当前位置:网站首页>STL--String类的常用功能复写
STL--String类的常用功能复写
2022-07-07 22:59:00 【New Young】
文章目录
前言:
string类的初识
- string本质是basic_string模板类的实例化后的重命名,其中含有很多处理字符串的成员函数:重栽的[],=等
typedef basic_string<char> string;
命名空间
在复写string类时,因为string类是标准库中的内置类型,为了避免命名污染问题,可以命名一个自己的命名空间
//完成string的增删查改复写
namespace My_Str //防止污染std命名空间
{
class string
{
private:
char* _str;
int _size;//有效字符的个数
int _capacity;//有效字符的容量,不包含'\0',但是因为开辟空间时多开辟一个,
//因此默认预留了一个'\0',方便执行C函数
......
};
数据成员
这里使用数组形式,方便操作
namespace My_Str //防止污染std命名空间
{
class string
{
private:
char* _str;
int _size;//有效字符的个数
int _capacity;//有效字符的容量,不包含'\0',但是因为开辟空间时多开辟一个,
//因此默认预留了一个'\0',方便执行C函数
构造函数
string标准在初始化是不能用单一字符的,只能用字符串或者已存在的对象。
在这些构造函数中推荐使用现代写法,利用了函数栈帧后局部变量自动销毁和对代码的灵活复用
自定义构造函数
- 全缺省的构造函数,对于空字符串,_size为0,在扩容时要留意
//全缺省的构造函数,对于空字符串,_size为0,在扩容时要留意
//string(const char* str="");
My_Str::string::string(const char* str)
:_size(strlen(str)), _capacity( _size)
{
_str = new char[_capacity+1];//+1是给\0预留空间,防止
strcpy(_str, str);
}
拷贝构造函数
- 在不用引用的情况下, 实参到形参的传递也是一种拷贝
- 在有需要动态管理的成员时,防止浅拷贝造成的对同一空间多次delete问题
- 现代写法,本质是对代码的复用和对局部变量函数栈帧后销毁的操作
//拷贝构造,注意
// 1. 在不用引用的情况下, 实参到形参的传递也是一种拷贝
// 2.在有需要动态管理的成员时,防止浅拷贝造成的对同一空间多次delete问题
My_Str::string::string(const string& s)
{
一般写法
//_str = new char[strlen(s._str) + 1];
//strcpy(_str, s._str);
//_size = s._size;
//_capacity = s._capacity;
现代写法,本质是对代码的复用和对局部变量函数栈帧后销毁的操作
string tmp(s._str);//调用了自定义的构造函数
_str = nullptr;//这步必须要有,否则就是对随机值进行delete
swap(tmp);//string下的swap函数
//std::swap(_str,tmp._str);//标准库下的swap模板函数
_size = tmp._size;
_capacity = tmp._capacity;
}
赋值运算符
一般需要考虑自身赋值问题
现代写法,因为拷贝构造后的对象地址不同,因此不用考虑自身赋值和多次释放同一空间的问题
My_Str::string& My_Str::string::operator=(const My_Str::string& s)
{
//自身的赋值
//if (&s != this)
//{
// //一般写法:
// char *tmp = new char[s._size + 1];//防止申请失败,C++的new会抛异常,未学
// strcpy(tmp, s._str);
// delete[]_str;//释放原先的空间
// _str = tmp;//局部变量销毁后,堆的空间仍存在。
// _size = s._size;
// _capacity = s._capacity;
//}
//现代写法,不用考虑自身赋值和多次释放同一空间的问题
string tmp(s);//
std::swap(_str, tmp._str);
_size = tmp._size;
_capacity = tmp._capacity;
return *this;
}
析构函数
My_Str::string::~string()//析构函数
{
delete[]_str;
_str = nullptr;
_size =_capacity= 0;
}
c_str()
const char* My_Str::string::c_str()
{
return _str;
}
const char* My_Str::string::c_str()const
{
return _str;
}
clear()
void My_Str::string::clear()
{
_size = 0;
}
size()
size_t My_Str::string::size()
{
return _size;
}
size_t My_Str::string::size()const
{
return _size;
}
操作符[]
char& My_Str::string::operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& My_Str::string::operator[](size_t pos)const
{
assert(pos < _size);
return _str[pos];
}
迭代器
迭代器,暂时理解为指针
typedef char* iterator;
typedef const char* const_iterator;
My_Str::string::iterator My_Str::string::begin()
{
return _str;
}
My_Str::string::iterator My_Str::string::end()
{
