当前位置:网站首页>Deep understanding of grouping sets statements in SQL
Deep understanding of grouping sets statements in SQL
2022-07-03 16:12:00 【InfoQ】
Preface
Group Bydealer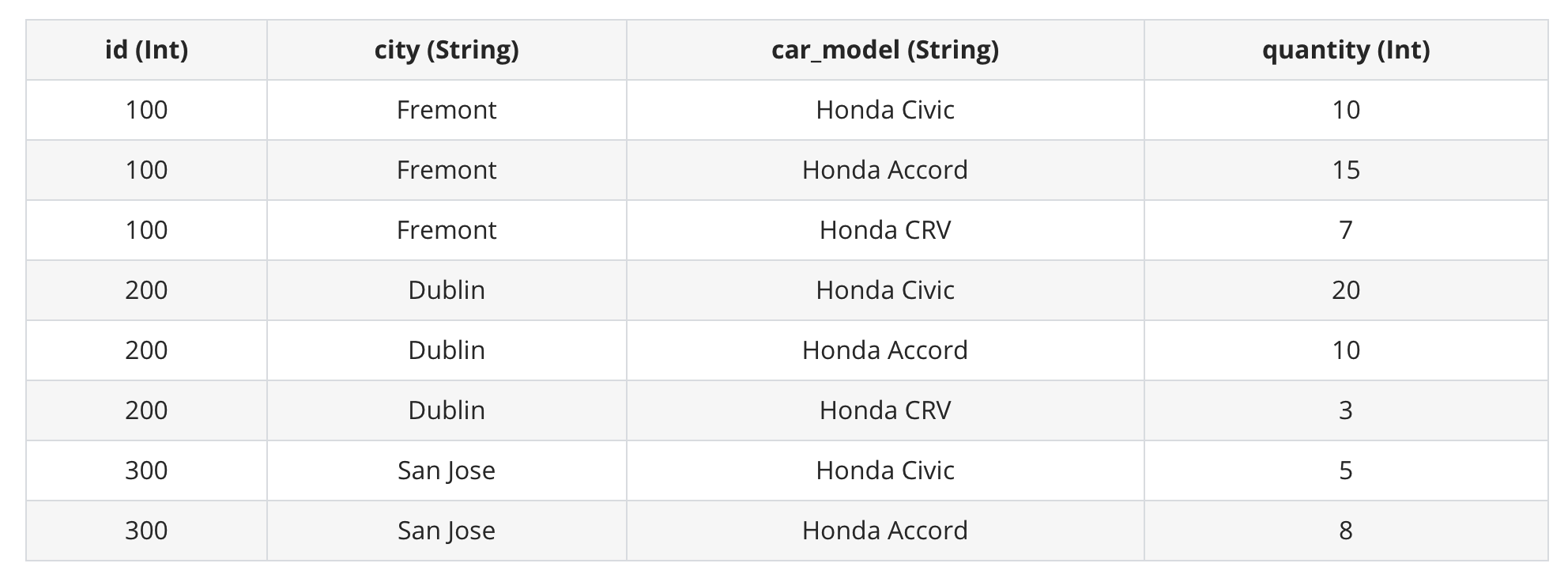
SELECT id, sum(quantity) FROM dealer GROUP BY id ORDER BY id+---+-------------+
| id|sum(quantity)|
+---+-------------+
|100| 32|
|200| 33|
|300| 13|
+---+-------------+
idquantityGroup ByGrouping SetsRollUpCubeRollUpCubeGrouping SetsGrouping SetsRollUpCubeGrouping SetsGrouping SetsGrouping Sets brief introduction
Grouping SetsUNION ALLUNION ALLGROUPING SETSGrouping SetsGroup ByGroup By dealerGroup By Grouping Sets ((city, car_model), (city), (car_model), ())Union All((Group By city, car_model), (Group By city), (Group By car_model), Global aggregation )spark-sql> SELECT city, car_model, sum(quantity) AS sum FROM dealer
> GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ())
> ORDER BY city, car_model;
+--------+------------+---+
| city| car_model|sum|
+--------+------------+---+
| null| null| 78|
| null|Honda Accord| 33|
| null| Honda CRV| 10|
| null| Honda Civic| 35|
| Dublin| null| 33|
| Dublin|Honda Accord| 10|
| Dublin| Honda CRV| 3|
| Dublin| Honda Civic| 20|
| Fremont| null| 32|
| Fremont|Honda Accord| 15|
| Fremont| Honda CRV| 7|
| Fremont| Honda Civic| 10|
|San Jose| null| 13|
|San Jose|Honda Accord| 8|
|San Jose| Honda Civic| 5|
+--------+------------+---+
spark-sql> (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL
> (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL
> (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL
> (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer)
> ORDER BY city, car_model;
+--------+------------+---+
| city| car_model|sum|
+--------+------------+---+
| null| null| 78|
| null|Honda Accord| 33|
| null| Honda CRV| 10|
| null| Honda Civic| 35|
| Dublin| null| 33|
| Dublin|Honda Accord| 10|
| Dublin| Honda CRV| 3|
| Dublin| Honda Civic| 20|
| Fremont| null| 32|
| Fremont|Honda Accord| 15|
| Fremont| Honda CRV| 7|
| Fremont| Honda Civic| 10|
|San Jose| null| 13|
|San Jose|Honda Accord| 8|
|San Jose| Honda Civic| 5|
+--------+------------+---+
Grouping Sets Implementation plan of
Grouping SetsUnion AllGrouping SetsUnion Allexplain extendedspark-sql> explain extended (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#93 ASC NULLS FIRST, car_model#94 ASC NULLS FIRST], true
+- Union false, false
:- Aggregate [city#93, car_model#94], [city#93, car_model#94, sum(quantity#95) AS sum#79L]
: +- Project [city#93, car_model#94, quantity#95]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#92, city#93, car_model#94, quantity#95], Partition Cols: []]
:- Aggregate [city#97], [city#97, null AS car_model#112, sum(quantity#99) AS sum#81L]
: +- Project [city#97, quantity#99]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#96, city#97, car_model#98, quantity#99], Partition Cols: []]
:- Aggregate [car_model#102], [null AS city#113, car_model#102, sum(quantity#103) AS sum#83L]
: +- Project [car_model#102, quantity#103]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#100, city#101, car_model#102, quantity#103], Partition Cols: []]
+- Aggregate [null AS city#114, null AS car_model#115, sum(quantity#107) AS sum#86L]
+- Project [quantity#107]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#104, city#105, car_model#106, quantity#107], Partition Cols: []]
== Physical Plan ==
...
- Execute each subquery statement , Calculate the query results . among , The logic of each query statement is like this :
- stayHiveTableRelationNode pair
dealerTable scanning .
- stayProjectThe node selects the columns related to the query statement results , For example, for sub query statements
SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer, Just keepquantityJust column .
- stayAggregateNode to complete
quantityColumn pair aggregation . In the above Plan in ,Aggregate Immediately following is the column used for grouping , such asAggregate [city#902]It means according tocityColumn to group .
- stayUnionThe node completes the union of each sub query result .
- Last , staySortThe node finishes sorting the data , Above Plan in
Sort [city#93 ASC NULLS FIRST, car_model#94 ASC NULLS FIRST]It means according tocityandcar_modelSort columns in ascending order .

