当前位置:网站首页>[Pytorch study notes] 9. How to evaluate the classification results of the classifier - using confusion matrix, F1-score, ROC curve, PR curve, etc. (taking Softmax binary classification as an example)
[Pytorch study notes] 9. How to evaluate the classification results of the classifier - using confusion matrix, F1-score, ROC curve, PR curve, etc. (taking Softmax binary classification as an example)
2022-08-05 05:38:00 【takedachia】
文章目录
After we have trained a classification model,会在测试(验证)Set to test the performance of the model,It involves some evaluation indicators of the model.如:准确率(Accuracy)、混淆矩阵(confusion matrix)、F1-score、ROC曲线、PR曲线等.
我以SoftmaxTake the regression binary classification model as an example,Show me how to demonstrate evaluation metrics for model performance,and a little bit of interpretation.
需要使用到pandas、scikit-learn、matplotlib库.
What the output of the classifier looks like(Softmax为例)
Generally, we use the feature data of the test set to pass to the trained modelnet:pred_y = net(valid_features_X).detach()
pred_yPresident like this: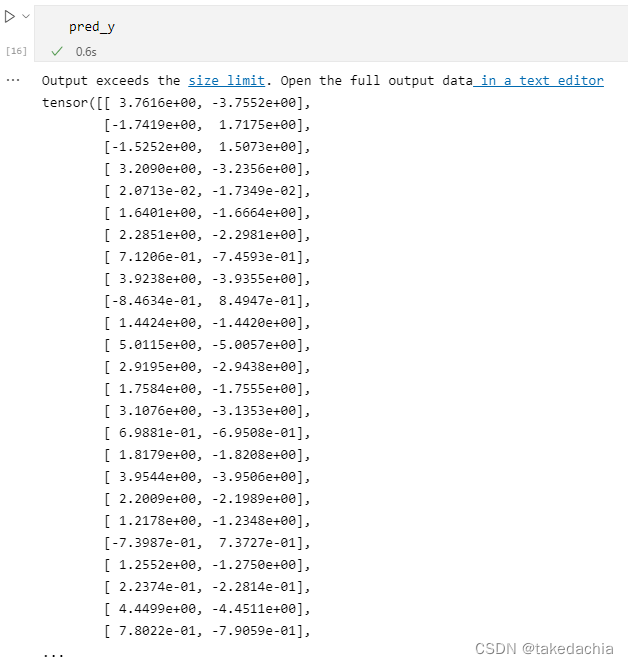
This is binary data,The output two-dimensional vectors correspond to the output values of the linear layer, respectively,represents the output of the two categories,Note this output value o 1 、 o 2 o_1、o_2 o1、o2did not ask for itsoftmax.
因为softmaxThe monotonicity of the function does not change,This time on the output o o o Comparing the size can determine which category should be divided into.
softmaxIf you forget what happened, you can review the picture below: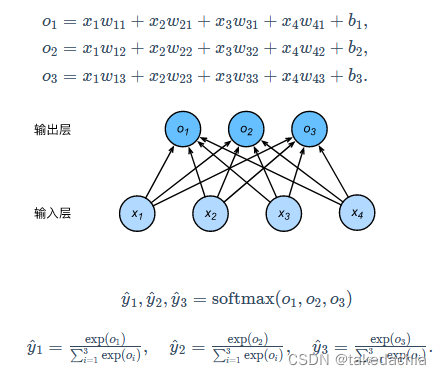
上图中,输出的 y y y便是对 o o o求softmaxThe predicted probability obtained later.
But if we only make classification predictions,比较 o 1 、 o 2 、 o 3 o_1、o_2、o_3 o1、o2、o3The size of the three values will do,Don't ask for it specificallysoftmax,因为softmaxDoes not change monotonicity.
1 混淆矩阵
The confusion matrix contains comprehensive information about the model's predictions for a dataset,包含了 真阳TP、假阳FP、假阴FN、真阴TN 4个值,4The values can be combined into various common evaluation metrics.
