当前位置:网站首页>神经网络也能像人类利用外围视觉一样观察图像
神经网络也能像人类利用外围视觉一样观察图像
2022-08-05 05:15:00 【FightingCV】

本篇分享论文『Peripheral Vision Transformer』,POSTECH&MSRA&中科大提出PerViT,让神经网络也能关注图片中的重点信息!
详细信息如下:

论文地址:https://arxiv.org/abs/2206.06801
项目地址:http://cvlab.postech.ac.kr/research/PerViT/ (尚未开源)
01
摘要
人类视觉拥有一种特殊类型的视觉处理系统,称为外围视觉(peripheral vision)。根据到凝视中心的距离将整个视野划分为多个轮廓区域,外围视觉为人类提供了感知不同区域的各种视觉特征的能力。
在这项工作中,作者采用了一种受生物学启发的方法,并探索在深度神经网络中对外围视觉进行建模以进行视觉识别。作者提出将外围位置编码合并到多头自注意力层中,以让网络学习在给定训练数据的情况下将视野划分为不同的外围区域。
作者在大规模 ImageNet 数据集上评估了本文提出的网络PerViT,并系统地研究了机器感知模型的内部工作原理,表明该网络学习感知视觉数据的方式类似于人类视觉的方式。在各种模型大小的图像分类任务中的最新性能证明了所提出方法的有效性。
02
Motivation
在过去的十年中,卷积一直是视觉识别神经网络中的主要特征转换,因为它在图像空间配置建模方面具有优势。尽管在学习视觉模式方面很有效,但卷积核的局部和静止特性限制了灵活处理中表示能力的最大程度,例如,具有全局感受野的动态变换。
自注意力最初是为自然语言处理 (NLP) 设计的,它阐明了这个方向;配备自适应输入处理和捕获远程交互的能力,它已成为计算机视觉的替代特征变换,被广泛用作核心构建块。
然而,独立的自注意模型,例如 ViT,需要更多的训练数据才能与其卷积对应物的竞争性能,因为它们错过了卷积的某些理想属性,例如,局部性。卷积和自注意力的这些固有优缺点鼓励了最近对两者结合的研究,以便享受两全其美,但哪一种最适合有效的视觉处理,但在文献中尚有争议。

与机器视觉中占主导地位的视觉特征转换不同,人类视觉拥有一种特殊类型的视觉处理系统,称为外围视觉(peripheral vision)。它根据到凝视中心的距离将整个视觉划分为多个轮廓区域,其中每个区域标识不同的视觉方面。如上图所示,人类在注视中心附近(即中心和准中心区域)进行了高分辨率处理,以识别高度详细的视觉元素,例如几何形状和低级细节。
对于距离注视更远的区域,即中部和远边缘区域,分辨率会降低以识别抽象的视觉特征,例如运动和高级上下文。这种系统化的策略使人类能够有效地感知一小部分(1%)视野内的重要细节,同时最大限度地减少对其余部分(99%)背景杂波的不必要处理,从而促进人脑的高效视觉处理。
根据最近对视觉Transformer内部工作原理的研究,它们的行为实际上与外围视觉的功能密切相关。学习早期层的注意力图以局部捕获中心区域的细粒度几何细节,而后面层的注意力图则执行全局注意力以从整个视野中识别粗粒度语义和上下文,覆盖外围区域。