explain extendedspark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST], true
+- Aggregate [city#138, car_model#139, spark_grouping_id#137L], [city#138, car_model#139, sum(quantity#133) AS sum#124L]
+- Expand [[quantity#133, city#131, car_model#132, 0], [quantity#133, city#131, null, 1], [quantity#133, null, car_model#132, 2], [quantity#133, null, null, 3]], [quantity#133, city#138, car_model#139, spark_grouping_id#137L]
+- Project [quantity#133, city#131, car_model#132]
+- HiveTableRelation [`default`.`dealer`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [id#130, city#131, car_model#132, quantity#133], Partition Cols: []]
== Physical Plan ==
...
- stayHiveTableRelationNode pair
dealerTable scanning .
- stayProjectThe node selects the columns related to the query statement results .
- NextExpandNodes are the key , After the data passes through this node , There's more
spark_grouping_idColumn . from Plan You can see that ,Expand The node containsGrouping SetsEvery one of them grouping set Information , such as[quantity#133, city#131, null, 1]The corresponding is(city)this grouping set. and , Every grouping set Correspondingspark_grouping_idThe values of the columns are fixed , such as(city)Correspondingspark_grouping_idby1.
- stayAggregateNode to complete
quantityColumn pair aggregation , The grouping rule iscity, car_model, spark_grouping_id. Be careful , Data after Aggregate After node ,spark_grouping_idThe column was deleted !
- Last , staySortThe node finishes sorting the data .

