当前位置:网站首页>Benchmarking Detection Transfer Learning with Vision Transformers(2021-11)
Benchmarking Detection Transfer Learning with Vision Transformers(2021-11)
2022-07-07 23:47:00 【Gy Zhao】

This article is written by he Kaiming in MAE Then about pure transformer The architecture is used to explore the downstream tasks of target detection , stay MAE Finally, I mentioned , Then there is an article ViTDET In line . about VIT Architecture for visual tasks brings a lot of inspiration .
brief introduction
As a central downstream task, target detection is often used to test the performance of the pre training model , Such as training speed or accuracy . When a new architecture such as VIT When it appears , The complexity of target detection task makes this benchmark more important . in fact , Some difficulties ( If the architecture is incompatible 、 Slow training 、 High memory consumption 、 Unknown training formula, etc ) Obstructed VIT Migration to target detection task research . The paper proposes the use of VIT As Mask RCNN backbone, Achieved the original research purpose : The author compares five VITs initialization , Including self supervised learning methods 、 Supervised initialization and strong random initialization baseline.
Unsupervised / Self supervised deep learning is a commonly used pre training method to initialize model parameters , Then they moved to the downstream task , For example, image classification and target detection finetune. The effectiveness of unsupervised algorithms often uses the indicators of downstream tasks ( Accuracy 、 Convergence speed, etc ) To measure and baseline Make a comparison , For example, there is supervised pre training or Network of retraining from scratch ( Not applicable to pre training ).
Unsupervised deep learning in the visual field usually uses CNN Model , because CNNs Widely used in most downstream tasks , So the benchmark prototype is easy to define , You can use CNN The unsupervised algorithm of is regarded as a plug and play parameter initialization model .
The paper uses Mask RCNN Framework assessment ViT The model is used in the field of object detection and semantic segmentation COCO Performance on data sets , Yes ViT Make minimal modifications , Keep it simple 、 Flexible features .
Conclusion
The paper gives a conclusion in Mask RCNN Use... In the architecture VIT The basic model serves as backbone Effective method . These methods can be accepted in training memory and time , At the same time, without using too many complex extensions COCO The powerful effect of .
- An effective training formula is obtained , Be able to deal with five different ViT Initialize the method to benchmark . Experiments show that ,Random initation It takes more time than any pre-training The initialization of is long 4 times , But we got better than ImageNet-1k Higher training before supervision AP.MoCo v3, Compare the representative algorithms of unsupervised learning , It shows almost the same performance as supervised pre training ( But worse than random initialization ).
- It is important to , An exciting new result : be based on mask Methods (BEiT and MAE) It shows considerable gains in supervision and random initialization , These gains increase as the model size increases . be based on supervise Initialization and based on MoCo v3 This kind of sacling Behavior .
VIT backbone
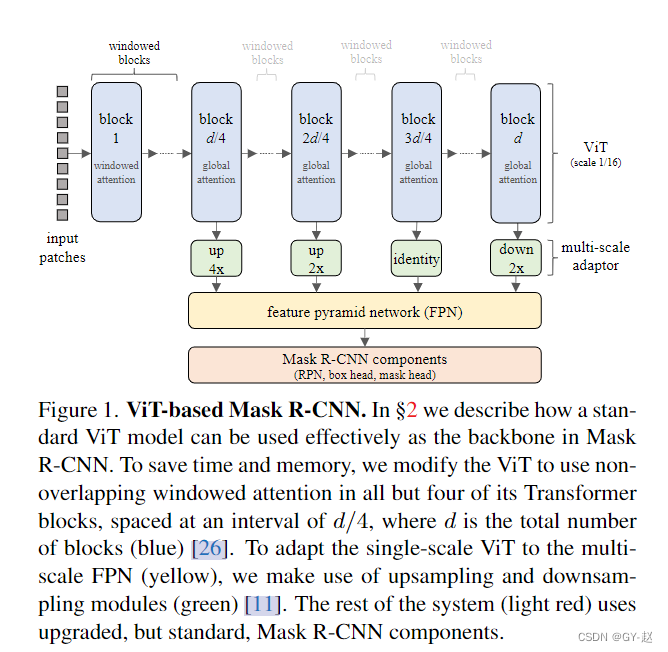
Use ViT As Mask RCNN Of backbone There are two questions :
