
// (1 sec)
// 1_A
// (1 sec)
// 2_A
// (1 sec)
// 3_A
// (1 sec)
// 1_B
// (1 sec)
// 2_B
// (1 sec)
// 3_B
// (1 sec)
// 1_C
// (1 sec)
// 2_C
// (1 sec)
// 3_C
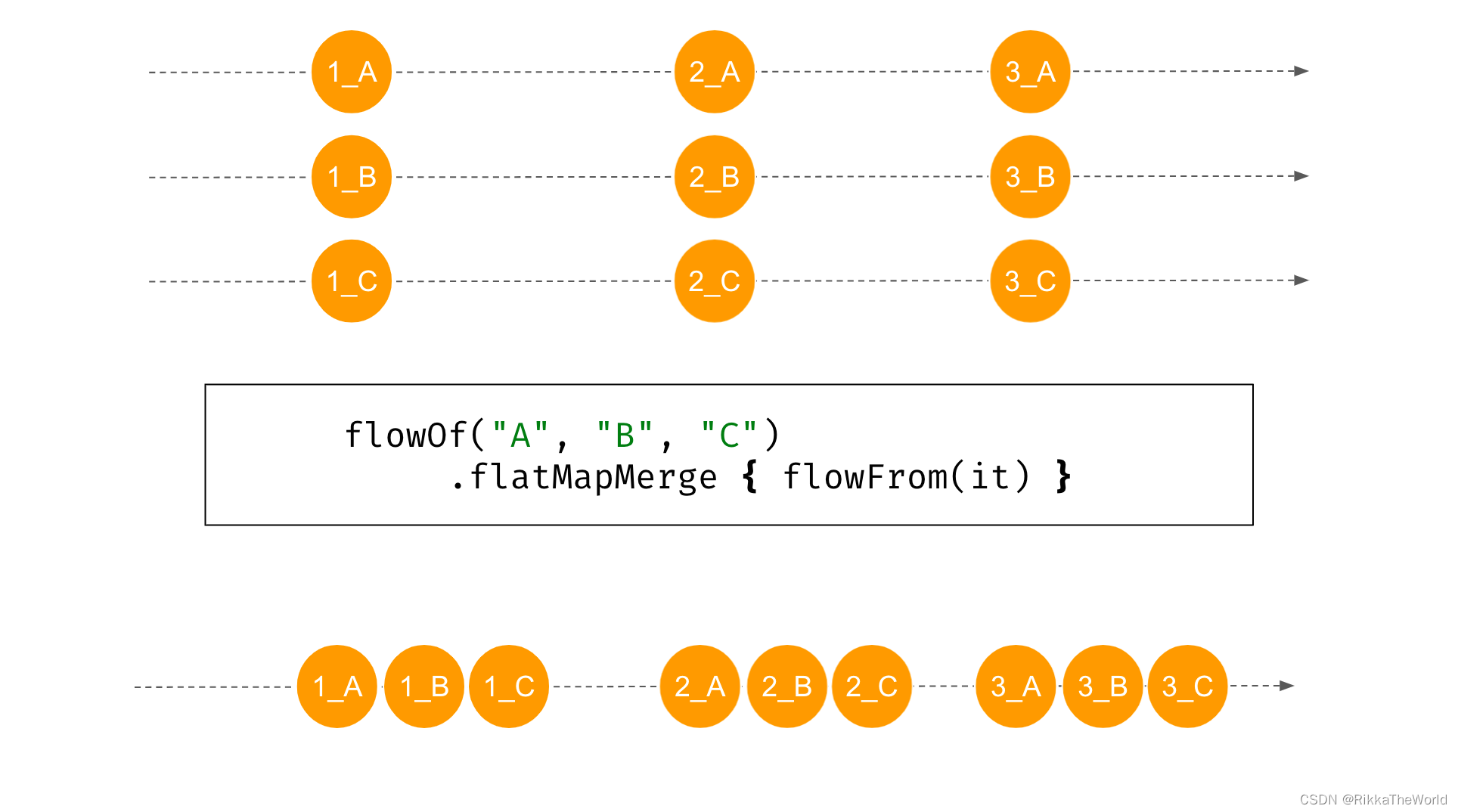
第二个函数 flatMapMerge 对我来说是最直观的,它同时处理 flow 生成的值。
fun flowFrom(elem: String) = flowOf(1, 2, 3)
.onEach {
delay(1000) }
.map {
"${
it}_${
elem} " }
suspend fun main() {
flowOf("A", "B", "C")
.flatMapMerge {
flowFrom(it) }
.collect {
println(it) }
}
// (1 sec)
// 1_A
// 1_B
// 1_C
// (1 sec)
// 2_A
// 2_B
// 2_C
// (1 sec)
// 3_A
// 3_B
// 3_C
可以使用 concurrently 参数来设置处理 flow 的并发数量。这个参数的默认值是16,但是可以在 JVM 属性的 DEFAULT_CONCURRENCY_PROPERTY_NAME 去更改它。注意这个默认限制,因为如果你在包含许多元素的 flow 上使用 flatMapMerge 时,同时只会同时处理16个元素。
suspend fun main() {
flowOf("A", "B", "C")
.flatMapMerge(concurrency = 2) {
flowFrom(it) }
.collect {
println(it) }
}
// (1 sec)
// 1_A
// 1_B
// (1 sec)
// 2_A
// 2_B
// (1 sec)
// 3_A
// 3_B
// (1 sec)
// 1_C
// (1 sec)
// 2_C
// (1 sec)
// 3_C
flatMapMerge 的典型使用场景是当我们需要为 flow 中的每个元素请求数据时。例如,我们有一个类别列表,你需要为每个类别请求报价。你已经知道可以通过 async 函数来实现这一点。而使用 flatMapMerge 流有两个优点:
- 我们可以控制并发参数,来决定我们想在同一时间取多少类别(以避免同时发送数百个请求)
- 我们可以返回
Flow并在下一个元素到达时发送它们(所以,在功能使用端,这些值可以被立即处理)
suspend fun getOffers(
categories: List<Category>