spark_grouping_idspark_grouping_id- Expand What is the implementation logic of , Why can we achieve
Union AllThe effect of ?
- Expand What is the output data of the node?
spark_grouping_idWhat is the function of columns?
Expand== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Sort [city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=422]
+- HashAggregate(keys=[city#138, car_model#139, spark_grouping_id#137L], functions=[sum(quantity#133)], output=[city#138, car_model#139, sum#124L])
+- Exchange hashpartitioning(city#138, car_model#139, spark_grouping_id#137L, 200), ENSURE_REQUIREMENTS, [plan_id=419]
+- HashAggregate(keys=[city#138, car_model#139, spark_grouping_id#137L], functions=[partial_sum(quantity#133)], output=[city#138, car_model#139, spark_grouping_id#137L, sum#141L])
+- Expand [[quantity#133, city#131, car_model#132, 0], [quantity#133, city#131, null, 1], [quantity#133, null, car_model#132, 2], [quantity#133, null, null, 3]], [quantity#133, city#138, car_model#139, spark_grouping_id#137L]
+- Scan hive default.dealer [quantity#133, city#131, car_model#132], HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#130, city#131, car_model#132, quantity#133], Partition Cols: []]
ExpandExpand The realization of operators
ExpandExecXxxExecXxxProjectExec/**
* Apply all of the GroupExpressions to every input row, hence we will get
* multiple output rows for an input row.
* @param projections The group of expressions, all of the group expressions should
* output the same schema specified bye the parameter `output`
* @param output The output Schema
* @param child Child operator
*/
case class ExpandExec(
projections: Seq[Seq[Expression]],
output: Seq[Attribute],
child: SparkPlan)
extends UnaryExecNode with CodegenSupport {
...
// Key points 1, take child.output, That is, the output data of the upstream operator schema,
// Bound to an expression array exprs, To calculate the output data
private[this] val projection =
(exprs: Seq[Expression]) => UnsafeProjection.create(exprs, child.output)
// doExecute() Method is Expand Where the operator executes logic
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
// Processing the output data of upstream operators ,Expand The input data of the operator starts from iter Iterator gets
child.execute().mapPartitions { iter =>
// Key points 2,projections Corresponding Grouping Sets Each of them grouping set The expression of ,
// Expression output data schema by this.output, such as (quantity, city, car_model, spark_grouping_id)
// The logic here is to generate a UnsafeProjection object , Through the apply The method will lead to Expand The output data of the operator
val groups = projections.map(projection).toArray
new Iterator[InternalRow] {
private[this] var result: InternalRow = _
private[this] var idx = -1 // -1 means the initial state
private[this] var input: InternalRow = _
override final def hasNext: Boolean = (-1 < idx && idx < groups.length) || iter.hasNext
override final def next(): InternalRow = {
// Key points 3, For each record of input data , Are reused N Time , among N The size of corresponds to projections Size of array ,
// That is to say Grouping Sets In the specified grouping set The number of
if (idx <= 0) {
// in the initial (-1) or beginning(0) of a new input row, fetch the next input tuple
input = iter.next()
idx = 0
}
// Key points 4, For each record of input data , adopt UnsafeProjection Calculate the output data ,
// Every grouping set Corresponding UnsafeProjection Will be the same input Do a calculation
result = groups(idx)(input)
idx += 1
if (idx == groups.length && iter.hasNext) {
idx = 0
}
numOutputRows += 1
result
}
}
}
}
...
}
ExpandExec Key points 1 Key points 2 Key points 2groupsUnsafeProjection[N]UnsafeProjectionGrouping Sets// A projection that returns UnsafeRow.
abstract class UnsafeProjection extends Projection {
override def apply(row: InternalRow): UnsafeRow
}
// The factory object for `UnsafeProjection`.
object UnsafeProjection
extends CodeGeneratorWithInterpretedFallback[Seq[Expression], UnsafeProjection] {
// Returns an UnsafeProjection for given sequence of Expressions, which will be bound to
// `inputSchema`.
def create(exprs: Seq[Expression], inputSchema: Seq[Attribute]): UnsafeProjection = {
create(bindReferences(exprs, inputSchema))
}
...
}
UnsafeProjectionapplyexprsinputSchemaGROUPING SETS ((city, car_model), (city), (car_model), ())groups
AttributeReferenceIteral Key points 3 Key points 4ExpandExec Key points 4groups(idx)(input)groups(idx).apply(input)GROUPING SETS ((city, car_model), (city), (car_model), ())
- Expand What is the implementation logic of , Why can we achieve
Union AllThe effect of ?
- if