这些发现表明,模仿生物设计可能有助于对有效的机器视觉进行建模,并且还支持最近实现卷积和自注意的混合方法,而不仅仅是独立的视觉处理。两种不同感知策略的优势:细粒度/局部和粗粒度/全局。
在这项工作中,作者采用了一种受生物学启发的方法,并提出将外围归纳偏置注入深度神经网络以进行图像识别。作者提出将外围注意力机制结合到多头自注意力中,以让网络学习在给定训练数据的情况下将视野划分为不同的外围区域,其中每个区域捕获不同的视觉特征。作者通过实验表明,所提出的网络对有效的视觉外围进行了建模,以实现可靠的视觉识别。
本文的主要贡献可以总结如下:
这项工作探索通过将外围归纳偏置注入自注意力层来缩小人类和机器视觉之间的差距,并提出了一种称为多头外围注意 (MPA) 的新形式的特征转换。
在 MPA 的基础上,作者引入 PerViT(PerViT),并通过定性和定量分析 PerViT 的学习注意力系统地研究 PerViT 的内部工作原理,这揭示了网络学习感知视觉元素的方式类似于人类视觉没有的方式任何特殊监督。
不同模型大小的图像分类任务的最新性能验证了所提出方法的有效性。
03
方法
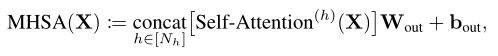
其中是一组输入token,和是转换参数。自注意力的个输出旨在从输入表示中提取一组不同的特征。形式上,head h 的 self-attention 定义为:
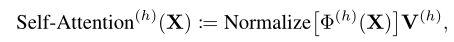
其中 Normalize[·] 表示逐行归一化,是一个基于内容信息提供空间注意力以聚合值的函数:
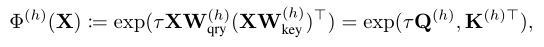
使用的线性投影分别用于查询、键和值。
3.1 Peripheral Vision Transformer
基于 MHSA 的公式,作者将多头外围注意 (MPA) 定义为:
 其中是 Hadamard 积,它混合了给定的注意力对以提供混合注意力。对于基于内容的注意力,作者在查询和键之间使用指数(缩放)点积:。对于基于位置的注意力,作者设计了一个旨在模仿人类视觉系统(例如外围视觉)的神经网络。
其中是 Hadamard 积,它混合了给定的注意力对以提供混合注意力。对于基于内容的注意力,作者在查询和键之间使用指数(缩放)点积:。对于基于位置的注意力,作者设计了一个旨在模仿人类视觉系统(例如外围视觉)的神经网络。Modelling peripheral vision: a Roadmap
人类视野可以根据与注视中心的欧式距离分为几个区域,每个区域形成如图1所示的环形区域,其中每个区域捕获不同的视觉方面;离凝视越近,处理的特征越复杂,离凝视越远,感知的视觉特征就越简单。在二维注意力图的上下文中,作者将查询位置,即感兴趣的特征所在的位置进行变换,作为注视中心,局部查询周围的区域为中心/准中心区域,其余为中/远外围区域。
也许将视野划分为多个子区域的最简单方法是对欧式距离执行单个线性投影,即,其中,为了直接模仿外围视觉,作者使用欧式距离作为相对位置输入 R,并以种不同方式权衡距离,以便网络学习多个尺度的映射:,其中是一组跨层和头共享的可学习参数,并且是查询和键位置之间的欧式距离,。