): List<Offer> = coroutineScope {
categories
.map {
async {
api.requestOffers(it) } }
.flatMap {
it.await() }
}
// 更好的解决方案
suspend fun getOffers(
categories: List<Category>
): Flow<Offer> = categories
.asFlow()
.flatMapMerge(concurrency = 20) {
suspend {
api.requestOffers(it) }.asFlow()
// 或者 flow { emit(api.requestOffers(it)) }
}
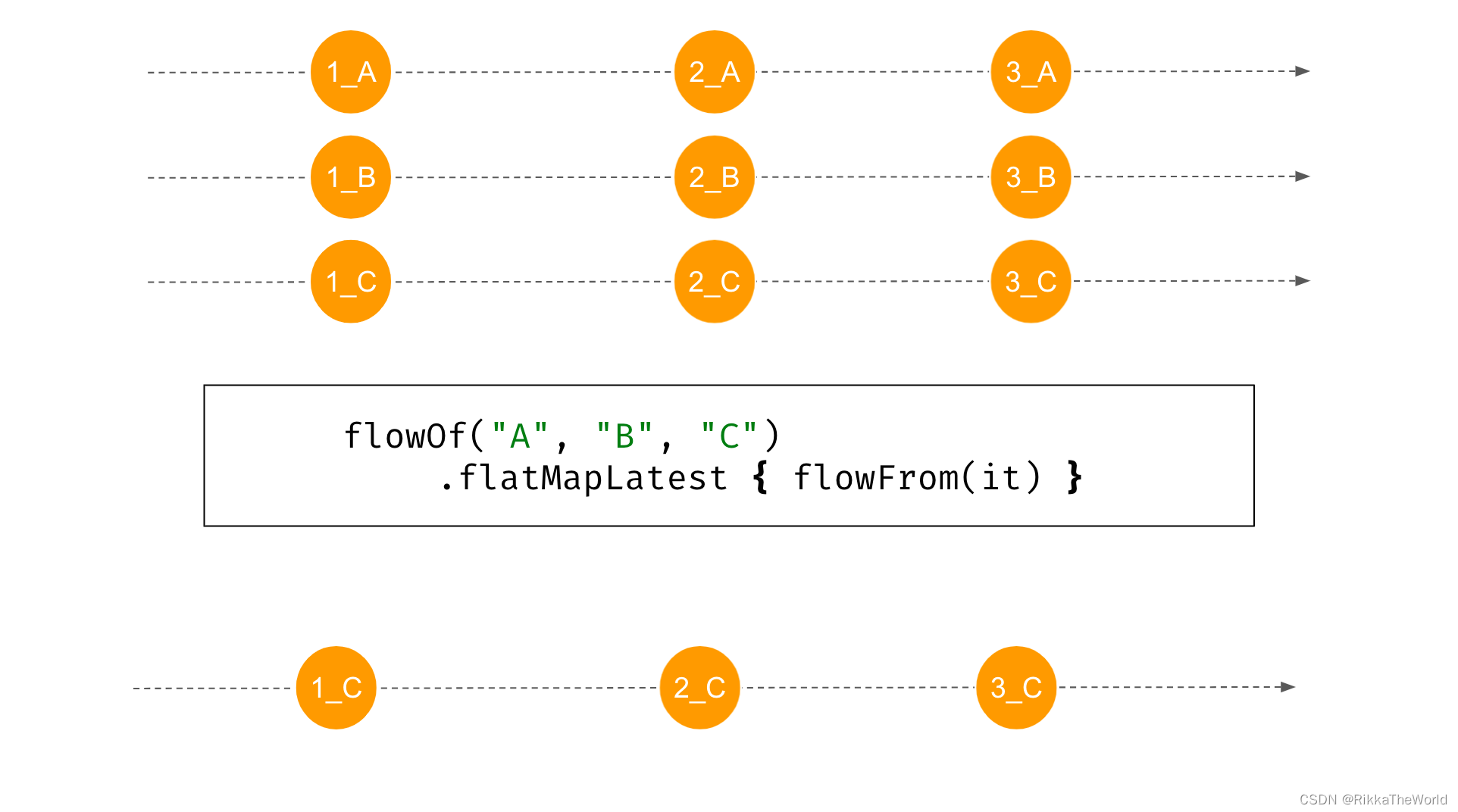
最后一个函数是 flatMapLatest。一旦新的 flow 出现,它就会遗忘之前的 flow。对于每个新的值,之前的流处理将会被遗忘。因此,如果 “A”、“B”、“C”之间没有延迟,那么你只会看到 “1_C”,“2_C”、“3_C”。
fun flowFrom(elem: String) = flowOf(1, 2, 3)
.onEach {
delay(1000) }
.map {
"${
it}_${
elem} " }
suspend fun main() {
flowOf("A", "B", "C")
.flatMapLatest {
flowFrom(it) }
.collect {
println(it) }
}
// (1 sec)
// 1_C
// (1 sec)
// 2_C
// (1 sec)
// 3_C
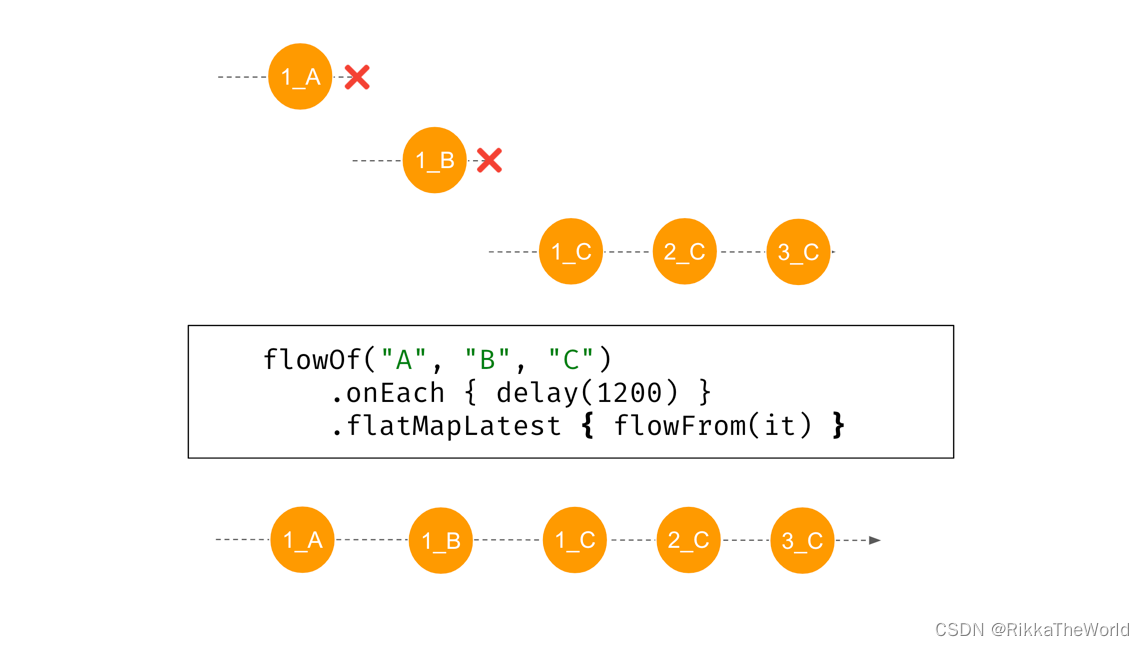
当初始 flow 中的元素有延迟时,事情就变的有趣了起来。下面的例子中,(1.2s后)“A”启动了它的 flow,也就是 flowFrom 。该 flow 在1s内产生了一个元素“1_A”,但是1200ms后出现了“B”,之前的 flow 被关闭并被遗忘。当“C”出现并启动了新的 flow 时,“B” 成功的产生了“1_B”。这个函数最终将生成元素“1_C”、“2_C”、“3_C”,中间有1s的延迟。
suspend fun main() {
flowOf("A", "B", "C")
.onEach {
delay(1200) }
.flatMapLatest {
flowFrom(it) }
.collect {
println(it) }
}
// (2.2 sec)
// 1_A
// (1.2 sec)
// 1_B
// (1.2 sec)
// 1_C
// (1 sec)
// 2_C
// (1 sec)
// 3_C
终端操作