Union AllIt is to aggregate first and then unite , that Expand Is to unite first and then aggregate .Expand utilizegroupsInside N An expression evaluates each input record , Expanded into N Output records . When we aggregate later , Can achieve andUnion AllThe same effect .
- Expand What is the output data of the node?
- stay schema On ,Expand The output data will be more than the input data
spark_grouping_idColumn ; On the record number , Is the number of input data records N times .
spark_grouping_idWhat is the function of columns?
spark_grouping_idFor each grouping set Number , such , Even in Expand The stage combines the data first , stay Aggregate Stage ( holdspark_grouping_idAdd to the grouping rule ) It can also ensure that the data can be in accordance with each grouping set Aggregate separately , Ensure the correctness of the results .
Query performance comparison
// Grouping Sets Version execution 10 Time consuming information
// SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) ORDER BY city, car_model;
Time taken: 0.289 seconds, Fetched 15 row(s)
Time taken: 0.251 seconds, Fetched 15 row(s)
Time taken: 0.259 seconds, Fetched 15 row(s)
Time taken: 0.258 seconds, Fetched 15 row(s)
Time taken: 0.296 seconds, Fetched 15 row(s)
Time taken: 0.247 seconds, Fetched 15 row(s)
Time taken: 0.298 seconds, Fetched 15 row(s)
Time taken: 0.286 seconds, Fetched 15 row(s)
Time taken: 0.292 seconds, Fetched 15 row(s)
Time taken: 0.282 seconds, Fetched 15 row(s)
// Union All Version execution 10 Time consuming information
// (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) ORDER BY city, car_model;
Time taken: 0.628 seconds, Fetched 15 row(s)
Time taken: 0.594 seconds, Fetched 15 row(s)
Time taken: 0.591 seconds, Fetched 15 row(s)
Time taken: 0.607 seconds, Fetched 15 row(s)
Time taken: 0.616 seconds, Fetched 15 row(s)
Time taken: 0.64 seconds, Fetched 15 row(s)
Time taken: 0.623 seconds, Fetched 15 row(s)
Time taken: 0.625 seconds, Fetched 15 row(s)
Time taken: 0.62 seconds, Fetched 15 row(s)
Time taken: 0.62 seconds, Fetched 15 row(s)
RollUp and Cube
Group ByRollUpCubeRollUpRollUpROLLUPGROUPING SETSRollUpGrouping SetsRollUp(A, B, C) == Grouping Sets((A, B, C), (A, B), (A), ())Group By RollUp(city, car_model)Group By Grouping Sets((city, car_model), (city), ())expand extendedspark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY ROLLUP(city, car_model) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#2164 ASC NULLS FIRST, car_model#2165 ASC NULLS FIRST], true
+- Aggregate [city#2164, car_model#2165, spark_grouping_id#2163L], [city#2164, car_model#2165, sum(quantity#2159) AS sum#2150L]
+- Expand [[quantity#2159, city#2157, car_model#2158, 0], [quantity#2159, city#2157, null, 1], [quantity#2159, null, null, 3]], [quantity#2159, city#2164, car_model#2165, spark_grouping_id#2163L]
+- Project [quantity#2159, city#2157, car_model#2158]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#2156, city#2157, car_model#2158, quantity#2159], Partition Cols: []]
== Physical Plan ==
...
RollUpRollUpGrouping SetsExpand [[quantity#2159, city#2157, car_model#2158, 0], [quantity#2159, city#2157, null, 1], [quantity#2159, null, null, 3]]RollUpCubeCubeCUBEGROUP BYCUBEGROUPING SETSCubeGrouping SetsCube(A, B, C) == Grouping Sets((A, B, C), (A, B), (A, C), (B, C), (A), (B), (C), ())Group By Cube(city, car_model)Group By Grouping Sets((city, car_model), (city), (car_model), ())expand extendedspark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY CUBE(city, car_model) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#2202 ASC NULLS FIRST, car_model#2203 ASC NULLS FIRST], true
+- Aggregate [city#2202, car_model#2203, spark_grouping_id#2201L], [city#2202, car_model#2203, sum(quantity#2197) AS sum#2188L]
+- Expand [[quantity#2197, city#2195, car_model#2196, 0], [quantity#2197, city#2195, null, 1], [quantity#2197, null, car_model#2196, 2], [quantity#2197, null, null, 3]], [quantity#2197, city#2202, car_model#2203, spark_grouping_id#2201L]
+- Project [quantity#2197, city#2195, car_model#2196]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#2194, city#2195, car_model#2196, quantity#2197], Partition Cols: []]
== Physical Plan ==
...
CubeCubeGrouping SetsRollUpCubeGrouping SetsLast
Group ByGroupings SetsGroupings SetsUnion AllGrouping Setsspark_grouping_idUnion AllGrouping SetsGroup ByRollUpCubeGrouping SetsGrouping SetsArticle with pictures
Reference resources
边栏推荐
- 面试官:JVM如何分配和回收堆外内存
- Why can't strings be directly compared with equals; Why can't some integers be directly compared with the equal sign
- 大csv拆分和合并
- 如何在本机搭建SVN服务器
- 阿飞的期望
- Go语言自学系列 | golang switch语句
- Chinese translation of Tagore's floating birds (1~10)
- 坚持输出需要不断学习
- 几种常见IO模型的原理
- Redis installation under windows and Linux systems
猜你喜欢

