当前位置:网站首页>使用LIME解释黑盒ML模型
使用LIME解释黑盒ML模型
2020-11-06 01:14:00 【人工智能遇见磐创】

作者|Travis Tang (Voon Hao) 编译|VK 来源|Towards Data Science
在这一点上,任何人都认为机器学习在医学领域的潜力是老生常谈的。有太多的例子支持这一说法-其中之一就是微软利用医学影像数据帮助临床医生和放射科医生做出准确的癌症诊断。同时,先进的人工智能算法的发展大大提高了此类诊断的准确性。毫无疑问,医疗数据如此惊人的应用,人们有充分的理由对其益处感到兴奋。
然而,这种尖端算法是黑匣子,可能很难解释。黑匣子模型的一个例子是深度神经网络,输入数据通过网络中的数百万个神经元后,作出一个单一的决定。这种黑盒模型不允许临床医生用他们的先验知识和经验来验证模型的诊断,使得基于模型的诊断不那么可信。
事实上,最近对欧洲放射科医生的一项调查描绘了一幅在放射学中使用黑匣子模型的现实图景。调查显示,只有55.4%的临床医生认为没有医生的监督,患者不会接受纯人工智能的应用。[1]

在接受调查的635名医生中,超过一半的人认为患者还没有准备好接受仅仅由人工智能生成的报告。
下一个问题是:如果人工智能不能完全取代医生的角色,那么人工智能如何帮助医生提供准确的诊断?
这促使我探索有助于解释机器学习模型的现有解决方案。一般来说,机器学习模型可以分为可解释模型和不可解释模型。简而言之,可解释的模型提供的输出与每个输入特征的重要性相关。这些模型的例子包括线性回归、logistic回归、决策树和决策规则等。另一方面,神经网络形成了大量无法解释的模型。
有许多解决方案可以帮助解释黑匣子模型。这些解决方案包括Shapley值、部分依赖图和Local Interpretable Model Agnostic Explanations(LIME),这些方法在机器学习实践者中很流行。今天,我将关注LIME。
根据Ribeiro等人[2]的LIME论文,LIME的目标是“在可解释表示上识别一个局部忠实于分类器的可解释模型”。换句话说,LIME能够解释某一特定点的分类结果。LIME也适用于所有类型的模型,使其不受模型影响。
直观解释LIME
听起来很难理解。让我们一步一步地把它分解。假设我们有以下具有两个特征的玩具数据集。每个数据点都与一个基本真相标签(正或负)相关联。
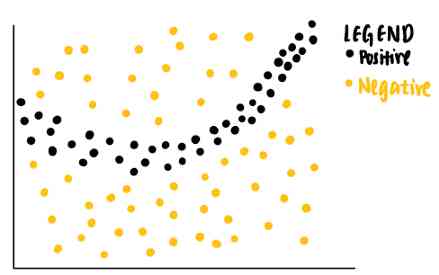
从数据点可以看出,线性分类器将无法识别区分正负标签的边界。因此,我们可以训练一个非线性模型,例如神经网络,来对这些点进行分类。如果模型经过良好训练,它能够预测落在深灰色区域的新数据点为正,而落在浅灰色区域的另一个新数据点为负。
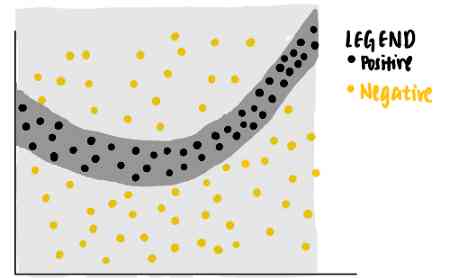
现在,我们很好奇模型对特定数据点(紫色)所做的决定。我们扪心自问,为什么这个特定的点被神经网络预测为负?
