CUDA It has its own memory model , At execution time, the thread will access the data in different memory spaces .cuda Application development involves 8 Medium memory , The hierarchical results are shown in the figure :
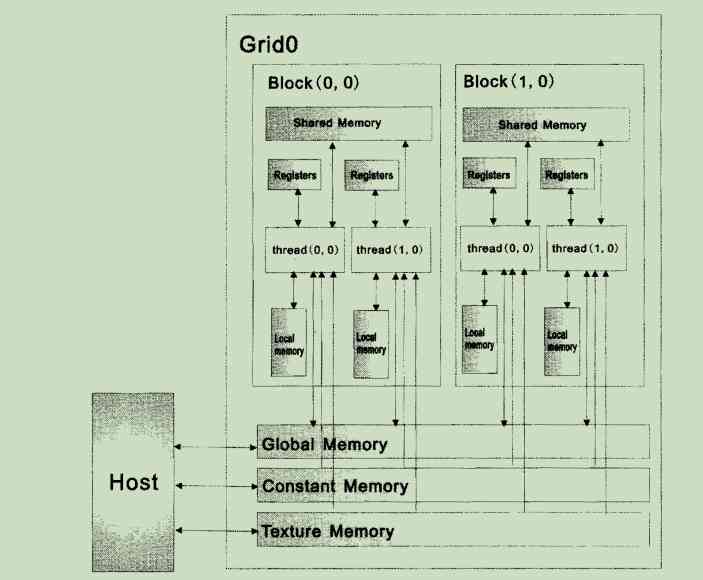
Each thread has its own private memory register and local memory ; Each thread block has a shared memory (shared_memory); Last ,grid All threads in can access the same global memory (global memory). besides , There are also two types of read-only memory that can be accessed by all threads : Constant memory (constant memory) And texture memory (Texture memory), They optimized for different applications . Global memory 、 The values in constant memory and texture memory will be maintained after a kernel function is executed , Can be called by other kernel functions in the same program .
Compare all kinds of memory :
| Memory | Location | Having a cache | Access right | Variable life cycle |
|---|---|---|---|---|
| register | GPU Intraslice | N/A | device Can be read / Write | And thread identical |
| local_memory | On board video memory | nothing | device Can be read / Write | And thread identical |
| shared_memory | CPU Intraslice | N/A | device Can be read / Write | And block identical |
| constant_memory | On board video memory | Yes | device Can be read ,host Can be read / Write | Can be maintained in the program |
| texture_memory | On board video memory | Yes | device Can be read ,host Can be read / Write | Can be maintained in the program |
| global_memory | On board video memory | nothing | device Can be read / Write ,host Can be read / Write | Can be maintained in the program |
| host_memory | host Memory | nothing | host Can be read / Write | Can be maintained in the program |
| pinned_memory | host Memory | nothing | host Can be read / Write | Can be maintained in the program |
explain
(1)Register and shared_memory All are GPU High speed memory on a chip ;
(2) adopt mapped memory Realized zero copy function , Some functions GPU Can be directly in kernel Medium visit page-locked memory.
GPU What is performed is a load of memory / The storage model (load-storage model), That is, all operations must be executed after the instruction is loaded into the register , So master GPU The memory model of is for GPU The optimization of code performance is of great significance .