- How to make it with FPN synergy (ViT Produce a single scale feature map)
- How to reduce memory consumption and running time
For 1 spot :
In order to adapt FPN Multi scale input of , Yes ViT Produced by the middle layer feature map Multiscale features are generated by up sampling or down sampling through four modules with different resolutions , As shown in the above figure, green module, The interval between these four modules is d 4 \frac{d}{4} 4d, d d d yes transformer blocks Number of , That is, equal interval division .
- The first green module, By using two stride-two Of 2 × 2 2 \times 2 2×2 The transpose convolution of 4 Multiple sampling , First, use a 2 × 2 2 \times 2 2×2 Transposition convolution , And then through Group Normaliztion , One more pass Gelu Nonlinear functions , Then use another stride-two 2 × 2 2 \times 2 2×2 Transposition convolution .
- Next d 4 \frac{d}{4} 4dblock Use a stride-two 2 × 2 2 \times 2 2×2 Transpose convolution 2 Multiple sampling , Do not use normalized and nonlinear functions .
- Third d 4 \frac{d}{4} 4dblock The output does not change
- the last one block Conduct stride by 2 Of 2 × 2 2 \times 2 2×2 Of max pooling Double down sampling .
these module, Each one is preserved ViT Of Embeding/channel dimension , For one size =16 Of patch To produce feature map stride Respectively 4,8,16,32, Then input FPN.( Because the original ViT Produced feature The size is input 1 16 \frac{1}{16} 161, After the upper sampling and the lower sampling, it is the size mentioned in the paper )
For 2 spot :
ViT Every one of them self-attention The calculation has O ( h 2 w 2 ) O(h^2w^2) O(h2w2) Spatial complexity of , And expand the image into non overlapping h × w h \times w h×w Of patches Time spent .
This complexity is controllable during pre training , Because the general image size is 224 × 224 224 \times 224 224×224,patch The size is 16 16 16, h = w = 14 h=w=14 h=w=14 This is a typical setting . But in the downstream task of target detection , Standard image size is 1024 × 1024 1024 \times 1024 1024×1024, This is usually pre trained pixels as well patch Of 20 Times as big as , Such a large resolution is also needed to detect larger and smaller targets . So in this case , Even with ViT-base As Mask RCNN Of backbone, In the case of small batches and semi precision floating-point numbers, it usually needs to consume 20-30GB Of GPU Memory .
To reduce space and time complexity , Use restricted self-attention( Also called windowed self-attention)( originate attention is all you need , No impression , I'm going to check , The first impression is Swin Of window attention). take h × w h \times w h×w The mosaic image of is divided into r × r r \times r r×r A non overlapping window , Calculate separately in each window self-attention. such windowed self-attention Have O ( r h 2 w 2 ) O(rh^2w^2) O(rh2w2) Space and time complexity . Set up r Is the size of global self attention , Typical values for 14.( share h r × w r individual w i n d o w s , Every time individual w i n d o w Embrace Yes O ( r 2 ) complex miscellaneous degree \frac{h}{r} \times \frac{w}{r} individual windows, Every window Have O(r^2) Complexity rh×rw individual windows, Every time individual window Embrace Yes O(r2) complex miscellaneous degree ).
