当前位置:网站首页>Redis集群(docker版)——从原理到实战超详细
Redis集群(docker版)——从原理到实战超详细
2022-08-05 05:16:00 【呆比特】
Redis集群(docker版)——从原理到实战超详细
一、问题:1~2亿数据如何缓存?
分布式存储,Redis实现方案常见有三种:
哈希取余分区
原理:
在一个Redis集群中,用户每次读写操作都根据公式:hash(key)/ n ,决定数据映射到哪一个节点上;
优点:
简单有效,只需要预估好数据,规划好节点,就能保证一段时间的数据支撑
使用Hash算法让固定的一部分请求落到同一台服务器上,起到负载均衡、分而治之的作用。
缺点:
扩缩容比较麻烦,每次数据变动导致节点有变动,映射关系就需要重新进行计算
某台机器宕机,机器数量就发生了变化,公式计算结果全部改变
一致性哈希算法分区
原理:
首先,将0~2^32看做一个首位相接的环
然后有一个hash函数,根据各个节点的ip,将集群中各个节点映射到环上的某一个位置:hash(ip)% 2^32
当我们要存储一个k-v时,首先计算k的哈希值(hash(k)),然后从环上的这个哈希值位置开始顺时针行走,
遇到的第一个节点就是应该存储的节点。
优点:
容错性:某节点宕机,只会影响环上本节点顺时针前后节点之间的数据,并将这些数据保存到了本节点的下一个节点,其他数据无影响
扩展性:如果在A、B节点之间增加一台节点C,只有A到C之间的数据收到影响,把A到C的数据从B转移到C即可