return _str + _size ;
}
My_Str::string::const_iterator My_Str::string::begin()const
{
return _str;
}
My_Str::string::const_iterator My_Str::string::end()const
{
return _str + _size;
}
扩容函数
reserve()
不支持缩小扩,因此只需要考虑n>_capacity的情况
void My_Str::string::reserve(size_t n)
{
if(n > _capacity)
{
char* tmp = new char[n+1];
strcpy(tmp,_str);
delete[]_str;
_str = tmp;
_capacity = n;
}
}
resize()
支持缩小扩,因此需要以size为界,考虑情况
void My_Str::string::resize(size_t n, char ch)
{
//resize不支持缩小_capacity;
if (n <= _size)
{
_str[n] = '\0';
_size = n;
}
else
{
if (n > _capacity)
{
reserve(n);
}
memset(_str + _size, ch, n - _size);
_str[_size] = '\0';
}
}
插入
尾插
- 单个字符,只需要按情况扩容2倍即可,
- 但是对于字符串,其个数不可空,因此扩容时依情况确定。
- 对于尾插更建议使用 +=;
push_back()
void My_Str::string::push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity==0?4:_capacity*2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
append()
void My_Str::string::append(const char* str)
{
size_t len = strlen(str);
if ((len + _size) > _capacity)
{
reserve(len + _size);
}
strcpy(_str + _size, str);
}
操作符+=
My_Str::string& My_Str::string::operator +=(const char ch)
{
push_back(ch);
return *this;
}
My_Str::string& My_Str::string::operator +=(const char* str)
{
append(str);
return *this;
}
头插
insert()
头插,一般不建议使用,效率低
My_Str::string& My_Str::string::insert(size_t pos, const char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//因为是无符号整型,在减运算中要注意死循环问题
size_t end = _size+1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
return *this;
}
My_Str::string& My_Str::string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + len;
while (end > pos+len)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str,len);
//strcpy会将'\0添加进去'
return *this;
}
查
find()
size_t My_Str::string::find(char ch)
{
for (size_t i = 0; i < _size; ++i)
{
if (ch == _str[i])
{
return i;
}
}
return npos;
}
size_t My_Str::string::find(const char* str, size_t pos)
{
assert(pos < _size&& strlen(str)<_size);
const char* ret = strstr(_str, str);
if (ret != nullptr)
{
return ret - _str;
}
return npos;
}
删
erase()
My_Str::string& My_Str::string::erase(size_t pos , size_t len )
{
assert(pos < _size);
if (len == npos || len >= (_size - pos))//删除全部
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
输入输出函数
operator<<()
std::ostream& operator<<(std::ostream& out, const My_Str::string& s)
{
for (int i = 0; i < s.size(); ++i)//有限次的循环,可以避免字符串中间含有'\0'的情况
{
out << s[i];
}
//cout<<s.c_str();
return out;
}
operator>>()
std::istream& operator >> (std::istream& in, My_Str::string& s)
{
char ch = 0;
//ch = getchar();
//while (ch != ' '&&ch!='\n')
//{
// s += ch;
// ch = getchar();
//}
s.clear();
ch = in.get();
while (ch != ' '&&ch!='\n')
{
s += ch;
ch = in.get();
}
return in;
}
比较函数
因为string的接口很多,这里将重载的函数都定义为全局函数
operator<()
//"abcd" "abcd" false
//"abcd" "abcde"true
