当前位置:网站首页>[AMEX] LGBM Optuna美国运通信用卡欺诈赛 kaggle
[AMEX] LGBM Optuna美国运通信用卡欺诈赛 kaggle
2022-08-01 00:00:00 【人工智能曾小健】
竞赛描述:
无论是在餐厅外出还是购买音乐会门票,现代生活都依靠信用卡的便利进行日常购物。它使我们免于携带大量现金,还可以提前全额购买,并且可以随着时间的推移支付。发卡机构如何知道我们会偿还所收取的费用?这是许多现有解决方案的复杂问题,甚至更多潜在的改进,有待在本次比赛中进行探索。
信用违约预测是管理消费贷款业务风险的核心。信用违约预测允许贷方优化贷款决策,从而带来更好的客户体验和稳健的商业经济。当前的模型可以帮助管理风险。但是有可能创建更好的模型,这些模型的性能优于当前使用的模型。
美国运通是一家全球综合支付公司。作为世界上最大的支付卡发行商,他们为客户提供丰富生活和建立商业成功的产品、见解和体验。
在本次比赛中,您将运用机器学习技能来预测信用违约。具体来说,您将利用工业规模的数据集来构建机器学习模型,以挑战生产中的当前模型。训练、验证和测试数据集包括时间序列行为数据和匿名客户档案信息。您可以自由探索任何技术来创建最强大的模型,从创建特征到在模型中以更有机的方式使用数据。
如果成功,您将更容易获得信用卡批准,从而帮助为持卡人创造更好的客户体验。顶级解决方案可能会挑战世界上最大的支付卡发行商使用的信用违约预测模型——为您赢得现金奖励、接受美国运通公司采访的机会,以及可能获得回报的新职业。
数据描述:
本次比赛的目的是根据客户每月的客户资料预测客户未来不偿还信用卡余额的概率。目标二元变量是通过观察最近一次信用卡账单后 18 个月的绩效窗口来计算的,如果客户在最近一次账单日后的 120 天内未支付到期金额,则将其视为违约事件。
该数据集包含每个客户在每个报表日期的汇总配置文件特征。特征是匿名和规范化的,分为以下一般类别:
D_* = 拖欠变量 Delinquency variables
S_* = 支出变量 Spend variables
P_* = 付款变量 Payment variables
B_* = 平衡变量Balance variables
R_* = 风险变量 Risk variables
具有以下分类特征:
['B_30'、'B_38'、'D_114'、'D_116'、'D_117'、'D_120'、'D_126'、'D_63'、'D_64'、'D_66'、'D_68']
您的任务是为每个 customer_ID 预测未来付款违约的概率(目标 = 1)。
请注意,该数据集的负类已被二次抽样为 5%,因此在评分指标中获得了 20 倍的权重。

