当前位置:网站首页>Swin Transformer代码讲解
Swin Transformer代码讲解
2022-06-12 16:34:00 【QT-Smile】
Swin Transformer代码讲解
下采样是4倍,所以patch_size=4

2.
3.
emded_dim=96就是下面图片中的C,经过第一个Linear Embedding处理之后的通道数

4.
经过第一个全连接层把通道数翻为几倍

6.
在Muhlti-Head Attention中是否使用qkv——bias,这里默认是使用
7.
第一个drop_rate接在PatchEmbed后面


第二个drop_rate在Multi-Head Attention过程中使用的
9.
第三个drop_rate是指在每一个Swin Transformer Blocks中使用的,它是从0慢慢增长到0.1的

10.
patch_norm默认接在PatchEmbed后面的
11.
默认不使用,使用的话,只是会节省内存
12.
对应于每一个stage中Swin Transformer Blocks的个数
13.
对应stage4的输出的通道的个数

14.
PatchEmbed就是把图片划分成没有重叠的patches
15.
PatchEmbed对应结构图中高的 Patch Partition 和Linearing Embedding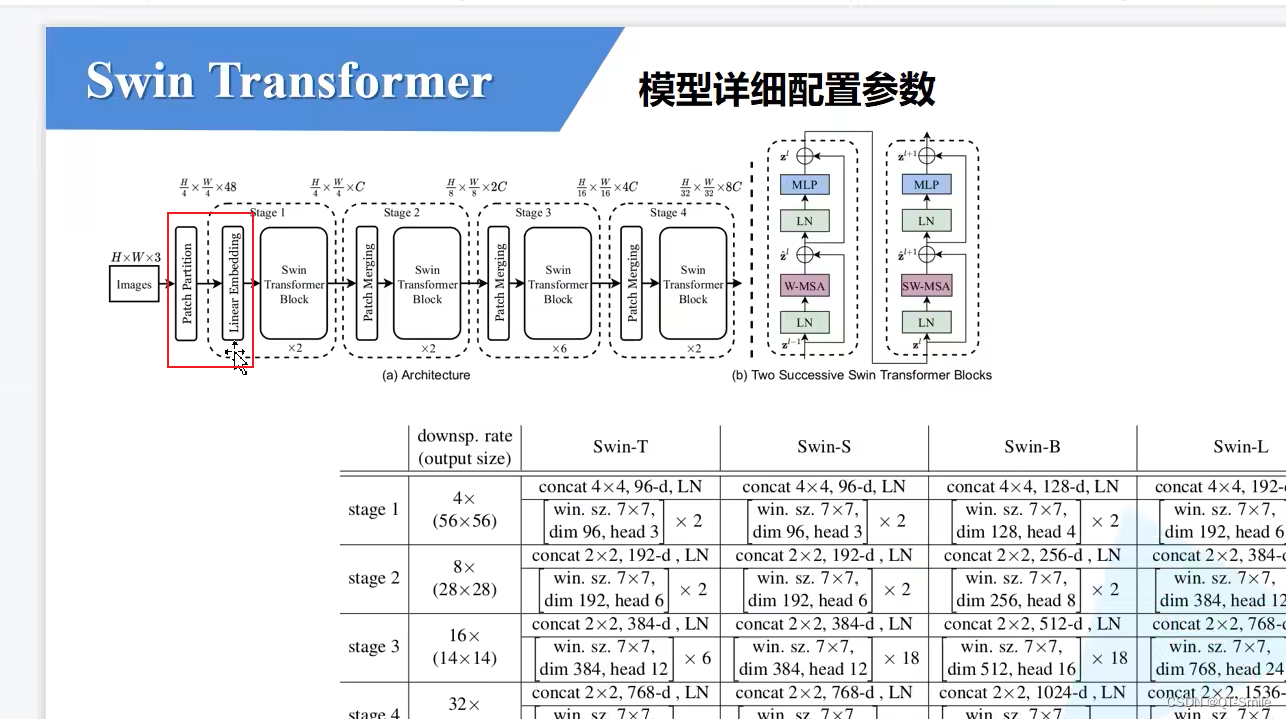