//"abcde" "abcd"false
bool operator<(const My_Str::string& s1, const My_Str::string& s2)
{
size_t i1 = 0;
size_t i2 = 0;
while ( i1< s1.size()&& i2<s2.size())
{
if (s1[i1] < s2[i2])
{
return false;
}
++i1;
++i2;
}
return i1 < s1.size() ? false : true;
}
operator==()
bool operator==(const My_Str::string& s1, const My_Str::string& s2)
{
size_t i1 = 0;
size_t i2 = 0;
while (i1 < s1.size() && i2 < s2.size())
{
if (s1[i1] != s2[i2])
{
return false;
}
++i1;
++i2;
}
return i1 == s1.size() && i2 == s2.size() ? true : false;
}
operator!=()
bool operator!=(const My_Str::string& s1, const My_Str::string& s2)
{
return !(s1 == s2);
}
operator<=()
bool operator<=(const My_Str::string& s1, const My_Str::string& s2)
{
return s1 < s2 || s1 == s2;
}
operator>()
bool operator>(const My_Str::string& s1, const My_Str::string& s2)
{
return !(s1 <= s2);
}
operator>=()
bool operator>=(const My_Str::string& s1, const My_Str::string& s2)
{
return !(s1 < s2);
}
全部代码
String.h
#pragma once
#include<iostream>
#include<string>
#include<assert.h>
//完成string的增删查改复写
namespace My_Str //防止污染std命名空间
{
class string
{
private:
char* _str;
int _size;//有效字符的个数
int _capacity;//有效字符的容量,不包含'\0',但是因为开辟空间时多开辟一个,
//因此默认预留了一个'\0',方便执行C函数
public:
static const size_t npos;
//全缺省的构造函数,不能用空指针赋值,会产生野指针问题
string(const char* str="");
//自定义拷贝构造,
// 1. 在不用引用的情况下, 实参到形参的传递也是一种拷贝
// 2.默认的拷贝构造是浅拷贝,在有需要动态管理的成员时,防止浅拷贝造成的对同一空间多次delete问题
//这也是现代写法的原因
string(const string& s);
//析构函数
~string();
void swap(string& s);
//赋值运算符
string& operator=(const string& s);
//字符首地址.
const char* c_str();
const char* c_str()const;
size_t size();
size_t size()const ;
char& operator[](size_t pos);
const char& operator[](size_t pos)const;
//迭代器,暂时理解为指针
//普通对象迭
typedef char* iterator;
iterator begin();
iterator end();
//常对象
typedef const char* const_iterator;
const_iterator begin()const;
const_iterator end()const;
//扩容
void reserve(size_t n);//不支持缩小扩
void resize(size_t n, char ch='\0');//支持缩小扩
//插入,更多的是使用+=
//头插,一般不建议使用,效率低
string& insert(size_t pos, const char ch);
string& insert(size_t pos, const char *str);
//尾插,
//单个字符,只需要按情况扩容2倍即可,
// 但是对于字符串,其个数不可空,因此扩容时依情况确定。
//
void push_back(char ch);
void append( const char* str);
string& operator +=(const char ch);
string& operator +=(const char* str);
//删
string& erase(size_t pos = 0, size_t len = npos);
//查
size_t find(char ch);
size_t find(const char* str, size_t pos = 0);
};
}
std::ostream &operator<<(std::ostream& out, const My_Str::string& s);
std::istream& operator >> (std::istream& in, My_Str::string& s);
bool operator<(const My_Str::string& s1, const My_Str::string& s2);
bool operator==(const My_Str::string& s1, const My_Str::string& s2);
bool operator!=(const My_Str::string& s1, const My_Str::string& s2);
bool operator<=(const My_Str::string& s1, const My_Str::string& s2);
