当前位置:网站首页>Avenue to Jane | Comment concevoir un vit pour configurer l'auto - attraction est - il le plus raisonnable?
Avenue to Jane | Comment concevoir un vit pour configurer l'auto - attraction est - il le plus raisonnable?
2022-06-11 14:27:00 【Tom Hardy.】
Cliquez en haut“Atelier de vision informatique”,Sélectionner“Étoile”
Première livraison de marchandises sèches

Auteur 丨ChaucerG
Source 丨 collection de livres intelligents

TransformerEst devenu l'une des principales architectures de l'apprentissage profond,Surtout en tant que réseau neuronal convolutif dans la vision par ordinateur (CNN) Une alternative puissante à.Et pourtant,Parce queSelf-AttentionComplexité quadratique dans la représentation des longues séquences,En particulier pour les missions de prévision intensive à haute résolution,Travaux antérieursTransformerLa formation et le raisonnement peuvent être très coûteux.À cette fin,,Nous proposons une nouvelle vision avec moins d'attentionTransformer(LIT),Basé surTransformersMoyen et précoceSelf-AttentionToujours concentré sur le mode local,Et dans la vision stratifiée la plus procheTransformersMoins d'avantages .Plus précisément,, Une stratification est proposée
Transformer, Utiliser un perceptron multicouche pur (MLP) Codage de modèles locaux riches à un stade précoce ,Application simultanéeSelf-AttentionLes modules capturent des dépendances plus longues à des niveaux plus profonds .En outre,Un autre type deLearned Deformable Token Merging Module, Fusion adaptative non uniforme de l'informationPatch.Proposition
LITDans la tâche de reconnaissance d'image (Inclure la classification des images、Détection d'objets et Segmentation d'instances) Des performances remarquables ont été obtenues , Peut être un pilier puissant pour de nombreuses tâches visuelles .Open Source Address:https://github.com/zhuang-group/LIT
1Introduction
TransformersDans le traitement du langage naturel(NLP) Et plus récemment dans Computer Vision (CV) Des progrès considérables ont été accomplis dans ce domaine. .SousCNN Inspiration de la conception pyramidale moyenne , Convertisseur visuel stratifié le plus proche (HVT)Oui.Transformer BlockDivisé en plusieurs étapes, Et à mesure que le réseau s'approfondit, la carte des caractéristiques diminue .Et pourtant, Les premières cartes à haute résolution ont donné lieu à de longues tokenSéquence,Parce queSelf-AttentionLa complexité quadratique de, Avec des coûts de calcul énormes et une consommation de mémoire .Par exemple,La taille est56×56×96 Les caractéristiques de Multi-Head Self-Attention(MSA)Besoins moyens2.0G FLOPs,EtResNet-18 Tout le modèle de 1.8G FLOPs. Les coûts de calcul sont si élevés que Transformer Il devient très difficile de l'appliquer à un large éventail de tâches de vision par ordinateur .
InHVTLes premières étapes, Des efforts ont été faits pour réduire les coûts de calcul .Par exemple, Une partie du travail a été réduite MSAEn couchesSelf-Attention Head Le nombre de Transformer BlockNombre de. Une autre ligne de travail suggère un compromis par approximation heuristique MSA Précision et efficacité , Comme la réduction de l'attention spatiale (SRA)Et sur la baseShift Window Multi-Head Self-Attention(SW-MSA). Il y a aussi des études sur l'utilisation de couches de convolution lorsque la résolution d'une carte caractéristique est assez grande .Et pourtant,Adoption précoceSelf-Attention On ne sait toujours pas dans quelle mesure les couches contribuent au rendement Final .
Dans cet article, nous proposons Less attention Vision Transformer(LIT) Pour résoudre ce qui précède HVTQuestions.Plus précisément,, Il est recommandé de StageUtiliserMLP Couche pour saisir l'information locale , Introduction simultanée d'un nombre suffisant de HeadPour gérerMSA Dépendance à long terme à la fin de la strate .
La motivation de l'auteur vient de 2Aspects.Tout d'abord,,PrécédentCNNEtTransformerDes études pertinentes ont montré que, La couche superficielle du modèle se concentrera sur l'information locale , La profondeur tend à saisir des relations sémantiques ou globales de haut niveau , C'est ce qui s'est produit au début StageEst - il nécessaire d'utiliserSelf-AttentionLa question de.Deuxièmement,, D'un point de vue théorique , Un avec assez de HeadDeSelf-Attention L'application à l'image peut représenter n'importe quel rouleau .
Et pourtant,MSA Moins dans la couche Head Théoriquement, l'approximation est bloquée avec de grandes kernel-size Capacité d'enroulement , Où les extrêmes sont 1×1Convolution Tout aussi expressif. , Peut être considéré comme une norme appliquée indépendamment à chaque pixel FCCouche.Bien que récemmentHVT Peu de Head Pour fournir une représentation pyramidale , Mais l'auteur pense que ce n'est pas optimal , Parce qu'une telle configuration entraîne des coûts de calcul et de mémoire élevés , Mais les avantages sont minimes. .
Il convient de souligner que, Par le biais de StageUtilisationMLP BlockPeut être évitéSelf-Attention Coûts de calcul importants et empreinte mémoire générée sur les cartes à haute résolution .En outre,À un stade ultérieurStageApplicationSelf-Attention Pour saisir les dépendances distantes .Les résultats expérimentaux montrent que, Une architecture aussi simple permet un équilibre optimal entre la performance et l'efficacité du modèle .
En outre,Le plus procheHVT Ou utiliser un rouleau standard , Soit une couche de projection linéaire est utilisée pour fusionner les Token, Conçu pour contrôler l'échelle des cartes de caractéristiques .Et pourtant, Considérant que la contribution de chaque pixel à l'unit é de sortie n'est pas la même , Cette approche a entravé Vision Transformer Représentation de la modélisation des transformations géométriques .
À cette fin,, L'auteur propose un Deformable ConvolutionsInspiréDeformable Token Merging(DTM) Module,Dans ce module, Une grille offset a été apprise pour augmenter de façon adaptative la position de l'échantillon spatial , Ensuite, les voisins des sous - fenêtres du diagramme caractéristique sont fusionnés Patch. De cette façon, vous pouvez obtenir plus d'informations sur l'échantillonnage descendant TokenPour traitement ultérieur.
Principales contributions:
Tout d'abord,, Les premiers
MSALa couche est la plus procheHVTPetite contribution à , Et au début StageUn simpleHVTStructure, Il contientMLP Block;Deuxièmement,,J'ai proposé
Deformable Token MergingModule, Pour fusionner plus d'informations de manière adaptativePatchPour fournir une représentation hiérarchique , Avec des capacités de modélisation améliorées ;Enfin,Des expériences approfondies ont été menées, Pour indiquer ce qui a été proposé
LITEfficacité dans le calcul de la complexité et de la consommation de mémoire .
2Méthode de cet article
2.1 Structure générale