缺点:
节点太少时,容易因为节点分布不均匀而造成数据倾斜
哈希槽分区
原理:
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,
这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。
优点:
解决了均匀分配的问题
在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系
二、Redis集群搭建(3主3从)
1. 关闭防火墙,启动docker后台服务
systemctl stop firewalld
#永久关闭
systemctl disable firewalld
#查看防火墙状态
systemctl status firewalld
systemctl start docker

2. 新建6个docker容器redis实例
#命令解释:
#docker run --> 创建并运行docker容器实例
#--name redis-node-1 --> 容器名
#--net host --> 默认使用宿主机的ip和端口
#--privileged=true --> 获取root权限
#-v /data/redis/share/redis-node-1:/data --> 容器卷:宿主机地址:docker内部地址
#--cluster-enabled yes --> 开启redis集群
#--appendonly yes --> 开启持久化
#--port 6381 --> redis端口号
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386

3. 构建集群关系
#进入redis-node-1容器
docker exec -it redis-node-1 /bin/bash
#构建关系,ip地址改为自己的
redis-cli --cluster create 192.168.189.131:6381 192.168.189.131:6382 192.168.189.131:6383 192.168.189.131:6384 192.168.189.131:6385 192.168.189.131:6386 --cluster-replicas 1
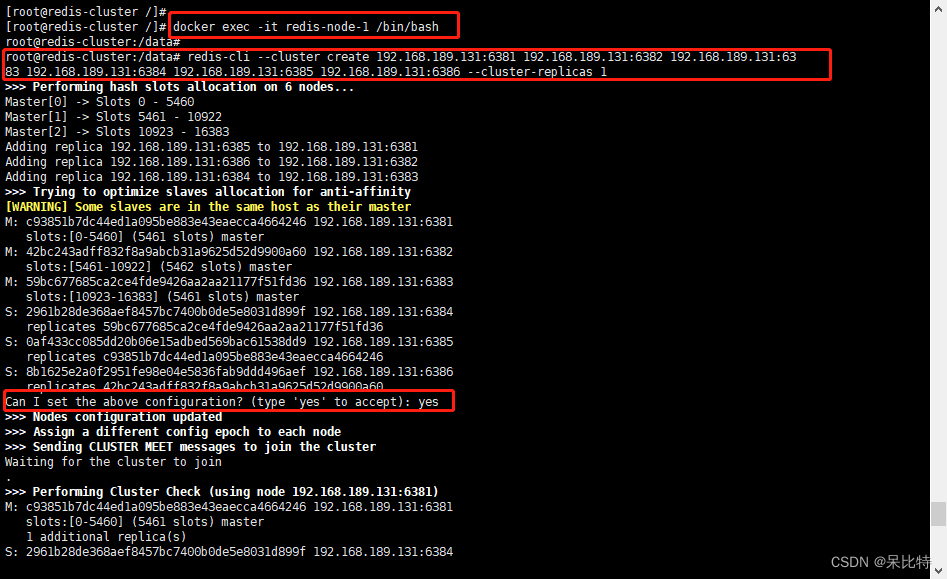
进入6381,查看节点状态
redis-cli -p 6381
cluster info
cluster nodes
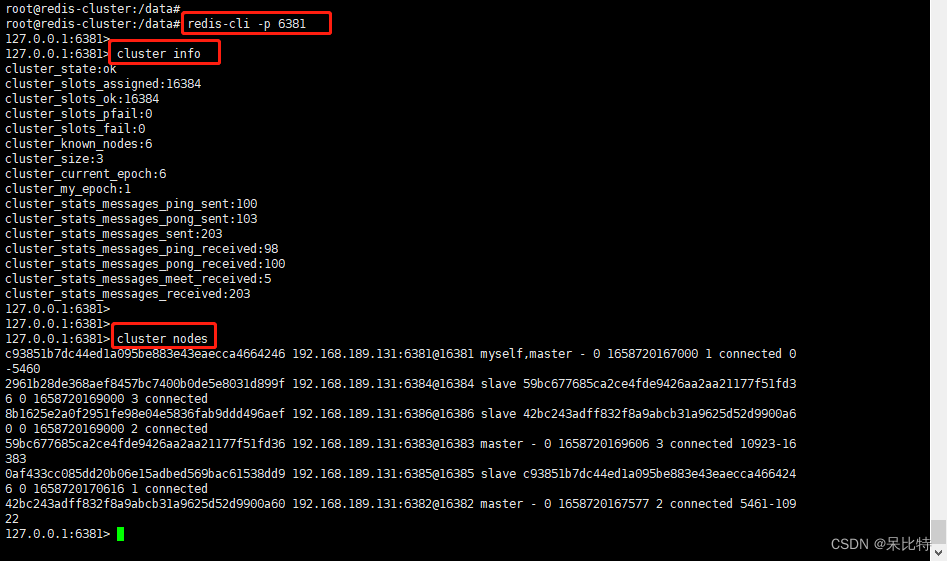
节点关系
主: 6381 -----从: 6385
主: 6383 -----从: 6384
主: 6382 -----从: 6386
三、主从容错切换迁移
1. 数据读写存储
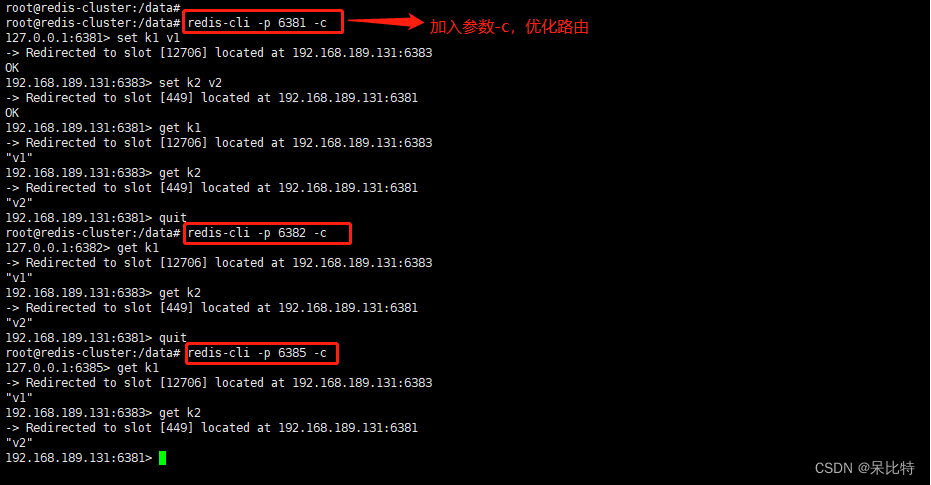
2. 容错切换迁移
停止主机6381,从机6385自动顶上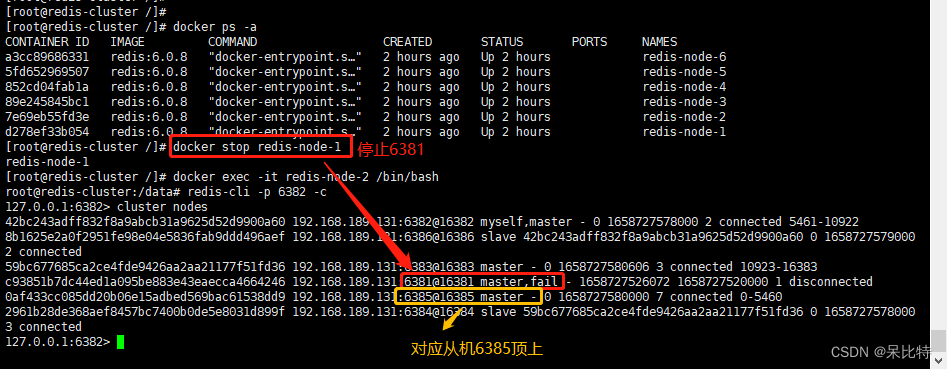