bool operator>(const My_Str::string& s1, const My_Str::string& s2);
bool operator>=(const My_Str::string& s1, const My_Str::string& s2);
String.cpp
#define _CRT_SECURE_NO_WARNINGS
#include"String.h"
const size_t My_Str::string::npos=-1;
//全缺省的构造函数,对于空字符串,_size为0,在扩容时要留意
My_Str::string::string(const char* str)
:_size(strlen(str)), _capacity( _size)
{
_str = new char[_capacity+1];
strcpy(_str, str);
}
//拷贝构造,注意
// 1. 在不用引用的情况下, 实参到形参的传递也是一种拷贝
// 2.在有需要动态管理的成员时,防止浅拷贝造成的对同一空间多次delete问题
// 3.这也是现代写法的原因
My_Str::string::string(const string& s)
{
一般写法
//_str = new char[strlen(s._str) + 1];
//strcpy(_str, s._str);
//_size = s._size;
//_capacity = s._capacity;
现代写法,本质是对代码的复用和对局部变量函数栈帧后销毁的操作
string tmp(s._str);//调用了自定义的构造函数
_str = nullptr;//这步必须要有,否则就是对随机值进行delete
swap(tmp);//string下的swap函数
//std::swap(_str,tmp._str);//标准库下的swap模板函数
_size = tmp._size;
_capacity = tmp._capacity;
}
My_Str::string::~string()//析构函数
{
delete[]_str;
_str = nullptr;
_size =_capacity= 0;
}
void My_Str::string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
My_Str::string& My_Str::string::operator=(const My_Str::string& s)
{
//自身的赋值
//if (&s != this)
//{
// //一般写法:
// char *tmp = new char[s._size + 1];//防止申请失败,C++的new会抛异常,未学
// strcpy(tmp, s._str);
// delete[]_str;//释放原先的空间
// _str = tmp;//局部变量销毁后,堆的空间仍存在。
// _size = s._size;
// _capacity = s._capacity;
//}
//现代写法,不用考虑自身赋值和多次释放同一空间的问题
string tmp(s);//
std::swap(_str, tmp._str);
_size = tmp._size;
_capacity = tmp._capacity;
return *this;
}
//字符首地址.
const char* My_Str::string::c_str()
{
return _str;
}
const char* My_Str::string::c_str()const
{
return _str;
}
size_t My_Str::string::size()
{
return _size;
}
size_t My_Str::string::size()const
{
return _size;
}
char& My_Str::string::operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& My_Str::string::operator[](size_t pos)const
{
assert(pos < _size);
return _str[pos];
}
My_Str::string::iterator My_Str::string::begin()
{
return _str;
}
My_Str::string::iterator My_Str::string::end()
{
return _str + _size ;
}
My_Str::string::const_iterator My_Str::string::begin()const
{
return _str;
}
My_Str::string::const_iterator My_Str::string::end()const
{
return _str + _size;
}
void My_Str::string::reserve(size_t n)
{
if(n > _capacity)
{
char* tmp = new char[n+1];
strcpy(tmp,_str);
delete[]_str;
_str = tmp;
_capacity = n;
}
}
void My_Str::string::resize(size_t n, char ch)
{
//resize不支持缩小_capacity;
if (n <= _size)
{
_str[n] = '\0';
_size = n;
}
else
{
if (n > _capacity)
{
reserve(n);
}
memset(_str + _size, ch, n - _size);
_str[_size] = '\0';
}
}
void My_Str::string::push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity==0?4:_capacity*2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
void My_Str::string::append(const char* str)
{
size_t len = strlen(str);