LITL'architecture globale de1Comme indiqué. Définir comme entrée RGBImages,Parmi euxHEtWIndique respectivement la hauteur et la largeur.D'abordI Diviser en non - chevauchement Patch,PatchLa taille est4×4,Donc chaquePatch La dimension caractéristique initiale de 4×4×3=48.
Et puis..., Chaque Patch Projeter dans les dimensions , Utilisé comme entrée initiale pour la procédure suivante . L'ensemble du modèle est divisé en 4- Oui.Stage.Jeans∈[1,2,3,4] En tant queStageIndex de,Dans chaqueStage Utilisez Block,Dont avant2- Oui.StageUtiliser uniquementMLP Block Pour encoder des informations locales ,Les deux derniersStageCritères d'utilisationTransformer Block Pour coder des dépendances plus longues .
Dans chaqueStage, Zoomer le diagramme de fonction d'entrée vers , Où et représentent respectivement s- Oui.Stage Taille du bloc et dimensions cachées pour .Pour la dernière2- Oui.Stage,Dans chaqueTransformer Block Set in Self-Attention heads.
2.2 LITDansBlockConception
Comme le montre la figure1Comme indiqué,LITAdoption2Types de modules:MLPModules etTransformerModule.Au débutStageApplicationMLP Block.Plus précisément,,MLP BlockFondé surMLPAu - dessus de,LeMLPPar2- Oui.FCComposition des couches,Il y aGELU.Pour la sections Chaque étape MLP, Rapport d'extension utilisé .
Plus précisément,,No1- Oui.FCLa couchetoken La dimension de ,L'autre.FC La couche réduit la dimension à .Formellement, Ordonnance no sContribution à la phase,l Index des blocs ,MLP BlockPeut être exprimé comme suit::

Parmi euxLN Normalisation de la couche de présentation .Dans la phase finale,ViTDécrit dansTransformer BlockContient unMSACouche et unMLP,Peut être exprimé comme suit::