主机6381恢复,主从关系恢复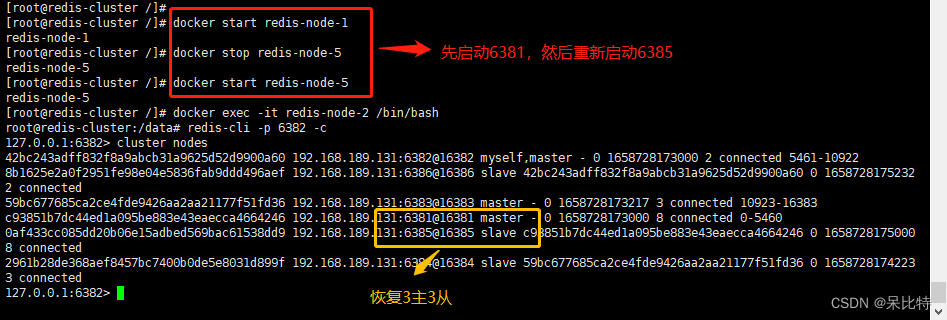
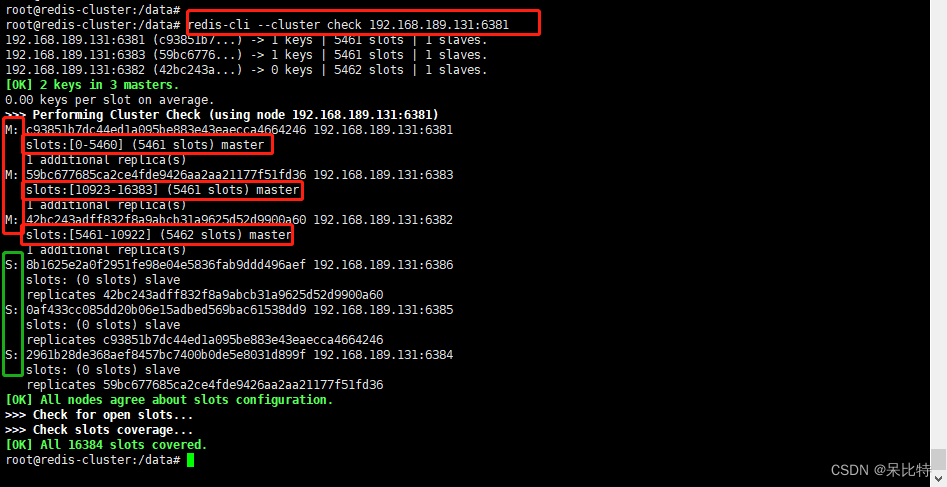
查看集群状态
#redis-cli --cluster check 自己ip:6381
redis-cli --cluster check 192.168.189.131:6381
四、主从扩容
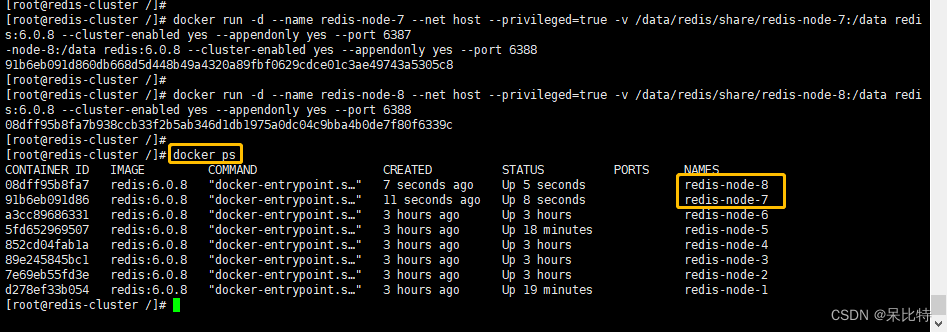
1. 新建 6387、6388节点
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
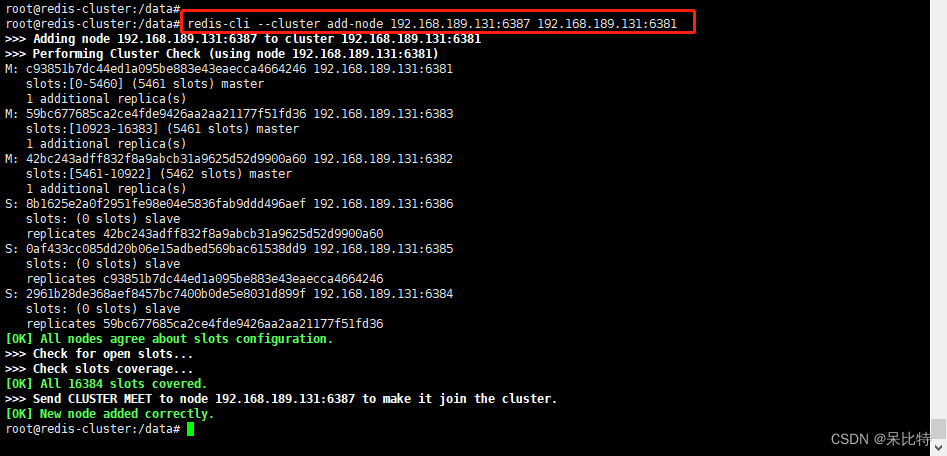
2. 进入6387,将6387作为master加入原集群
docker exec -it redis-node-7 /bin/bash
# redis-cli --cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381
redis-cli --cluster add-node 192.168.189.131:6387 192.168.189.131:6381
3. 第一次检查集群情况
redis-cli --cluster check 192.168.189.131:6381
