当前位置:网站首页>GraphAcademy 課程講解:《Neo4j 圖數據科學基礎》
GraphAcademy 課程講解:《Neo4j 圖數據科學基礎》
2022-06-11 02:50:00 【Neo4j 開發者】
目錄

上次給大家介紹了GraphAcademy裏面向數據科學家、數據工作者的課程《Neo4j 圖數據科學簡介》,從那裏我們了解了Neo4j GDS的基本概念、安裝和啟用,以及圖投影的具體操作。
今天給大家介紹後續課程《Neo4j 圖數據科學基礎》,我們詳細看一下Neo4j GDS提供的圖算法和它們適用的場景,以及圖機器學習的基本用法。
希望通過本文的閱讀可以了解課程內容,强烈推薦注册課程開始你自己的學習和進行實際編碼和測試。
什麼是 GraphAcademy

Neo4j GraphAcademy 是 Neo4j 推出的在線互動學習平臺,提供免費、自由掌握進度的在線動手實驗培訓課程。不管你是開發者、運維管理員,還是數據科學家或從事機器學習、人工智能相關工作的人員,都可以在 GraphAcademy 找到適合你的課程。
所有課程均由具有多年經驗的 Neo4j 專業人士開發。我們的目標是為你提供令人愉快的實踐培訓,其中包含文本內容、視頻和代碼挑戰。
你通過的每門課程都會解鎖一個徽章,可以通過你的職業檔案或社交網絡與朋友和同事分享。通過完成 Neo4j 認證考試,你將解鎖限量版的 Neo4j T 恤獎勵,以及更重要的是,獲得圖技術專業技術的證明,可以向雇主和同事展示這一榮譽。
《Neo4j 圖數據科學基礎》課程一覽

在本課程中,我們將介紹數據科學家在使用 Neo4j 圖形數據科學庫 (GDS) 進行分析時需要了解的高級概念,課程涵蓋了 GDS 中可用的圖算法和機器學習操作的內容,並舉例說明了如何在真實數據上使用它們。該課程繼續使用運行在 Neo4j 沙箱的movie recommendations數據集,你將在整個課程中使用它。
本課程需要你具備一些基礎的圖數據科學知識和圖數據庫知識。如果沒有完成《Neo4j 圖數據科學簡介》課程,建議先完成後再進行本課程的學習。
通過本課程你將掌握:
- 圖算法的執行模式
- 不同類別的圖算法和常見用例
- 如何在 GDS 中運行原生圖機器學習管道
本課程分為兩節內容,目錄大綱如下:
圖算法
- 算法層和執行模式
- 中心性和重要性
- 挑戰:度中心性
- 尋找路徑
- 挑戰:找到最短路徑
- 社區檢測
- 節點嵌入
- 相似
圖機器學習
- 機器學習概述
- 節點分類管道
- 鏈接預測
現在跟我一起看一看吧。
圖算法
圖算法產品級別和執行模式
我們從一段偽代碼開始:
CALL gds[.<tier>].<algorithm>.<execution-mode>[.<estimate>](
graphName: STRING,
configuration: MAP
)
這段代碼錶示調用Neo4j GDS庫,[]錶示可選,<>錶示可以選擇不同的值。
圖算法產品層級
tier錶示Neo4j GDS產品的不同級別:alpha、beta和正式版。
- Alpha:錶示算法處於實驗階段,可用於測試和驗證,但隨著版本的更新可能會發生變更。需要指定
tier的值為alpha來調用Alpha版本的算法。 - Beta:錶示算法經過了Alpha版本的驗證,可以作為正式版的候選版本。需要指定
tier為beta來調用。 - 正式版(production-quality):即生產就緒版本,錶示算法經過了穩定性和可擴展性測試,可以用在正式環境中。不指定
tier的值就默認錶示使用正式版。
執行模式
execution-mode有4種,用來指定如何處理算法的結果:
stream:將算法的結果作為記錄流返回。stats:返回匯總統計的單條記錄,但不寫入 Neo4j 數據庫或修改任何數據。mutate:將算法的結果寫入內存中的圖投影並返回匯總統計的單個記錄。write:將算法的結果寫回 Neo4j 數據庫並返回匯總統計的單個記錄。
內存估計
estimate錶示用來估算執行某個算法需要的內存大小,由GDS提供的一個估算程序來計算。
接下來我們詳細看一看Neo4j GDS 提供的算法,即algorithm。
中心性和重要程度
中心性算法用於確定圖中不同節點的重要程度,常見用例包括:
- 推薦系統:識別並推薦你的內容或產品目錄中最具影響力或最受歡迎的項目
- 供應鏈分析:找到供應鏈中最關鍵的節點,無論是網絡中的供應商、成品中的原材料還是路線中的港口
- 欺詐和异常檢測:查找具有許多共享標識符或充當許多社區之間橋梁的用戶
度中心性算法
度中心性是最普遍和最簡單的中心性算法之一。它計算節點具有的關系數(度數)。在 GDS 實現中,我們專門計算出度中心性,即來自節點的傳出關系的計數。比如:
//get top 5 most prolific actors (those in the most movies)
//using degree centrality which counts number of `ACTED_IN` relationships
CALL gds.degree.stream('proj')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS actorName, score AS numberOfMoviesActedIn
ORDER BY numberOfMoviesActedIn DESCENDING, actorName LIMIT 5
PageRank 算法
另一種常見的中心性算法是 PageRank,用於衡量有向圖中節點的影響,特別是在關系暗示某種形式的移動流的情况下,例如支付網絡、供應鏈和物流、通信、路由以及網站和鏈接圖。PageRank 通過計算來自相鄰節點的傳入關系的數量來估計節點的重要性,這些相鄰節點的權重是這些鄰居的重要性和出度中心性。基本假設是,更重要的節點可能具有成比例的更多來自其他導入節點的傳入關系。
如果您有興趣深入研究,我們的 PageRank 文檔會提供有關 PageRank 的全面技術解釋。
其他中心性算法
- 中介中心性:衡量一個節點在圖中其他節點之間的程度。它通常用於查找充當子圖的一部分到另一部分的橋梁的節點。
- 特征向量中心性:測量節點的傳遞影響。類似於 PageRank,但僅適用於鄰接矩陣的最大特征向量,因此不會以相同的方式收斂,並且傾向於更强烈地偏愛高度節點。它在某些用例中可能更合適,尤其是那些具有無向關系的用例。
- ArticleRank:PageRank 的一種變體,它假設源自低度節點的關系比來自高度節點的關系具有更高的影響力。
可以在GDS 文檔的中心性部分找到所有產品層的中心性算法的完整列錶。
挑戰:度中心性實戰

