当前位置:网站首页>The whole process of building a fully distributed cluster
The whole process of building a fully distributed cluster
2020-11-09 08:20:00 【osc_ychelles】
Full distributed, full step
Three machines , Respectively hdp01,hdp02,hdp03
The idea is to configure first hdp01, Clone again hdp02,hdp03
One . build hdp01
1. Turn off firewall ( There will be delays in general , Even if you turn off the firewall, you can still view the status , Restart can be seen in the state is OK )
systemctl disable firewalld
Check status
systemctl status firewalld
reboot -h now---- Restart the computer
2. Change ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
Six places need to be changed
1.BOOTPROTO=static
2.ONBOOT=yes
3.IPADDR=192.168.73.102
4.NETMASK=255.255.255.0
5.GATEWAY=192.168.73.2
6.DNS1=8.8.8.8
DNS2=114.114.114.114
It's over ip Be sure to restart the network , Otherwise it will not take effect
systemctl restart network
Restart the network and check again ip
ip addr
3. Change host name ( The first one doesn't have to be changed )
hostnamectl set-hostname hdp02
You can check , use hostname command
4. Change the mapping file
vi /etc/hosts
5. If you connect to a remote finalshell Software etc. , Change local host file
C:\Windows\System32\drivers\etc\host
6. Write the secret key
ssh-keygen -t rsa
cd .ssh You can see that the public key and private key are generated
If you are datenode, Also must do to oneself do not secret ( As long as slaves All of them are datenode)
ssh-copy-id localhost
7. install jdk and hadoop
Extract to the directory you want to extract
tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/
You can change your name , The name is too long
mv hadoop-2.7.6/ hadoop
7.1 install ntp ntpdate Source , When you set up a cluster , Time synchronization with
# yum -y install ntp ntpdate
8. Configure environment variables
vi /etc/profile
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile( You have to refresh , Otherwise, the environment variable doesn't work )
Check if it is installed as
java -version
hadoop vesion
9. Change profile
vi core-site.xml
<configuration>
<property>
<!-- hdfs Address name of :schame,ip,port Because of my mapping file IP Mapped to the host name -->
<name>fs.defaultFS</name>
<value>hdfs://hdp01:8020</value>
</property>
<property>
<!-- hdfs The basic path , A base path that is dependent on other properties Here is metadata and other information -->
<name>hadoop.tmp.dir</name>
<value>/usr/local/tmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
# The one that holds metadata fsimage
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
# Storage location of blocks
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<property>
# Number of copies
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
# The size of the block
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdp02:50090</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///${hadoop.tmp.dir}/checkpoint/dfs/cname</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///${hadoop.tmp.dir}/checkpoint/dfs/cname</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hdp01:50070</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml This file does not have
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp01:19888</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!-- Appoint yarn Of shuffle technology -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Appoint resourcemanager The host name -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>qianfeng01</value> </property>
<!-- The following options --> <!-- Appoint shuffle The corresponding class -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- To configure resourcemanager Internal address of -->
<property>
<name>yarn.resourcemanager.address</name>
<value>qianfeng01:8032</value>
</property>
<!-- To configure resourcemanager Of scheduler Internal address of -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>qianfeng01:8030</value>
</property>
<!-- To configure resoucemanager Internal address of resource scheduling for -->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>qianfeng01:8031</value>
</property>
<!-- To configure resourcemanager The internal address of the administrator -->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>qianfeng01:8033</value>
</property>
<!-- To configure resourcemanager Of web ui Monitoring page of -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>qianfeng01:8088</value>
</property>
</configuration>
hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
vi slaves( Here is datanode)
hdp01
hdp02
hdp03
Two . clone
Try to remember the snapshot
close hdp01, clone hdp02,hdp03
Change ip
Change host name
3. Set up the cluster
1. Time synchronization
Time synchronization detailed configuration
2. format namenode
hdfs namenode -format
3. Start cluster
The startup script -- start-dfs.sh Used to start hdfs The script for the cluster
start-yarn.sh : Used to start yarn Daemon
start-all.sh : Used to start hdfs and yarn
4. test
(1) Build on distributed systems input Folder
hdfs dfs -mkdir /input
(2) Upload the file at will
hdfs dfs -put a.txt /input
(3) test , They sealed us up mapreduce Small feature , Check the number of words
/usr/local/hadoop/share/hadoop/mapreduce( The small function rack bag is all here )
Be sure to look good at the path when you execute , and output We can't build it ourselves , You have to generate , Otherwise, it will report a mistake
hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
版权声明
本文为[osc_ychelles]所创,转载请带上原文链接,感谢
边栏推荐
- Why don't we use graphql? - Wundergraph
- 代码保存
- How does pipedrive support quality publishing with 50 + deployments per day?