最后,我们有结束 flow 处理的操作。这些被称为终端操作。到目前为止,我们只使用了 collect。但还有其他类似于集合和序列提供的方法:count(计算 flow 中元素的数量)、first 和 firstOrNull(获取 flow 中发射出的第一个元素)、fold 和 reduce(将元素积累到一个对象中)。终端操作将被挂起,并在 flow 完成时返回值。
suspend fun main() {
val flow = flowOf(1, 2, 3, 4) // [1, 2, 3, 4]
.map {
it * it } // [1, 4, 9, 16]
println(flow.first()) // 1
println(flow.count()) // 4
println(flow.reduce {
acc, value -> acc * value }) // 576
println(flow.fold(0) {
acc, value -> acc + value }) // 30
}
目前, flow 的终端操作虽然不多,但如果你需要一些不同的操作,你总是可以自己实现它。例如下面实现整型流的 sum:
suspend fun Flow<Int>.sum(): Int {
var sum = 0
collect {
value ->
sum += value
}
return sum
}
类似地,仅适用 collect 方法就可以实现几乎任何终端操作。
总结
有许多工具支持 flow 处理。对它们有所了解是一件好事,因为它们在后端和 Android 开发中都很有用。另外,如果你需要一些不同的函数,可以通过 collect 方法和 flow 构建器轻松的实现它们。
边栏推荐
- Zhou Hongqi, 52 ans, est - il encore jeune?
- Single machine high concurrency model design
- 自动化测试:Robot FrameWork框架90%的人都想知道的实用技巧
- At the age of 35, I made a decision to face unemployment
- Flask learning record 000: error summary
- [leetcode] 20. Valid brackets
- PostGIS learning
- Prompt configure: error: required tool not found: libtool solution when configuring and installing crosstool ng tool
- How to measure whether the product is "just needed, high frequency, pain points"