16.
Patch Partition 确实是通过一个卷积实现的
17.
在宽度方向右侧pad和在高度方向的底部pad
18.
从维度2开始展平的
19.
这儿是上文提到的第一个drop_rate直接接在patchEmbed后面
20.
针对所使用的Swin Transformer Blocks设置一个drop_path_rate。从0开始一直到drop_path_rate
21.
遍历生成每一个stage,而代码中的stage和论文中的stage有一点差异
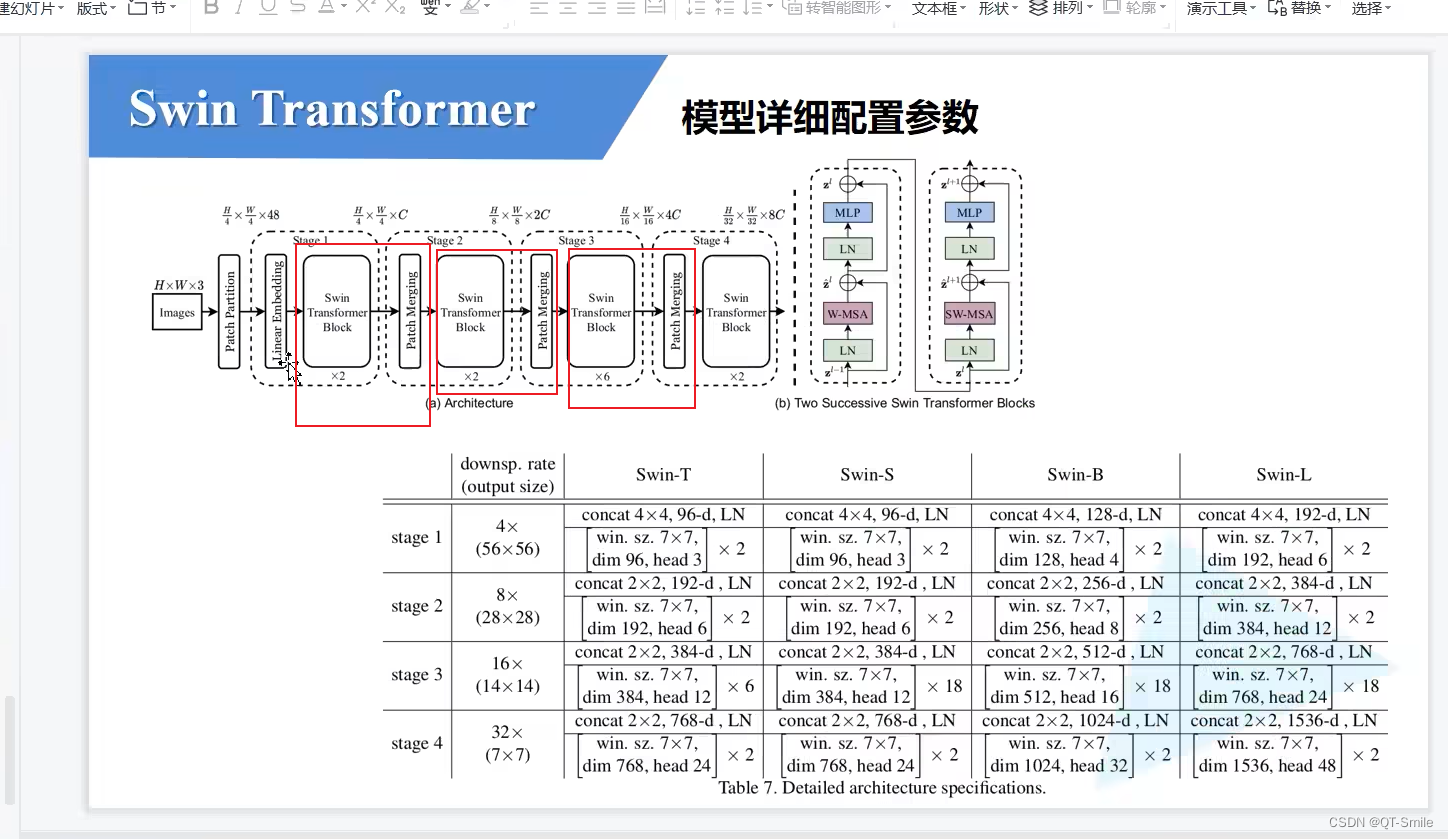