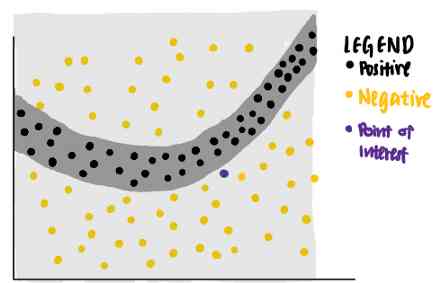
我们可以用LIME来回答这个问题。LIME首先从原始数据集中识别随机点,并根据每个数据点到紫色兴趣点的距离为每个数据点分配权重。采样数据点越接近感兴趣的点,就越重要。(在图片中,较大的点表示分配给数据点的权重更大。)
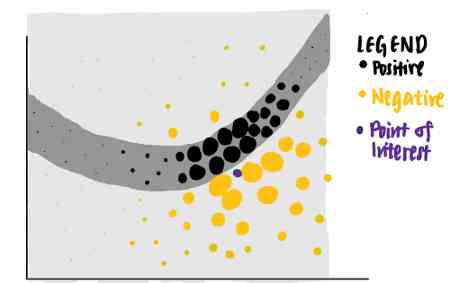
使用这些不同权重的点,LIME给出了一个具有最高可解释性和局部保真度的解释。
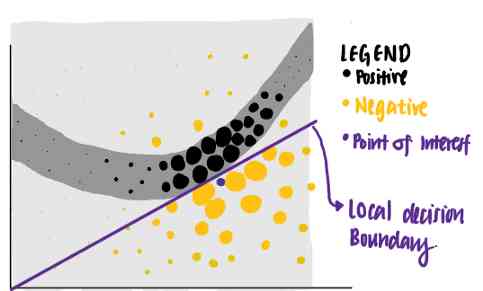
使用这个标准,LIME将紫色线标识为兴趣点的已知解释。我们可以看到,紫线可以解释神经网络的决策边界靠近数据点。所学的解释具有较高的局部保真度,但全局保真度较低。
让我们看看LIME在实际中的作用:现在,我将重点介绍LIME在解释威斯康辛州乳腺癌数据训练的机器学习模型中的使用。
威斯康星州乳腺癌数据集:了解癌细胞的预测因子
威斯康星州乳腺癌数据集[3],由UCI于1992年发布,包含699个数据点。每个数据点代表一个细胞样本,可以是恶性的也可以是良性的。每个样品也有一个数字1到10,用于以下特征。
-
肿块厚度:Clump Thickness
-
细胞大小均匀性:Uniformity of Cell Size
-
细胞形状均匀性:Uniformity of Cell Shape
-
单个上皮细胞大小:Single Epithelial Cell Size
-
有丝分裂:Mitoses
-
正常核:Normal Nucleoli
-
乏味染色体:Bland Chromatin
-
裸核:Bare Nuclei
-
边缘粘着性:Marginal Adhesion
让我们试着理解这些特征的含义。下面的插图使用数据集的特征显示了良性和恶性细胞之间的区别。
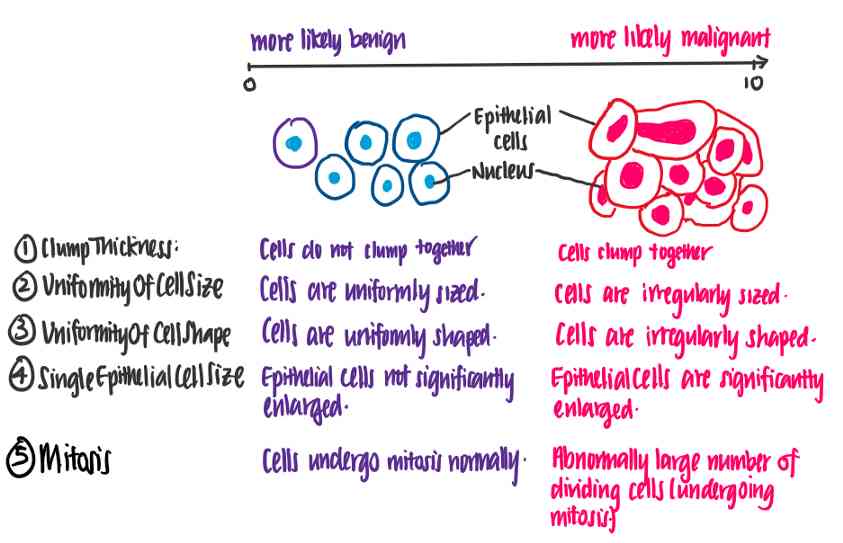
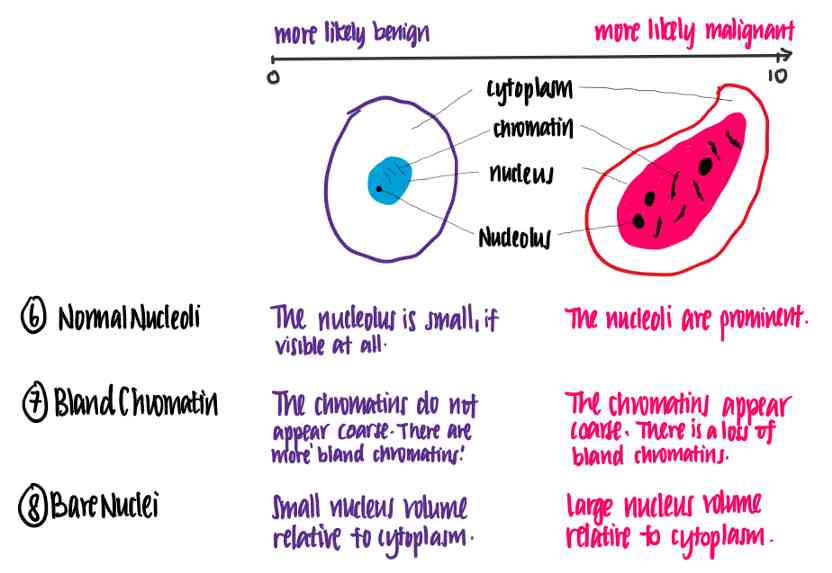
感谢医学院的朋友的专题讲解。
从这个例子中,我们可以看到每个特征值越高,细胞越有可能是恶性的。
预测细胞是恶性还是良性
现在我们已经理解了数据的含义,让我们开始编码吧!我们首先读取数据,然后通过删除不完整的数据点并重新格式化类列来清理数据。
数据导入、清理和探索
# 数据导入和清理
import pandas as pd
