当前位置:网站首页>Machine Learning (1) - Machine Learning Fundamentals
Machine Learning (1) - Machine Learning Fundamentals
2022-08-05 05:37:00 【share16】
机器学习(一) —— 机器学习基础
大家可以关注知乎或微信公众号的share16,我们也会同步更新此文章.
写在前面的话
This is my first exposure to machine learning,This paper recorded the basic knowledge of machine learning and related code,以供参考.
机器学习is to automatically analyze the model from the data/规律,并利用模型对未知数据进行预测;Algorithms are at the heart of machine learning,数据是计算的基础.
大部分复杂模型的算法设计都是算法工程师(博士/硕士)在做,而我们只需:1︎⃣学会分析问题,使用机器学习相关算法完成对应的需求;2︎⃣掌握算法的基本思想,Learn to choose corresponding algorithm to solve different problems;3︎⃣学会利用框架和库解决问题;
scikit-learn包含众多顶级机器学习算法,There are six main categories of basic functions-分别是分类、回归、聚类、数据降维、模型选择和数据预处理.
注:变量按其数值表现是否连续,Can be divided into continuous variables and discrete variables.
A simple way to distinguish between continuous and discrete variables:
连续变量是一直叠加上去的,增长量可以划分为固定的单位,即1,2,3… 如:一个人的身高,他首先长到1.51,然后才能长到1.52,1.53……
离散变量则是通过计数方式取得的,Is to count the object to be statistical,增长量非固定的,如:一个地区的企业数目可以是今年只有一家,而第二年开了十家;一个企业的职工人数今年只有10人,第二年一次招聘了20人等.

一、数据集
1.1 加载数据集
数据集的采集:公司内部产生的数据、和其他公司合作获取的数据、Purchased data, etc.;
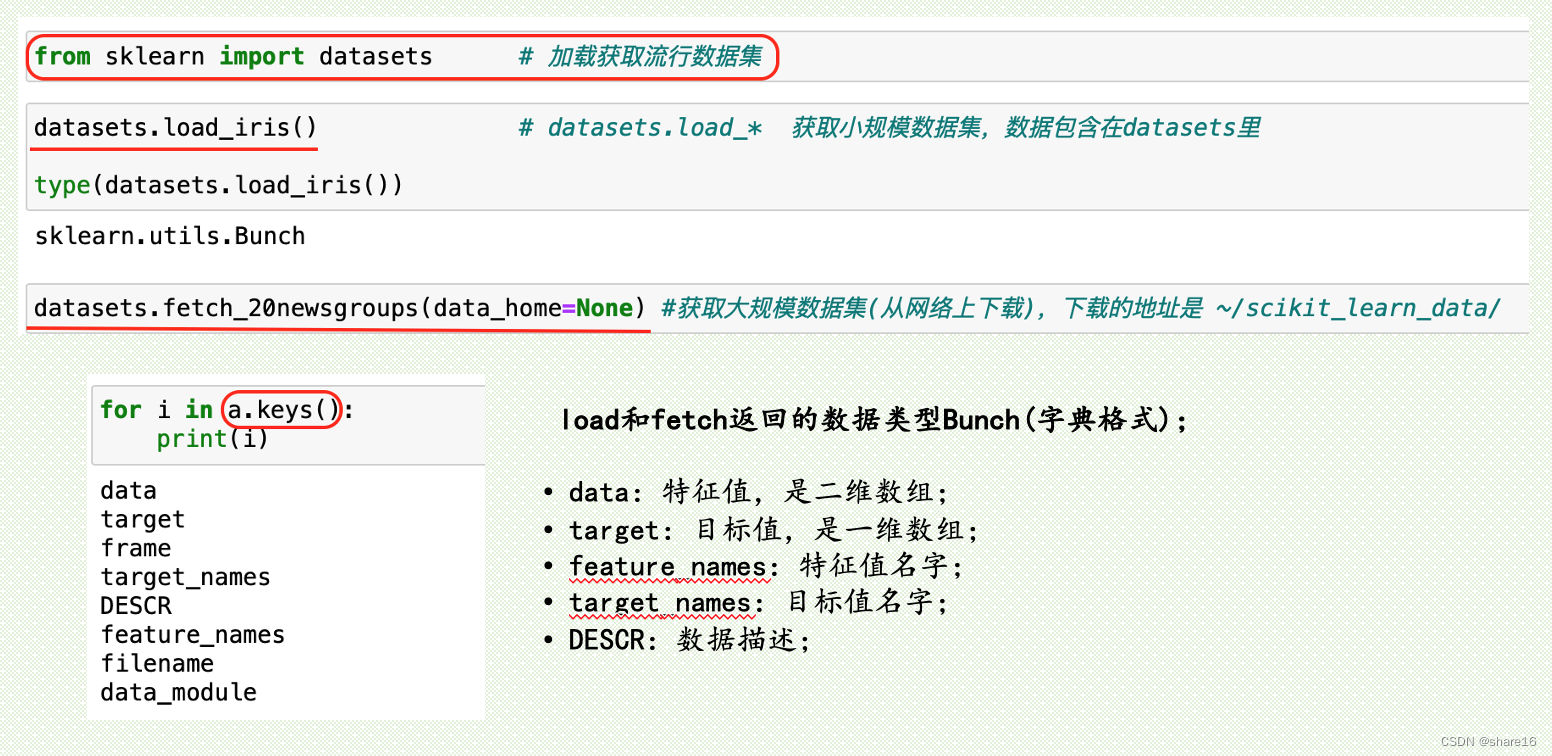
sklearn.datasets.load_iris()
sklearn.datasets.fetch_20newsgroups(data_home=None,···)
1.2 划分数据集

数据的基本处理:数据清洗、合并、级联等;
machine learning datasets,Generally divided into two parts(训练集和测试集),如下:sklearn.model_selection.train_test_split(x, [y], test_size, train_size, random_state, shuffle, stratify)
- 训练集:用于训练,构建模型;测试集:在模型检验时使用,用于评估模型是否有效;
- test_size/train_size:默认None,若是float([0,1]),represents its proportion in the dataset;若是int,represents the absolute number of samples;
- random_state:随机数种子,不同的种子会造成不同的随机采样结果(相同的种子采样结果相同);
二、特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程;It will directly affect the effect of machine learning.特征工程包含的内容:特征预处理、特征降维、特征提取.
2.1 特征预处理(归一化/标准化)
归一化:通过对原始数据进行变换把数据映射到[0,1]之间, y = x − m i n m a x − m i n y = { {x-min}\over{max-min}} y=max−minx−min .
标准化:通过对原始数据进行变换把数据变换到均值为0、标准差为1的范围内, y = x − μ σ y = { {x-\mu}\over{\sigma}} y=σx−μ .