L'utilisation de cette architecture 2 Principaux avantages :
Tout d'abord,, Évitez les premiers Stage Coûts de calcul énormes et empreinte mémoire introduite par de longues séquences ;
Deuxièmement,, Contrairement à l'utilisation récente de sous - fenêtres pour réduire les cartes d'attention ou réduire les cartes d'attention keyEtvalue Sur la dimension spatiale de la matrice ,A la fin2- Oui.Stage Normes de conservation
MSACouche,Pour maintenirLIT Capacité de gérer les dépendances à distance .
Remarques
En considérant Couche de convolution、FCCoucheEtMSACouche La relation entre les deux pour prouver qu'au début Stage Application pure MLP BlockLe caractère raisonnable.
Il est recommandé ici de se référer à la nouvelle sortie récente de Byte Jump TRT-ViT, Avec des conclusions correspondantes , En même temps, des critères très détaillés de conception du modèle sont donnés , Les liens vers les tweets correspondants sont les suivants: :
Tout d'abord,, En commençant par un examen des rouleaux standard . Faire un diagramme de caractéristiques d'entrée , Pour le poids de convolution ,Parmi euxKPourKernel-size, Et sont les dimensions des canaux d'entrée et de sortie respectivement .Par souci de simplicité,L'élément offset a été omis, Et en indiquant ,Parmi eux(i,j) Représente l'index des pixels ,.Compte tenu deK×K Noyau de convolution des emplacements d'échantillonnage ,Pixelsp La sortie de :

Où est l'indice d'échantillonnage à l'offset prédéterminé ΔK Double cartographie de .
Par exemple,OrdreΔK={(−1,−1),(−1,0),...,(0,1),(1,1)}Pour3×3Dekernel,Le taux d'expansion est de1,Etg(0)=(-1,-1)Indique le paragraphe1 Offset d'échantillonnage .QuandK=1Heure, Tenseur de poids W Équivalent à une matrice ,De faire$.Dans ce cas,,Eq(4)Peut être représentéFCCouche,Pixelsp La sortie de est définie comme :

Enfin, Laisse - le. MSADans la coucheHeadNombre,$Oui.h- Oui.HeadParamètres d'apprentissage pour. Sous un schéma de codage de position relative spécifique ,Cordonnier Et d'autres ont prouvé que les pixels pDeMSACouche La sortie de :

Il y aHead Double cartographie du déplacement des pixels .Dans ce cas,,Eq(6)Peut être considéré commeKernel-sizePour L'approximation de la couche enroulée de .
DeEqs(4)-(6)Observations, Bien qu'il y ait suffisamment de HeadDeMSA Les couches peuvent approcher n'importe quelle couche de convolution , Mais moins en théorie Head Limite la capacité de cette approximation . Comme cas extrême ,Avec unHeadDeMSA Les couches ne peuvent s'approcher que FCCouche.
Votre attention, s'il vous plaît.,MSA .En pratique, les couches ne sont certainement pas équivalentes aux laminations .Et pourtant,d'Ascoli Et d'autres ont observé ,Les premiersMSA Les couches peuvent apprendre des représentations similaires de la convolution pendant l'entraînement . Considérez le plus récent HVTAu débutStage Avec peu de Head, Ce comportement de convolution peut être limité à de petits champs de sensation .

Dans la figure3Moyenne, Afficher dans la visualisation PVT-S Au début de MSA La couche ne se concentre vraiment que sur query Une petite zone autour des pixels , Et leur suppression entraînerait une légère dégradation des performances , .Mais cela réduit considérablement la complexité du modèle . Ça prouve qu'avant 2- Oui.stage Application pure MLP BlockC'est raisonnable..
2.3 Deformable Token Merging
Précédemment sur HVT Le travail dépend dePatch Merge Pour réaliser la représentation pyramidale des caractéristiques .Et pourtant, Fusionner à partir de la grille des règles Patch, Et ignore que ce n'est pas tous Patch Le fait que la contribution à l'unité de sortie soit la même . Inspiré par la convolution déformable ,J'ai proposéDeformable Token Merging Module pour apprendre la grille offset , Pour échantillonner de façon adaptative plus de blocs d'information .Formellement, La Convolution déformable est exprimée comme suit: :

