当前位置:网站首页>C语言数组
C语言数组
2022-07-04 12:33:00 【天黑再醒】
目录
一维数组:
一维数组创建:
格式:元素类型 数组名 [常量表达式]
如:int arr[10] ;
const int n=10;
int arr[n]; //由const 是常变量 本质上来说还是变量,所以不成立
注:数组创建,在C99标准之前, [] 中要给一个常量才可以,不能使用变量。在C99标准支持了变长数组的概念。
一维数组初始化:
int arr[5]={1,2,3,4} //结果是: 1 2 3 4 0 字符个数小于[]里的由0来补
int arr[]={1,2,3,4} //结果是 : 1 2 3 4
char ch[]={'a','b','c'} //结果是: a b c
char ch[]={'a',98,'c'} //结果是: a b c 因为在ASCII表里字符b的ASCII值为98
char ch[4]={'a','b','c'} //结果是: a b c \0
char ch[]="abc" //结果是: a b c \0
int arr[10]={1,2,3,4,5};printf("%d\n",arr[4]);
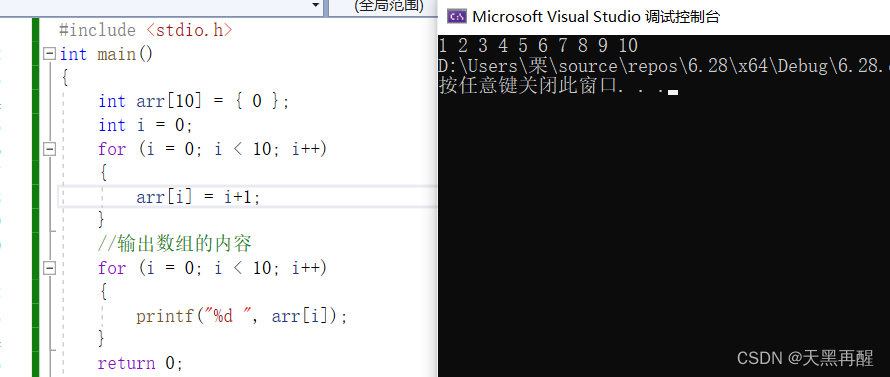
赋值1~10
#include <stdio.h>
int main()
{
int arr[10] = {0};
int i = 0;
for(i=0; i<10; i++)
{
arr[i] = i+1;
}
for(i=0; i<10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
数组的大小也是可以计算的:
int arr[10];int sz = sizeof(arr);//求字节的个数int sz = sizeof(arr1[10]);//求一个元素的字节int sz = sizeof(arr)/sizeof(arr[0]);//求元素的个数
一维数组在内存中的存储:
#include <stdio.h>
int main()
{
int arr[10] = {0};
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
for(i=0; i<sz; ++i)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0;
}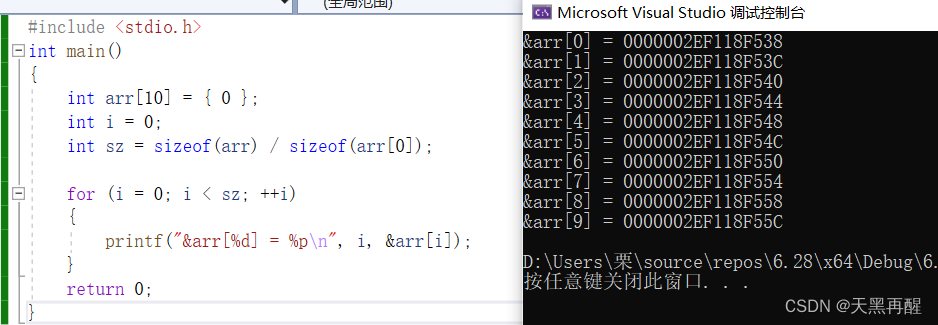
随着数组下标的增长,元素的地址,也在有规律的递增。
二维数组:
二维数组的创建:
int arr[3][5]; //3行5列
char arr[3][5]; //3行5列double arr[2][4]; //2行4列
二维数组初始化:
int arr[3][5]={1,2,3,4,5,6};
// { 1 2 3 4 5 }
{ 6 0 0 0 0 }
{ 0 0 0 0 0 }
如果想把1,2存在第一行,3,4存在第二行,5,6存在第三行则:
int arr[3][5]={ {1,2},{3,4},{5,6}};
// { 1 2 0 0 0 }
{ 3 4 0 0 0 }
{ 5 6 0 0 0 }
二维数组初始化的时候行可以省略,列不能省略
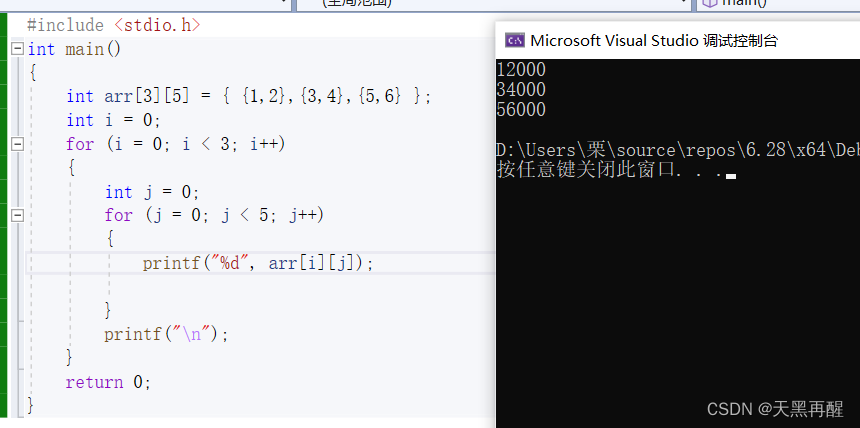
想打印出这个
int arr[3][5]={ {1,2},{3,4},{5,6}};
代码如下:
#include <stdio.h>
int main()
{
int arr[3][5] = { {1,2},{3,4},{5,6} };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
printf("%d", arr[i][j]);
}
printf("\n");
}
return 0;
}
二维数组的存储:
#include <stdio.h>
int main()
{
int arr[3][5];
int i = 0;
for(i=0; i<3; i++)
{
int j = 0;
for(j=0; j<5; j++)
{
printf("&arr[%d][%d] = %p\n", i, j,&arr[i][j]);
}
}
return 0; }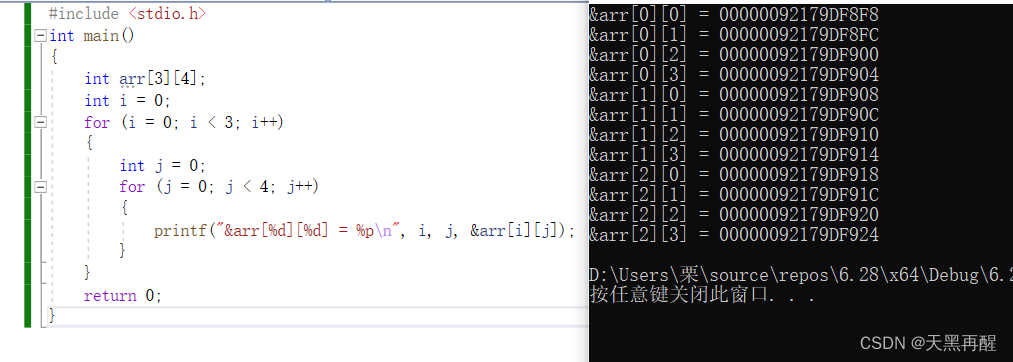
二维数组在内存中也是连续存放的。
数组的越界:
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
for(i=0; i<=10; i++)
{
printf("%d\n", arr[i]);//当i等于10的时候,越界访问了