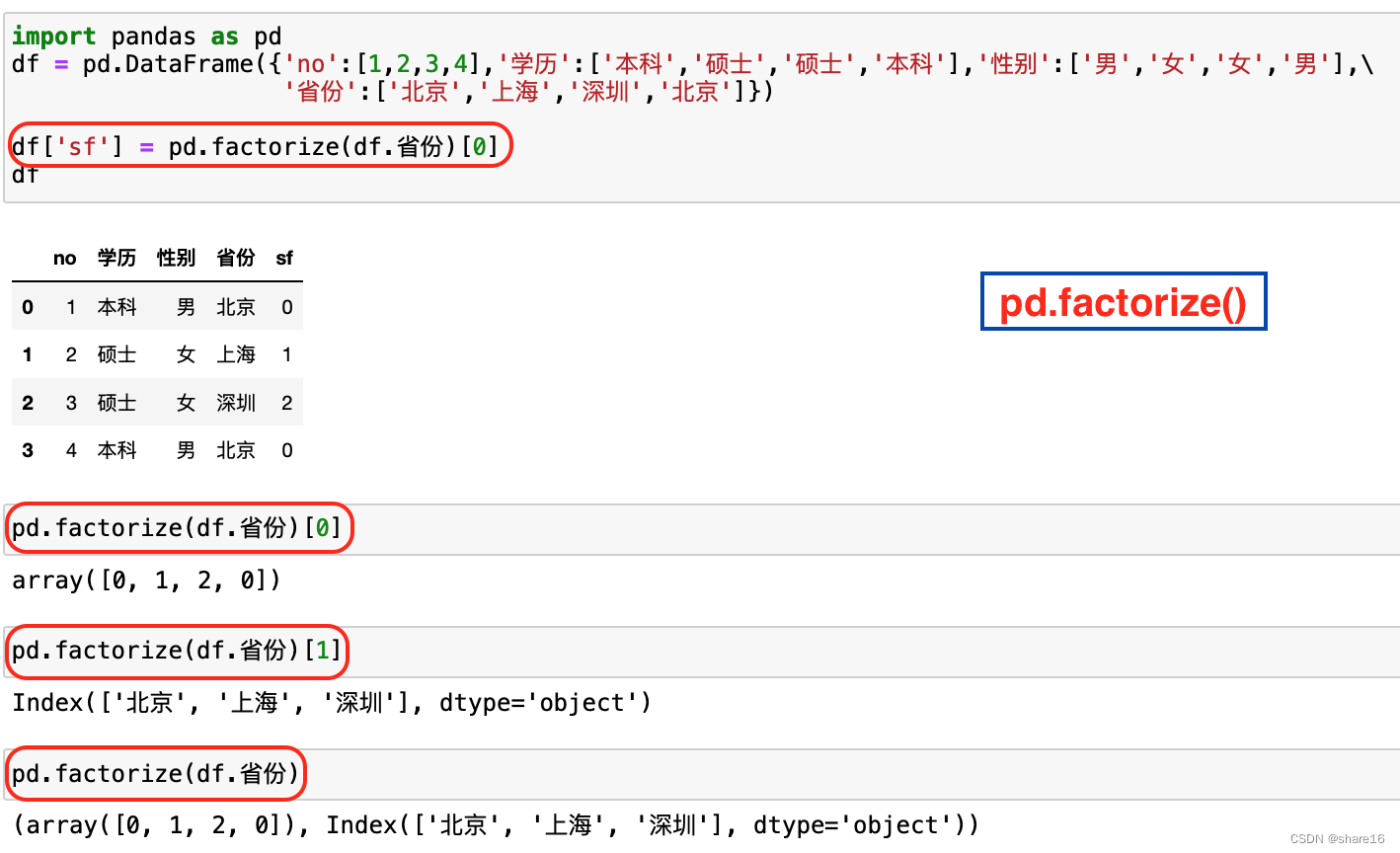
将 标签 编码为 分类变量:pd.factorize、sklearn.LabelEncoder;
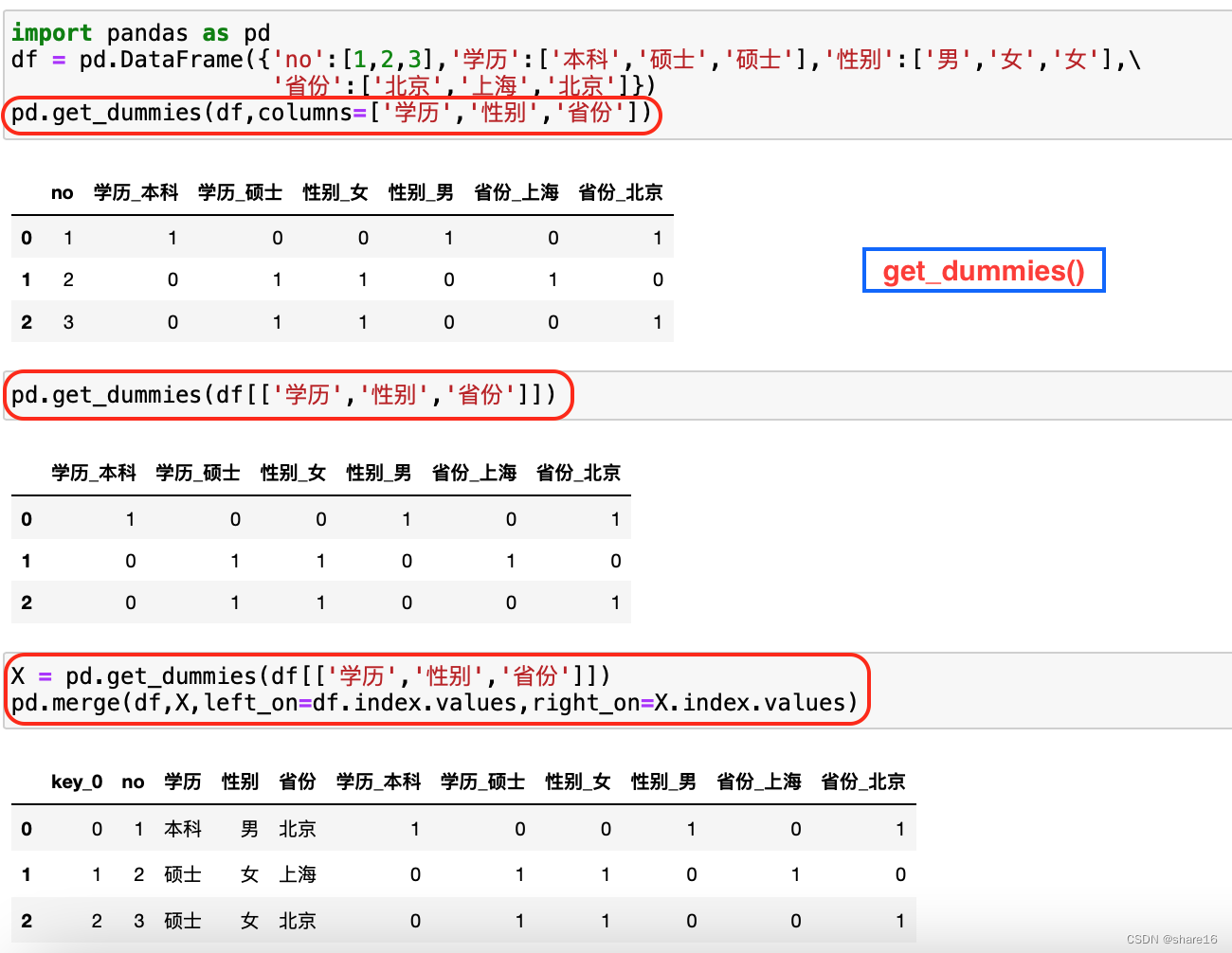
将 分类变量 编码为 Virtual index variables:pd.get_dummies、sklearn.OneHotEncoder;哑变量编码:即pd.get_dummies,There is a data setnThe value of the column is of type string,如学历、性别等;This function can be used to convert,如下.