如果網頁上沒有自己彈出Neo4j Browser窗口,可以點擊右下角第一個按鈕切換。希望你能一次通過,記得GDS的流程嗎?先做投影然後執行算法。
路徑查找
路徑查找算法找到兩個或多個節點之間的最短路徑或評估路徑的可用性和質量。常見用例是:
- 供應鏈分析:確定原產地和目的地之間或原材料和成品之間的最快路徑
- 客戶旅程:分析構成客戶體驗的事件。例如,在醫療保健領域,這可以是住院患者從入院到出院的經曆
Dijkstra 源-目標最短路徑
一種常見的行業標准相似性算法是 Dijkstra。它計算源節點和目標節點之間的最短路徑。與 GDS 中的許多其他路徑查找算法一樣,Dijkstra 在比較路徑時支持加權關系以考慮距離或其他成本屬性。
下面是使用 Dijkstra 源-目標最短路徑來查找演員“Kevin Bacon”和“Denzel Washington”之間的最短路徑的示例。
MATCH (a:Actor)
WHERE a.name IN ['Kevin Bacon', 'Denzel Washington']
WITH collect(id(a)) AS nodeIds
CALL gds.shortestPath.dijkstra.stream('proj', {sourceNode:nodeIds[0], TargetNode:nodeIds[1]})
YIELD sourceNode, targetNode, path
RETURN gds.util.asNode(sourceNode).name AS sourceNodeName,
gds.util.asNode(targetNode).name AS targetNodeName,
nodes(path) as path;
其他尋路算法
其他 GDS 生產層路徑查找算法可以分為以下幾個不同的子類別:
兩個節點之間的最短路徑:
- A* 最短路徑: Dijkstra 的擴展,它使用啟發式函數來加速計算。
- Yen 最短路徑 :Dijkstra 的擴展,可讓您找到多條 top k最短路徑。
一個源節點和多個其他目標節點之間的最短路徑:
- Dijkstra 單源最短路徑 :Dijkstra 實現一個源和多個目標之間的最短路徑。
- 增量步進單源最短路徑:並行化的最短路徑計算。比 Dijkstra 單源最短路徑計算更快,但使用更多內存。
一個源節點和多個其他目標節點之間的一般路徑搜索:
- 廣度優先搜索:在每次迭代中按照與源節點的距離遞增的順序搜索路徑。
- 深度優先搜索:在每次迭代中盡可能沿著單個多跳路徑進行搜索。