df = pd.read_csv("/BreastCancerWisconsin.csv",
dtype = 'float', header = 0)
df = df.dropna() # 删除所有缺少值的行
# 原始数据集在Class列中使用值2和4来标记良性和恶性细胞。此代码块将其格式化为良性细胞为0类,恶性细胞为1类。
def reformat(value):
if value == 2:
return 0 # 良性
elif value == 4:
return 1 # 恶性
df['Class'] = df.apply(lambda row: reformat(row['Class']), axis = 'columns')
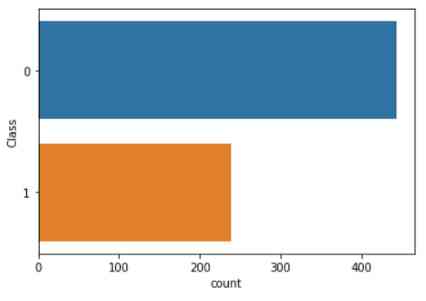
在删除了不完整的数据之后,我们对数据进行了简单的研究。通过绘制细胞样本类别(恶性或良性)的分布图,我们发现良性(0级)细胞样本多于恶性(1级)细胞样本。
import seaborn as sns
sns.countplot(y='Class', data=df)
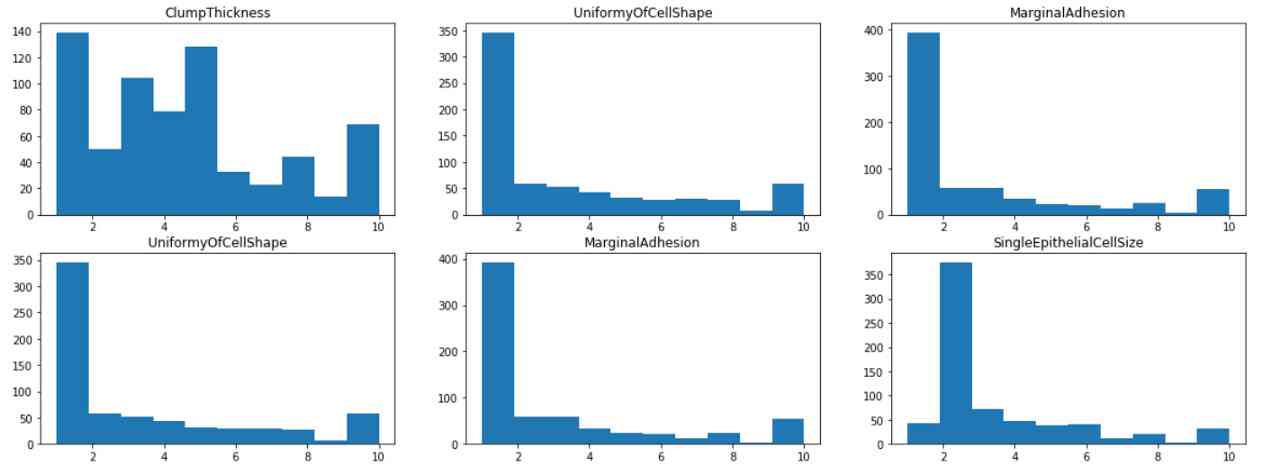
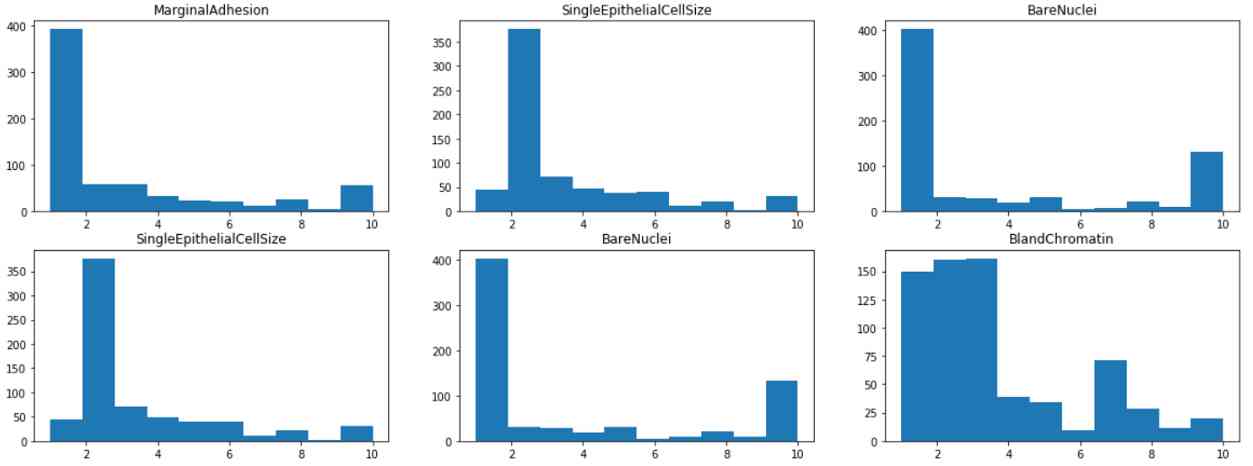
通过可视化每个特征的直方图,我们发现大多数特征都有1或2的模式,除了块状和淡色质,其分布在1到10之间更为均匀。这表明团厚和乏味的染色质可能是该类的较弱的预测因子。
from matplotlib import pyplot as plt
fig, axes = plt.subplots(4,3, figsize=(20,15))
for i in range(0,4):
for j in range(0,3):
axes[i,j].hist(df.iloc[:,1+i+j])
axes[i,j].set_title(df.iloc[:,1+i+j].name)
模型训练和测试
然后,将数据集按80%-10%-10%的比例分成典型的训练验证测试集,利用Sklearn建立K-近邻模型。经过一些超参数调整(未显示),发现k=10的模型在评估阶段表现良好-它的F1分数为0.9655。代码块如下所示。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
