当前位置:网站首页>flink部署操作-flink standalone集群安装部署
flink部署操作-flink standalone集群安装部署
2022-08-05 05:14:00 【bigdata1024】
flink集群安装部署
standalone集群模式
- 必须依赖
- 必须的软件
- JAVA_HOME配置
- flink安装
- 配置flink
- 启动flink
- 添加Jobmanager/taskmanager 实例到集群
- 个人真实环境实践安装步骤
必须依赖
必须的软件
flink运行在所有类unix环境中,例如:linux、mac、或者cygwin,并且集群由一个master节点和一个或者多个worker节点。在你开始安装系统之前,确保你有在每个节点上安装以下软件。
- java 1.8.x或者更高
- ssh
如果你的集群没有这些软件,你需要安装或者升级他们。注意:一般linux服务器上都有ssh,但是java是需要自己安装的。
在集群的所有节点上需要配置SSH免密码登录。
JAVA_HOME配置
flink需要在集群的所有节点(master节点和worker节点)配置JAVA_HOME,指向安装在机器上的java。
你可以在这个文件中进行配置:conf/flink-conf.yaml 通过env.java.home这个key。
flink安装
去下载页面随时下载安装包。确保选择flink安装包匹配到你的hadoop版本。如果你不打算使用hadoop的话,可以选择任意版本。
下载最新版本之后,把安装包上传到你的master节点,然后解压:
tar xzf flink-*.tgz
cd flink-*配置flink
解压之后,需要修改conf/flink-conf.yaml
设置jobmanager.rpc.address的值为master节点的ip或者主机名。你也可以定义每个节点上允许jvm申请的最大内存,使用jobmanager.heap.mb和taskmanager.heap.mb
这两个参数的值的单位都是MB,如果有一些节点想要分配更多的内存,可以通过覆盖这个参数的默认值 FLINK_TM_HEAP
最后,你需要提供一个节点列表作为worker节点。因为,类似于HDFS配置,修改文件conf/slaves 然后在里面输入每一个worker节点的ip/hostname 。每一个worker节点将运行一个taskmanager程序。
下面的例子说明了三个节点的配置:(ip地址从10.0.0.1到10.0.0.3 对应的主机名 master worker1 worker2)并显示配置文件的内容(需要访问所有机器的相同路径)

vi /path/to/flink/conf/flink-conf.yaml
jobmanager.rpc.address: 10.0.0.1
vi /path/to/flink/conf/slaves
10.0.0.2
10.0.0.3flink目录必须在每一个worker节点的相同路劲。你可以使用一个共享的NFS目录,或者拷贝整个flink目录到每一个worker节点。
有关配置的详细信息,请参见详细的配置页面进行查看。
下面这几个参数的配置值非常重要。
- Jobmanager可用内存(jobmanager.heap.mb)
- taskmanager可用内存(taskmanager.heap.mb)
- 每个机器可用cpu数量(taskmanager.numberOfTaskSlots)
- 集群中的总cpu数量(parallelism.default)
- 节点临时目录(taskmanager.tmp.dirs)
启动flink
下面的脚本将会在本机启动一个jobmanager节点,然后通过SSH连接到slaves文件中的所有worker节点,在worker节点上面启动taskmanager。现在flink启动并且运行。在本地运行的jobmanager现在将会通过配置的RPC端口接收任务。
确认你在master节点并且进入flink目录:
bin/start-cluster.sh停止flink,需要使用stop-cluster.sh脚本
添加jobmanager或者taskmanager实例到集群
你可以通过bin/jobmanager.sh脚本和bin/taskmanager.sh脚本向一个运行中的集群添加jobmanager和taskmanager。
添加jobmanager
bin/jobmanager.sh ((start|start-foreground) cluster)|stop|stop-all
添加taskmanager
bin/taskmanager.sh start|start-foreground|stop|stop-all
个人真实环境实践安装步骤
以上的内容来源于官网文档翻译
下面的内容来自于本人在真实环境的一个安装步骤:
集群环境规划:三台机器,一主两从
hadoop100 jobManager
hadoop101 taskManager
hadoop102 taskManager
注意:
1:这几台节点之间需要互相配置好SSH免密码登录。(至少要配置hadoop100可以免密码登录hadoop101和hadoop102)
2:这几台节点需要安装jdk1.8及以上,并且在/etc/profile中配置环境变量JAVA_HOME
例如:
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
1:上传flink安装包到hadoop100节点的/usr/local目录下,然后解压
cd /usr/local
tar -zxvf flink-1.4.1-bin-hadoop27-scala_2.11.tgz2:修改hadoop100节点上的flink的配置文件
cd /usr/local/flink-1.4.1/conf
vi flink-conf.yaml
# 修改此参数的值,改为主节点的主机名
jobmanager.rpc.address: hadoop100
vi slaves
hadoop101
hadoop1023:把修改好配置文件的flink目录拷贝到其他两个节点
scp -rq /usr/local/flink-1.4.1 hadoop101:/usr/local
scp -rq /usr/local/flink-1.4.1 hadoop102:/usr/local4:在hadoop100节点启动集群
cd /usr/local/flink-1.4.1
bin/start-cluster.sh执行上面命令以后正常将会看到以下日志输出:
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Starting cluster.
