当前位置:网站首页>spark-streaming状态流之mapWithState
spark-streaming状态流之mapWithState
2022-07-26 15:51:00 【InfoQ】
背景
updateStateByKey mapWithStatemapWithState工作流程
mapWithStateupdateStateBykey
mapWithStatemapWithState具体类及关系
MapWithStateStreamImpl,InternalMapWithStateStream,MapWithStateRDD,MapWithStateRDDRecordmapWithState
源码分析
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local")
val ssc = new StreamingContext(sparkConf, Seconds(10))
ssc.checkpoint("d:\\tmp")
val params = Map("bootstrap.servers" -> "master:9092", "group.id" -> "scala-stream-group")
val topic = Set("test")
val initialRDD = ssc.sparkContext.parallelize(List[(String, Int)]())
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, params, topic)
val word = messages.flatMap(_._2.split(" ")).map { x => (x, 1) }
//自定义mappingFunction,累加单词出现的次数并更新状态
val mappingFunc = (word: String, count: Option[Int], state: State[Int]) => {
val sum = count.getOrElse(0) + state.getOption.getOrElse(0)
val output = (word, sum)
state.update(sum)
output
}
//调用mapWithState进行管理流数据的状态
val stateDstream = word.mapWithState(StateSpec.function(mappingFunc).initialState(initialRDD)).print()
ssc.start()
ssc.awaitTermination()
mapWithStatePairDStreamFunctionstoPairDStreamFunctionsmapWithState implicit def toPairDStreamFunctions[K, V](stream: DStream[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null):
PairDStreamFunctions[K, V] = {
new PairDStreamFunctions[K, V](stream)
}
PairDStreamFunctions.mapWithState()@Experimental
def mapWithState[StateType: ClassTag, MappedType: ClassTag](
spec: StateSpec[K, V, StateType, MappedType]
): MapWithStateDStream[K, V, StateType, MappedType] = {
new MapWithStateDStreamImpl[K, V, StateType, MappedType](
self, #这是本批次DStream对象
spec.asInstanceOf[StateSpecImpl[K, V, StateType, MappedType]]
)
}
mapWithStateStateSpecStateSpecmapWithStatemapWithStateprivate val internalStream =
new InternalMapWithStateDStream[KeyType, ValueType, StateType, MappedType](dataStream, spec)
......
# 这个方法只是把需要返回的数据进行一下转换,主要的逻辑在internalStream的computer里面
override def compute(validTime: Time): Option[RDD[MappedType]] = {
internalStream.getOrCompute(validTime).map { _.flatMap[MappedType] { _.mappedData } }
}
MapWithStateDStreamImplinternalStream.getOrComputeDStream.getOrComputeInternalMapWithStateDStream.computeInternalMapWithStateDStream: line 132
/** Method that generates a RDD for the given time */
override def compute(validTime: Time): Option[RDD[MapWithStateRDDRecord[K, S, E]]] = {
// 计算上一个状态的RDD
val prevStateRDD = getOrCompute(validTime - slideDuration) match {
case Some(rdd) =>
// 这个rdd是RDD[MapWithStateRDDRecord[K, S, E]]类型,其实就是一个MapWithStateRDD
if (rdd.partitioner != Some(partitioner)) {
// If the RDD is not partitioned the right way, let us repartition it using the
// partition index as the key. This is to ensure that state RDD is always partitioned
// before creating another state RDD using it
// _.stateMap.getAll()就是获取了所有的状态数据(往会下看会明白),在此基础创建MapWithStateRDD
MapWithStateRDD.createFromRDD[K, V, S, E](
rdd.flatMap { _.stateMap.getAll() }, partitioner, validTime)
} else {
rdd
}
case None =>
// 首批数据流入时会进入该分支
MapWithStateRDD.createFromPairRDD[K, V, S, E](
spec.getInitialStateRDD().getOrElse(new EmptyRDD[(K, S)](ssc.sparkContext)),
partitioner,
validTime
)
}
// 本批次流数据构成的RDD:dataRDD
val dataRDD = parent.getOrCompute(validTime).getOrElse {
context.sparkContext.emptyRDD[(K, V)]
}
val partitionedDataRDD = dataRDD.partitionBy(partitioner) // 重新分区
val timeoutThresholdTime = spec.getTimeoutInterval().map { interval =>
(validTime - interval).milliseconds
}
// 构造MapWithStateRDD
Some(new MapWithStateRDD(
prevStateRDD, partitionedDataRDD, mappingFunction, validTime, timeoutThresholdTime))