One side effect of this approach is window There is no cross window information interaction between , Therefore, a hybrid method is adopted , As shown in the figure , contain 4 A global self attention module , And FPN consistent , Here is what the author calls adding extra parts to make VIT Generate multiscale features .
Yes Mask RCNN module Modification of
- FPN Convolution in Batch Normalization
- stay RPN Use two convolution layers instead of one
- region-of-interest (RoI) classification and box regression head The following full connection layer uses four with batch normal Instead of the original convolution layer with Normalization The two layers MLP.
- Follow the standard mask head Convolution in Batch Normal
The modification code is located in :https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md #new-baselines-using-large-scale-jitter-and-longer-training-schedule
Differences in different pre training methods
- Different pre training methods epoch Dissimilarity , every last epoch Training cost Are not the same as , The paper adopts various methods of default epoch, Obviously, these methods are not comparable .
- BEiT Use learnable realtive positional bias Add self attention to each block logits in , Other methods use absolute position embedding . To explain this , The author includes relative position deviation and absolute position embedding in all detection models , Whether they are used in training or not . about BEiT, Author migration pre-trained bias, And randomly initialize the absolute position embedding . For other methods ,relative positional bias Zero initialization , And transfer the absolute position of pre training to embed . The relative position deviation is across windowed attention blocks and ( A separate ) stay across global attention blocks Share . When there is a spatial dimension mismatch between pre training and fine tuning , We will adjust the size of the pre training parameters , Make it reach the required resolution .
- BEiT Used in training layer scale, Other methods are not used . In the process of fine-tuning ,Beit The initialized model must also be parameterized using layer scale, Other models are not used before training or during fine-tuning layer scale.
- The author tries to standardize the data before training to ImageNet1k, However ,BEiT Use DALL·E、discrete VAE (dVAE), This is about 2.5 Trained on proprietary and unpublished images . The impact of these additional training data has not been fully understood .
Experimental part
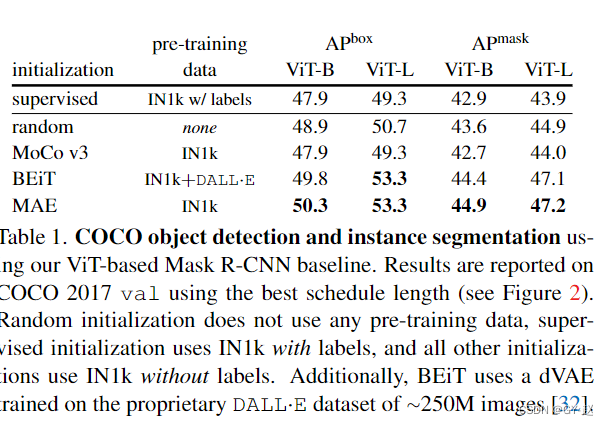
- Comparison of initialization methods , There is no pre training for random initialization .
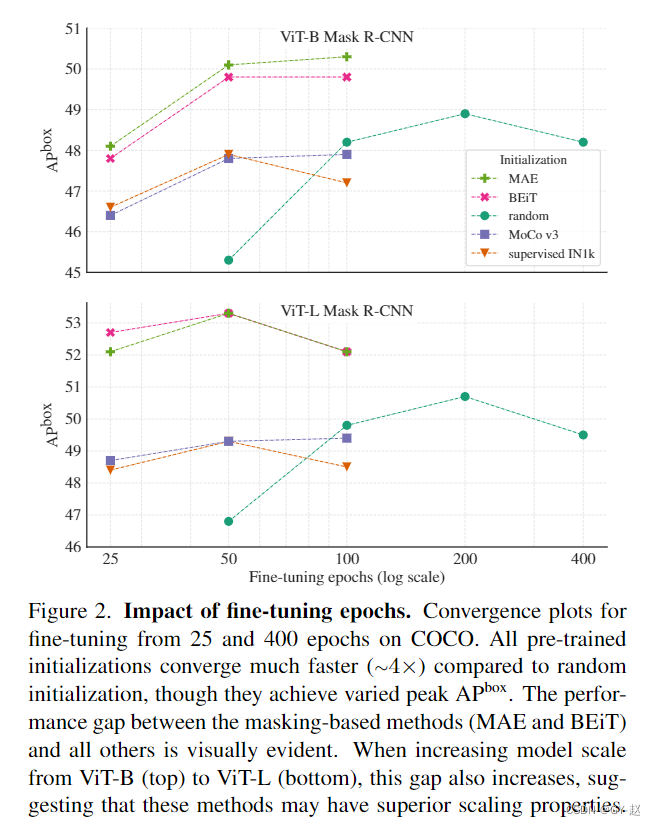
- finetune epoch from 25-400 Convergence comparison of , You can see that any method converges faster than random initialization , And obtained by various methods AP Each are not identical , among MAE And BeiT similar , But apparently ViT-B Compared with ViT-L And BeiT There's a bigger gap , This increases as the size of the model increases , It shows that they have strong scalability .
Most methods are after long training , All show signs of over fitting ,AP Value down , At the same time, we observe the random initialization method AP Above MoCo V3 And supervised IN1k, This is because COCO Dataset is a challenging setting for migration learning , Therefore, random initialization may achieve better performance .MAE and BEiT Provides the first convincing result , Based on pre training COCO AP Greatly improved , And as the model size increases AP There is still great potential for improvement .
Ablation Experiment