''' 归一化:Scale data to a given range,feature_range默认范围是(0,1) '''
MinMaxScaler = sklearn.preprocessing.MinMaxScaler(feature_range=(0,1))
MinMaxScaler.fit_transform(array).round(2)
''' 标准化 '''
StandardScaler = sklearn.preprocessing.StandardScaler()
StandardScaler.fit_transform(array).round(2)
''' Labels are encoded as categorical variables '''
x,y = pd.factorize(df.省份)
''' 哑变量编码 '''
pd.get_dummies(df,columns=['学历','性别','省份'])
pd.get_dummies(df[['学历','性别']])
2.2 特征降维(特征选择/主成分分析/Linear discriminator)
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组‘不相关’主变量的过程.
- 降低随机变量的个数;
- 相关特征(correlated feature),如:相对湿度与降雨量之间的相关等等;
降维方法:特征选择、单变量特征选定、递归特征消除、主成分分析、Linear discriminator
特征选择:数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征.
- Filter(过滤式):主要探究特征本身特点、The association between features and feature and target values(方差选择法:低方差特征过滤;皮尔逊相关系数);
- Embedded(嵌入式):算法自动选择特征,That is, the association between the feature and the target value(决策树:信息熵、信息增益;正则化:L1、L2;深度学习:卷积等);
单变量特征选定:The analysis selects the data features that have the greatest impact on the results.如卡方检验,It is the degree of deviation between the actual value of the statistical sample and the predicted value,偏离程度决定了卡方值的大小(卡方值越大,The more inconsistent;卡方值越小,The more compatible;若两者相等,The chi-square value is equal to0,show that the predicted values are in full agreement with).
递归特征消除:Use one base model for multiple rounds of training,每轮训练后消除若干权值系数的特征,再基于新的特征集进行下一轮训练.通过每一个基模型的精度,找到对最终的预测结果影响最大的数据特征.
主成分分析PCA:是一种无监督的降维方法;is an orthogonal transformation,Convert observations represented by linearly dependent variables into a few data represented by linearly independent variables;The new variable may have the largest variance of the variable in the orthogonal transformation,方差表示在新变量上信息的大小,将变量依次成为第一主成分、第二主成分.
Linear discriminatorLDA:是一种有监督的降维方法;LDA与PCAThe similarity is that they are all dimensionality reduction methods,The reference is the variance.LDAThe dimensionality reduction is:在投影之后,The variance within the data of the same class is as small as possible,The variance between the different classes is as large as possible.If all samples areX(特征)If projected on the same line,那么就是labelShould be very close to the same data projection results,反之labelDifferent data projection results should be farther away.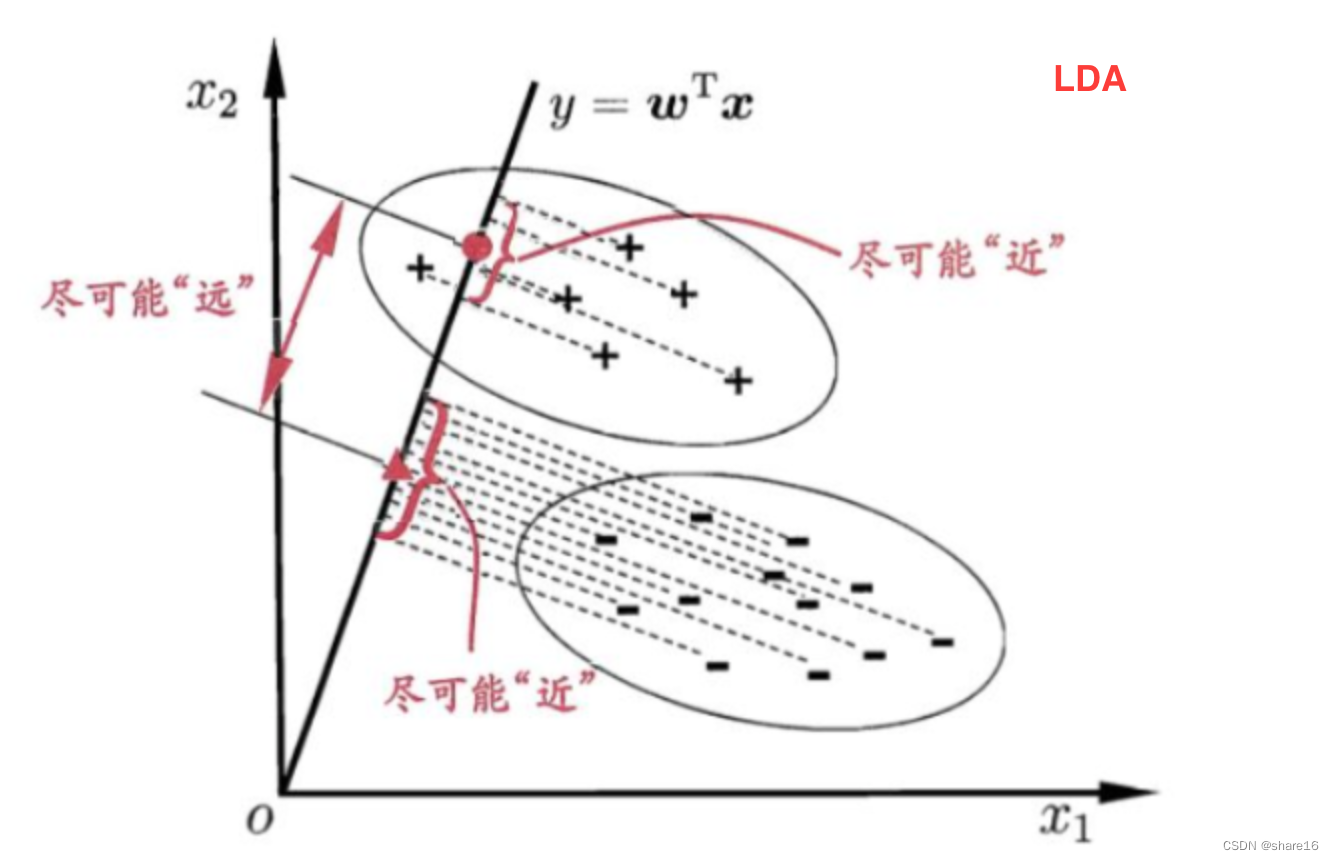
''' 过滤式:删除方差低于threshold的特征 '''
VarianceThreshold = feature_selection.VarianceThreshold(threshold=0.0)
VarianceThreshold.fit_transform(array)
''' 皮尔逊相关系数 '''
from scipy import stats
stats.pearsonr(x,y) # x/yBoth are one-digit arrays
''' 主成分分析PCA n_components是float,indicates how much information to keep; n_components是int,represents how many features to reduce to;'''
PCA = sklearn.decomposition.PCA(n_components=None)
PCA.fit_transform(array)
''' Linear discriminatorLDA '''
from sklearn.discriminant_analysis import\
LinearDiscriminantAnalysis as LDA
lda = LDA(n_components=None)
2.3 特征提取(字典/文本特征提取)