对于stage4,它没有Patch Merging,只有Swin Transformer Blocks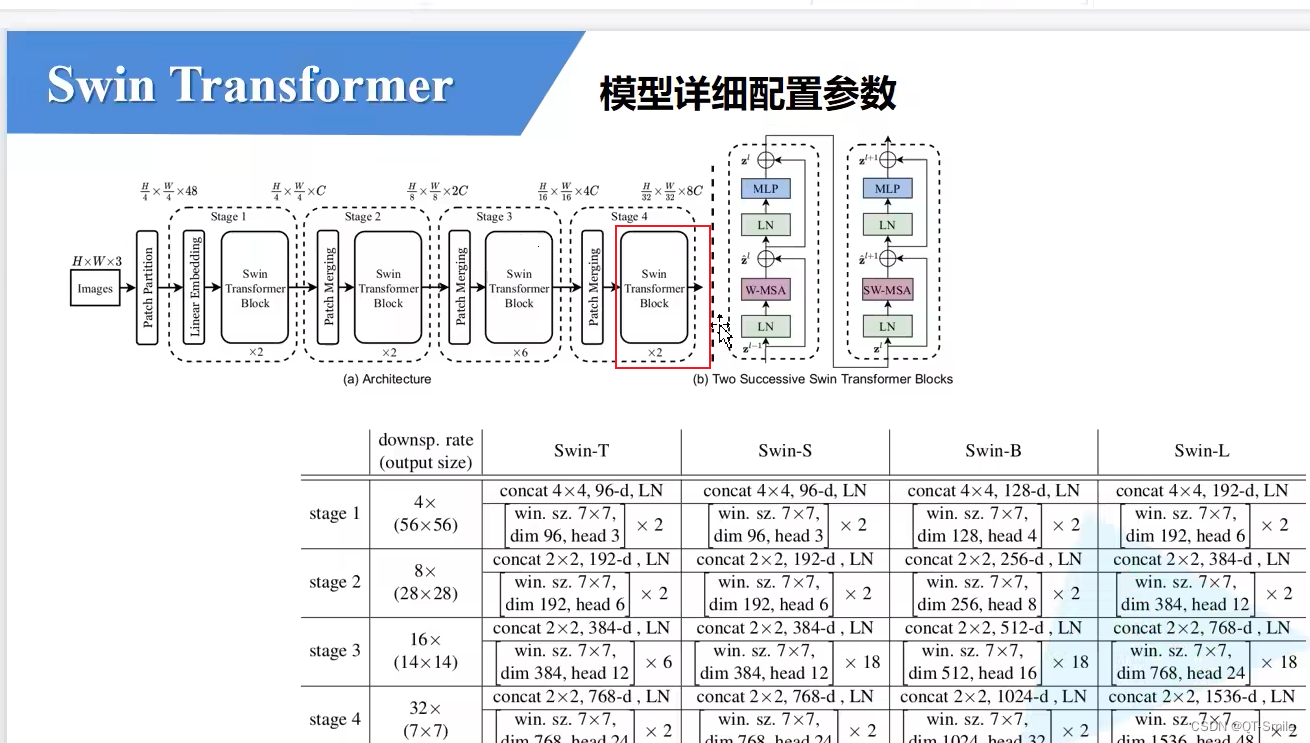
在该stage层中需要堆叠的Swin Transformer Blocks的次数
23.
drop_rate:直接接在patchEmbed后面
attn_drop:该stage所使用的
dpr:该stage中不同Swin Traansformer Blocks所使用的
24.
构建前3个stage是有PatchMerging,但是最后一个stage是没有PatchMerging
在这里self.num_layers=4
25.