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Starting jobmanager daemon on host hadoop100.
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Starting taskmanager daemon on host hadoop101.
Starting taskmanager daemon on host hadoop102.5:验证集群启动情况
查看进程:
在hadoop100节点上执行jps,可以看到:
3785 JobManager
在hadoop101节点上执行jps,可以看到:
2534 TaskManager
在hadoop101节点上执行jps,可以看到:
2402 TaskManager
能看到对应的jobmanager和taskmanager进程即可。如果启动失败了,请查看对应的日志:
cd /usr/local/flink-1.4.1/log
针对jobmanager节点:
more flink-root-jobmanager-0-hadoop100.log
针对taskmanager节点:
more flink-root-taskmanager-0-hadoop101.log
more flink-root-taskmanager-0-hadoop102.log
查看此日志文件中是否有异常日志信息6:访问集群web界面
http://hadoop100:8081
7:停止集群
在hadoop100节点上执行下面命令
cd /usr/local/flink-1.4.1
bin/stop-cluster.sh执行停止命令之后将会看到下面日志输出:
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Stopping taskmanager daemon (pid: 3321) on host hadoop101.
Stopping taskmanager daemon (pid: 3088) on host hadoop102.
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/contrib/capacity-scheduler/*.jar
Stopping jobmanager daemon (pid: 5341) on host hadoop100.再去对应的节点上执行jps进程发现对应的jobmanager和taskmanager进程都没有了。
获取更多大数据资料,视频以及技术交流请加群:

边栏推荐
- 学习总结week2_3
- 学习总结day5
- Transformation 和 Action 常用算子
- Do you use tomatoes to supervise your peers?Add my study room, come on together
- [Go through 4] 09-10_Classic network analysis
- [Go through 3] Convolution & Image Noise & Edge & Texture
- 【After a while 6】Machine vision video 【After a while 2 was squeezed out】
- DOM and its applications
- 「PHP8入门指南」PHP简明介绍
- Mesos学习
猜你喜欢
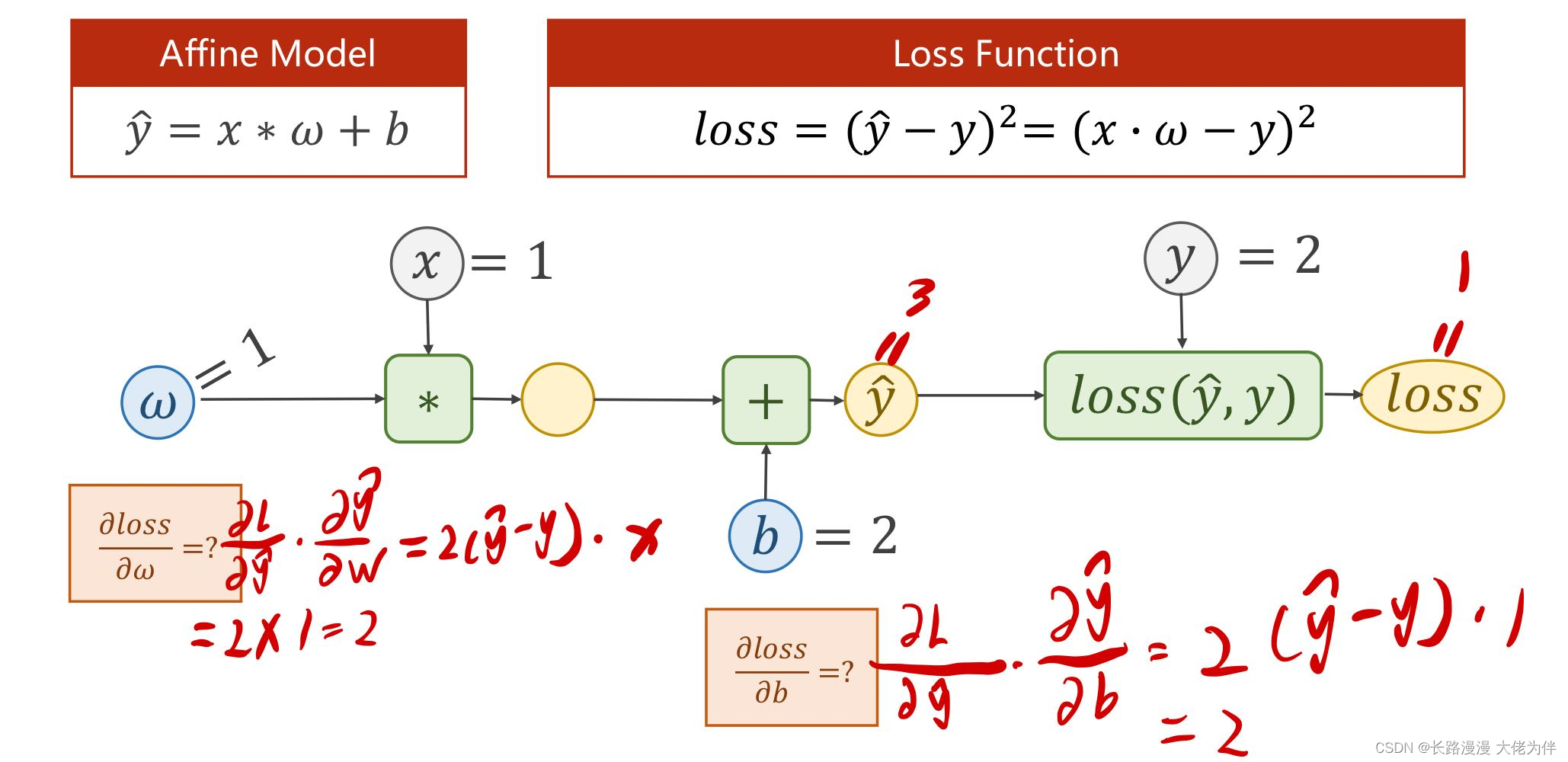
第四讲 back propagation 反向传播
vscode+pytorch使用经验记录(个人记录+不定时更新)
![[Go through 7] Notes from the first section of the fully connected neural network video](/img/e2/1107171b52fe9dcbf454f7edcdff77.png)
[Go through 7] Notes from the first section of the fully connected neural network video

The mall background management system based on Web design and implementation
NodeJs接收上传文件并自定义保存路径
Geek卸载工具