特征提取:is any data(如文本或图像)转换为可用于机器学习的数字特征.字典特征提取:对字典数据进行特征值化;文本特征提取:对文本数据进行特征值化;Tf-idf文本特征提取:To evaluate a word for a set of files or in a document to the importance of the corpus(词频(tf)refers to the frequency with which a given word appears in the document;逆向文档频率(idf)是一个词语普遍重要性的度量,of a particular wordidf,Divide by the total number of documents by the number of documents containing the term,再将得到的商取以10为底的对数得到;The importance of a particular word is equal to thetf*idf);图像特征提取;
''' 字典特征提取:sparse-默认True,That is, whether the transformation producesscipy.sparse矩阵 '''
DictVectorizer = feature_extraction.DictVectorizer(sparse=False)
# 返回sparse矩阵
DictVectorizer.fit_transform(字典组成的列表)
# 返回转换之前数据格式
DictVectorizer.inverse_transform(array或sparse矩阵)
# 返回类别名称
DictVectorizer.get_feature_names()
''' 文本特征提取:Whether the transformation occursscipy.sparse矩阵 '''
CountVectorizer = feature_extraction.text.CountVectorizer(encoding,stop_words,analyzer)
# 返回单词列表
CountVectorizer.get_feature_names()
# 返回sparse矩阵
CountVectorizer.fit_transform(text or a list of texts).toarray()
# 返回转换之前数据格式
CountVectorizer.inverse_transform(array或sparse矩阵)
''' Tf-idf文本特征提取 '''
TfidfVectorizer = feature_extraction.text.TfidfVectorizer()
TfidfVectorizer.fit_transform(text or a list of texts).toarray()
''' jieba分词处理 '''
jieba.lcut(文本)
三、分类算法
3.1 K 近邻算法
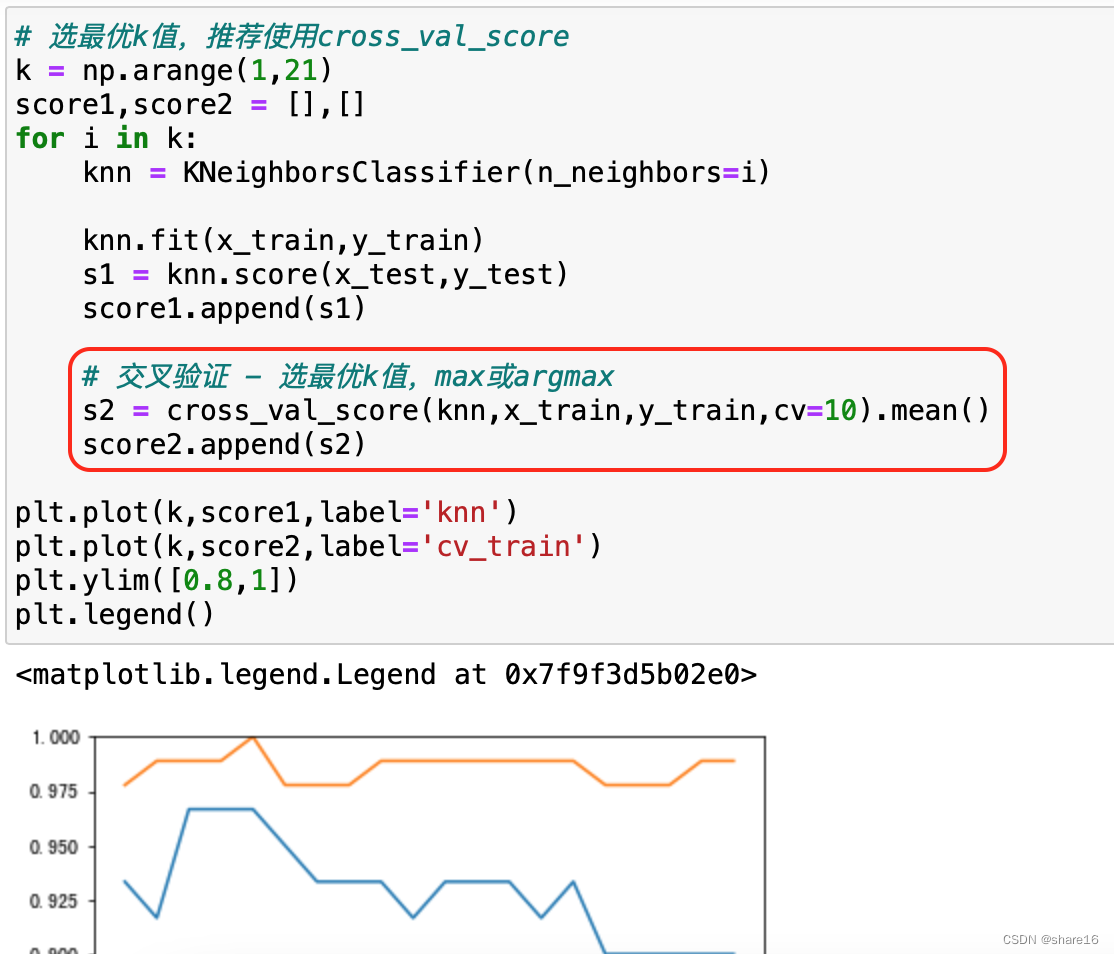
K 近邻算法(K-Nearest Neighbors,KNN)是一种惰性学习算法,可用于回归和分类,Its main idea is to cluster together,人以群分;for a new instance,We find the closest approximation to the labeled training setk个数据,用他们的label进行投票,分类问题则进行表决投票,Regression problems using weighted average or direct average.KNN算法中,The three most important issues:k值的选择、Distance calculation and decision rules.
- k值的选取:Choose according to the cross-check method,详见下图;
- 距离的计算:distance between two samples,方法有欧式距离、曼哈顿距离等;
- 曼哈顿距离: ∣ a 1 − b 1 ∣ + ∣ a 2 − b 2 ∣ + ⋅ ⋅ ⋅ + ∣ a n − b n ∣ |a_1-b_1|+|a_2-b_2|+···+|a_n-b_n| ∣a1−b1∣+∣a2−b2∣+⋅⋅⋅+∣an−bn∣;
- 欧氏距离: ( a 1 − b 1 ) 2 + ( a 2 − b 2 ) 2 + ⋅ ⋅ ⋅ + ( a n − b n ) 2 \sqrt{(a_1-b_1)^2+(a_2-b_2)^2+···+(a_n-b_n)^2} (a1−b1)2+(a2−b2)2+⋅⋅⋅+(an−bn)2;
- 决策规则:mode for classification,mean for regression.Sometimes the distance factor is also taken into account,Add weight to samples that are closer;
''' 分类 '''
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(data,target) # 利用模型对数据进行拟合
knn.score(data,target) # The score of the printed model
knn.predict(X_new) # 进行预测,X_new新数据点
''' 回归 '''
from sklearn.neighbors import KNeighborsRegressor
KNeighborsRegressor(n_neighbors=1)
- n_neighbors:KNN中的k值,That is, the number of selected neighbors,默认5; weights:权重,默认uniform(统一的权重,i.e. all points in each neighborhood have equal weight);
- 欧式距离:即 metric=minkowski & p=2 ;
- algorithm:用于计算最近邻居的算法,默认auto,还可取值ball_tree、kd_tree、brute;
3.2 朴素贝叶斯算法
Naive bayes algorithm is a kind of supervised learning algorithm based on bayesian theory,之所以说‘朴素’,Because this algorithm is based on the naive assumption that the sample features are independent of each other.