}
}
- 如果可以得到结果MapWithStateRDD
- 判断该RDD是否已经正确分区,后面的计算是分别每个分区对应的旧状态与新流入的数据进行计算的,如果两者的分区不一致,会导致计算出错(即会更新到错误的状态)。如果正确分区了,那么直接返回RDD,否则通过
MapWithStateRDD.createFromRDD指定partitioner对数据进行重新分区
- 如果计算不可以得到结果MapWithStateRDD
- 通过
MapWithStateRDD.createFromPairRDD创建一个,如果在WordCount代码中有对StateSpec进行设置initialStateRDD初始值,那么将在initialStateRDD基础上创建MapWithStateRDD,否则创建一个空的MapWithStateRDD,注意,这里使用的是同一个partitioner以保证具有相同的分区
new MapWithStateRDD(
prevStateRDD, partitionedDataRDD, mappingFunction, validTime, timeoutThresholdTime)
override def compute(
partition: Partition, context: TaskContext): Iterator[MapWithStateRDDRecord[K, S, E]] = {
val stateRDDPartition = partition.asInstanceOf[MapWithStateRDDPartition]
val prevStateRDDIterator = prevStateRDD.iterator(
stateRDDPartition.previousSessionRDDPartition, context)
val dataIterator = partitionedDataRDD.iterator(
stateRDDPartition.partitionedDataRDDPartition, context)
# prevRecord代表prevStateRDD一个分区的数据
val prevRecord = if (prevStateRDDIterator.hasNext) Some(prevStateRDDIterator.next()) else None
val newRecord = MapWithStateRDDRecord.updateRecordWithData(
prevRecord,
dataIterator,
mappingFunction,
batchTime,
timeoutThresholdTime,
removeTimedoutData = doFullScan // remove timedout data only when full scan is enabled
)
Iterator(newRecord)
}
MapWithStateRDDRecord.updateRecordWithData def updateRecordWithData[K: ClassTag, V: ClassTag, S: ClassTag, E: ClassTag](
prevRecord: Option[MapWithStateRDDRecord[K, S, E]],
dataIterator: Iterator[(K, V)],
mappingFunction: (Time, K, Option[V], State[S]) => Option[E],
batchTime: Time,
timeoutThresholdTime: Option[Long],
removeTimedoutData: Boolean
): MapWithStateRDDRecord[K, S, E] = {
// 从prevRecord中拷贝历史的状态数据(保存在MapWithStateRDDRecord的stateMap属性中)
val newStateMap = prevRecord.map { _.stateMap.copy() }. getOrElse { new EmptyStateMap[K, S]() }
// 保存需要返回的数据
val mappedData = new ArrayBuffer[E]
val wrappedState = new StateImpl[S]() // State子类,代表一个状态
// 循环本batch的所有记录(key-value)
dataIterator.foreach { case (key, value) =>
// 根据key从历史状态数据中获取该key对应的历史状态
wrappedState.wrap(newStateMap.get(key))
// 将mappingFunction应用到本次batch的每条记录
val returned = mappingFunction(batchTime, key, Some(value), wrappedState)
if (wrappedState.isRemoved) {
newStateMap.remove(key)
} else if (wrappedState.isUpdated
|| (wrappedState.exists && timeoutThresholdTime.isDefined)) {
newStateMap.put(key, wrappedState.get(), batchTime.milliseconds)
}
mappedData ++= returned
} // 判断是否删除、更新等然后维护newStateMap里的状态,并记录返回数据mappedData
// 如果有配置超时,也会进行一些更新操作
if (removeTimedoutData && timeoutThresholdTime.isDefined) {
newStateMap.getByTime(timeoutThresholdTime.get).foreach { case (key, state, _) =>
wrappedState.wrapTimingOutState(state)
val returned = mappingFunction(batchTime, key, None, wrappedState)
mappedData ++= returned
newStateMap.remove(key)
}
}
// 依然是返回一个MapWithStateRDDRecord,只是里面的数据变了
MapWithStateRDDRecord(newStateMap, mappedData)
}
# word="hello",value=1,state=("hello",3)
val mappingFunc = (word: String, value: Option[Int], state: State[Int]) => {
val sum = value.getOrElse(0) + state.getOption.getOrElse(0) #sum=4
val output = (word, sum) #("hello",4)
state.update(sum) #更新key="hello"的状态为4
output # 返回("hello",4)
}
/** Companion object for [[StateMap]], with utility methods */
private[streaming] object StateMap {
def empty[K, S]: StateMap[K, S] = new EmptyStateMap[K, S]
def create[K: ClassTag, S: ClassTag](conf: SparkConf): StateMap[K, S] = {
val deltaChainThreshold = conf.getInt("spark.streaming.sessionByKey.deltaChainThreshold",
DELTA_CHAIN_LENGTH_THRESHOLD)
new OpenHashMapBasedStateMap[K, S](deltaChainThreshold)
}
}
org.apache.spark.util.collection.OpenHashMap参考
边栏推荐
猜你喜欢
2022年全国最新消防设施操作员(高级消防设施操作员)考试试题及答案