26.

在下面的Patch Merging中传入的特征矩阵的shape是x: B , H*W , C这样的


28.
当x的h和w不是2的整数倍时,就需要padding,需要在右边padding一列0,在下面padding一行0。

29.
30.
31.
对于分类模型就需要加上下面这部分代码
32.
对整个模型进行权重初始化
33.
进行4倍下采样
34.
L:H*W
35.
按照一定的比例进行丢失
36.
遍历各个stage
下面的代码是在搭建Swin-T模型

Swin_T在imagenet-1k上的预训练权重
39.
Swin_B(window7_224)

Swin_B(window7_384)
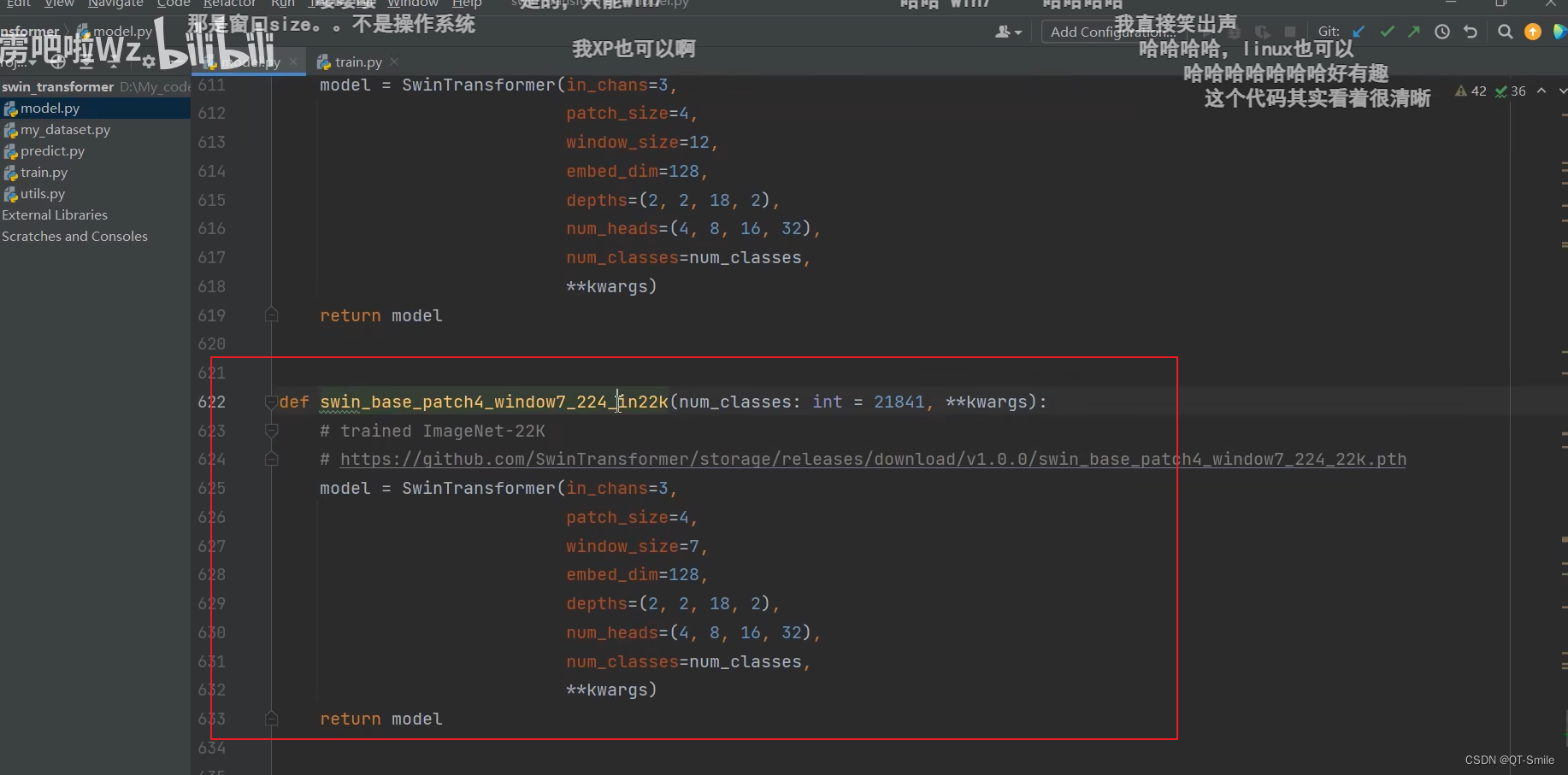

41.
原始的特征矩阵需要进行向右和向下进行移动,但是具体的向右和向下移动的距离等于:窗口的大小除以2,再向下取整

self.shift_size就是向右和向下移动的距离
42.
一个stage中的Swin Trasformer Blocks的个数
当shift_size=0:使用W-MSA
当shift_size不等于0:使用SW-MSA,shift_size = self.shift_size
44.
Swin Transformer Blocks有可能是W-MSA也有可能是SW-MSA。在使用的时候并不是把W-MSA和SW-MSA当成一个Swin Transformer Blocks
45.
depth表示下图中圈出来的数字