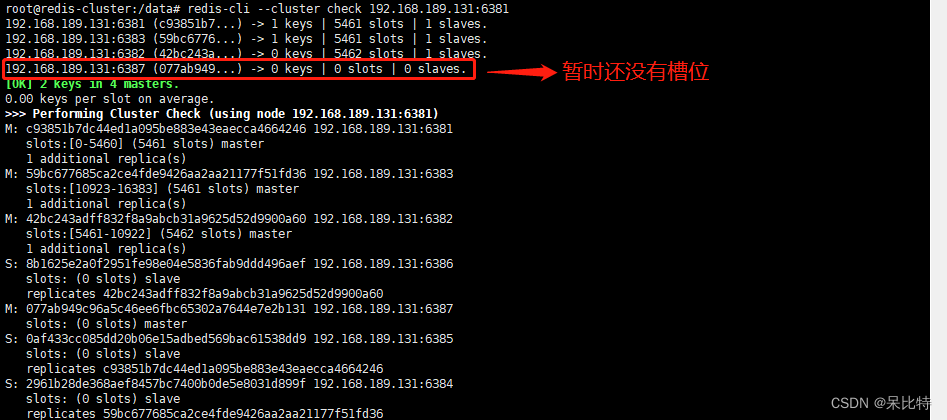
4. 重新分配槽位
#命令:redis-cli --cluster reshard IP地址:端口号
redis-cli --cluster reshard 192.168.189.131:6381
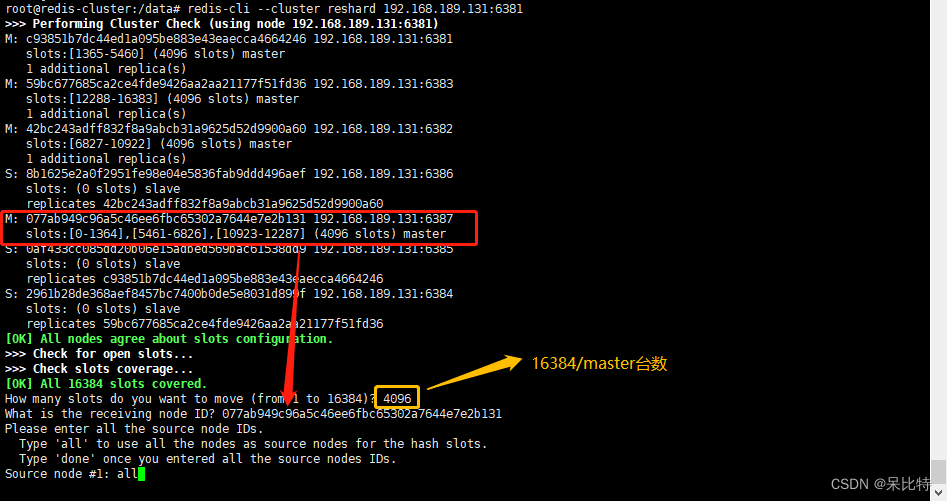
5. 第二次检查集群情况
redis-cli --cluster check 192.168.189.131:6381
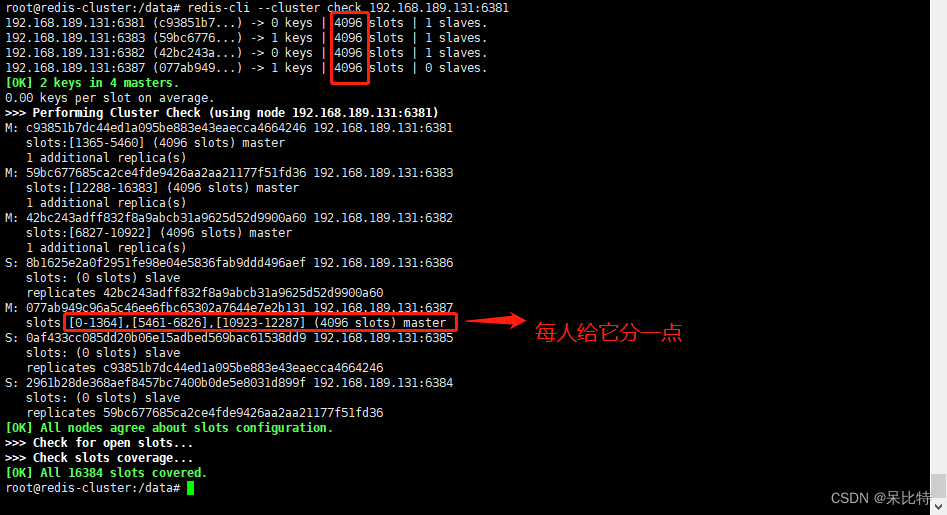
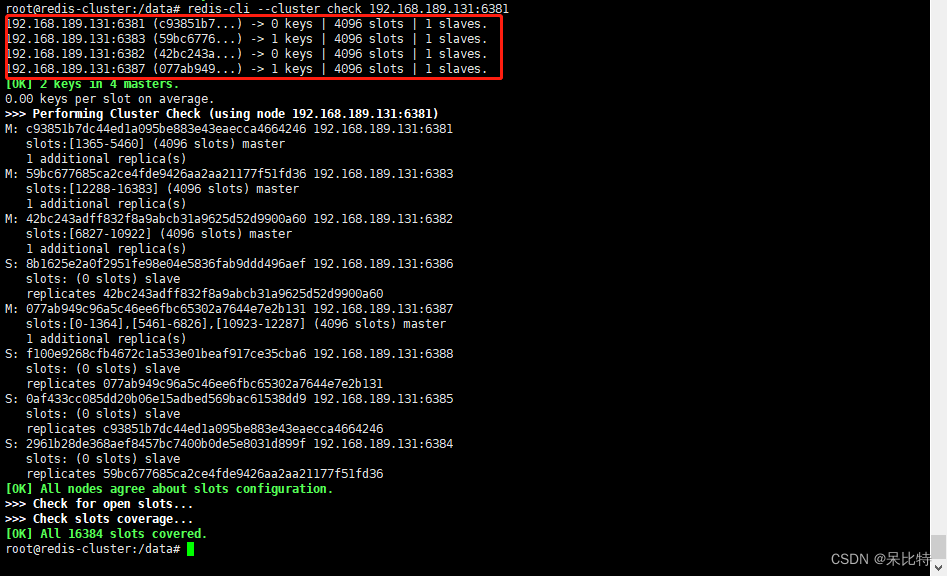
6. 为6387主节点添加从节点6388
#命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
redis-cli --cluster add-node 192.168.189.131:6388 192.168.189.131:6387 --cluster-slave --cluster-master-id 077ab949c96a5c46ee6fbc65302a7644e7e2b131
五、主从缩容:将6387和6388下线
1. 从集群中删除6388节点
#redis-cli --cluster del-node ip:从机端口 从机6388节点ID