AvecEq(4) Comparaison des opérations de convolution standard dans ,DC Pour chaque décalage prédéterminé g(k) Apprendre un décalage Δg(k).ApprendreΔg(k) Nécessite une couche de convolution séparée , Il s'applique également aux diagrammes de caractéristiques d'entrée X. Pour fusionner de façon adaptative Patch,InDTM Un dans le module DCCouche,Peut être exprimé comme suit::

Parmi eux BN Représente la normalisation des lots ,Et utilisé GELU.
Dans les études d'ablation, Quand la taille et la forme de l'objet changent ,DTM La position de l'échantillon est ajustée de façon adaptative , Pour bénéficier de l'offset appris .Veuillez également noter,AvecBaseline Échantillonnage en grille régulière comparé à ,LégerDTM Introduit un FLOPEt paramètres, Donc C'est le plus récent HVT Module plug - and - play pour .
3L'expérience
3.1 Expérience d'ablation
1、Effect of the architecture design

Les résultats sont présentés dans le tableau ci - dessous. 2 Comme indiqué.En général,LIT En utilisant moins FLOP(3.6G Avec 3.8G)En même temps,Oui.PVT-SDeTop-1Précision accrue0.6%.PourSwin-TiOui. FLOPs Diminution0.4G, Performances équivalentes .
Il est également intéressant de noter que,PVT-S Et Swin-Ti Réduction du nombre total de paramètres pour . Le rendement global démontre l'efficacité de l'architecture proposée , Cela souligne également les premiers MSAInPVTEtSwin Un petit avantage dans .
2、Effect of deformable token merging

Les résultats sont présentés dans le tableau ci - dessous. 3 Comme indiqué.Pour cela2Modèles,DTM Introduit un FLOP Et paramètres,En même temps Top-1 Les aspects de précision seront PVT-S Et Swin-Ti Amélioration 0.7% Et 0.3%.

En outre,Dans la figure 2 Le décalage appris est visualisé dans .Comme le montre la figure, Avec l'unification précédente Patch MergeLes stratégies sont différentes, Avant l'unification Patch Merge La politique limite les emplacements d'échantillonnage à un rectangle vert ,DTM Selon l'échelle et la forme de l'objet (Par exemple, Les jambes de Koala 、 Queue de chat ). Cela souligne une fois de plus LIT La capacité de s'adapter à diverses transformations géométriques .
3、Effect of MSA in each stage
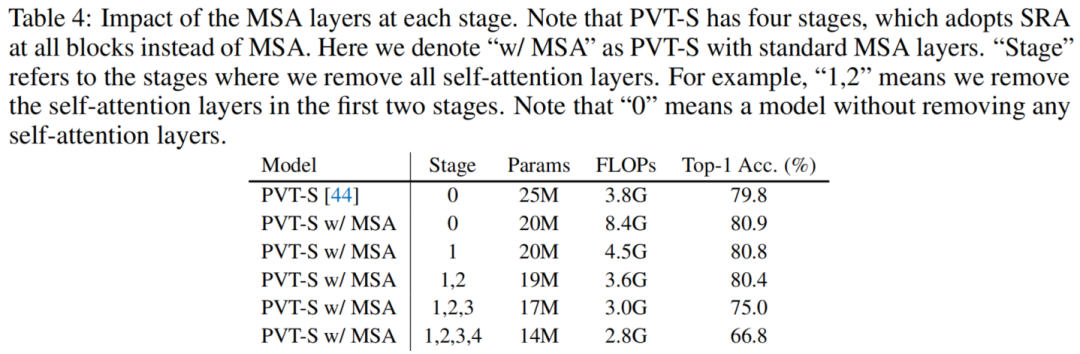
Les résultats sont présentés dans le tableau ci - dessous.4Comme indiqué.Tout d'abord,, Norme en service MSARemplacement des couchesPVT-SDansSRACouche postérieure,Observations Top-1 Précision accrue 1.1%,EtFLOPsPresque doublé.Ça veut direPVT Il y a un compromis entre le rendement et l'efficacité .
Et puis..., En passant devant 2 Étape par étape MSACouche,Top-1 La précision n'a diminué que séparément 0.1%、0.5%.Cela signifie PVT Au début self-attention La contribution des couches au rendement final est inférieure aux attentes , Et leur performance n'est pas plus pure que MLP Combien de couches . Cela peut être attribué au fait que les couches superficielles se concentrent davantage sur le codage de l'information locale. .
Et pourtant, On peut observer qu'à la fin 2 Étape (s) enlevée (s) self-attention Les performances temporelles diminuent considérablement .Les résultats montrent que,self-attention Les couches jouent un rôle important à un stade ultérieur , Capture de la dépendance à longue distance pour une vision stratifiée performante TransformerEssentiel.

