当前位置:网站首页>Shardingsphere data slicing
Shardingsphere data slicing
2022-07-26 02:37:00 【steakliu】
The yard farmer is in trouble
Persistence is a difficult thing , Persistence is not a kind of self paralysis and comfort of self deception , It's not for people , I think , The essence of persistence does not carry too much utilitarianism , If it is full of utilitarianism , Then this persistence will not last long , There will be no good harvest , Persistence should be with love , With thoughts , Take it as a habit , But it's not involution , But a kind of heartfelt love and plain ! I hope we all have our own persistence , Stick to writing an article , Insist on loving someone , Keep reading a book , Insist on going far away !
Preface
Last time we said ShardingSphere Separation of reading and writing , Using read-write separation can reduce the read-write operation of a single database , So as to improve the throughput of the database , But when the data volume of tables in the database reaches a certain amount , We may need to segment , Slicing is divided into vertical slicing and horizontal slicing , Now let's make a simple analysis of the two .
Vertical slice
We usually have many data tables in a database , But maybe our classification is not in place , Will appear The death of waterlogging and drought The situation of , For example, some data tables are read and written very frequently , And my library has a large number of such Tables with frequent read and write operations , Then the overall throughput will be reduced , And in a certain library, there are tables that are not read and written frequently , The throughput is very high ( But it seems to be useless ), So we should allocate reasonably , To ensure that the throughput of sorting reaches the maximum , The following figure divides the data tables into a database .

However, vertical fragmentation cannot fundamentally solve the bottleneck of reading and writing , Because no matter how you divide it , All the data is always concentrated in one table , Even if the performance of the database is good , It can't solve the problem . So we need to do More fine-grained segmentation , Now let's talk about horizontal segmentation .
Horizontal slice
Horizontal slicing can also be called Horizontal resolution , Is to split a large table into several small tables , For example, there is 1 Billion data , Then I split it into 10 A watch , Each table contains 1000 Ten thousand data , Then the efficiency will be higher , Some data needs to be classified and archived , Then we also need to divide the tables , Previously, a table in our system was used to store document information , For more than ten years, because of the huge amount of data , In business, you need to sort documents and other operations , Originally, the query is relatively Time consuming , Plus the need for logical processing , So it takes more time , So we divided the table , Save the data of each year into a table , This improves the query efficiency , And it is easier to track and manage data , The following is the level Fragment legend .

ShardingSphere Data fragmentation and actual combat
Use ShardingSphere Data fragmentation , We can achieve this by simply configuring ,ShardingSphere It helps us shield the underlying logic , We can also go through ShardingSphere Reserved Interface and SPI Expand our requirements , For example, we can implement our own segmentation algorithm , Primary key generation strategy, etc .
The following is a demonstration of dividing documents by year , Divide the document data into tables to 2013 - 2022 Deposit over the years , Generally, our configuration files are configured in nacos above , So it can be configured flexibly , When it comes to 2023 year , We can add a 2023 Table of years , Change nacos Configuration of , Of course , Generally, the data table will be reserved first ,nacos There is also space on it , Our is reserved until 2032 year , Set aside 10 year .
yml file
We will focus on the following configurations ,actual-data-nodes Represents the table for slicing , Use expressions ,document.document_$->{2013..2022} representative document database Below document_ The table of prefixes is partitioned , Such as document_2022,document_2021,{2013..2022} representative 2013 To 2022 This interval ,sharding-column It's a segmented column , It is a field in our data table , It is based on it to segment ,sharding-algorithms It's a slicing algorithm , We can go through SPI To achieve their own segmentation algorithm , Interface is StandardShardingAlgorithm, We use INLINE Segmentation algorithm based on row expression ,algorithm-expression Is a fragment expression ,ShardingSphere The bottom layer will parse the expression , Then slice to the corresponding data table , Our expression is document_$->{year}, In other words, it is divided according to the year , Of course , We can write expressions according to our own needs , For example, take the mold according to the primary key and divide it , We need to do it according to our actual scene , key-generate-strategy It is the primary key generation strategy ,ShardingSphere Support custom primary key generation strategies , We just need to pass SPI Can be realized , Interface is KeyGenerateAlgorithm, already Realized UUID and snowflake Snowflake algorithm Wait for the primary key generation strategy .
spring:
shardingsphere:
mode:
type: Standalone
repository:
type: File
overwrite: true
datasource:
names: document
document:
jdbc-url: jdbc:mysql://localhost:3306/document?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
username: root
password: [email protected]
rules:
sharding:
tables:
document:
actual-data-nodes: document.document_$->{2013..2022}
table-strategy:
standard:
sharding-column: year # Piecewise series
sharding-algorithm-name: document-inline # Fragment algorithm name
key-generate-strategy:
column: id # Primary key column
key-generator-name: timestamp # Primary key generation algorithm
sharding-algorithms: # Sharding algorithm
document-inline:
type: INLINE
props:
algorithm-expression: document_$->{year}
key-generators:
timestamp:
type: SNOWFLAKE
Test data segmentation
Unreal insertion ten times , Insert every time 2013 Year to 2022 Years of data .
void addDocSliceYear(){
for (int i = 0; i < 10; i++) {
for (int year = 2013; year <= 2022; year++) {
Document document = new Document()
.setDocumentName("document year【" + year + "】")
.setDocumentDetail("year【" + year + "】")
.setYear(year);
documentService.save(document);
}
}
}