46.
此处的下采样是使用Patch Merging实现的
47.
这个实在SW-MSA时使用的
48.
Swin Transformer Blocks是不会改变特征矩阵的高和宽的,所以每一个SW-MSA都是一样的,所以attn_mask的大小是不会发生改变的,所以attn_mask只需要创建一次
49.
50.
这便是创建完了一个stage中的全部Swin Transformer Blocks
51.
这便是下采样Patch Merging,下采样高度和宽度会减小两倍
52.
这里的+1,是防止传入的H和W是奇数,那么就需要padding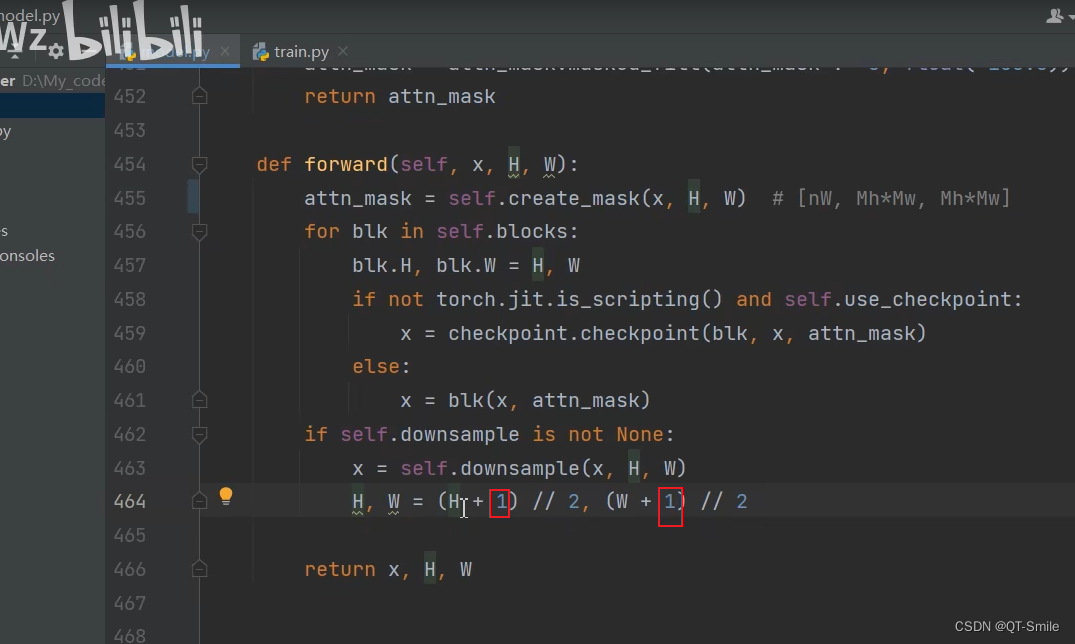

53.


54.

55.
56.


58.
59.
下面这两个x的shape是一样的

60.
边栏推荐
- calibration of sth
- 程序的动态加载和执行
- h t fad fdads
- 数据库的三大范式
- generate pivot data 0
- PostgreSQL source code (53) plpgsql syntax parsing key processes and function analysis
- [DSP video tutorial] DSP video tutorial Issue 8: performance comparison of DSP library trigonometric function, C library trigonometric function and hardware trigonometric function, and accuracy compar
- Anyone who watches "Meng Hua Lu" should try this Tiktok effect
- Servlet API
- Cookies and sessions
猜你喜欢

Batch --04--- moving components

Qcustomplot notes (I): qcustomplot adding data and curves

收藏 | 22个短视频学习Adobe Illustrator论文图形编辑和排版

Leetcode 2194. Excel 表中某个范围内的单元格(可以,已解决)

Multimix: small amount of supervision from medical images, interpretable multi task learning

ISCC-2022 部分wp

acwing 801. Number of 1 in binary (bit operation)

有哪些特容易考上的院校?

MySQL interview arrangement

Servlet API
随机推荐
Acwing 1927 automatic completion (knowledge points: hash, bisection, sorting)
The C Programming Language(第 2 版) 笔记 / 8 UNIX 系统接口 / 8.2 低级 I/O(read 和 write)
每日一题-890. 查找和替换模式
generate pivot data 1
acwing 800. Target and of array elements
Project training of Shandong University rendering engine system (V)
The C Programming Language(第 2 版) 笔记 / 8 UNIX 系统接口 / 8.3 open、creat、close、unlink
The C programming language (version 2) notes / 8 UNIX system interface / 8.7 instance (storage allocator)
\begin{algorithm} 笔记
The C programming language (version 2) notes / 8 UNIX system interface / 8.3 open, create, close, unlink
Canvas image processing (Part 1)
[fishing artifact] UI library second change lowcode tool -- List part (I) design and Implementation
Super detailed dry goods! Docker+pxc+haproxy build a MySQL Cluster with high availability and strong consistency
Differences between SQL and NoSQL of mongodb series
token与幂等性问题
并发包和AQS
Programmers broke the news: 3 job hopping in 4 years, and the salary has tripled! Netizen: the fist is hard
Understand go modules' go Mod and go sum
MySQL面试整理
generate pivot data 0