# 训练测试拆分
X_traincv, X_test, y_traincv, y_test = train_test_split(data, target, test_size=0.1, random_state=42)
# K-折叠验证
kf = KFold(n_splits=5, random_state=42, shuffle=True)
for train_index, test_index in kf.split(X_traincv):
X_train, X_cv = X_traincv.iloc[train_index], X_traincv.iloc[test_index]
y_train, y_cv = y_traincv.iloc[train_index], y_traincv.iloc[test_index]
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import f1_score,
# 训练KNN模型
KNN = KNeighborsClassifier(k=10)
KNN.fit(X_train, y_train)
# 评估KNN模型
score = f1_score(y_testset, y_pred, average="binary", pos_label = 4)
print ("{} => F1-Score is {}" .format(text, round(score,4)))
使用LIME的模型解释
一个Kaggle行家可能会说这个结果很好,我们可以在这里完成这个项目。然而,人们应该对模型的决策持怀疑态度,即使模型在评估中表现良好。因此,我们使用LIME来解释KNN模型对这个数据集所做的决策。这通过检查决策是否符合我们的直觉来验证模型的有效性。
import lime
import lime.lime_tabular
# LIME准备
predict_fn_rf = lambda x: KNN.predict_proba(x).astype(float)
# 创建一个LIME解释器
X = X_test.values
explainer = lime.lime_tabular.LimeTabularExplainer(X,feature_names =X_test.columns, class_names = ['benign','malignant'], kernel_width = 5)
# 选择要解释的数据点
chosen_index = X_test.index[j]