提交格式:
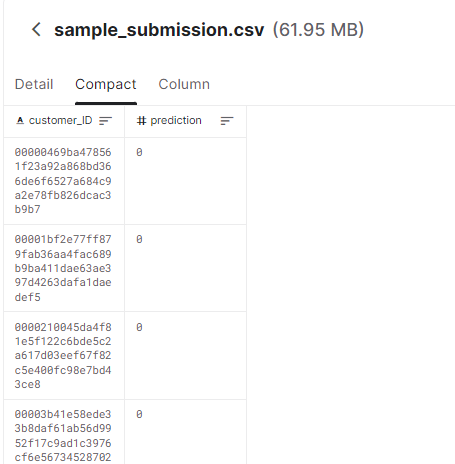
LGBM Optuna Starter
This notebook shows how to use Optuna in LGBM Models to automate hyper parameter searching.
References
(1) AMEX data - integer dtypes - parquet format | Kaggle
(2) XGBoost Starter - [0.793] | Kaggle
(3) American Express - Default Prediction | Kaggle
# LOAD LIBRARIES
import pandas as pd, numpy as np # CPU libraries
import cupy, cudf # GPU libraries
import matplotlib.pyplot as plt, gc, os
print('RAPIDS version',cudf.__version__)![]()
# VERSION NAME FOR SAVED MODEL FILES
VER = 1
# TRAIN RANDOM SEED
SEED = 42
# FILL NAN VALUE
NAN_VALUE = -127 # will fit in int8
# FOLDS PER MODEL
FOLDS = 5流程和特征工程师训练数据
我将使用 XGBoost 入门笔记本(2)中介绍的功能和数据预处理方法
我们将从此处加载@raddar Kaggle 数据集并在此处进行讨论。然后我们将在此处和此处的笔记本中设计@huseyincot 建议的功能。我们将使用 RAPIDS 和 GPU 快速创建新功能。
def read_file(path = '', usecols = None):
# LOAD DATAFRAME
if usecols is not None: df = cudf.read_parquet(path, columns=usecols)
else: df = cudf.read_parquet(path)
# REDUCE DTYPE FOR CUSTOMER AND DATE
df['customer_ID'] = df['customer_ID'].str[-16:].str.hex_to_int().astype('int64')
df.S_2 = cudf.to_datetime( df.S_2 )
# SORT BY CUSTOMER AND DATE (so agg('last') works correctly)
#df = df.sort_values(['customer_ID','S_2'])
#df = df.reset_index(drop=True)
# FILL NAN
df = df.fillna(NAN_VALUE)
print('shape of data:', df.shape)
return dfdef process_and_feature_engineer(df):
# FEATURE ENGINEERING FROM
# https://www.kaggle.com/code/huseyincot/amex-agg-data-how-it-created
all_cols = [c for c in list(df.columns) if c not in ['customer_ID','S_2']]
cat_features = ["B_30","B_38","D_114","D_116","D_117","D_120","D_126","D_63","D_64","D_66","D_68"]
num_features = [col for col in all_cols if col not in cat_features]
test_num_agg = df.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last'])
test_num_agg.columns = ['_'.join(x) for x in test_num_agg.columns]
test_cat_agg = df.groupby("customer_ID")[cat_features].agg(['count', 'last', 'nunique'])
test_cat_agg.columns = ['_'.join(x) for x in test_cat_agg.columns]
df = cudf.concat([test_num_agg, test_cat_agg], axis=1)
del test_num_agg, test_cat_agg
print('shape after engineering', df.shape )
return dfprint('Reading train data...')
TRAIN_PATH = '../input/amex-data-integer-dtypes-parquet-format/train.parquet'
train = read_file(path = TRAIN_PATH)
train = process_and_feature_engineer(train)![]()
targets = cudf.read_csv('../input/amex-default-prediction/train_labels.csv')
targets['customer_ID'] = targets['customer_ID'].str[-16:].str.hex_to_int().astype('int64')
targets.index = targets['customer_ID'].sort_index()
targets = targets.drop('customer_ID', axis=1)
train = train.join(targets,on =['customer_ID'] ).sort_index()
del targets
gc.collect()
# NEEDED TO MAKE CV DETERMINISTIC (cudf merge above randomly shuffles rows)
train = train.sort_index().reset_index()
# FEATURES
FEATURES = train.columns[1:-1]Faster metric Implementation
def amex_metric(y_true: np.array, y_pred: np.array) -> float:
# count of positives and negatives
n_pos = y_true.sum()
n_neg = y_true.shape[0] - n_pos
# sorting by descring prediction values
indices = np.argsort(y_pred)[::-1]
preds, target = y_pred[indices], y_true[indices]
# filter the top 4% by cumulative row weights
weight = 20.0 - target * 19.0
cum_norm_weight = (weight / weight.sum()).cumsum()
four_pct_filter = cum_norm_weight <= 0.04
# default rate captured at 4%
d = target[four_pct_filter].sum() / n_pos
# weighted gini coefficient
lorentz = (target / n_pos).cumsum()
gini = ((lorentz - cum_norm_weight) * weight).sum()
# max weighted gini coefficient
gini_max = 10 * n_neg * (1 - 19 / (n_pos + 20 * n_neg))
# normalized weighted gini coefficient
g = gini / gini_max
return 0.5 * (g + d)
def lgb_amex_metric(y_true, y_pred):
return ('Score',
amex_metric(y_true, y_pred),
True)import datetime
import warnings
import gc
import pickle
import sklearn
from sklearn.model_selection import StratifiedKFold, train_test_split
import lightgbm as lgb使用 Optuna 进行超参数调整
import optuna
train_pd = train.to_pandas()
del train
gc.collect()train_df, test_df = train_test_split(train_pd, test_size=0.25, stratify=train_pd['target'])
del train_pd
gc.collect()X_train = train_df.drop(['customer_ID', 'target'], axis=1)
X_test = test_df.drop(['customer_ID', 'target'], axis=1)
y_train = train_df['target']
y_test = test_df['target']
del train_df, test_df
gc.collect()# 1. Define an objective function to be maximized.
def objective(trial):
dtrain = lgb.Dataset( X_train, label=y_train)
# 2. Suggest values of the hyperparameters using a trial object.
param = {
'objective': 'binary',
'metric': 'binary_logloss',
'seed' : 42,
'lambda_l1': trial.suggest_float('lambda_l1', 1e-8, 10.0, log=True),
'lambda_l2': trial.suggest_float('lambda_l2', 1e-8, 10.0, log=True),
'num_leaves': trial.suggest_int('num_leaves', 2, 256),
'feature_fraction': trial.suggest_float('feature_fraction', 0.1, 1.0),
'bagging_fraction': trial.suggest_float('bagging_fraction', 0.1, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 1, 7),
'min_data_in_leaf': trial.suggest_int('min_child_samples', 5, 100),
'learning_rate': trial.suggest_float('learning_rate', 0.001, 0.05, step=0.001),
'device' : 'gpu',
"verbosity": -1,
}
gbm = lgb.train(param, dtrain)
preds = gbm.predict(X_test)
pred_labels = np.rint(preds)
accuracy = sklearn.metrics.accuracy_score(y_test, pred_labels)
return accuracy边栏推荐
- 博弈论(Depu)与孙子兵法(42/100)
- SQL注入 Less42(POST型堆叠注入)
- 一行代码解决CoreData托管对象属性变更在SwiftUI中无动画效果的问题
- date命令
- thymeleaf iterates the map collection
- [QNX Hypervisor 2.2用户手册]9.16 system
- 一文概述:VPN的基本模型及业务类型
- Recommendation system: Summary of common evaluation indicators [accuracy rate, precision rate, recall rate, hit rate, (normalized depreciation cumulative gain) NDCG, mean reciprocal ranking (MRR), ROC
- EntityFramework保存到SQLServer 小数精度丢失
- 【云驻共创】【HCSD大咖直播】亲授大厂面试秘诀
猜你喜欢
什么是客户画像管理?
/etc/sysconfig/network-scripts configure the network card
网易云信圈组上线实时互动频道,「破冰」弱关系社交
Shell common script: Nexus batch upload local warehouse script

