当前位置:网站首页>Meituan Ali's Application Practice on multimodal recall
Meituan Ali's Application Practice on multimodal recall
2022-07-04 12:54:00 【Weiyaner】
1. Meituan multimodal recall - Search business applications
Multimodal recall task , It mainly exists in the recall and sorting list POI、 picture 、 Text 、 Video and other modal results , How to ensure Query Correlation with multimodal search results is a big challenge , At present, more multimodal recalls are mainly applied to e-commerce , Short video recommendation search and other fields .
Common multimodal recall tasks , Given a paragraph query Text , Output pictures / The video with the highest similarity topk Return as result , Also is to item Item replaced with picture / video . take query-query The matching task is transformed into query-image Match task , By training the multimodal recall model , Yes Query-Image The samples were scored for correlation , Then sort the correlation scores , Determine the final recall list .
Two schools of multimodal models
With Goolge BERT The great success of models in natural language processing , In the field of multimodality, more and more researchers begin to learn from BERT The pre training method of , Developing fusion images / video (Image/Video) And other modes of BERT Model , And successfully applied to multimodal retrieval 、VQA、Image Caption Etc . therefore , Consider using BERT Related multimodal pre training model (Vision-Language Pre-training, VLP), And the downstream task of graph text correlation calculation is transformed into the binary classification problem of whether the picture and text match , Model learning .
at present , be based on Transformer Multimodality of the model VLP The algorithm is mainly divided into two schools :
Single stream ( Single tower ) Model
In the single stream model, text information and visual information are fused at the beginning , Input directly into Encoder(Transformer) in .
The model represents :ImageBERT,VisualBERT、VL-BERT
ImageBERT: Qi, D., Su, L., Song, J., Cui, E., Bharti, T., and Sacheti, A. Imagebert: Cross-modal Pre-training with Large-scale Weak-supervised Image-text Data. arXiv preprint arXiv:2001.07966 (2020).
VisualBERT: Li L H, Yatskar M, Yin D, et al. Visualbert: A simple and performant baseline for vision and language[J]. arXiv preprint arXiv:1908.03557, 2019.
VL-BERT: Su W, Zhu X, Cao Y, et al. Vl-bert: Pre-training of generic visual-linguistic representations[J]. arXiv preprint arXiv:1908.08530, 2019.
Double current ( Two towers ) Model
In the two stream model, text information and visual information first go through two independent Encoder(Transformer) modular , And then through Cross Transformer To realize the fusion of different modal information .
The typical two stream model is as follows LXMERT,ViLBERT etc. .
LXMERT : Tan, H., and Bansal, M. LXMERT: Learning Cross-modality Encoder Representations from Transformers. arXiv preprint arXiv:1908.07490 (2019).
ViLBERT : Lu J, Batra D, Parikh D, et al. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[C]//Advances in Neural Information Processing Systems. 2019: 13-23.
Text-Image Matching Mission
For each Query-Image The sample pairs were scored for similarity , And then for each Query The candidate images are sorted by relevance , Get the final result . There are usually two ways to solve multimodal matching problems :
- Mapping different modal data to different feature spaces , Then we learn an unexplained distance function through hidden layer interaction , Pictured (a) Shown .
- Mapping different modal data to the same feature space , So as to calculate the interpretable distance between different modal data ( Similarity degree ), Pictured (b) Shown .
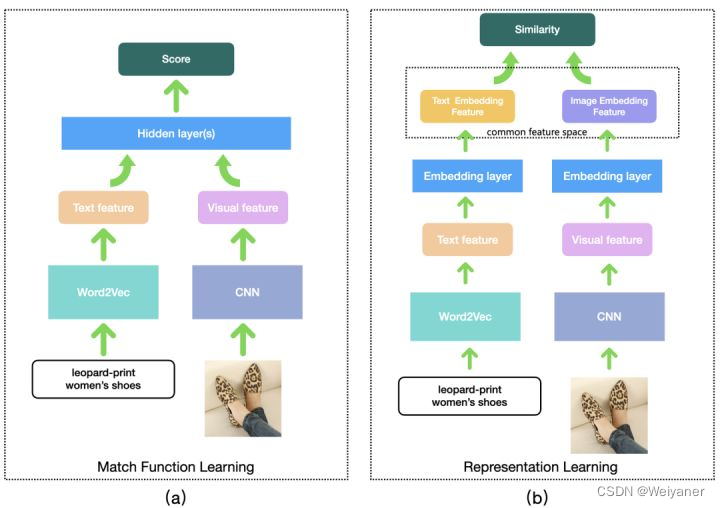
These are the two main genres of multimodal tasks : Single tower / Interactive and twin towers / Representational model .
In general , The effect of a single tower will be better , Because the characteristic information of text and image is fully interactive , Provide more cross feature information for the hidden layer of the model .
2 Ali · Some practices of multimodal semantic recall in content recommendation scenario
Preface
Content recommendation system as a means of accurately matching users and content , It plays an important role in the link of content distribution , Among them, the recall determines the performance of the whole recommendation system upper bound .
In the content distribution platform , Behavior based recall model models user interests at different scales through personalization , Build personalized content consumption experience . But it completely depends on the available log information on the platform , It will make the recommendation system easy to fall into spin , Further aggravate the information cocoon effect , High quality long tail content cannot be distributed more fairly and effectively , It is not conducive to the ecological health of the whole platform .
Due to the sparsity of user interaction data , The model based on user behavior makes their interest representation easy to appear larger bias, Corresponding means are needed to ensure that the interests of these users match .
content-base Due to the decoupling of behavior , It has certain advantages in alleviating such problems , Conventional content-base Methods include labels 、 Property recall , To some extent, it can alleviate such problems , However, the matching of tags and attributes is generally relatively hard, There are certain bottlenecks in generalization ability and expansion ability , With the evolution of multimodal and deep recall models , Adopt multimodal and semantic recall model to solve content-base The problem has become one of the sharp weapons of many recommendation platforms .
Multimodal recall
Semantics contains multi-level information , In addition to text tags, there are also visual and audio , Both of them have a certain impact on users' decisions , The combination of the two can better characterize the semantic information and personalized characteristics of video .
A more comprehensive understanding of the video content in the recommendation system recall is also conducive to a more comprehensive understanding of the user's recommendation intention , So as to improve the effect of recommendation . At present, the common solution in the industry is multimodal modeling , Integrate multiple modes such as text and video , Promote each other's expression , To achieve a more comprehensive understanding of the video content .
Generally speaking, there are many modes of text video fusion , By referring to the research of the industry and academia , Multimodal recall uses video bert The architecture of , adopt Double current Input +later fusion And the text mask, Video frame mask Wait for auxiliary tasks , Better learn the content of multimodal expression , The overall model architecture is as follows :
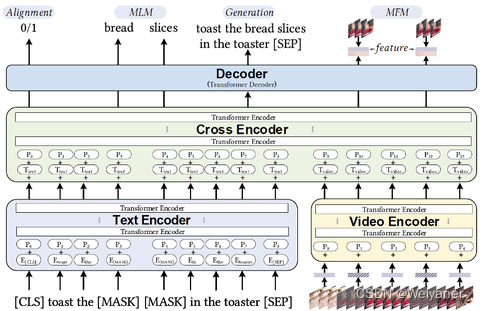
1 Multimodal recall v1.0: vector v2v
Based on large-scale pre training model , We can get the multimodal representation of the whole content , The combination of visual and textual representation can give the recommendation system the ability to find similarities to a certain extent . We have launched visual similarity v2v And visual clustering recall , The former is based on multimodal pre training representation , Portray users trigger Similarity from video to distribution video , Online v2v Recall .
adopt 1.0 It can realize the representation of user interest space , It solves the problem of finding similarity . But on the content distribution platform , Frequent recommendation similarity doc It will cause user fatigue , Information cocoon room and other issues .
Therefore, a more generalized “ Look for similarities ” Methods to match user interests .
2 Multimodal recall v2.0: Cluster center recall
We adopt the method of clustering recall , adopt k-means clustering , Will be continuous 、 The extensive multimodal space is reduced to discrete 、 Constrained clustering space .K-means After clustering, it is more likely to reach a wider range of user interests , And the recall content is more divergent . You can see from the picture that ,k-means Clustering has a greater probability of hitting user interest ( The area of the intersection is large ), And the categories of recall are more divergent .