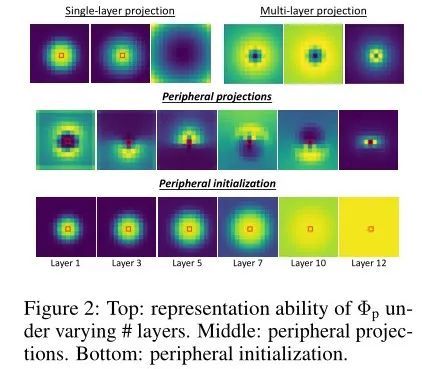
对于 σ,作者选择 sigmoid 来为基于内容的注意力提供归一化权重。这种单层公式的一个主要缺点是只能提供如上图左上角所示的类似高斯的注意力图,因此无法表示不同的外围区域。对于表示不同(环形)外围区域的编码函数,距离必须由 MLP 处理:
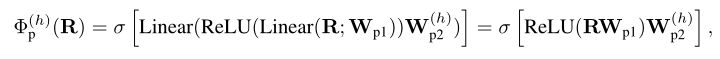
其中和 是线性投影参数,ReLU 赋予函数非线性。第一个投影在头之间共享以交换信息,因此每个特征都能够提供对其他头注意力有效或互补的注意力。给定固定查询点和关键点之间的相同相对距离,即,上式提供了相同的注意力分数:,如上图的右上角所示。
然而,在实际场景中并不总是需要此属性,因为旋转对称属性几乎不适用于大多数现实世界的对象。为了打破上式中的对称属性,并充分保留外围设计,作者引入外围投影(peripheral projection),其中变换参数被赋予小的空间分辨率,使得和,因此它们提供相似但不同的注意力分数,。给定,通过参考键周围的相邻相对距离:
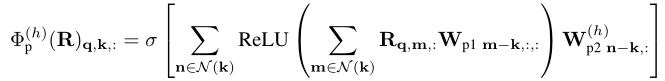
其中是一个提供输入位置周围的一组邻域的函数。在每个外围投影之后,作者添加一个实例归一化层以进行稳定优化:
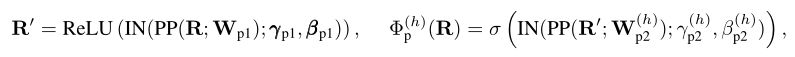
其中是实例范数的权重/偏置。上图的中间行描绘了具有外围投影的的学习注意力,与没有 N 的单层和多层对应物相比,它提供了更多样化的外围注意力图。
Peripheral initialization
最近的研究观察到,受过训练的视觉Transformer的早期层学习局部关注,而后期层则执行全局关注。为了促进本文网络的训练,作者在训练阶段的开始注入这个属性,为此目的通过初始化 的参数,使靠近查询的注意力分数大于早期层中较远的查询,同时均匀地分布在后期层中,如上图的底行所示。作者将此方法称为外围初始化( peripheral initialization),因为它类似于外围视觉的特征,外围视觉也可以在局部或全局范围内操作以感知不同的视觉。给定两个任意选择的距离,满足 ,作者希望,即早期层的局部注意力。
对于后期层的全局注意力,作者希望。作者首先将和的参数初始化为特定值。具体来说,对于所有层和 head :
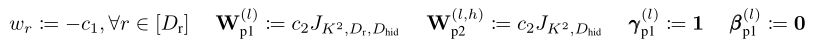
其中是正实数,指的是大小为 N × M 的全一矩阵。上述初始化在第二次外围投影后提供局部注意力,即给定,。
接下来,基于本文的发现,即第二实例范数中的偏差和权重分别控制局部注意力的大小和强度,通过将它们的初始值设置为来模拟外围初始化,其中是注意力大小和强度的初始值集。
3.2 Overall Architecture
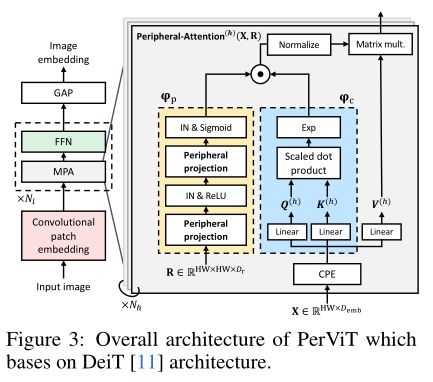
基于提出的外围投影和初始化,作者开发了称为外围视觉Transformer的图像分类模型,如上图所示。原始的 patchify stem由于其粗粒度的早期视觉处理而表现出不合标准的可优化性,因此许多最近的 ViT 模型采用多分辨率金字塔设计来缓解该问题。