阿里巴巴一面 :十道经典面试题解析

Teach the big model to skip the "useless" layer and improve the reasoning speed × 3. The performance remains unchanged, and the new method of Google MIT is popular

German EMG e-anji thruster ed301/6 HS
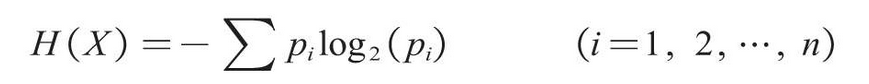
Using information entropy to construct decision tree

Google Earth Engine——MERRA-2 M2T1NXAER:1980-2022年气溶胶逐日数据集

基于SSM实现个性化健康饮食推荐系统

【工具分享】自动生成文件目录结构工具mddir
Google Earth engine - merra-2 m2t1nxaer: aerosol daily data set from 1980 to 2022
API 版本控制【 Eolink 翻译】
随机推荐
哪本书才是编程领域的“九阴真经”
6种方法帮你搞定SimpleDateFormat类不是线程安全的问题
A coal mine in Yangquan, Shanxi Province, suffered a safety accident that killed one person and was ordered to stop production for rectification
拒绝噪声,耳机小白的入门之旅
PS + PL heterogeneous multicore case development manual for Ti C6000 tms320c6678 DSP + zynq-7045 (3)
2022你的安全感是什么?沃尔沃年中问道
Super simple! It only takes a few steps to customize the weather assistant for TA!!
Encryption model
共议公共数据开放,“数牍方案”亮相数字中国建设峰会
API version control [eolink translation]
Delta controller rmc200
Can the parameterized view get SQL with different rows according to the characteristics of the incoming parameters? For example, here I want to use the column in the transmission parameter @field
13年资深开发者分享一年学习Rust经历:从必备书目到代码练习一网打尽
Can't you see the withdrawal? Three steps to prevent withdrawal on wechat.
ES6高级-查询商品案例
一款可视化浏览器历史的 Firefox/Chrome 插件
《硅谷之谜》读后感
Clojure 运行原理之编译器剖析
13 years of senior developers share a year of learning rust experience: from the necessary bibliography to code practice
Clojure Web 开发-- Ring 使用指南