可以在路徑查找的文檔中找到跨所有產品層的中心性算法的完整列錶。
挑戰:尋找最短路徑
同樣,你可以在Neo4j Browser力執行任意的查詢。希望你能一次通過。
社區檢測
社區檢測算法用於評估節點組在圖中的聚類或分區方式。GDS 中的大部分社區檢測功能都側重於區分這些節點組並將其分配 ID,以進行下遊分析、可視化或其他處理。常見用例包括:
- 欺詐檢測:通過識別經常發生可疑交易和/或彼此共享標識符的賬戶來發現欺詐圈。
- 客戶 360:將多個記錄和交互消歧到一個客戶檔案中,這樣組織就可以為每個客戶提供一個匯總的事實來源。
- 市場細分:根據優先級、行為、興趣和其他標准將目標市場劃分為可接近的子組。
Louvain 社區檢測
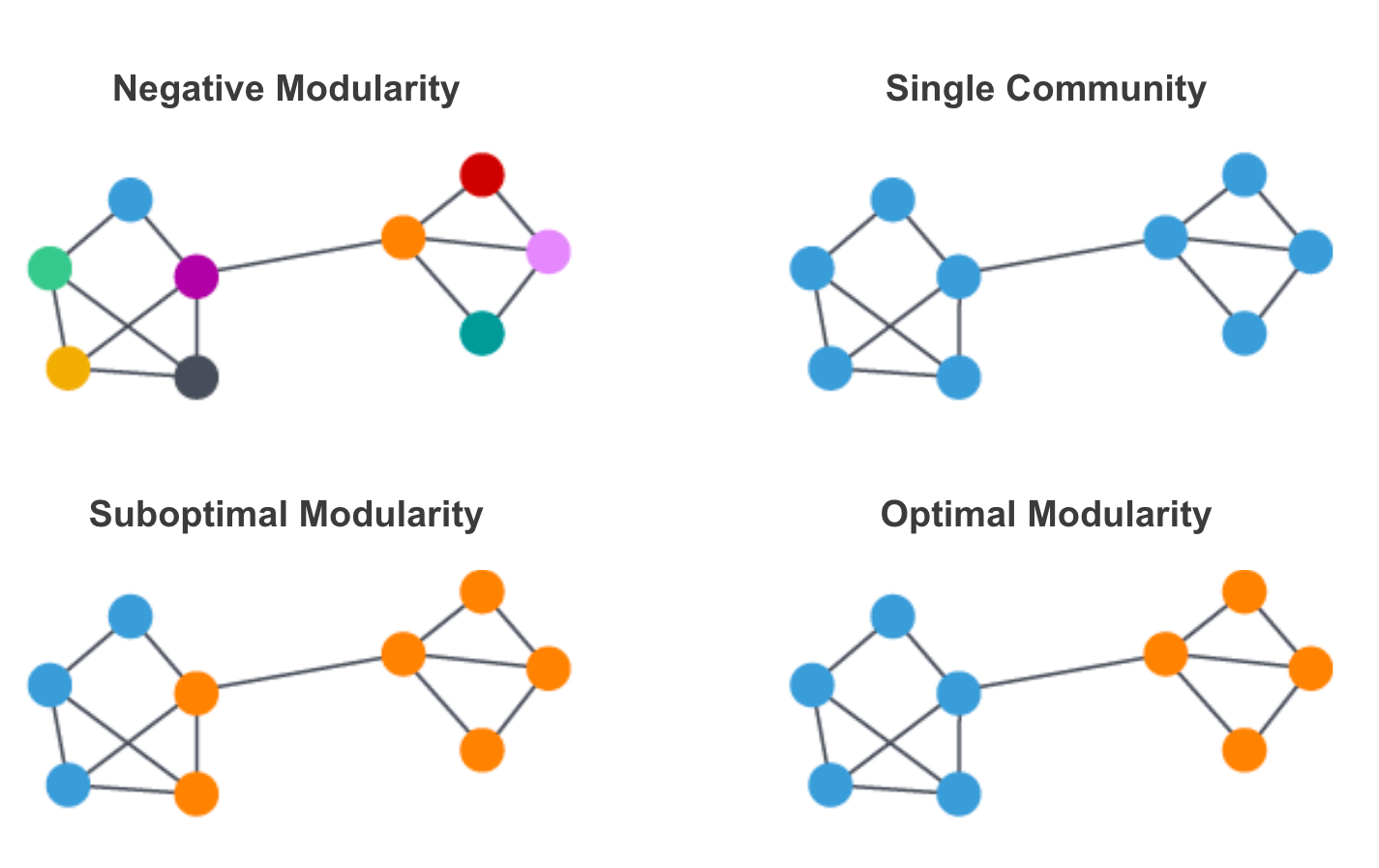
一種常見的社區檢測算法是 Louvain。Louvain 最大化每個社區的模塊化分數,其中模塊化量化了將節點分配給社區的質量。這意味著評估社區中節點的連接密度與隨機網絡中節點的連接程度相比。
Louvain 使用分層聚類方法優化了這種模塊化,該方法將社區遞歸地合並在一起。有多個參數可用於調整 Louvain 以控制其性能以及產生的社區的數量和規模。這包括要使用的最大迭代次數和層次級別以及用於評估收斂/停止條件的容差參數。我們的Louvain 文檔更詳細地介紹了這些參數和調整。
其他社區檢測算法
以下是其他一些生產層社區檢測算法。可以在社區檢測算法文檔中找到所有社區檢測算法的完整列錶。
- 標簽傳播:與 Louvain 類似的意圖。並行化良好的快速算法。非常適合大型圖錶。
- 弱連接組件(WCC):將圖劃分為連接節點集,使得
- 每個節點都可以從同一集合中的任何其他節點訪問
- 不同集合的節點之間不存在路徑
- 三角形計數:計算每個節點的三角形數量。可用於檢測社區的凝聚力和圖的穩定性。
- 局部聚類系數:計算圖中每個節點的局部聚類系數,這是節點如何與其鄰居聚類的指標。
節點嵌入
節點嵌入的目標是計算節點的低維向量錶示,使得向量之間的相似度(例如點積)近似於原始圖中節點之間的相似度。這些向量,也稱為嵌入,對於探索性數據分析、相似性測量和機器學習非常有用。
下圖說明了節點嵌入背後的概念,即圖中靠得很近的節點最終在二維嵌入空間中靠得很近。因此,嵌入從圖中獲取結構,即 n 維鄰接矩陣,並將其近似為每個節點的二維向量。由於顯著降低了維度,嵌入向量在下遊過程中的使用效率更高。例如,它們可以用於聚類分析,或者作為訓練節點分類或鏈接預測模型的特征。