Confusion matrix and common metrics 例图: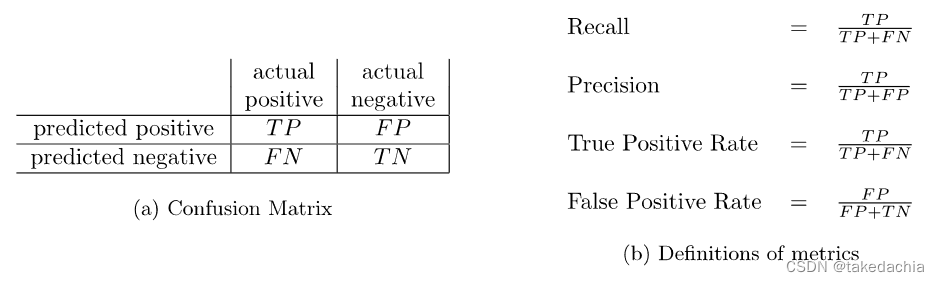
准备数据
To draw confusion matrix,The required data is 正确的结果 和 预测的结果.
预测的结果:
我们先对pred_y求argmax即可获得y的类别(设0为负类,1为正类)pred_y = pred_y.argmax(dim=1)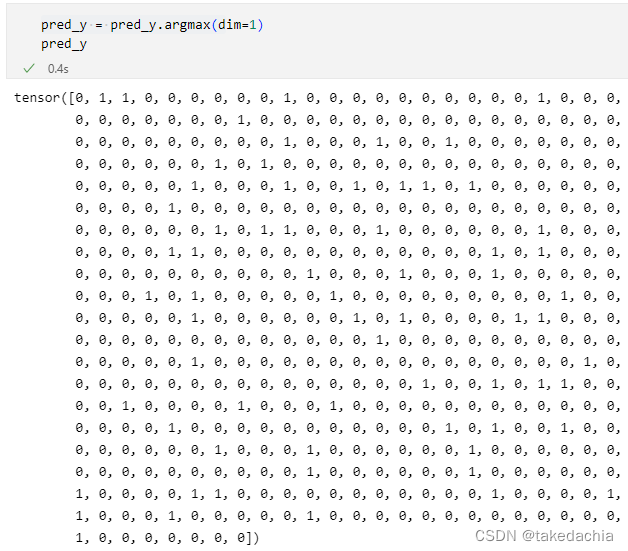 正确的结果:
正确的结果:valid_features_y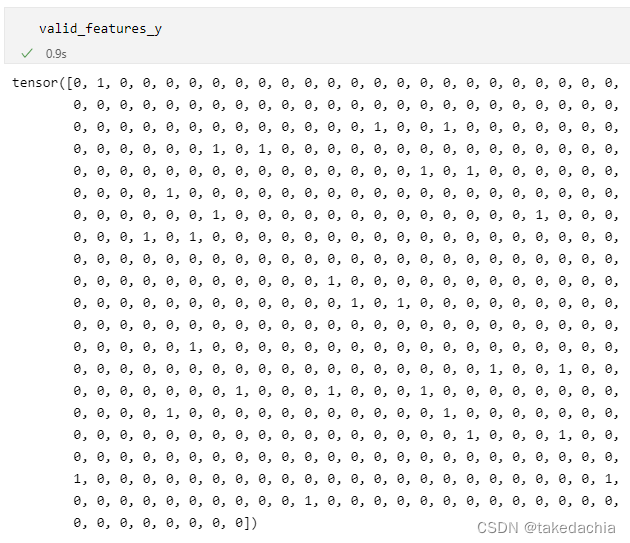
绘制
使用pandas的crosstabmethod to draw,直接把两个tensor传进去: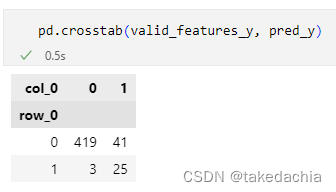
我们可以将pandas的DataFrame's column is passed in,This makes the classification clearer: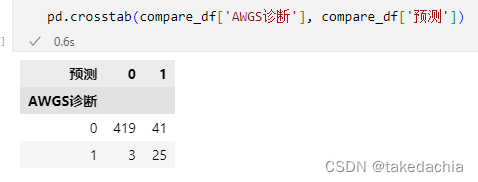
2 F1-score
F1-scores是precision(查准率)和recall(查全率、敏感性)的调和平均数,Subclasses can be reflected(少数类)的预测性能,It is often used to evaluate model prediction performance for class-imbalanced samples.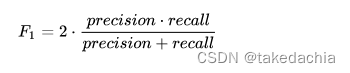
代码:
from sklearn.metrics import f1_score
# 计算 F1 score
report = f1_score(valid_features_y, pred_y)
print(report)
>>> 0.5319148936170213
3 Statistical comprehensive classification indicators(precision、recall等)
We can also count the comprehensive indicators of the classifier.