- be based on FPN Multi scale and single scale variants of contrast .

- Comparison of strategies to reduce time and memory consumption , There are four options .
- use 14 × 14 14 \times 14 14×14window self-attention Replace all Global attention
- A mixture of attention
- All use Global attention with activation checkpointing
- Do not use the above strategy , Will report a mistake out-of-memory (OOM) error Block training .
The second scheme achieves a good balance in accuracy, training time and memory , Surprisingly, it's all used window attention The performance is not so bad . This may be due to the cross window computation introduced by convolution operation and in Mask R-CNN Of RoI Align Caused by the rest of .
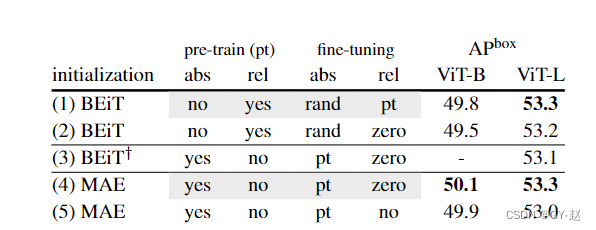
- The influence of location information .
- stay BEiT in VIT Modified to be in each transformer block Use in realtive positional bias, Instead of adding absolute positional Embeeding To Patch embeeding. This choice is an orthogonal enhancement , Other pre training methods are not used .
For a fair comparison , By default, all fine-tuning models include relative positional bias( And absolute position embedding ).
Meaning in the table
relative position biases (rel)
absolute position embeddings (abs)
pt: initialized with pre-trained values;
rand: random initialization;
zero: initialized at zero;
no: this positional information is not used in the fine-tuned model
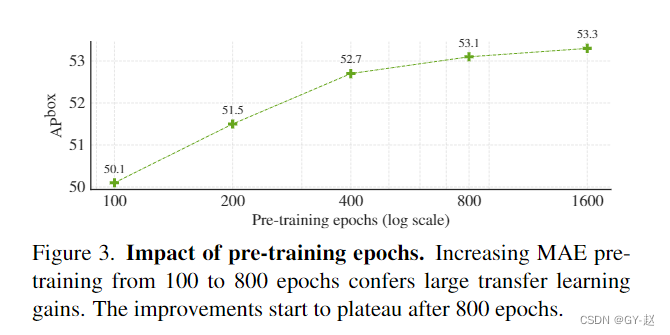
- Preliminary training epoch Influence . With epoch increase ,AP Also increase .
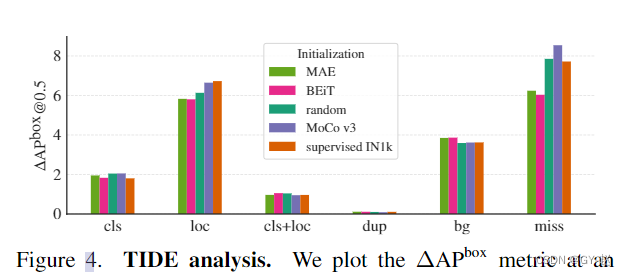
- Drew Δ A P b o x @ 0.5 \Delta AP^{box}@0.5 ΔAPbox@0.5 Indicators of . Each one represents something that can be improved after correcting a certain error A P AP AP value .
cls: Correct positioning (IoU>0.5), Classification error
loc: The classification is correct but the positioning is wrong (IoU in [0.1, 0.5))
cls+loc: Classification and positioning are wrong
dup: detection would be correct if not for a higher scoring correct detection
bg: detection is in the background (IoU <0.1)
miss: all undetected ground-truth objects not covered by other error types.
be based on mask Methods (MAE /BEiT) Compared with MoCo V3 And the supervised initialization method has fewer positioning errors , The number of missed inspections is also less .
- Model complexity . When training from scratch ,ResNet101 And ViT-B All achieved 48.9 A P b o x AP^{box} APbox, In training VIT-B Training 200 individual epoch Reached the peak ,ResNet-101 want 400 individual epoch.ResNet-101 Of fps Obviously faster .
边栏推荐
- DataGuard active / standby cleanup archive settings
- How did a fake offer steal $540million from "axie infinity"?
- Codeworks 5 questions per day (average 1500) - day 8
- 数据湖(十五):Spark与Iceberg整合写操作
- Understand TCP's three handshakes and four waves with love
- ASP. Net core middleware request processing pipeline
- SAP HR labor contract information 0016
- Chisel tutorial - 05 Sequential logic in chisel (including explicit multi clock, explicit synchronous reset and explicit asynchronous reset)
- 机器人(自动化)等专业课程创新的结果
- Anxinco EC series modules are connected to the multi protocol access products of onenet Internet of things open platform
猜你喜欢

The file format and extension of XLS do not match

机器人(自动化)等专业课程创新的结果

光流传感器初步测试:GL9306

Anxin vb01 offline voice module access intelligent curtain guidance

Aitm3.0005 smoke toxicity test
Dataguard 主备清理归档设置

C # exchange number, judge to pass the exam
DataGuard active / standby cleanup archive settings

C - linear table
一个测试工程师的7年感悟 ---- 致在一路独行的你(别放弃)
随机推荐
数据湖(十五):Spark与Iceberg整合写操作
@Detailed introduction of configuration annotation
Understand TCP's three handshakes and four waves with love
Jisuan Ke - t3104
保证接口数据安全的10种方案
Take you hand in hand to build Eureka server with idea
光流传感器初步测试:GL9306
Flash download setup
企业应用需求导向开发之人力部门,员工考勤记录和实发工资业务程序案例
10 schemes to ensure interface data security
C method question 2
One of the anti climbing methods
@Configuration注解的详细介绍
C language learning
Gorm Association summary
aws-aws help报错
C cat and dog
Aitm3.0005 smoke toxicity test
ASP. Net core middleware request processing pipeline
codeforces每日5题(均1500)-第八天