節點嵌入向量本身並不提供洞察力,它們是為了啟用或擴展其他分析而創建的。常見的工作流程包括:
- 探索性數據分析 (EDA),例如可視化 TSNE 圖中的嵌入,以更好地理解圖結構和潜在的節點集群
- 相似度測量:節點嵌入允許您使用 K 最近鄰 (KNN) 或其他技術在大型圖中擴展相似度推斷。這對於擴展基於內存的推薦系統很有用,例如協同過濾的變體。它還可以用於欺詐檢測等領域的半監督技術,例如,我們可能希望生成類似於一組已知欺詐實體的線索。
- 機器學習的特征:節點嵌入向量自然地作為各種機器學習問題的特征插入。例如,在在線零售商的用戶購買圖錶中,我們可以使用嵌入來訓練機器學習模型來預測用戶接下來可能有興趣購買的產品。
FastRP
GDS 提供了一種節點嵌入技術的自定義實現,稱為快速隨機投影,或簡稱為 FastRP。FastRP 利用概率采樣技術生成圖的稀疏錶示,從而可以極快地計算嵌入向量,其質量與傳統隨機遊走和神經網絡技術(如 Node2vec 和 GraphSage)生成的向量相當。這使得 FastRP 成為開始在 GDS 中探索嵌入圖錶的絕佳選擇。
其他節點嵌入算法
GDS 還實現了 Node2Vec,它基於圖中的隨機遊走計算節點的向量錶示,以及GraphSage,它是一種使用節點屬性和圖結構計算節點嵌入的歸納建模方法。
相似度
相似度算法用於推斷節點對之間的相似度。在 GDS 中,這些算法在圖投影上批量運行。當根據用戶指定的度量和閾值識別出相似的節點對時,在該對之間繪制具有相似性得分屬性的關系。根據運行算法時使用的執行模式,這些相似性關系可以stream傳輸、mutate到內存圖或write寫回數據庫。常見用例包括:
- 欺詐檢測:通過分析一組新用戶帳戶與標記帳戶的相似程度來發現潜在的欺詐用戶帳戶。
- 推薦系統:在在線零售商店中,識別與用戶當前正在查看的商品配對的商品,以告知印象並提高購買率。
- 實體解析:根據圖中的活動或識別信息識別彼此相似的節點。
GDS 有兩種主要的相似性算法:
- 節點相似度:根據圖中共享相鄰節點的相對比例確定節點之間的相似度。在可解釋性很重要的情况下,節點相似性是一個不錯的選擇,您可以將比較範圍縮小到數據的子集。縮小範圍的示例包括僅關注單個社區、新添加的節點或特定接近感興趣子圖的節點。
- K 最近鄰 (KNN):根據節點屬性確定相似度。如果調整得當,GDS KNN 實現可以很好地擴展以在大圖上進行全局推理。它可以與嵌入和其他圖算法結合使用,根據圖中的接近度、節點屬性、社區結構、重要性/中心性等來確定節點之間的相似性。
相似函數
除了節點相似度和 KNN 算法之外,GDS 還提供了一組函數,可用於使用各種相似度度量計算兩個數字數組之間的相似度,包括 jaccard、overlap、pearson、餘弦相似度等。完整的文檔可以在 Similarity Functions 文檔中找到。當您有興趣一次測量單個選擇節點對之間的相似性而不是計算整個圖形的相似性時,這些函數很有用。
圖機器學習
首先討論一下 GDS 為何具有機器學習功能會有所幫助,你可以在 Neo4j 中生成圖特征並將它們導出到另一個環境中以進行機器學習,例如 Python、Apache Spark 等。這些外部框架具有很大的自定義靈活性並調整機器學習模型。但是,您可能希望在 GDS 中使用基於圖的機器學習工具有多種原因:
- 管理複雜的模型設計:圖數據本質上是高度互連的,它給機器學習工作流程帶來了複雜性,對於那些不太熟悉圖的人來說,這些複雜性可能難以捕捉和解决。如果不加以考慮,這些複雜性可能會損害 ML 模型的有效性、計算性能和預測性能。GDS 管道包括解决這些複雜性的方法,否則這些複雜性很難在通用、非圖特定的 ML 框架中開發和維護。主要示例是適當的數據拆分設計、處理嚴重的類不平衡以及避免特征工程中的數據泄漏。
- 具有强數據庫耦合的快速生產路徑:由於 Neo4j 中提供了 GDS,因此很容易將 GDS ML 直接應用於 Neo4j 數據庫。一旦你在 GDS 中訓練了一個管道,模型就會被有效地自動保存和部署——准備好通過一個簡單的
predict命令對來自 Neo4j 數據庫的數據進行預測。企業用戶可以保留這些模型以供重用,也可以將它們發布以在團隊之間共享。 - 開發和實驗:即使對於擁有成熟和强大 MLOps 工作流程的企業中經驗豐富的從業者來說,原生 ML 管道也消除了許多通常與圖機器學習相關的初始摩擦。這使您可以試驗和測試模型方法以快速起步。
GDS 專注於為端到端 ML 工作流提供托管管道。數據選擇、特征工程、數據拆分、超參數配置和訓練步驟在管道對象中耦合在一起,以跟踪所需的端到端步驟。目前有兩種受支持的 ML 管道類型:
- 節點分類管道:節點的監督二元和多類分類
- 鏈接預測管道:對節點對之間是否應該存在關系或“鏈接”的監督預測
這些管道有一個train程序,一旦運行,就會產生一個經過訓練的模型對象。反過來,這些經過訓練的模型對象具有predict可用於對數據進行預測的過程。您可以在 GDS 中同時擁有多個管道和模型對象。管道和模型都有一個目錄,允許您按名稱管理它們,類似於圖目錄中的圖投影。
節點分類管道
下面是 GDS 中高級節點分類模式的圖示,從投影圖通過各個步驟到最終注册模型並對數據進行預測。