统计的时候,classification_reportThe function also needs to specify the label0、1Represents negative and positive.
from sklearn.metrics import classification_report
# Statistics of each indicator of the model
report = classification_report(valid_features_y, pred_y, labels=[0, 1], target_names=['阴性', '阳性'])
print(report)
>>>
precision recall f1-score support
阴性 0.99 0.91 0.95 460
阳性 0.38 0.89 0.53 28
accuracy 0.91 488
macro avg 0.69 0.90 0.74 488
weighted avg 0.96 0.91 0.93 488
解读一下:
因为precision(查准率)和recall(查全率)for a given category,So strictly speaking, there will be one negative and one positiveprecision、recall和对应的f1-score.But since this is a class imbalanced data,Negative proportions are high,Therefore, negative data are not of much research significance.
We generally study the classification performance of small classes,So look at the positive lineprecision、recall、f1-score就行了.
maro avg和weighted avgis the corresponding average of the data of the above two categories.
macro avgis the arithmetic mean,weighted avgis the weighted average(The two values are each multiplied by the proportion of the number of their own categories,再相加).
4 ROC曲线
ROCThe curves represent the combined classification performance of the model,Including positive and negative classes.
We also often use the area under the curve(AUC-ROC)来衡量ROCquality of the curve.
准备数据
但是绘制ROCThe curve needs to pass in the predicted probability of the output class.
获得0、1The predicted probabilities of the two classes need to be calculated for the outputsoftmax,What you get is the respective probabilities of the two classes.
We only need the probability of the positive class.代码就是pred_y_softmax = torch.softmax(pred_y_output, dim=1).numpy()[:,1]
绘制
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
# gives the probability of the positive class
pred_y_output = net(valid_features_X).detach()
pred_y_softmax = torch.softmax(pred_y_output, dim=1).numpy()[:,1]
# 绘制ROC曲线,计算AUC
fpr, tpr, thresholds_roc = roc_curve(valid_features_y, pred_y_softmax, pos_label=1)
plt.plot(fpr,tpr,marker = '.')
plt.show()
AUC = auc(fpr, tpr)
print(AUC)
>>>
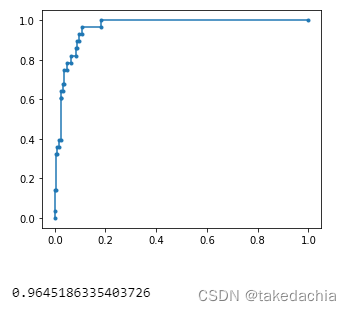
5 PR曲线
PR曲线和 F1-score 一样,is an evaluation metric for the classification performance of the minority class of class-imbalanced data.
和ROC曲线一样,The predicted probability needs to be passed in.
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds_pr = precision_recall_curve(valid_features_y, pred_y_softmax)
plt.plot(precision, recall, marker = '.')
plt.show()
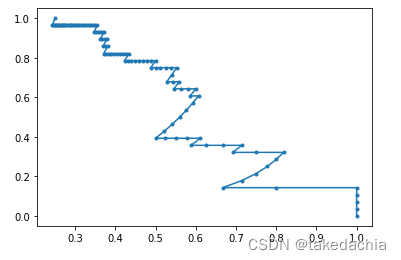
本节代码
可参考我的Github.
边栏推荐
猜你喜欢


随机推荐
Day1:用原生JS把你的设备变成一台架子鼓!
day12函数进阶作业
【论文精读】R-CNN 之预测框回归(Bounding box regression)问题详述
Redux
基于Flink CDC实现实时数据采集(四)-Sink接口实现
门徒Disciples体系:致力于成为“DAO世界”中的集大成者。
Lecture 3 Gradient Tutorial Gradient Descent and Stochastic Gradient Descent
redis cache clearing strategy
拿出接口数组对象中的所有name值,取出同一个值
【数据库和SQL学习笔记】3.数据操纵语言(DML)、SELECT查询初阶用法
MaskDistill-不需要标注数据的语义分割
In Opencv, imag=cv2.cvtColor(imag,cv2.COLOR_BGR2GRAY) error: error:!_src.empty() in function 'cv::cvtColor'
[Go through 7] Notes from the first section of the fully connected neural network video
Flink EventTime和Watermarks案例分析
SparkML-初探-文本分类
ES6 Set、WeakSet
[Let's pass 14] A day in the study room
【数据库和SQL学习笔记】8.SQL中的视图(view)
flink部署操作-flink on yarn集群安装部署
学习总结week2_5