什么是动态规划,什么是背包问题

NIO programming

How to Design High Availability and High Performance Middleware - Homework

Daily--Kali opens SSH (detailed tutorial)
数据分析(一)——matplotlib

SVN server construction + SVN client + TeamCity integrated environment construction + VS2019 development
随机推荐
vim的基本使用-底行模式
基于simulink的Passive anti-islanding-UVP/OVP and UFP/OFP被动反孤岛模型仿真
【1161. 最大层内元素和】
Flutter教程之 02 Flutter 桌面程序开发入门教程运行hello world (教程含源码)
Pytest first experience
How to Design High Availability and High Performance Middleware - Homework
无状态与有状态的区别
Flutter教程之四年开发经验的高手给的建议
NIO编程
不知道该怎么办的同步问题
SVN服务器搭建+SVN客户端+TeamCity集成环境搭建+VS2019开发
【Acwing】第62场周赛 题解
IJCAI2022 | 代数和逻辑约束的混合概率推理
Mysql environment installation under Linux (centos)
The role of /etc/resolv.conf
UOS - WindTerm use
推荐系统:常用评价指标总结【准确率、精确率、召回率、命中率、(归一化折损累计增益)NDCG、平均倒数排名(MRR)、ROC曲线、AUC(ROC曲线下的面积)、P-R曲线、A/B测试】
简单的vim配置
Keil nRF52832下载失败
Program processes and threads (concurrency and parallelism of threads) and basic creation and use of threads