Redis在Windows以及Linux系统下的安装

嵌入式开发:避免开源软件的7个理由
How idea starts run dashboard

App移动端测试【5】文件的写入、读取
【声明】关于检索SogK1997而找到诸多网页爬虫结果这件事

Microservice - declarative interface call openfeign

请做好3年内随时失业的准备?
App mobile terminal test [5] file writing and reading

From the 18th line to the first line, the new story of the network security industry

Automatic generation of client code from flask server code -- Introduction to flask native stubs Library
随机推荐
请求头不同国家和语言的表示
Pandora IOT development board learning (HAL Library) - Experiment 5 external interrupt experiment (learning notes)
Persisting in output requires continuous learning
TCP擁塞控制詳解 | 3. 設計空間
Redis在Windows以及Linux系统下的安装
[combinatorics] combinatorial identity (sum of variable upper terms 1 combinatorial identity | summary of three combinatorial identity proof methods | proof of sum of variable upper terms 1 combinator
[web security] - [SQL injection] - error detection injection
How to use AAB to APK and APK to AAB of Google play apps on the shelves
【Proteus仿真】8×8LED点阵屏仿电梯数字滚动显示
The difference between calling by value and simulating calling by reference
探索Cassandra的去中心化分布式架构
Reading notes of "micro service design" (Part 2)
June to - -------
Function introduction of JMeter thread group
Embedded development: seven reasons to avoid open source software
[list to map] collectors Tomap syntax sharing (case practice)
Semi supervised learning
[proteus simulation] 74hc595+74ls154 drive display 16x16 dot matrix
"Everyday Mathematics" serial 56: February 25
2022年Q2加密市场投融资报告:GameFi成为投资关键词