- Salesforce connect & external object
- object
- This program cannot be started because msvcp120.dll is missing from your computer. Try to install the program to fix the problem
- WordPress Import 上传的文件尺寸超过php.ini中定义的upload_max_filesize值--&gt;解决方法。
- 六家公司CTO讲述曾经历的“宕机噩梦”
- SaaS: another manifestation of platform commercialization capability
- 梁老师小课堂|谈谈模板方法模式
猜你喜欢

C + + adjacency matrix
android开发中提示:requires permission android.permission write_settings解决方法
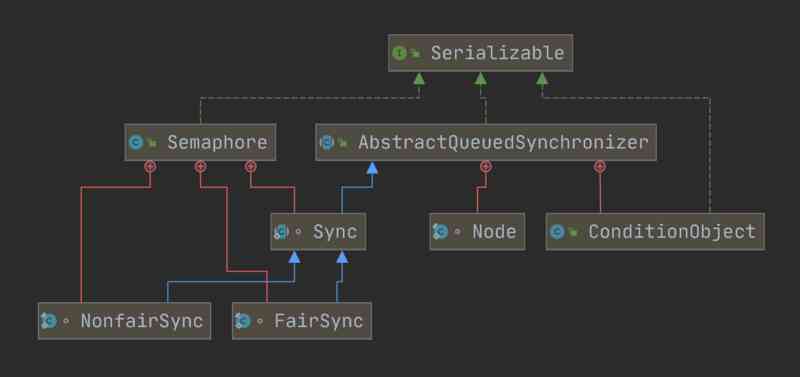
使用递增计数器的线程同步工具 —— 信号量,它的原理是什么样子的?
首次开通csdn,这篇文章送给过去的自己和正在发生的你
LTM理解及配置笔记记录
3.你知道计算机是如何启动的吗?

C / C + + Programming Notes: pointer! Understand pointer from memory, let you understand pointer completely
Installation record of SAP s / 4hana 2020
1. What does the operating system do?
Several rolling captions based on LabVIEW
随机推荐
python生日贺卡制作以及细节问题的解决最后把python项目发布为exe可执行程序过程
六家公司CTO讲述曾经历的“宕机噩梦”
Tips in Android Development: requires permission android.permission write_ Settings solution
leetcode之反转字符串中的元音字母
平台商业化能力的另一种表现形式SAAS
梁老师小课堂|谈谈模板方法模式
作业2020.11.7-8
23张图,带你入门推荐系统
14. Introduction to kubenetes
你有没有想过为什么交易和退款要拆开不同的表
For the first time open CSDN, this article is for the past self and what is happening to you
2020,Android开发者打破寒冬的利器是什么?
How does pipedrive support quality publishing with 50 + deployments per day?
C / C + + Programming Notes: pointer! Understand pointer from memory, let you understand pointer completely
首次开通csdn,这篇文章送给过去的自己和正在发生的你
This program cannot be started because msvcp120.dll is missing from your computer. Try to install the program to fix the problem
Android emulator error: x86 emulation currently requires hardware acceleration的解决方案
图节点分类与消息传递 - 知乎
2.计算机硬件简介
2 普通模式