联合概率:包含多个条件,且所有条件同时成立的概率,记作P(A,B);
P ( A , B ) = P ( A ) P ( B ) P(A,B) = P(A)P(B) P(A,B)=P(A)P(B)
条件概率:指事件A在另外一个事件B已经发生条件下的发生概率,记作P(A|B);
P ( A ∣ B ) = P ( A B ) P ( B ) P(A|B) = { {P(AB)}\over{P(B)}} P(A∣B)=P(B)P(AB)
P ( A 1 , A 2 ∣ B ) = P ( A 1 ∣ B ) P ( A 2 ∣ B ) P(A_1,A_2|B) = P(A_1|B)P(A_2|B) P(A1,A2∣B)=P(A1∣B)P(A2∣B) (注意:A1,A2相互独立)
贝叶斯公式: P ( B ∣ A ) = P ( A , B ) P ( A ) = P ( A ∣ B ) P ( B ) P ( A ) P(B|A) = { {P(A,B)}\over{P(A)}} = { {P(A|B)P(B)}\over{P(A)}} P(B∣A)=P(A)P(A,B)=P(A)P(A∣B)P(B)
''' 二项分布:伯努利朴素贝叶斯(alpha:平滑参数,默认1.0,0表示不平滑) '''
from sklearn.naive_bayes import BernoulliNB
clf = BernoulliNB(alpha=1.0)
clf.fit(X,Y) # 拟合
clf.score(X,Y) # 得分
clf.predict(X_new) # 预测
clf.predict_proba(X_new) # The model predicts the probability of a class
''' 正态分布:高斯朴素贝叶斯 '''
from sklearn.naive_bayes import GaussianNB
''' 多项式朴素贝叶斯 '''
from sklearn.naive_bayes import MultinomialNB
3.3 决策树与随机森林
决策树It is an algorithm that is widely used in classification and regression.,It works by asking a series of questionsif-else的推导,final implementation decision;But it is prone to overfitting problem.
随机森林Also known as random decision forest,is a collective learning method,是一种经典的Bagging模型,既可用于分类,也可用于回归.while the ensemble learning algorithm,In fact, it is a combination of multiple machine learning algorithms,make a bigger model.Currently widely used ensemble algorithms include random forests and gradient ascent decision trees.
此外,Decision trees and random forests also have related regression models,如DecisionTreeRegressor、RandomForestRegressor等.
''' 决策树 '''
from sklearn.tree import DecisionTreeClassifier,export_graphviz
clf = DecisionTreeClassifier(max_depth=2,···) # 决策树分类器
clf.fit(X,Y) # 拟合
export_graphviz(clf,out_file,···) # 以DOT格式导出决策树
# criterion:gini(基尼指数)、entropy(熵)
''' 随机森林 '''
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators,max_depth,bootstrap,···)
forest.fit(X,Y) # 拟合
# 随机森林分类器
# n_estimators:number of trees in the forest,默认100
# bootstrap:是否在构建树时使用放回抽样,默认True
3.4 逻辑回归
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,Its dependent variable is binary;multi-category,可以使用softmax方法进行处理.
由于算法的简单和高效,The most commonly used in practice is the binary classification,If it can be used to predict whether something will happen or not,If you predict whether the Shanghai Composite Index will rise tomorrow、Will it rain in a certain area tomorrow?、Whether a transaction is suspected of violation、Whether the user will buy an item, etc..
* { ① 线 性 回 归 模 型 , 即 y = k x + b ② 回 归 结 果 输 入 到 s i g m o i d 函 数 , 即 h = g ( k x + b ) \implies \begin{cases}① 线性回归模型,即y = kx + b\\ \\② The input to the regression resultssigmoid函数,即h = g(kx + b)\end{cases} *⎩⎪⎨⎪⎧①线性回归模型,即y=kx+b②回归结果输入到sigmoid函数,即h=g(kx+b)
sigmoid函数,也称为logistic函数,即 g ( z ) = 1 1 + e − z g(z)={1\over{1+e^{-z}}} g(z)=1+e−z1;It can convert the results in a linear regression into a[0, 1]之间的概率值,默认0.5为阈值.
''' 逻辑回归 '''
from sklearn.linear_model import LogisticRegression
logr = LogisticRegression()
# Built-in functions in accordance with the above
四、回归算法
Linear models are a class of predictive models widely used in machine learning,In fact, the linear model does not refer to a specific model,a class of models.在机器学习领域,Commonly used linear models include linear regression、岭回归、套索回归、Logistic Regression and LinearitySVC等.
4.1 线性回归、Ridge regression and lasso regression
在回归分析中,formula for linear model: y = k 1 x 1 + k 2 x 2 + k 3 x 3 + ⋅ ⋅ ⋅ + k n x n + b = k x + b y = k_1x_1+k_2x_2+k_3x_3+···+k_nx_n+b = kx + b y=k1x1+k2x2+k3x3+⋅⋅⋅+knxn+b=kx+b .
线性回归,Also known as Ordinary Least Squares(OLS),is the simplest and most classic linear model in regression analysis.线性回归的原理:find when the training datasetywhen the squared difference between the predicted value and its true value is the smallest,所对应的k值和b值.Linear regression has no user adjustable parameters,这是它的优势,But it also means that we have no control over the complexity of the model.
岭回归It is also a linear model commonly used in regression analysis.,It is actually a modified least squares method.从实用的角度来说,Ridge regression is actually a linear model that avoids overfitting.
在岭回归中,The model retains all feature variables,But it will reduce the coefficient value of the characteristic variable,Minimize the influence of feature variables on prediction results,In ridge regression is by changing alpha参数 to control the degree to which the coefficient of the characteristic variable is reduced.And this by retaining all characteristic variables,Just reduce the coefficient value of the feature variable to avoid overfitting,我们称之为L2正则化.
套索回归,除了岭回归之外,There is also a model that regularizes linear regression,lasso regression(lasso).和岭回归一样,Lasso regression will also limit the coefficients to very close0的范围内,But it does the restriction in a slightly different way,我们称之为L1正则化.
与L2正则化不同的是,L1 Regularization can cause when using lasso regression,Some features have coefficients exactly equal to0.也就是说,Some features are completely ignored by the model,This can also be seen as the model for the characteristics of a method of automatic selection.turn some of the coefficients into0Helps make the model easier to understand,and can highlight the most important features of the model.
SGDRegressorImplemented stochastic gradient descent learning,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型.