Pour mieux comprendre ce phénomène, Sans enlever MSA Visualisation des couches PVT-S La probabilité d'attention ,Comme le montre la figure3Comme indiqué.Tout d'abord,,No1 Affichage de la carte d'attention de la phase query Les pixels remarquent à peine les autres positions .
En2Phase,query Le champ de perception des pixels s'est légèrement élargi , Mais avec la 1 Les étapes sont similaires .Considérant quePVT-SEn1Phase seulement1- Oui.head,En2Phase seulement2- Oui.head, Cela confirme fortement l'hypothèse de l'auteur :MSA Trop peu dans la couche head Cela conduit à des champs sensoriels plus petits ,En ce momentself-attentionPresque équivalent àFCCouche.
En outre,De la fin2 Des champs sensoriels relativement grands ont été observés dans les cartes d'attention à différents stades. . Parce que les grands champs réceptifs aident souvent à modéliser des dépendances plus longues , Ça explique qu'à la fin 2 Étape (s) enlevée (s) MSA Table arrière 4 Réduction significative des performances .
3.2 Classification

3.3 Détection des cibles

3.4 Segmentation des instances

3.5 Segmentation sémantique

4RÉFÉRENCES
[1].Less is More: Pay Less Attention in Vision Transformers
Cet article n'est destiné qu'au partage académique,En cas d'infraction,Veuillez contacter delete.
Téléchargement de marchandises sèches et apprentissage
Retour en arrière - plan:BarceloneC'est...Didacticiels de l'Université autonome,Télécharger les dépôts universitaires à l'étranger pendant plusieurs années3D VisonExcellent didacticiel
Retour en arrière - plan:Vision par ordinateurLes livres,Disponible en téléchargement3DLivres classiques dans le domaine visuelpdf
Retour en arrière - plan:3DCours de vision,Pour apprendre3DCours de qualité dans le domaine de la vision
Site officiel de l'atelier de vision informatique:3dcver.com
1.Technologie de fusion de données multi - capteurs pour la conduite automatique
2.Pour la conduite automatique3DPiste d'apprentissage de la pile complète pour la détection d'objets en nuage ponctuel!(Mode unique+Multimodal/Données+Code)
3.Reconstruction 3D complète de la vision:Analyse des principes、Explication du Code、Optimisation et amélioration
4.Le premier cours de traitement en nuage point au niveau industriel en Chine
5.Laser-La vision-IMU-GPSIntégrationSLAMTri des algorithmes et explication du Code
6.Comprendre complètement la vision-InertieSLAM:Basé surVINS-FusionC'est officiel.
7.Comprendre complètement la baseLOAMCadre3DLaserSLAM: Analyse du code source à l'optimisation de l'algorithme
8.Analyse approfondie de la pièce、Laser extérieurSLAMPrincipe de l'algorithme clé、Code et pratique(cartographer+LOAM +LIO-SAM)
10.Méthode d'estimation de la profondeur monoculaire:Tri des algorithmes et mise en œuvre du Code
11.Déploiement d'un modèle d'apprentissage profond dans la conduite automatique
12.Modèle de caméra et étalonnage(Monoculaire+Binoculaire+Fisheye)
13.Poids lourd!Véhicule à quatre rotors:Algorithme et combat réel
14.ROS2De l'initiation à la maîtrise:Théorie et pratique
15.Le premier3DTutoriel de détection des défauts:Théorie、Code source et combat réel
Poids lourd!Atelier de vision informatique-ApprendreGroupe ACCréé
Numériser le Code pour ajouter un petit assistant Wechat,Peut demander l'adhésion3DAtelier visuel-Rédaction et contribution de documents universitaires Groupe de communication Wechat,Conçu pourRéunion de haut niveau sur la communication、Haut de la page、SCI、EIQuestions relatives à la rédaction et à la contribution.
En même tempsVous pouvez également demander à rejoindre notre groupe de communication directionnelle,Actuellement, il y a principalementORB-SLAMSérie d'apprentissage des sources、3DLa vision、CV&Apprentissage profond、SLAM、Reconstruction 3D、Point Cloud post - traitement、Conduite automatique、CVIntroduction、Mesure tridimensionnelle、VR/AR、3DReconnaissance faciale、Imagerie médicale、Détection des défauts、Reconnaissance des piétons、Suivi des cibles、Produits visuels au sol、Concours de vision、Reconnaissance des plaques d'immatriculation、Sélection du matériel、Estimation de la profondeur、Échanges universitaires、Échanges de recherche d'emploiGroupe isowechat,.S'il vous plaît, Scannez le micro - signal ci - dessous et groupez,Remarques:”Orientation de la recherche+L'école/Entreprises+Un surnom.“,Par exemple:”3DLa vision + Shanghai Jiaotong University + Silence.“.Veuillez noter selon le format,Sinon, il ne passera pas.Une fois l'ajout réussi, les groupes Wechat pertinents seront invités en fonction de l'orientation de la recherche.Contributions originalesVeuillez également contacter.