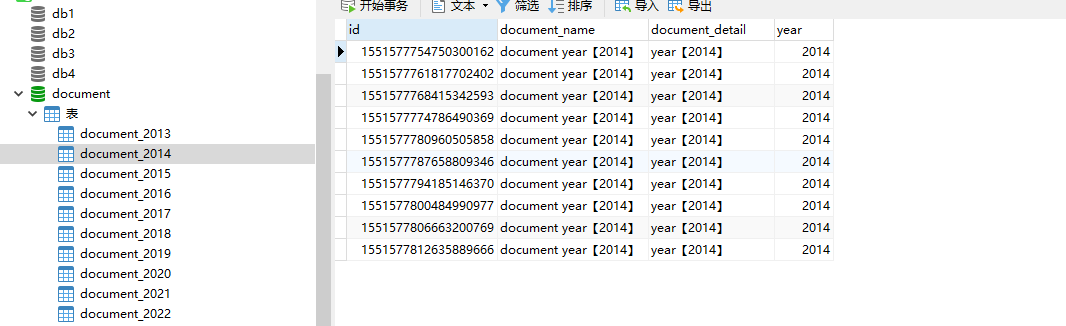
We can see that , Data fragmentation succeeded , Let's take a look at how to query fragment data ( Here is only a single table query ), Let's see ShardingSphere-SQL Output sql sentence
SELECT id,document_name,document_detail,year FROM document_2013
UNION ALL SELECT id,document_name,document_detail,year FROM document_2014
UNION ALL SELECT id,document_name,document_detail,year FROM document_2015
UNION ALL SELECT id,document_name,document_detail,year FROM document_2016
UNION ALL SELECT id,document_name,document_detail,year FROM document_2017
UNION ALL SELECT id,document_name,document_detail,year FROM document_2018
UNION ALL SELECT id,document_name,document_detail,year FROM document_2019
UNION ALL SELECT id,document_name,document_detail,year FROM document_2020
UNION ALL SELECT id,document_name,document_detail,year FROM document_2021
UNION ALL SELECT id,document_name,document_detail,year FROM document_2022
Printed from the console SQL It can be seen from the statement ,ShardingSphere Fragment query uses UNION ALL,UNION ALL Realize the two before and after SELECT Combined data , Form a result set query output , Joint query requires the same fields in each table , The field types are the same , The same number , This is also the basic requirement of slicing .
Above, we only demonstrate the data fragment query of a single table , If it's a multi table query , We need to configure binding-tables Binding table , This can reduce the Cartesian product of the query , So as to improve the query efficiency , We won't do A detailed introduction , You can check it on the official website .
Sharding algorithm
ShardingSphere There are many fragmentation algorithms , We can also implement a set of segmentation algorithm by ourselves , adopt SPI, The top interface of sharding algorithm is ShardingAlgorithm, At present, many algorithms have been implemented .
BoundaryBasedRangeShardingAlgorithm: Range partition algorithm based on partition boundary
VolumeBasedRangeShardingAlgorithm: Range slicing algorithm based on slicing capacity
ComplexInlineShardingAlgorithm: Compound slicing algorithm based on line expression
AutoIntervalShardingAlgorithm: Segmentation algorithm based on variable time range
ClassBasedShardingAlgorithm: Segmentation algorithm based on user-defined classes
HintInlineShardingAlgorithm: Based on line expression Hint Sharding algorithm
IntervalShardingAlgorithm: Segmentation algorithm based on fixed time range
HashModShardingAlgorithm: Sharding algorithm based on Hash modulo
InlineShardingAlgorithm: Segmentation algorithm based on row expression
ModShardingAlgorithm: Segmentation algorithm based on modulus
CosIdModShardingAlgorithm: be based on CosId Modulo partition algorithm
CosIdIntervalShardingAlgorithm: be based on CosId Fixed time range slicing algorithm
CosIdSnowflakeIntervalShardingAlgorithm: be based on CosId Snow of ID Fixed time range segmentation algorithm
Distributed primary key generation algorithm
ShardingSphere You can also customize the primary key generation strategy , adopt SPI, The top-level interface is KeyGenerateAlgorithm, At present, the algorithms implemented are .
SnowflakeKeyGenerateAlgorithm Distributed primary key generation algorithm based on snowflake Algorithm
UUIDKeyGenerateAlgorithm: be based on UUID Distributed primary key generation algorithm
CosIdKeyGenerateAlgorithm: be based on CosId Distributed primary key generation algorithm
CosIdSnowflakeKeyGenerateAlgorithm: be based on CosId Snowflake algorithm distributed primary key generation algorithm
NanoIdKeyGenerateAlgorithm: be based on NanoId Distributed primary key generation algorithm
summary
ShardingSphere It can easily realize data fragmentation , But data fragmentation itself is a matter of necessity , It will make our business more complicated , In the design, we need to consider strictly before data segmentation , Prevent some unnecessary trouble .
About ShardingSphere Data fragmentation , Let's talk about it , Thanks for watching , See you next time .
边栏推荐
- eslint常见报错集合
- 图解B+树的插入过程
- el-table 表头合并前四列,合并成一个单元格
- [reading notes] user portrait methodology and engineering solutions
- ES6高级-利用构造函数继承父类属性
- Prometheus + process exporter + grafana monitor the resource usage of the process
- Illustration of the insertion process of b+ tree
- 微信小程序解密并拆包获取源码教程
- Wechat applet decryption and unpacking to obtain source code tutorial
- What does the Red Cross in the SQL editor mean (toad and waterdrop have been encountered...)
猜你喜欢