}
return 0;
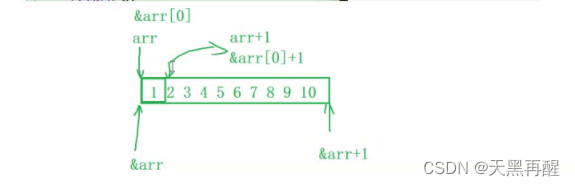
}数组名:
数组名是数组首元素的地址。
有两个例外:
1.sizeof(数组名),数组名不是数组首元素的地址,数组名表示整个数组,计算的是整个数组的地址。
2.&数组名, 数组名不是数组首元素的地址,数组名表示整个数组,取出的是整个数组的地址。
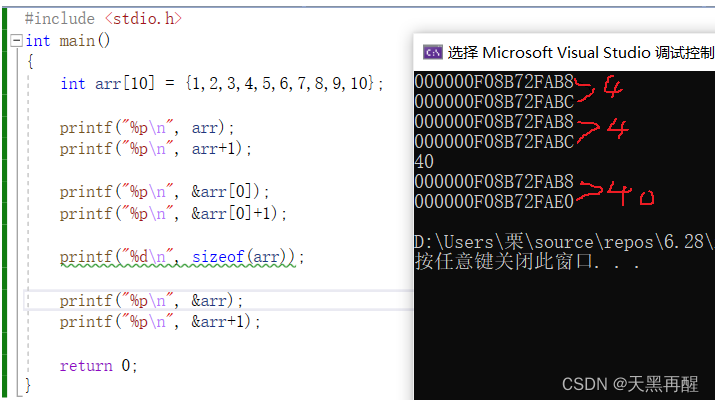
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};printf("%p\n", arr);
printf("%p\n", arr+1);printf("%p\n", &arr[0]);
printf("%p\n", &arr[0]+1);printf("%d\n", sizeof(arr));
printf("%p\n", &arr);
printf("%p\n", &arr+1);return 0;
}
冒泡排序:
数组中2个相邻的元素进行比较,如果不满足顺序就进行交换。
如: 将3,1,4,2,5,7,6,8,10,9 排序(升序)
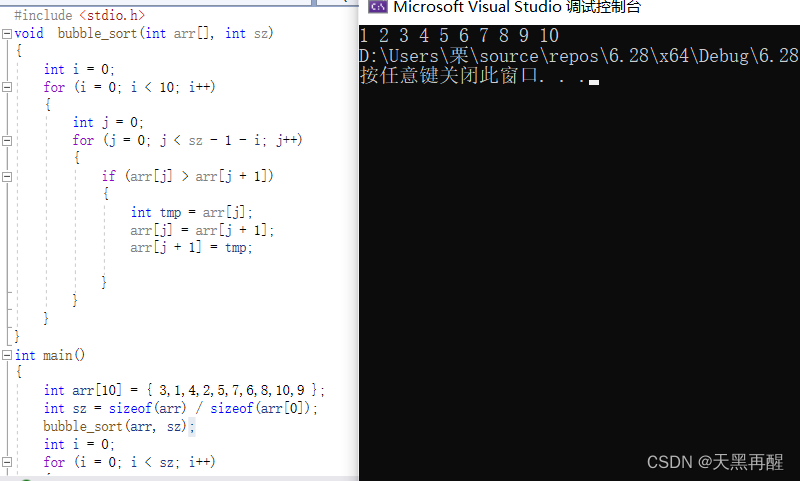
#include <stdio.h>
//void bubble_sort(int* arr[], int sz)
void bubble_sort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < 10; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[10] = { 3,1,4,2,5,7,6,8,10,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ",arr[i]);
}
return 0;
} 
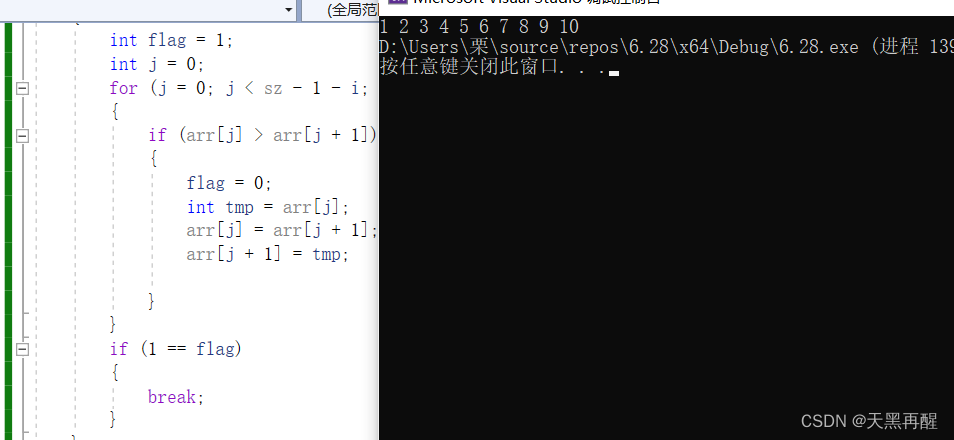
如果顺序正确,那只是在交换,可以优化一下:
#include <stdio.h>
void bubble_sort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < 10; i++)
{
int flag = 1;
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
flag = 0;
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
if (1 == flag)
{
break;
}
}
}
int main()
{
int arr[10] = { 3,1,4,2,5,7,6,8,10,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
以上内容为数组相关的。
愿诸君共勉之!!!!
边栏推荐
- Source code analysis of the implementation mechanism of multisets in guava class library
- PKCs 5: password based cryptography specification version 2.1 Chinese Translation
- Ml and NLP are still developing rapidly in 2021. Deepmind scientists recently summarized 15 bright research directions in the past year. Come and see which direction is suitable for your new pit
- Openssl3.0 learning 20 provider KDF
- (August 10, 2021) web crawler learning - Chinese University ranking directed crawler
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 10
- Iframe to only show a certain part of the page
- Global and Chinese markets for environmental disinfection robots 2022-2028: Research Report on technology, participants, trends, market size and share