均方误差MSE: M S E = ∑ i = 1 m ( y ˉ − y ) 2 m MSE = { {\sum_{i=1}^m(\bar{y}-y)^2}\over{m}} MSE=m∑i=1m(yˉ−y)2, 其中 y ˉ 是 预 测 值 , y 是 真 实 值 ; \bar{y}是预测值,y是真实值; yˉ是预测值,y是真实值;
''' 线性回归 '''
from sklearn.linear_model import LinearRegression
lr = LinearRegression(fit_intercept,···)
lr.fit(X,Y)
lr.coef_ # 返回系数-k
lr.intercept_ # 返回截距-b
lr.score(X,Y) # 模型性能/得分
lr.predict(X_new) # 预测
''' 岭回归 : alpha默认值是1,可调节 '''
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1.5)
ridge.fit(X,Y)
ridge.coef_
ridge.intercept_
ridge.score(X,Y)
ridge.predict(X_new) # 预测
''' 套索回归 : alpha默认值是1,可调节;max_iter最大迭代次数 '''
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=1.0)
lasso.fit(X,Y)
lasso.coef_
lasso.intercept_
lasso.score(X,Y)
lasso.predict(X_new) # 预测
''' SGDRegressor '''
from sklearn.linear_model import SGDRegressor
sgd = SGDRegressor(loss,fit_intercept,learning_rate,eta0)
sgd.fit(x_train,y_train)
sgd.coef_
sgd.intercept_
''' 均方误差MSE '''
from sklearn.metrics import mean_squared_error
mean_squared_error(y_true,y_pred)
- loss:默认squared_error,还可取值huber、epsilon_insensitive、squared_epsilon_insensitive;
- fit_intercept:是否计算此模型的截距,即b值;
- learning_rate:学习率,默认invscaling(eta = eta0/pow(t, power_t)),还可取值constant( eta=eta0 )、optimal( eta=1.0/(alpha*(t + t0)) )等;
- eta0:默认0.01; power_t:默认0.25; 对于一个常数值的学习率来说,可使用learning_rate=’constant’,并使用eta0来指定学习率;
4.2 欠拟合与过拟合
机器学习中一个重要的话题便是模型的泛化能力,泛化能力强的模型才是好模型.对于训练好的模型,若在训练集表现差,在测试集表现同样会很差,这可能是欠拟合导致.欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据.
Underfitting solutions are:
- 出现的原因:学习到数据的特征过少;
- 增加数据的特征数量,Feature combinations can be added、high-order features, etc.;
- 添加多项式特征,For example, the linear model can be more generalized by adding quadratic or cubic terms;
- 减少正则化参数;or use a nonlinear model,如SVM 、决策树、深度学习等模型;
过拟合:Able to get a better fit on the training set than other hypotheses,But it doesn't fit the data well on the test set,At this point, it is considered to be an overfitting phenomenon(模型过于复杂).
The solution to overfitting is:
- 出现的原因:原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点;
- 正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则(岭回归)与L2正则(岭回归)等;
五、聚类算法
上文提到过,Supervised learning is mainly used for classification and regression,A very important use of unsupervised learning is to cluster data.Clustering and classification have certain similarities,Classification is an algorithm that learns from already labeled data and classifies new data,while clustering is done in the absence of existing labels at all,有算法‘猜测’which data should’堆‘在一起的,and let the algorithm give different’堆‘label the data in.
聚类算法,有K-means聚类、凝聚聚类以及DBSCAN这几个算法.
5.1 K-means算法
K-meansThe algorithm is a very classic clustering algorithm,其工作原理是:Suppose the samples in our dataset are different because of the characteristics,spread out on the ground like small piles of sand,K-meansAlgorithms will plant flags on small sand piles;And the flags inserted for the first time cannot perfectly represent the distribution of the sand piles.,所以K-means还要继续,Allow each flag to be placed in the best position on each sand pile,That is, on the mean of the data points,这也是K-means算法名字的由来.The above actions will be repeated,until no better location can be found.
from sklearn.cluster import KMeans
km = KMeans(n_clusters=8)
km.fit(X) # 以鸢尾花为例,X是data,Y是target
km.cluster_centers_ # 各类的中心点
list(X[km.labels_==2].mean(axis=0)) # Find the center point of a class,此处2is a value for the category
list(X[Y==2].mean(axis=0)) # Find the center point of a class,此处2is a value for the category
# 使用Y还是km.labels_,具体情况具体分析吧
# n_clusters:聚类中心数量,默认8,即将数据分为n_clusters类;
# init:初始化方法,默认k-means++,还可取值random;
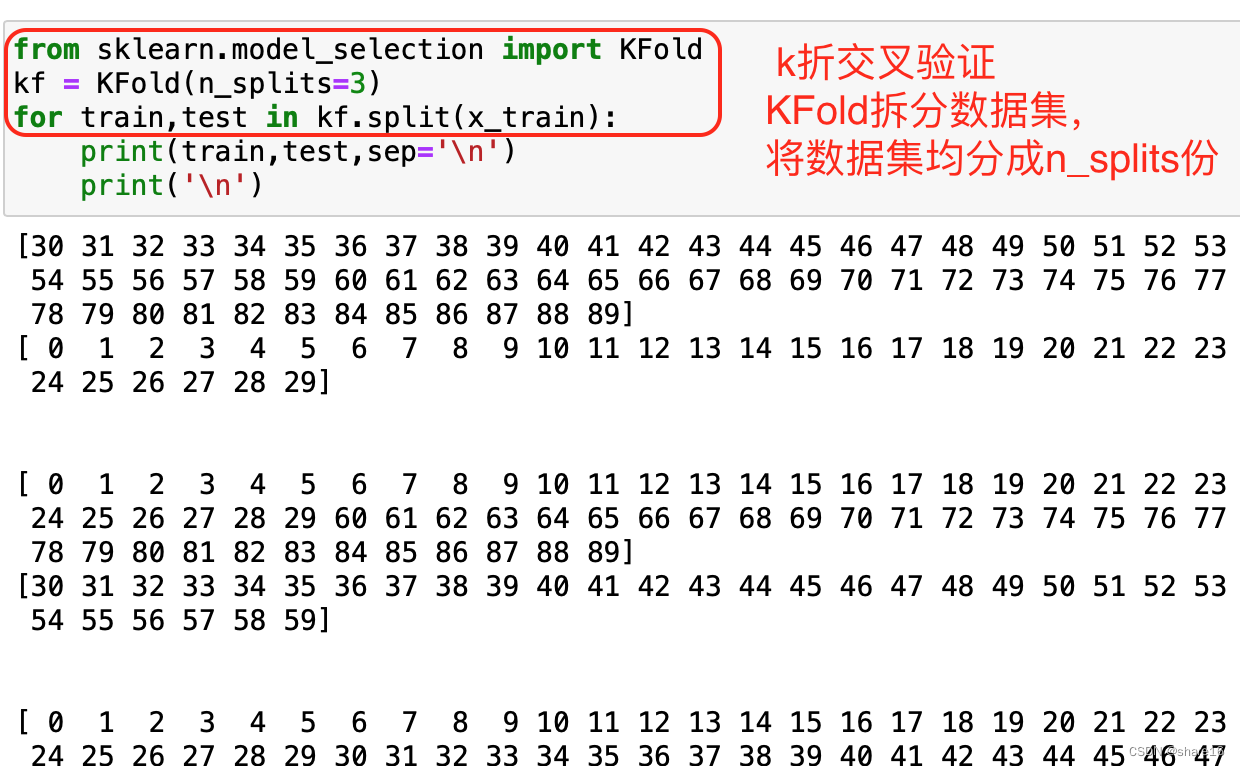
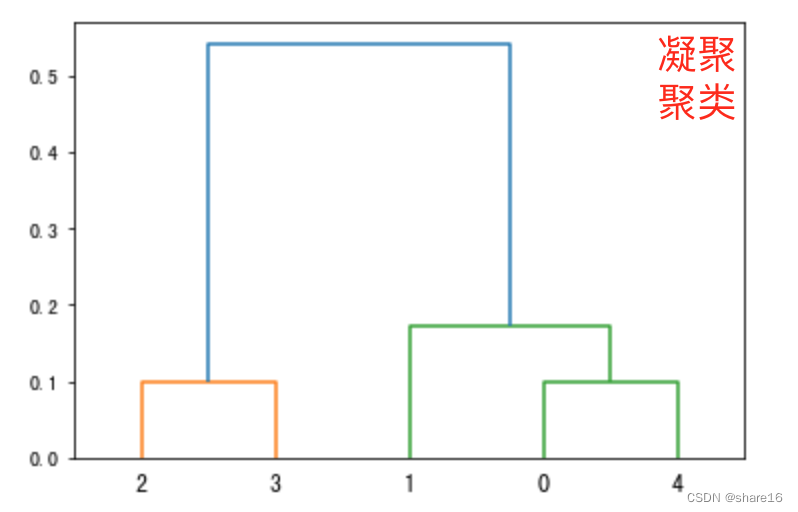
5.2 Agglomerative clustering withDBSCAN
凝聚聚类:例子如下,Observe the lotus leaves after the rain,会发现这个现象:在重力的作用下,The small water droplets on the lotus leaf will gather towards the center of the lotus leaf,and condensed into a large drop of water,This can be used to visualize the agglomerative clustering algorithm.