虽然金字塔模型在学习可靠的图像嵌入方面已经显示出它们的功效,但作者坚持使用 PerViT 的原始单分辨率圆柱形设计,因为多分辨率的特征使本文的研究难以解释。为了进行细粒度的早期处理,同时保持跨层的单分辨率特征,作者采用卷积patch嵌入层,通道尺寸具有多阶段布局。卷积嵌入层由四个 3×3 和一个 1×1 卷积组成,其中 3×3 卷积后面是BatchNorm和ReLU。
Peripheral Vision Transformer
给定一张图像,卷积patch嵌入提供了token嵌入。嵌入被馈送到个块,每个块由一个 MPA 层和一个带有残差路径的前馈网络组成: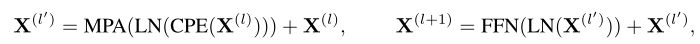
其中 LN 是层归一化,FFN 是由两个带有 GELU 激活的线性变换组成的 MLP。作者在第一层归一化之前采用卷积位置编码 (CPE),即 3 × 3 深度卷积。输出被全局平均池化以形成图像嵌入。
04
实验
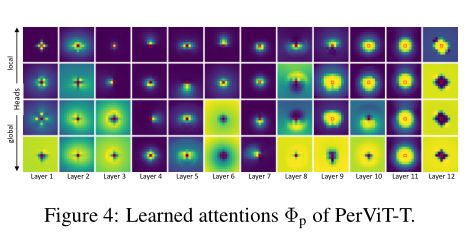
上图展示了学习到的注意力图,可以观察到注意力被学习到处于不同形状的外围区域中。
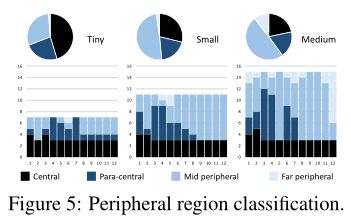
上图的饼图描述了 Tiny、Small 和 Medium 模型的外围区域的比例,其中条形图以分层方式显示它们。
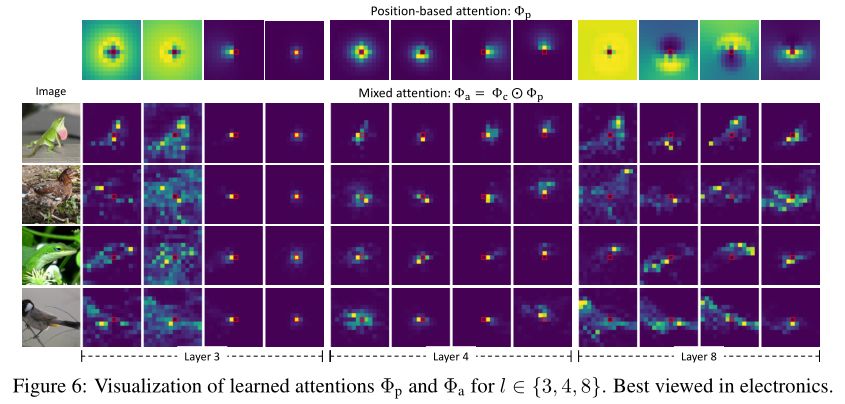
为了研究基于位置的注意力如何对混合注意力 做出贡,作者收集样本图像并将其在上图中的第 3、4 和 8 层的注意力图可视化。
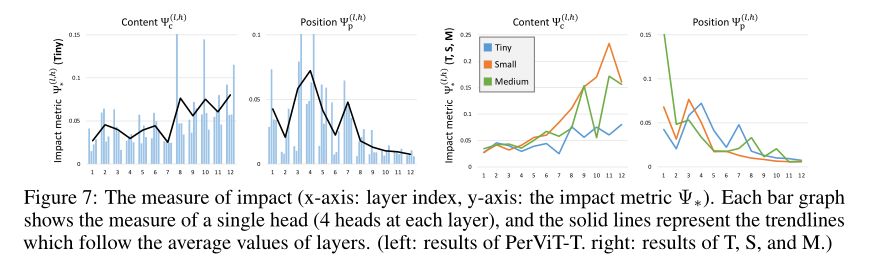
如上图所示,作者观察到一个明显的趋势,即基于位置的注意力的影响在早期处理中显着更高,半动态地转换特征,而后面的层需要较少的位置信息,将视为较小的位置偏差。这种趋势随着更大的模型变得更加明显,如上图右侧所示;与 Tiny 模型相比,Small 和 Medium 模型更多地利用动态转换,尤其是在后面的层中。
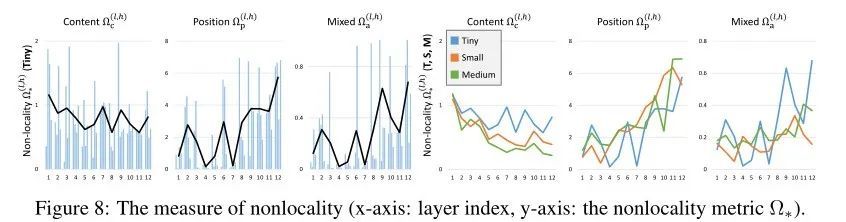
如上图所示,作者观察到之间相似的局部性趋势,这表明位置信息在形成用于特征转换的空间注意力 () 方面比内容信息更占主导地位。
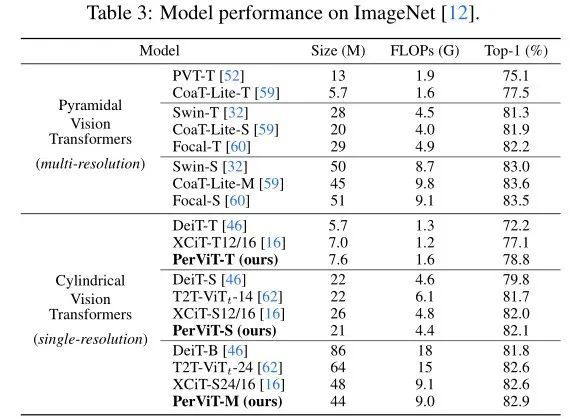
上表展示了本文方法和SOTA方法的对比结果。
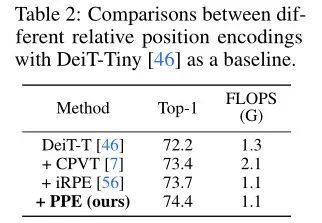
上表展示了不同相对位置编码的结果对比。
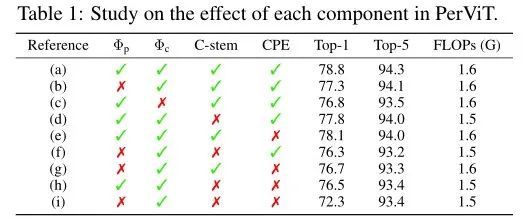
上表展示了本文方法的不同模块的消融结果。
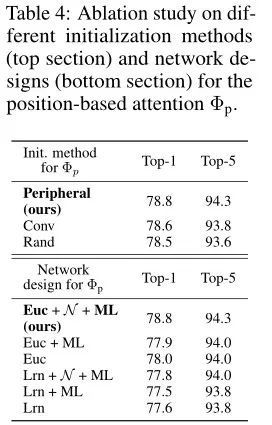
上表展示了不同的初始化方法和网络设计对实验结果的影响。
05
总结