Binary search 33. search rotation sort array

博云容器云、DevOps 平台斩获可信云“技术最佳实践奖”

Adruino basic experimental learning (I)

项目管理:精益管理法

What can EAM system help enterprises do?

Wechat applet - get user location (longitude and latitude + city)
U++ common type conversion and common forms and proxies of lambda
![[pure theory] Yolo v4: optimal speed and accuracy of object detection](/img/1f/f38c3b38feed9e831ad84b4bbf81c0.png)
[pure theory] Yolo v4: optimal speed and accuracy of object detection
Business Intelligence BI full analysis, explore the essence and development trend of Bi
Project management: lean management method
随机推荐
Data warehouse: Practice of hierarchical structure of data warehouse in banking industry
Manifold learning
(Dynamic Programming Series) sword finger offer 48. the longest substring without repeated characters
scipy.sparse.vstack
Yum install MySQL FAQ
案例:使用keepalived+Haproxy搭建Web群集
Illustration of the insertion process of b+ tree
AMD64(x86_64)架构abi文档:中
ShardingSphere数据分片
数仓:浅谈银行业的数仓构建实践
力扣148:排序链表
ES6高级-利用构造函数继承父类属性
npm link的简单介绍及使用
Prove that perfect numbers are even
High score technical document sharing of ink Sky Wheel - Database Security (48 in total)
The sixth day of the third question of daily Luogu
Binary search 33. search rotation sort array
What if the test / development programmer gets old? Lingering cruel facts
U++ print information to screen and log
What can EAM system help enterprises do?