实际上,Agglomerative clustering algorithm is a collection of algorithms in a package,What this package of algorithms has in common is that,They first treat each data point as a cluster,That is, the water droplets on the lotus leaf,Then merge similar clusters,formed a larger droplet.然后重复这个过程,until the stop criterion is reached.So what are the criteria for stopping??在scikit-learn中,The criteria for stopping are the rest‘big water drop’的数量.
DBSCAN:The full name of the algorithm is‘Density-based spatial clustering of noisy applications’(Density-based spatial clustering of applications with noise),其工作原理是:DBSCANis by detecting the density in the feature space,Where the density is high it will be considered a class,而密度相对小的地方它会认为是一个分界线.It is for such work mechanism,使得DBSCANAlgorithms don't need to be likeK-meansOr condensed clustering algorithm that specifies the number of clustering at the outset.
''' 凝聚聚类:Use wired way visualization '''
from sklearn.datasets import load_iris
from scipy.cluster.hierarchy import dendrogram, ward
import matplotlib.pyplot as plt
x = load_iris().data[:5,:2]
linkage = ward(x) # x是数组
dendrogram(linkage)
ax = plt.gca()
''' DBSCAN '''
from sklearn.cluster import DBSCAN
db = DBSCAN()
db.fit_predict(x)
六、分类的评估方法
6.1 查准率与查全率
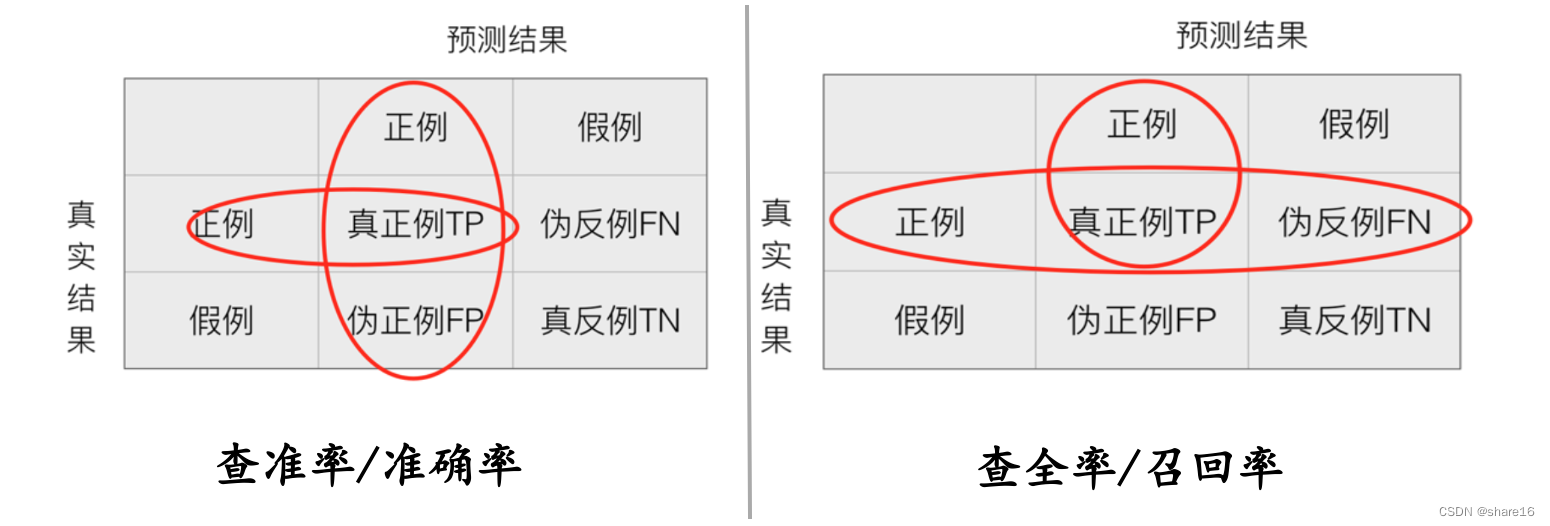
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类).
查准率/精确率:In the samples with positive prediction results,The proportion of true results that are positive; p r e c i s i o n = T P T P + F P precision={TP\over{TP+FP}} precision=TP+FPTP
查全率/召回率:Among the samples with positive results,The proportion of predicted positive results; r e c a l l = T P T P + F N recall={TP\over{TP+FN}} recall=TP+FNTP
P-R曲线:Take the recall as the abscissa,查准率为纵坐标,就可得到P-R曲线;
''' 查准率与查全率 '''
from sklearn.metrics import precision_recall_curve
precision,recall,thresholds = precision_recall_curve(y,y_pre,pos_label=1)
print(precision,recall,thresholds)
''' 绘制P-R曲线 '''
from sklearn.metrics import PrecisionRecallDisplay
PrecisionRecallDisplay.from_predictions(y,y_pre,pos_label=1)
''' Text reports of key taxonomic indicators '''
from sklearn.metrics import classification_report
report=classification_report(y,y_pre,labels=None,target_names=None)
print(report)
# y:真实值; y_pre:预测值/概率估计等;pos_label:positive class label
# labels:指定类别对应的数字; target_names:目标类别名称;
report结果是:每个类别精确率与召回率,f1-score反映了模型的稳健性;
6.2 ROC曲线与AUC指标
ROC曲线:以FPR为横坐标,TPR为纵坐标,就可得到ROC曲线;AUC指标:AUC为ROC曲线的面积,It is an important indicator to measure the generalization ability of the model..若AUC大,The optimal classification model;Otherwise, the classification model is poor.