在實踐中,訓練步驟 1-6 將由流水線自動執行。您將只負責為它們提供配置和超參數。因此,在較高級別上,您的工作流程對於節點分類將如下所示,對於鏈接預測也是如此:
- 投影圖並配置管道(順序無關緊要)。
- 使用命令執行管道
train。 predict使用命令在投影圖上進行預測。如果需要,可以使用圖寫入write操作將預測寫回數據庫。
鏈接預測
GDS 目前提供二進制分類器,其中目標是 0-1 指標,0 錶示無鏈接,1 錶示有鏈接。這種類型的鏈接預測在無向圖中非常有效,您可以在其中預測單個標簽的節點之間的一種類型的關系,例如社交網絡和實體解析問題。
下面是 GDS 中高級鏈接預測模式的圖示,從投影圖通過各個步驟到最終注册模型並對數據進行預測。

你會注意到此處的一些額外步驟與過去可能使用過的節點分類和其他通用 ML 管道不同。即,feature-input關系拆分中有一個附加集,現在比特於節點屬性和特征生成步驟之前。簡而言之,這是為了處理數據泄漏問題,從而使用你想要預測的關系來計算模型特征。這種情况將允許模型使用通常不可用的特征中的信息,從而導致過於樂觀的性能指標。可以在文檔中閱讀有關數據拆分方法的更多信息。
圖機器學習的兩節都有詳細的示例代碼,你可以點擊“Run in Sandbox”就能在當前頁面的Neo4j Browser裏看到執行結果。