3 Multimodal recall v3.0: Personalized multimodal content recall
Multimodal representation is self supervised in training , Just model the characteristics of the content itself .
But in reality , What is described in a video may only be of interest to users , If we are recalling the representation of all video content for similarity calculation , It is easy to introduce noise and affect the part that most people are really interested in .
So we need some kind of guidance signal to further personalize our existing representations , What we hope to achieve is , The content representation function we learned f(x) Can both To some extent, it can represent the content , At the same time, it can also highlight the most interesting parts of the Group .
Very natural , Multimodal representation combined with user behavior finetune It is worth trying , Therefore, we propose a content representation module that combines multimodal representation and user behavior. This module combines massive user preference signals and pre training ready The representation of , Get content expression that is more suitable for the actual business scenario
It should be noted that , Although the sample here is also based on the available platform logs , But the characteristics of statistics and id class (contentId etc. ) Not used , Because our goal is not a personalized recall model , But through group intelligence , Extract the expression suitable for most users from the content representation .
We believe that users' real expression Eu It should consist of two parts ,ECu and EPu, The former can be understood as the unbiased good of the content , The latter can be understood as personalized preferences . And the content Ei It should also contain two parts ECi and EPi, The former ECi It can be expressed as the characteristics of the content itself , In our model, it can be considered as the common feature expression obtained by filtering the input of our multimodal and other features through a filter , and EPi Is expressed as bias. So our model is on the user side and item Two are designed on the side bias, To extract personalized paranoid information .
The whole model architecture is as follows :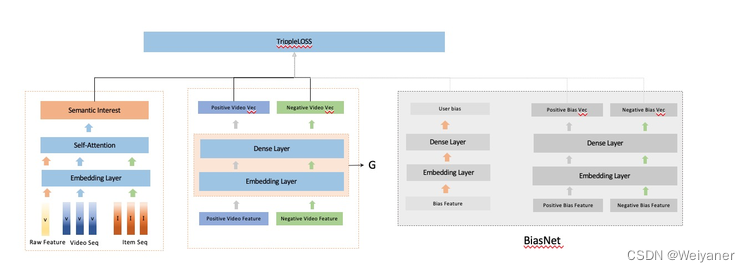
The whole model adopts contrastive learning( Comparative learning ) Framework , The exact sample originally comes from clicking , Negative samples originally come from random sampling + part hard sample. The pre trained multimodal representation is used as the input of the whole model . Through training , We can learn a semantic representation function that can integrate multimodality and behavior G.
边栏推荐
- Kivy教程之 08 倒计时App实现timer调用(教程含源码)
- 16. Memory usage and segmentation
- How to realize the function of Sub Ledger of applet?
- Runc hang causes the kubernetes node notready
- 8个扩展子包!RecBole推出2.0!
- mm_ Cognition of struct structure
- I want to talk about yesterday
- Communication tutorial | overview of the first, second and third generation can bus
- 老掉牙的 synchronized 锁优化,一次给你讲清楚!
- 二分查找的简单理解
猜你喜欢
C語言函數