R O C 曲 线 * { 真 正 例 率 : T P R = T P T P + F N 假 正 例 率 : F P R = F P T N + F P ROC曲线 \implies \begin{cases} 真正例率:TPR = {TP\over{TP+FN}} \\ \\ 假正例率:FPR = {FP\over{TN+FP}}\end{cases} ROC曲线*⎩⎪⎨⎪⎧真正例率:TPR=TP+FNTP假正例率:FPR=TN+FPFP
''' 返回fpr,tpr,thresholds '''
from sklearn.metrics import roc_curve
fpr,tpr,thresholds = roc_curve(y,knn.predict_proba(x)[:,1],pos_label=2)
print(fpr,tpr,thresholds)
''' 返回auc值 '''
from sklearn.metrics import roc_auc_score
auc = roc_auc_score(y,y_pre,multi_class='ovr')
print(auc)
# multi_class:取值为ovo、ovr;
# knn.predict_proba(x):返回测试数据x的概率估计
''' 绘制ROC曲线 '''
from sklearn.metrics import RocCurveDisplay
RocCurveDisplay.from_predictions(y,y_pre,pos_label=2)
七、总结图
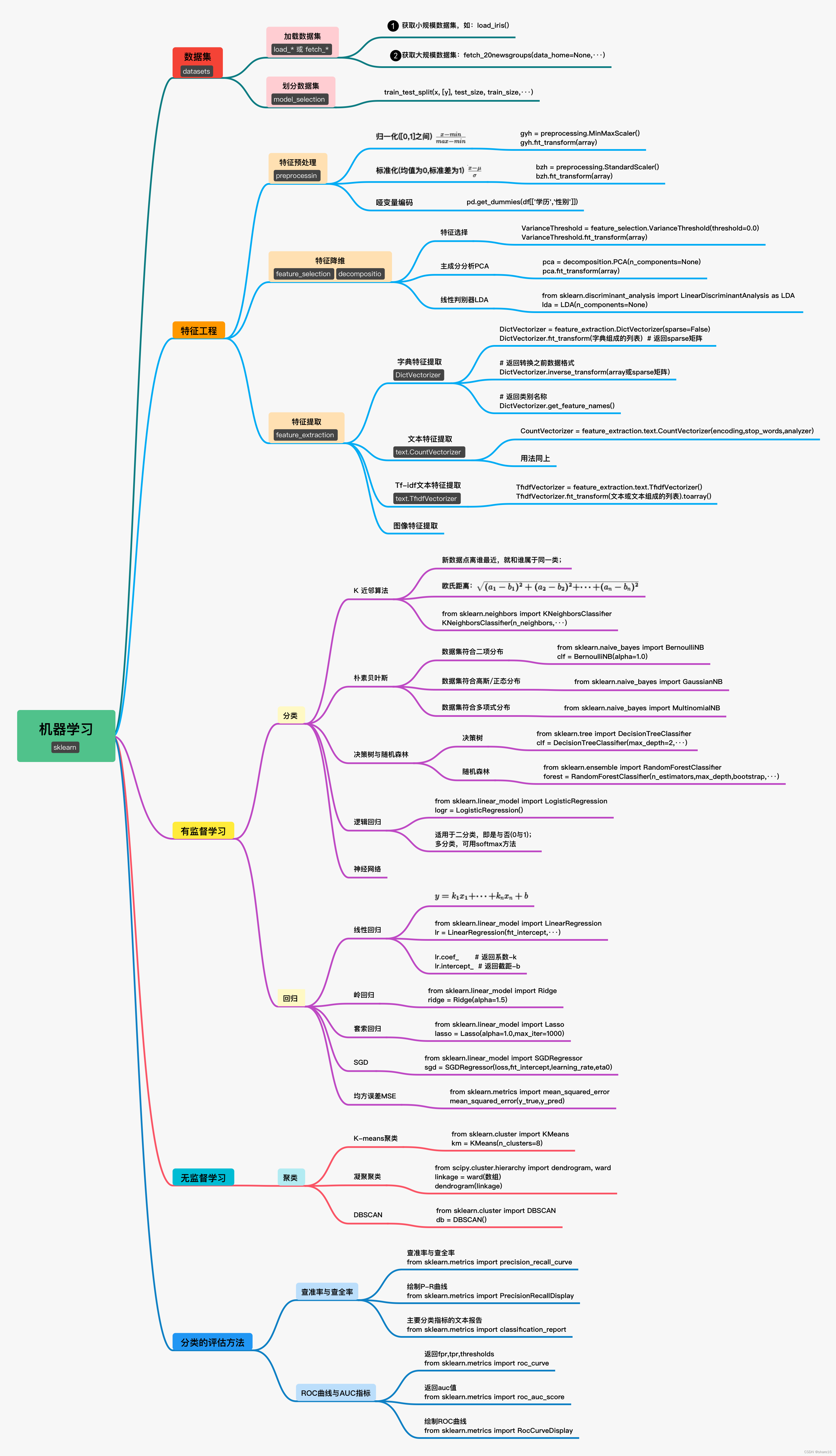
谢谢大家
边栏推荐
- Flink和Spark中文乱码问题
- Flutter 3.0升级内容,该如何与小程序结合
- Flink HA安装配置实战
- Distributed and Clustered
- 【论文精读】Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation(R-CNN)
- Tensorflow踩坑笔记,记录各种报错和解决方法
- 门徒Disciples体系:致力于成为“DAO世界”中的集大成者。
- vscode要安装的插件
- [Redis] Resid的删除策略
- [Go through 3] Convolution & Image Noise & Edge & Texture
猜你喜欢



随机推荐
【Reading】Long-term update
学习总结week2_5
vscode+pytorch use experience record (personal record + irregular update)
js实现数组去重
BroadCast Receiver(广播)详解
学习总结week3_4类与对象
SharedPreferences和SQlite数据库
Thread handler句柄 IntentServvice handlerThread
Redux
Distributed and Clustered
如何编写一个优雅的Shell脚本(三)
spingboot 容器项目完成CICD部署
数据库期末考试,选择、判断、填空题汇总
[Let's pass 14] A day in the study room
转正菜鸟前进中的经验(废话)之谈 持续更新中... ...
SQL(一) —— 增删改查
[Over 17] Pytorch rewrites keras
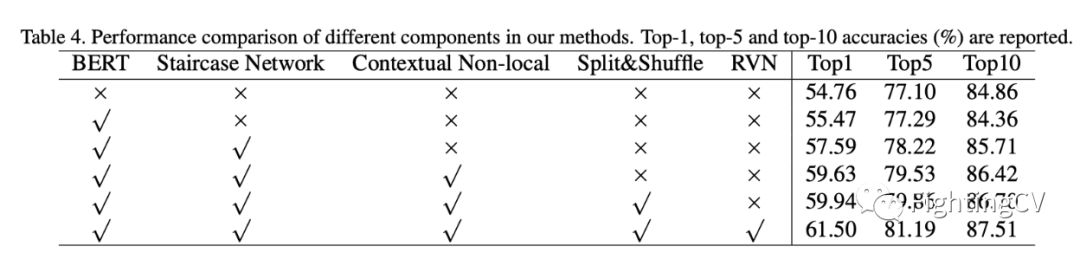
记我的第一篇CCF-A会议论文|在经历六次被拒之后,我的论文终于中啦,耶!
机器学习(二) —— 机器学习基础
day12函数进阶作业