if ((len + _size) > _capacity)
{
reserve(len + _size);
}
strcpy(_str + _size, str);
}
My_Str::string& My_Str::string::operator +=(const char ch)
{
push_back(ch);
return *this;
}
My_Str::string& My_Str::string::operator +=(const char* str)
{
append(str);
return *this;
}
size_t My_Str::string::find(char ch)
{
for (size_t i = 0; i < _size; ++i)
{
if (ch == _str[i])
{
return i;
}
}
return npos;
}
size_t My_Str::string::find(const char* str, size_t pos)
{
assert(pos < _size&& strlen(str)<_size);
const char* ret = strstr(_str, str);
if (ret != nullptr)
{
return ret - _str;
}
return npos;
}
My_Str::string& My_Str::string::insert(size_t pos, const char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//因为是无符号整型,在减运算中要注意死循环问题
size_t end = _size+1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
return *this;
}
My_Str::string& My_Str::string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + len;
while (end > pos+len)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str,len);
//strcpy会将'\0添加进去'
return *this;
}
My_Str::string& My_Str::string::erase(size_t pos , size_t len )
{
assert(pos < _size);
if (len == npos || len >= (_size - pos))//删除全部
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
//
//"abcd" "abcd" false
//"abcd" "abcde"true
//"abcde" "abcd"false
bool operator<(const My_Str::string& s1, const My_Str::string& s2)
{
size_t i1 = 0;
size_t i2 = 0;
while ( i1< s1.size()&& i2<s2.size())
{
if (s1[i1] < s2[i2])
{
return false;
}
++i1;
++i2;
}
return i1 < s1.size() ? false : true;
}
bool operator==(const My_Str::string& s1, const My_Str::string& s2)
{
size_t i1 = 0;
size_t i2 = 0;
while (i1 < s1.size() && i2 < s2.size())
{
if (s1[i1] != s2[i2])
{
return false;
}
++i1;
++i2;
}
return i1 == s1.size() && i2 == s2.size() ? true : false;
}
bool operator!=(const My_Str::string& s1, const My_Str::string& s2)
{
return !(s1 == s2);
}
bool operator<=(const My_Str::string& s1, const My_Str::string& s2)
{
return s1 < s2 || s1 == s2;
}
bool operator>(const My_Str::string& s1, const My_Str::string& s2)
{
return !(s1 <= s2);
}
bool operator>=(const My_Str::string& s1, const My_Str::string& s2)
{
return !(s1 < s2);
}
std::ostream& operator<<(std::ostream& out, const My_Str::string& s)
{
for (int i = 0; i < s.size(); ++i)//有限次的循环,可以避免字符串中间含有'\0'的情况
{
out << s[i];
}
//cout<<s.c_str();
return out;
}
std::istream& operator >> (std::istream& in, My_Str::string& s)
{
char ch = 0;
//ch = getchar();
//while (ch != ' '&&ch!='\n')
//{
// s += ch;
// ch = getchar();
//}
ch = in.get();
while (ch != ' '&&ch!='\n')
{
s += ch;
ch = in.get();
}
return in;
}
总结
在处理边界问题,一定要仔细,否则程序可能会CREASH
边栏推荐
- 接口测试要测试什么?
- 3 years of experience, can't you get 20K for the interview and test post? Such a hole?
- How can CSDN indent the first line of a paragraph by 2 characters?
