当前位置:网站首页>Sql分组查询后取每组的前N条记录
Sql分组查询后取每组的前N条记录
2020-11-09 10:51:00 【osc_um3gbrdm】
目录
一、背景
最近,在开发中遇到个功能需求。系统有个资讯查询模块,要求资讯按照卡片形式展示。如下图:
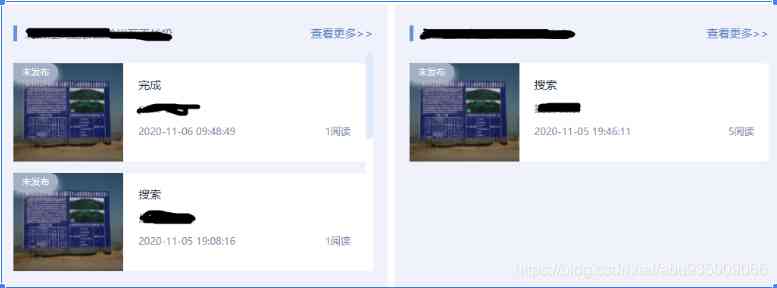
按照项目组展示卡片,每个项目组展示阅读量最多的TOP2。
需求解析:按照项目组分组,然后取每组阅读量最多的前2条。
二、实战解析
基于Mysql数据库
表定义
1、项目组:team
| id |
主键 |
| name |
项目组名称 |
2、资讯表:info
| id |
主键 |
| team_id |
项目组id |
| title |
资讯名称 |
| pageviews |
浏览量 |
| content |
资讯内容 |
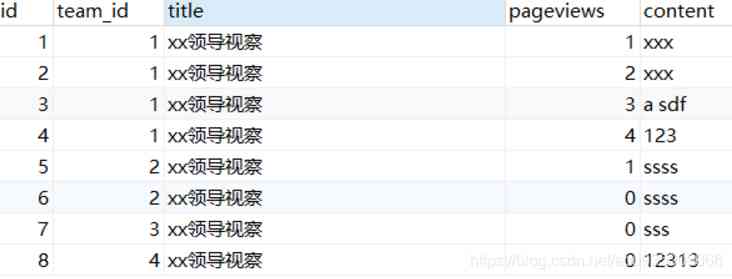
info表数据如下图:
我们先预习下Select基础知识
书写顺序:
select *columns*
from *tables*
where *predicae1*
group by *columns*
having *predicae1*
order by *columns*
limit *start*, *offset*;执行顺序:
from *tables*
where *predicae1*
group by *columns*
having *predicae1*
select *columns*
order by *columns*
limit *start*, *offset*;
count(字段名) # 返回表中该字段总共有多少条记录
DISTINCT 字段名 # 过滤字段中的重复记录
第一步:先找出资讯表中阅读量的前二名
info资讯表自关联
SELECT a.*
FROM info a
WHERE (
SELECT count(DISTINCT b.pageviews)
FROM info b
WHERE a.pageviews < b.pageviews AND a.team_id= b.team_id
) < 2 ;乍一看不好理解,下面举例说明
举个例子:
当阅读量pageviews a = b = [1,2,3,4]
a.pageviews = 1,b.pageviews 可以取值 [2,3,4],count(DISTINCT b.pageviews) = 3
a.pageviews = 2,b.pageviews 可以取值 [3,4],count(DISTINCT b.pageviews) = 2 # 有2条,即第三名
a.pageviews = 3,b.pageviews 可以取值 [4],count(DISTINCT b.pageviews) = 1 # 有1条,即第二名
a.pageviews = 4,b.pageviews 可以取值 [],count(DISTINCT b.pageviews) = 0 # 有0条,即最大 第一名count(DISTINCT b.pageviews) 代表有几个比这条值大
a.team_id= b.team_id 自关联条件,约等于分组
所以前二名 等价于 count(DISTINCT e2.Salary) < 2 ,所以 a.pageviews 可取值为 3、4,即集合前 2 高
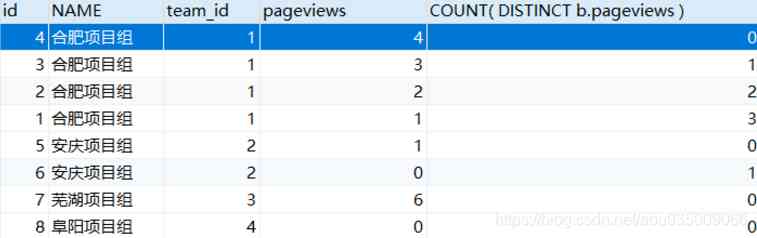
第二步:再把表 team和表 info连接
SELECT a.id, t.NAME, a.team_id, a.pageviews
FROM info a
LEFT JOIN team t ON a.team_id = t.id
WHERE (
SELECT count(DISTINCT b.pageviews)
FROM info b
WHERE a.pageviews < b.pageviews AND a.team_id= b.team_id) < 2
ORDER BY a.team_id, a.pageviews desc结果如下图:
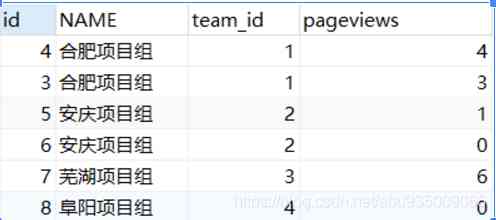
还有一种好理解的方式:
分组GROUP BY + HAVING,这种方式可以一步一步方便调试结果
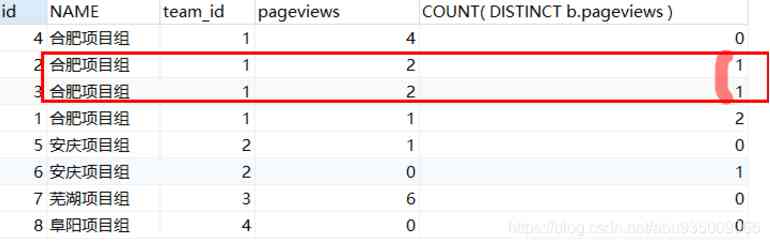
SELECT a.id, t.NAME, a.team_id, a.pageviews, COUNT( DISTINCT b.pageviews )
FROM info a
LEFT JOIN info b ON ( a.pageviews < b.pageviews AND a.team_id = b.team_id )
LEFT JOIN team t ON a.team_id = t.id
GROUP BY a.id, t.NAME, a.team_id, a.pageviews
HAVING COUNT( DISTINCT b.pageviews ) < 2