▲Presse longue plus Groupe Wechat ou contribution
▲Appuyez sur le bouton "attention au public"
3DLa vision passe de l'initiation à la maîtrise de la planète de la connaissance:Pour3DDans le domaine visuelCours de vidéoCheng(Série de reconstruction 3D、Série de nuages ponctuels 3D、Série de lumière structurée、Étalonnage main - oeil、Étalonnage de la caméra、Laser/La visionSLAM、AutomatiqueConduite, etc.)、Résumé des points de connaissance、Parcours d'apprentissage avancé d'entrée、Mise à jourpaperPartager、Réponses aux questionsCinq aspects du travail profond du sol,En outre, les ingénieurs d'algorithmes de toutes sortes de grandes usines fournissent des conseils techniques.En même temps,,Planet sera publié conjointement avec des entreprises bien connues3DInformation sur le poste de développement d'algorithmes visuels et l'amarrage des projets,Créer une zone de rassemblement de fans de fer intégrant la technologie et l'emploi,Proche4000Les membres de la planète créent de meilleuresAIProgrès communs dans le monde,Portail de la planète de la connaissance:
Apprendre3DTechnologie de base de la vision,Aperçu de la numérisation,3Remboursement inconditionnel dans les jours
Il y a des tutoriels de haute qualité dans le cercle、Répondre aux questions et répondre aux questions、Vous aider à résoudre vos problèmes efficacement
J'ai trouvé ça utile.,Un compliment, s'il vous plaît.~
边栏推荐
- Seven parameters of thread pool and reject policy
- 树莓派知识大扫盲
- Sqlmap detection SQL lab range
- mysql高级语句
- Is bone conduction earphone good for bone? Is bone conduction earphone harmful to the body?
- YOLOv3学习笔记:YOLOv3的模型结构
- Individual income tax rate table
- 【Try to Hack】URL
- one hundred and twenty-three thousand four hundred and sixty-five
- Leetcode 1968. Construct an array whose elements are not equal to the average value of two adjacent elements (yes, finally solved)
猜你喜欢
Airtest automated test

Cartoon: interesting "cake cutting" problem

HMS core shows the latest open capabilities in mwc2022, helping developers build high-quality applications

Live800:智能客服提升客户体验的几种方式

IC fresh Chinese cabbage price of 400000 yuan! Experienced experts who have worked for many years guide you how to choose an offer!

【Try to Hack】URL

NoSQL之Redis配置与优化

mysql创建表出错1067 - Invalid default value for ‘update_time‘
Live800: several ways for intelligent customer service to improve customer experience

AGV robot RFID sensor ck-g06a and Siemens 1200plc Application Manual
随机推荐
In depth research and analysis report on global and Chinese diet food market
gensim. Models word2vec parameter
Is the brokerage account given by qiniu business school safe? Do you charge for opening an account
I have something to say about final, finally and finalize
CVPR 2022 | 神经辐射场几何编辑方法NeRF-Editing
[pyhton crawler] regular expression
How to manually package your own projects
【Try to Hack】URL
你违规了吗?
Live800: several ways for intelligent customer service to improve customer experience
C language learning record 6
Work summary: it took a long time to write SQL because of Cartesian product problem (Cartesian product summary attached)
gensim.models word2vec 参数
Global and China dynamic light scattering nano laser particle sizer market depth research and Analysis Report
Cartoon: interesting "cake cutting" problem
leetcode每日一题——搜索插入位置
SQL must know and know
YOLOv3学习笔记:YOLOv3的模型结构
2022.2.26 library management system 2 - module 2: reader management system
mysql创建表出错1067 - Invalid default value for ‘update_time‘