作者系统地研究了所提出网络的内部工作原理,并观察到网络通过学习决定特征转换中的局部性和动态性水平,通过网络本身给定训练数据,从而享受卷积和自注意力的好处。在不同模型大小和深入的消融研究中,ImageNet 上现有技术的持续改进证实了所提出方法的有效性。
参考资料
[1]https://arxiv.org/abs/2206.06801▊ 作者简介研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。知乎/公众号:FightingCV
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
边栏推荐
猜你喜欢

如何停止flink job
el-table,el-table-column,selection,获取多选选中的数据
Lecture 4 Backpropagation Essays
![[Go through 4] 09-10_Classic network analysis](/img/f2/e6e71869b8ab014cc1eea0537fc2e7.png)
[Go through 4] 09-10_Classic network analysis
【Pytorch学习笔记】11.取Dataset的子集、给Dataset打乱顺序的方法(使用Subset、random_split)
vscode+pytorch use experience record (personal record + irregular update)
服务网格istio 1.12.x安装
flink中文文档-目录v1.4

数据库实验五 备份与恢复

Matplotlib(二)—— 子图
随机推荐
Calling Matlab configuration in pycharm: No module named 'matlab.engine'; 'matlab' is not a package
day9-字符串作业
基于Flink CDC实现实时数据采集(一)-接口设计
学习总结week2_3
[Practice 1] Diabetes Genetic Risk Detection Challenge [IFLYTEK Open Platform]
[Go through 4] 09-10_Classic network analysis
[Over 17] Pytorch rewrites keras
vscode要安装的插件
【NFT网站】教你制作开发NFT预售网站官网Mint作品
学习总结day5
Service
day8字典作业
【Kaggle项目实战记录】一个图片分类项目的步骤和思路分享——以树叶分类为例(用Pytorch)
拿出接口数组对象中的所有name值,取出同一个值
el-pagination分页分页设置
The difference between the operators and logical operators
redis persistence
Flink EventTime和Watermarks案例分析
Lecture 4 Backpropagation Essays
Tensorflow踩坑笔记,记录各种报错和解决方法