redis-cli --cluster del-node 192.168.189.131:6388 f100e9268cfb4672c1a533e01beaf917ce35cba6

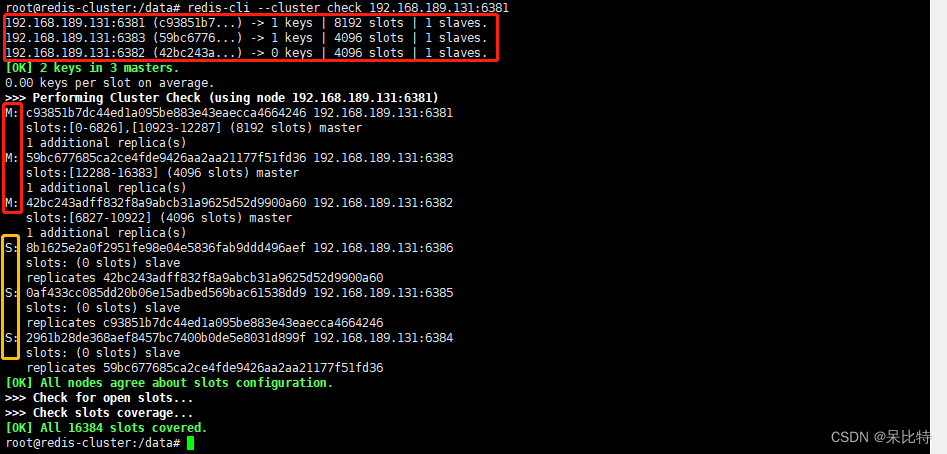
2. 情况1387节点槽位,重新分配,清理出的槽位都给6381
redis-cli --cluster reshard 192.168.189.131:6381

#检查集群情况
redis-cli --cluster check 192.168.189.131:6381
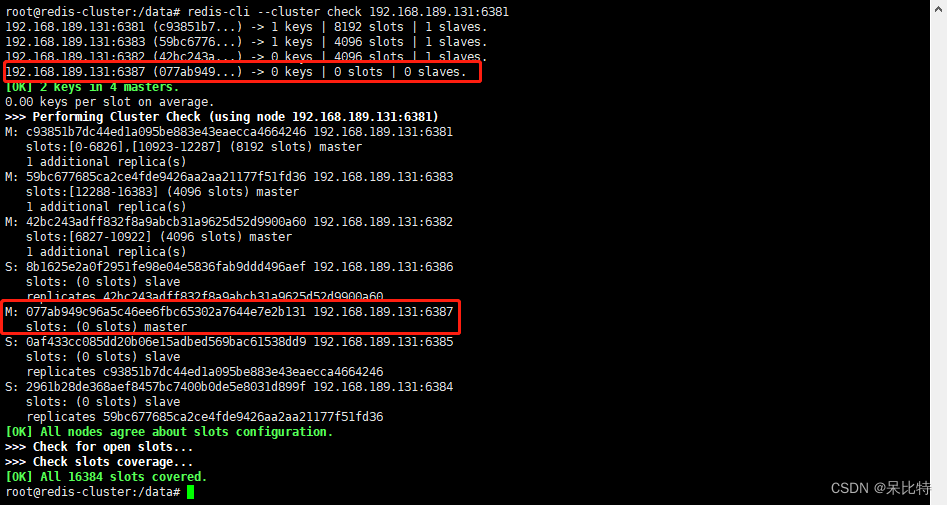
3. 删除6387节点
#命令:redis-cli --cluster del-node ip:端口 6387节点ID
redis-cli --cluster del-node 192.168.189.131:6387 077ab949c96a5c46ee6fbc65302a7644e7e2b131
OVER(∩_∩)O~
边栏推荐
- [Pytorch study notes] 10. How to quickly create your own Dataset dataset object (inherit the Dataset class and override the corresponding method)
- SQL (2) - join window function view
- 如何组织一场安全、可靠、高效的网络实战攻防演习?