chosen_instance = X_test.loc[chosen_index].values
# 使用LIME解释器解释数据点
exp = explainer.explain_instance(chosen_instance, predict_fn_rf, num_features = 10)
exp.show_in_notebook(show_all=False)
在这里,我选择了3点来说明LIME是如何使用的。
解释为什么样本被预测为恶性

这里,我们有一个数据点,实际上是恶性的,并且被预测为恶性。在左边的面板上,我们看到KNN模型预测这一点有接近100%的概率是恶性的。在中间,我们观察到LIME能够使用数据点的每一个特征,按照重要性的顺序来解释这种预测。根据LIME的说法,
-
事实上,样本对于裸核的值大于6.0,这使得它更有可能是恶性的。
-
由于样本有很高的边缘粘附性,它更可能是恶性的而不是良性的。
-
由于样本的团块厚度大于4,它更有可能是恶性的。
-
另一方面,样本的有丝分裂值≤1.00这一事实使其更有可能是良性的。
总的来说,考虑到样本的所有特征(在右边的面板上),样本被预测为恶性。
这四个观察符合我们对癌细胞的直觉和认识。知道了这一点,我们更相信模型是根据我们的直觉做出正确的预测。让我们看看另一个例子。
解释为什么预测样本是良性的

在这里,我们有一个细胞样本,预测是良性的,实际上是良性的。LIME通过引用(除其他原因外)解释了为什么会出现这种情况
-
该样品的裸核值≤1
-
该样品的核仁正常值≤1
-
它的团厚度也≤1
-
细胞形状的均匀性也≤1
同样,这些符合我们对为什么细胞是良性的直觉。
解释样本预测不清楚的原因
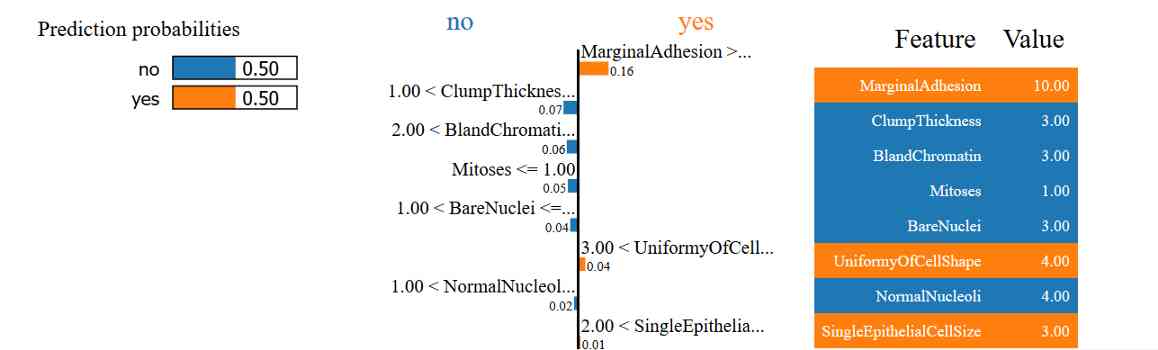
在最后一个例子中,我们看到这个模型无法很好地预测细胞是良性还是恶性。你能用LIME的解释明白为什么会这样吗?
结论
LIME的有用性从表格数据扩展到文本和图像,使其具有难以置信的通用性。然而,仍有工作要做。例如,本文作者认为,当前的算法在应用于图像时速度太慢,无法发挥作用。
尽管如此,在弥补黑盒模型的有用性和难处理性之间的差距方面,LIME仍然是非常有用的。如果你想开始使用LIME,一个很好的起点就是LIME的Github页面。
参考引用