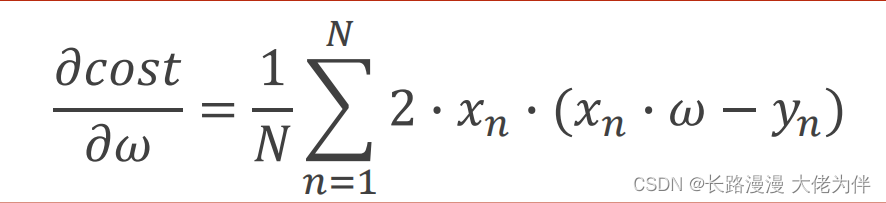
Lecture 3 Gradient Tutorial Gradient Descent and Stochastic Gradient Descent
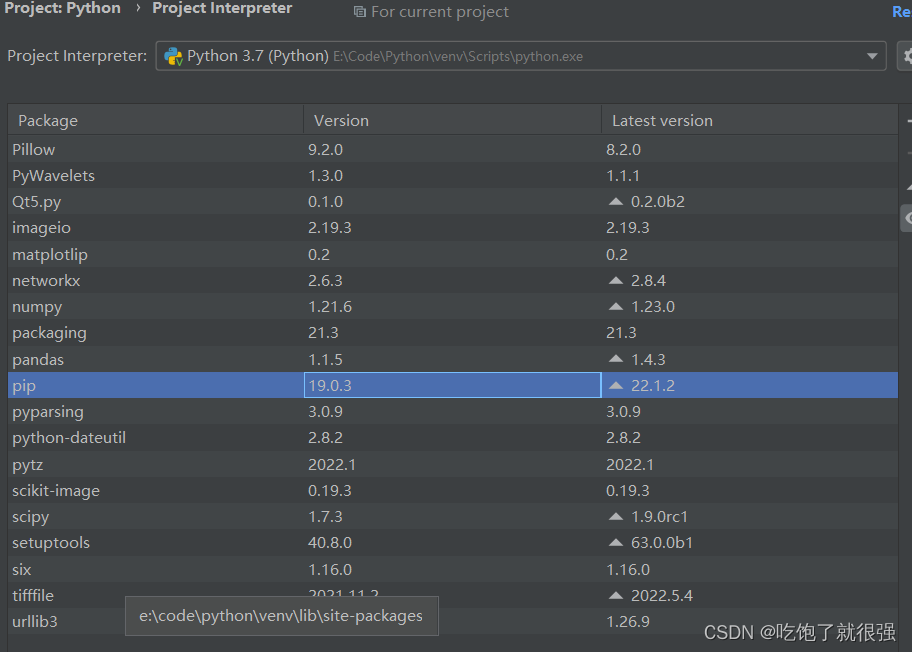
Pycharm中使用pip安装第三方库安装失败:“Non-zero exit code (2)“的解决方法
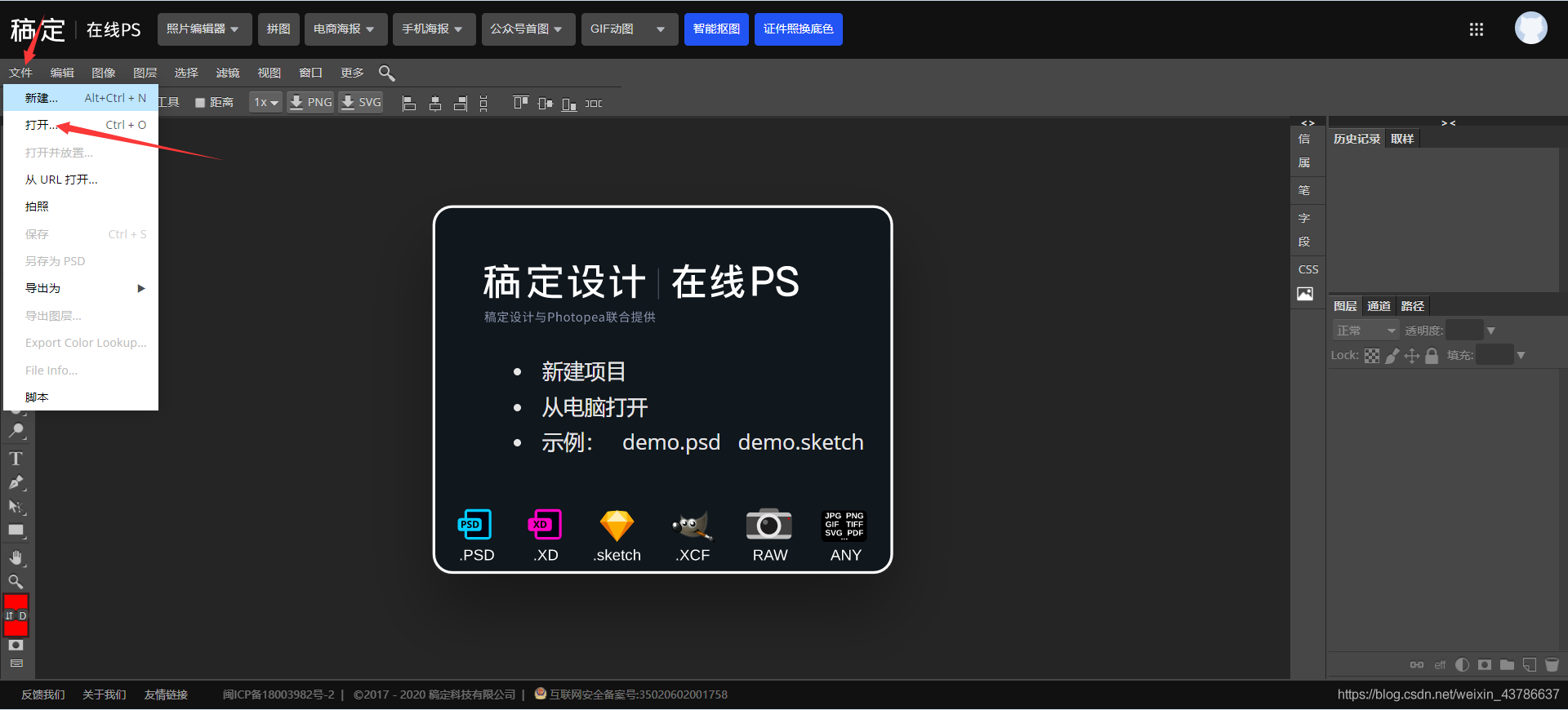
将照片形式的纸质公章转化为电子公章(不需要下载ps)
![[Let's pass 14] A day in the study room](/img/fc/ff4161db8ed13a0c8ef75b066b8eab.png)
[Let's pass 14] A day in the study room
随机推荐
Flink accumulator Counter 累加器 和 计数器
ES6 生成器
NodeJs接收上传文件并自定义保存路径
学习总结week2_4
OFDM Lecture 16 5 -Discrete Convolution, ISI and ICI on DMT/OFDM Systems
Difference between for..in and for..of
day12函数进阶作业
What are the characteristics of the interface of the physical layer?What does each contain?
数据库 单表查询
Lecture 2 Linear Model Linear Model
【Untitled】
SQL(一) —— 增删改查
BFC(Block Formatting Context)
【练一下1】糖尿病遗传风险检测挑战赛 【讯飞开放平台】
range函数作用
el-table鼠标移入表格改变显示背景色
02.01-----The role of parameter reference "&"
redis 持久化
【过一下9】卷积
Dashboard Display | DataEase Look at China: Data Presents China's Capital Market