比量子化学方法快六个数量级,一种基于绝热状态的绝热人工神经网络方法,可加速对偶氮苯衍生物及此类分子的模拟
16. Memory usage and segmentation
Reinforcement learning - learning notes 1 | basic concepts

VIM, another program may be editing the same file If this is the solution of the case

Will the concept of "being integrated" become a new inflection point of the information and innovation industry?

How to realize the function of Sub Ledger of applet?
Flet教程之 按钮控件 ElevatedButton入门(教程含源码)
C语言函数

When synchronized encounters this thing, there is a big hole, pay attention!
随机推荐
【AI系统前沿动态第40期】Hinton:我的深度学习生涯与研究心法;Google辟谣放弃TensorFlow;封神框架正式开源
DC-5 target
Jetson TX2配置Tensorflow、Pytorch等常用库
Langue C: trouver le nombre de palindromes dont 100 - 999 est un multiple de 7
C language function
Using nsproxy to forward messages
After the game starts, you will be prompted to install HMS core. Click Cancel, and you will not be prompted to install HMS core again (initialization failure returns 907135003)
Definition of cognition
AbstractDispatcherServletInitializer 的实现类为什么可以在初始化Web容器的时候被调用
mm_ Cognition of struct structure
0x15 string
2022, 6G is heating up
比量子化学方法快六个数量级,一种基于绝热状态的绝热人工神经网络方法,可加速对偶氮苯衍生物及此类分子的模拟
Flet教程之 02 ElevatedButton高级功能(教程含源码)(教程含源码)
C语言数组
Abnormal mode of ARM processor
认知的定义
When synchronized encounters this thing, there is a big hole, pay attention!
【云原生 | Kubernetes篇】深入了解Ingress(十二)
ArgMiner:一个用于对论点挖掘数据集进行处理、增强、训练和推理的 PyTorch 的包