[1] Codari, M., Melazzini, L., Morozov, S.P. et al., Impact of artificial intelligence on radiology: a EuroAIM survey among members of the European Society of Radiology (2019), Insights into Imaging
[2] M. Ribeiro, S. Singh and C. Guestrin, ‘Why Should I Trust You?’ Explining the Predictions of Any Clasifier (2016), KDD
[3] Dr. William H. Wolberg, Wisconsin Breast Cancer Database (1991), University of Wisconsin Hospitals, Madison
原文链接:https://towardsdatascience.com/interpreting-black-box-ml-models-using-lime-4fa439be9885
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4703068
边栏推荐
猜你喜欢





随机推荐
滴滴 Elasticsearch 集群跨版本升级与平台重构之路
微信小程序:防止多次点击跳转(函数节流)
H5打造属于自己的视频播放器(JS篇2)
刷了LeetCode的链表专题,我发现了一个秘密!
写一个通用的幂等组件,我觉得很有必要
Python + Appium 自動化操作微信入門看這一篇就夠了
梯度下降算法在机器学习中的工作原理
【C/C++ 1】Clion配置与运行C语言
键盘录入抽奖人随机抽奖
【數量技術宅|金融資料系列分享】套利策略的價差序列計算,恐怕沒有你想的那麼簡單
被产品经理怼了,线上出Bug为啥你不知道
企业数据库的选择通常由系统架构师主导决策 - thenewstack
阻塞队列之LinkedBlockingQueue分析
我们编写 React 组件的最佳实践
互联网 舆情系统的架构实践
解決pl/sql developer中資料庫插入資料亂碼問題
Azure DevOps 扩展之 Hub 插件的菜单权限控制配置
NodeJs爬虫抓取古代典籍,共计16000个页面心得体会总结及项目分享
Polkadot系列(二)——混合共识详解
es5 类和es6中class的区别