- 【Pytorch学习笔记】10.如何快速创建一个自己的Dataset数据集对象(继承Dataset类并重写对应方法)
- 【Pytorch学习笔记】8.训练类别不均衡数据时,如何使用WeightedRandomSampler(权重采样器)
- [Database and SQL study notes] 9. (T-SQL language) Define variables, advanced queries, process control (conditions, loops, etc.)
- 2022年中总结关键词:裁员、年终奖、晋升、涨薪、疫情
- BFC详解(Block Formmating Context)
- [Pytorch study notes] 11. Take a subset of the Dataset and shuffle the order of the Dataset (using Subset, random_split)
- ACL 的一点心得
猜你喜欢
![[Pytorch study notes] 10. How to quickly create your own Dataset dataset object (inherit the Dataset class and override the corresponding method)](/img/71/f82e76085f9d8e6610f6f817e2148f.png)
[Pytorch study notes] 10. How to quickly create your own Dataset dataset object (inherit the Dataset class and override the corresponding method)
物联网:LoRa无线通信技术

IJCAI 2022|边界引导的伪装目标检测模型BGNet
【论文精读】ROC和PR曲线的关系(The relationship between Precision-Recall and ROC curves)
【数据库和SQL学习笔记】4.SELECT查询2:排序(ORDER BY)、聚合函数、分组查询(GROUP BY)
Tensorflow2 与 Pytorch 在张量Tensor基础操作方面的对比整理汇总
ECCV2022 | RU&谷歌提出用CLIP进行zero-shot目标检测!

数控直流电源

PoE视频监控解决方案
![[Pytorch study notes] 9. How to evaluate the classification results of the classifier - using confusion matrix, F1-score, ROC curve, PR curve, etc. (taking Softmax binary classification as an example)](/img/ac/884d8aba8b9d363e3b9ae6de33d5a4.png)
[Pytorch study notes] 9. How to evaluate the classification results of the classifier - using confusion matrix, F1-score, ROC curve, PR curve, etc. (taking Softmax binary classification as an example)
随机推荐
CVPR best paper winner Huang Gao's team from Tsinghua University presented the first dynamic network review
网工必用神器:网络排查工具MTR
Comparison and summary of Tensorflow2 and Pytorch in terms of basic operations of tensor Tensor
【ts】typescript高阶:分布式条件类型
[Practice 1] Diabetes Genetic Risk Detection Challenge [IFLYTEK Open Platform]
[Database and SQL study notes] 8. Views in SQL
ES6 新特性:Class 的继承
5G中切片网络的核心技术FlexE
解决:Unknown column ‘id‘ in ‘where clause‘ 问题
flink项目开发-flink的scala shell命令行交互模式开发
CVPR 2022 |节省70%的显存,训练速度提高2倍
【ts】typescript高阶:typeof使用
Tensorflow2 与 Pytorch 在张量Tensor基础操作方面的对比整理汇总
【ts】typescript高阶:模版字面量类型
沁恒MCU从EVT中提取文件建立MounRiver独立工程
大型Web网站高并发架构方案
MySQL
Kubernetes常备技能
如何编写一个优雅的Shell脚本(一)
【shell编程】第二章:条件测试语句