- 面试题详解:用Redis实现分布式锁的血泪史
猜你喜欢

Robomaster visual tutorial (1) camera
Operating system principle --- summary of interview knowledge points
某马旅游网站开发(对servlet的优化)
redis你到底懂不懂之list

3年经验,面试测试岗20K都拿不到了吗?这么坑?

第四期SFO销毁,Starfish OS如何对SFO价值赋能?

【编程题】【Scratch二级】2019.03 绘制方形螺旋
Ping error: unknown name or service
Using Google test in QT
大数据开源项目,一站式全自动化全生命周期运维管家ChengYing(承影)走向何方?
随机推荐
ROS从入门到精通(九) 可视化仿真初体验之TurtleBot3
一鍵免費翻譯300多頁的pdf文檔
[programming problem] [scratch Level 2] 2019.09 make bat Challenge Game
自动化测试:Robot FrameWork框架90%的人都想知道的实用技巧
“一个优秀程序员可抵五个普通程序员”,差距就在这7个关键点
The difference between get and post
用語雀寫文章了,功能真心强大!
How to put recyclerview in nestedscrollview- How to put RecyclerView inside NestedScrollView?
应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设
SQL knowledge summary 004: Postgres terminal command summary
Robomaster visual tutorial (11) summary
[leetcode] 20. Valid brackets
数据库查询——第几高的数据?
FFA and ICGA angiography
[the most detailed in history] statistical description of overdue days in credit
[programming problem] [scratch Level 2] draw ten squares in December 2019
智慧监管入场,美团等互联网服务平台何去何从
Teach you to make a custom form label by hand
【史上最详细】信贷中逾期天数统计说明
[研发人员必备]paddle 如何制作自己的数据集,并显示。