ORDER BY a.team_id, a.pageviews DESC问题:如果出现阅读数相同的情况,就裂开了。
举例说明:
当阅读量pageviews a = b = [1,2,2,4]
a.pageviews = 1,b.pageviews 可以取值 [2,2,4],count(DISTINCT b.pageviews) = 3
a.pageviews = 2,b.pageviews 可以取值 [4],count(DISTINCT b.pageviews) = 1 # 有1条,即并列第二名
a.pageviews = 2,b.pageviews 可以取值 [4],count(DISTINCT b.pageviews) = 1 # 有1条,即第二名
a.pageviews = 4,b.pageviews 可以取值 [],count(DISTINCT b.pageviews) = 0 # 有0条,即最大 第一名count(DISTINCT e2.Salary) < 2 ,所以 a.pageviews 可取值为 2、2、4,即集合前 2 高,但是有三条数据
三、总结
需求转化:将分组求前几条,改为了自关联后,有几条数据比这条大
其实这个是类似LeetCode上难度为hard的一道数据库题目
参考:
版权声明
本文为[osc_um3gbrdm]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4267090/blog/4708807
边栏推荐
- Log analysis tool - goaccess
- Concurrent linked queue: a non blocking unbounded thread safe queue
- In 2020, what are the best tools for Android developers to break the cold winter?
- 推荐系统,深度论文剖析GBDT+LR
- Composition - API
- Apache Iceberg 中三种操作表的方式
- Application of cloud gateway equipment on easynts in Xueliang project
- 20201108 programming exercise exercise 3
- LTM understanding and configuration notes
- Detailed analysis of OpenGL es framework (8) -- OpenGL es Design Guide
猜你喜欢

GitHub 上适合新手的开源项目(Python 篇)
Log analysis tool - goaccess
Platform in architecture
Common feature pyramid network FPN and its variants

GDI 及OPENGL的区别
The vowels in the inverted string of leetcode
20201108编程练习——练习3
商品管理系统——整合仓库服务以及获取仓库列表
File queue in Bifrost (1)
When iperf is installed under centos7, the solution of make: * no targets specified and no makefile found. Stop
随机推荐
无法启动此程序,因为计算机中丢失 MSVCP120.dll。尝试安装该程序以解决此问题
Mac 终端(terminal) oh-my-zsh+solarized配置
Elasticsearch原理解析与性能调优
The difference between GDI and OpenGL
使用流读文件写文件处理大文件
Composition - API
Several rolling captions based on LabVIEW
20201108 programming exercise exercise 3
GLSB涉及负载均衡算法
A brief introduction of C code to open or close the firewall example
The whole process of building a fully distributed cluster
Principle analysis and performance tuning of elasticsearch
使用rem,做到屏幕缩放时,字体大小随之改变
LTM理解及配置笔记记录
Ten year itch of programmer
Application of cloud gateway equipment on easynts in Xueliang project
Windows环境下如何进行线程Dump分析
23 pictures, take you to the recommended system
上周热点回顾(11.2-11.8)
Adding OpenGL form to MFC dialog