- Service Mesh的基本模式
- 攻防世界Web进阶区unserialize3题解
- 2022-07-07:原本数组中都是大于0、小于等于k的数字,是一个单调不减的数组, 其中可能有相等的数字,总体趋势是递增的。 但是其中有些位置的数被替换成了0,我们需要求出所有的把0替换的方案数量:
- The standby database has been delayed. Check that the MRP is wait_ for_ Log, apply after restarting MRP_ Log but wait again later_ for_ log
- 韦东山第三期课程内容概要
- 取消select的默认样式的向下箭头和设置select默认字样
- They gathered at the 2022 ecug con just for "China's technological power"
猜你喜欢
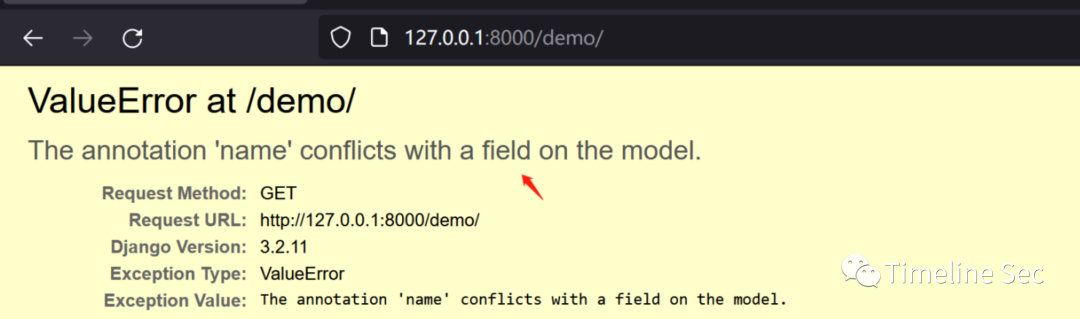
CVE-2022-28346:Django SQL注入漏洞
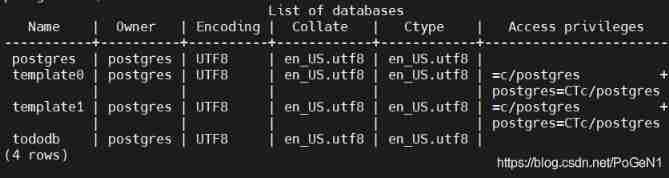
SQL knowledge summary 004: Postgres terminal command summary
fabulous! How does idea open multiple projects in a single window?

从Starfish OS持续对SFO的通缩消耗,长远看SFO的价值

3 years of experience, can't you get 20K for the interview and test post? Such a hole?
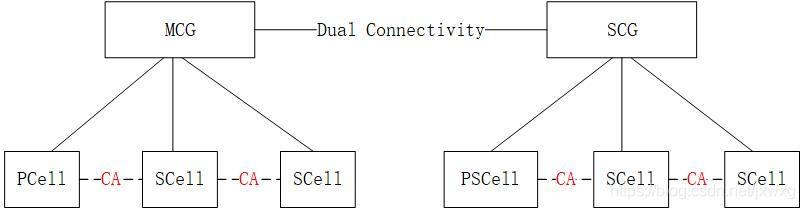
5G NR 系统消息
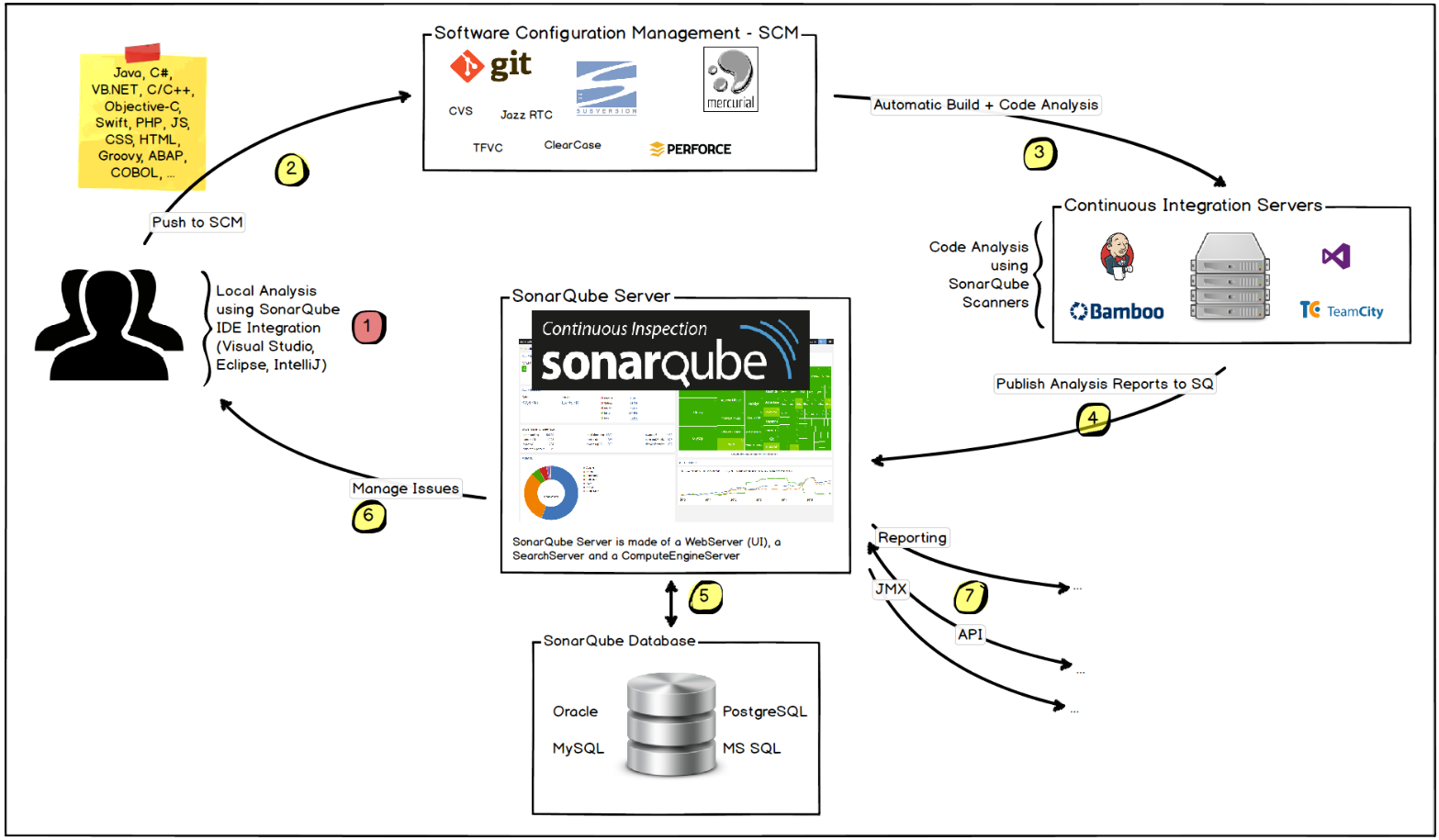
玩轉Sonar
Reentrantlock fair lock source code Chapter 0
Reptile practice (VIII): reptile expression pack
国外众测之密码找回漏洞
随机推荐
Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布
ThinkPHP kernel work order system source code commercial open source version multi user + multi customer service + SMS + email notification
备库一直有延迟,查看mrp为wait_for_log,重启mrp后为apply_log但过一会又wait_for_log
CVE-2022-28346:Django SQL注入漏洞
Summary of the third course of weidongshan
How to insert highlighted code blocks in WPS and word
攻防演练中沙盘推演的4个阶段
Application practice | the efficiency of the data warehouse system has been comprehensively improved! Data warehouse construction based on Apache Doris in Tongcheng digital Department
Interface test advanced interface script use - apipost (pre / post execution script)
Tencent security released the white paper on BOT Management | interpreting BOT attacks and exploring ways to protect
赞!idea 如何单窗口打开多个项目?
Flask learning record 000: error summary
他们齐聚 2022 ECUG Con,只为「中国技术力量」
玩轉Sonar
Service mesh introduction, istio overview
Smart regulation enters the market, where will meituan and other Internet service platforms go
华泰证券官方网站开户安全吗?
大数据开源项目,一站式全自动化全生命周期运维管家ChengYing(承影)走向何方?
[C language] objective questions - knowledge points
How does the markdown editor of CSDN input mathematical formulas--- Latex syntax summary