- 0x15 string
- MYCAT middleware installation and use
猜你喜欢

Leetcode: 408 sliding window median
What if the chat record is gone? How to restore wechat chat records on Apple Mobile

Decrypt the advantages of low code and unlock efficient application development

Process communication and thread explanation
13、 C window form technology and basic controls (3)
(2021-08-20) web crawler learning 2
The database connection code determines whether the account password is correct, but the correct account password always jumps to the failure page with wrong account password
How to create a new virtual machine
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 7](/img/44/1861f9016e959ed7c568721dd892db.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 7
Data communication and network: ch13 Ethernet
随机推荐
Memory computing integration: AI chip architecture in the post Moorish Era
Globalsign's SSL certificate products
Unity performance optimization reading notes - Introduction (1)
The detailed installation process of Ninja security penetration system (Ninjitsu OS V3). Both old and new VM versions can be installed through personal testing, with download sources
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 8
Awk getting started to proficient series - awk quick start
Uva536 binary tree reconstruction tree recovery
Global and Chinese market of piston rod 2022-2028: Research Report on technology, participants, trends, market size and share
MYCAT middleware installation and use
2021-08-09
CSDN documentation specification
mm_ Cognition of struct structure
Process communication and thread explanation
Interview question MySQL transaction (TCL) isolation (four characteristics)
R语言--readr包读写数据
asp. Core is compatible with both JWT authentication and cookies authentication
In 2022, financial products are not guaranteed?
How do std:: function and function pointer assign values to each other
It's hard to hear C language? Why don't you take a look at this (V) pointer
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 15