課程總結
恭喜!你現在應該准備好使用 Neo4j 圖數據科學庫運行你的第一個圖算法了。
在第一個模塊圖算法中,你了解了 Neo4j GDS 中可用的圖算法以及如何在真實數據上使用它們。
在第二個模塊圖機器學習中,你了解了 GDS 原生機器學習操作,包括節點分類管道和鏈接預測。
下一步
現在你對 Neo4j 圖數據科學 GDS 庫的圖算法和機器學習有了一些基本的了解和實戰,你可以閱讀 GDS 的詳細文檔來了解細節,甚至訪問 GDS 的源代碼來共同改進。現在是時候在實際業務中使用 GDS 了,歡迎隨時跟我們保持聯系。
參考資源
本課程地址:https://graphacademy.neo4j.com/courses/graph-data-science-fundamentals/
《Neo4j圖數據科學簡介》課程:https://graphacademy.neo4j.com/courses/gds-product-introduction/
課程數據集:https://github.com/neo4j-graph-examples/recommendations
边栏推荐
- Three special data types, day3 and redis (geographic location, cardinality statistics and bitmap scene usage)
- [interview question 17.04. missing numbers]
- Dynamically add attributes to objects
- [Fibonacci series]
- GCC C inline assembly
- Android WiFi hide SSID configuration method
- Jetpack compose box control
- Can Xiaoxiang life become the "Yonghui" in the discount industry after the completion of the round a financing of tens of millions of yuan?
- One line of code solves the problem that the time to fetch datetime from MySQL database is less than eight hours
- MySQL backup and recovery
猜你喜欢

蓝桥杯_小蓝吃糖果_鸽巢原理 / 抽屉原理

靠贴牌飞利浦冲击上市,德尔玛的自有品牌又该如何“起跳”?

If you understand the logic of mining and carbon neutrality, you will understand the 100 billion market of driverless mining areas

新来的同事问我 where 1=1 是什么意思???

Manon's advanced road - Daily anecdotes
弄懂了采矿业与碳中和的逻辑,就读懂了矿区无人驾驶的千亿市场

Unity animator rewind

MOFs, metal organic framework materials of folic acid ligands, are loaded with small molecule drugs such as 5-fluorouracil, sidabelamine, taxol, doxorubicin, daunorubicin, ibuprofen, camptothecin, cur
![[AI weekly] AI and freeze electron microscopy reveal the structure of](/img/2e/e986a5bc44526f686c407378a9492f.png)
[AI weekly] AI and freeze electron microscopy reveal the structure of "atomic level" NPC; Tsinghua and Shangtang proposed the "SIM" method, which takes into account semantic alignment and spatial reso

Write my Ini configuration file error
随机推荐
位置数据融合表3
When the interviewer opens his mouth, he comes to compose. Is this the case now?
AOSP ~ WiFi on by default + GPS off by default + Bluetooth off by default + rotary screen off
你的公司会选择开发数据中台吗?
92. actual combat of completable future
ShaderGraphs
How can Delma's own brand "take off" when Philips is listed on the market?
How to state clearly and concisely the product requirements?
CPT 102_LEC 18
mysql重装时写my.ini配置文件出错
AOSP ~ 修改默认音量
How to add cookie pop-up window in WordPress website (without plug-in)
Common vocabulary of software testing English
[MySQL 45 lecture -12] lecture 12 the reason why MySQL has a wind attack from time to time
String operation methods: replace, delete and split strings
Sd3.0 notes
P4338 [zjoi2018] history (tree section) (violence)
Project load failed
13. numeric array
Prophet