当前位置:网站首页>Flink Oracle CDC写入到HDFS
Flink Oracle CDC写入到HDFS
2022-08-05 05:14:00 【IT_xhf】
依赖包
引用maven依赖包
<oracle.cdc.version>2.2.0</oracle.cdc.version>
<hadoop.version>2.8.2</hadoop.version>
<avro.version>1.8.2</avro.version>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-oracle-cdc</artifactId>
<version>${oracle.cdc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
</exclusion>
</exclusions>
</dependency>
Oracle CDC Source
Properties properties = new Properties();
properties.put("decimal.handling.mode", "double");
DebeziumDeserializationSchema deserialization = new JsonDebeziumDeserializationSchema();
DebeziumSourceFunction source = OracleSource.builder().hostname("ip")
.port(1521)
.database("db_name")
.schemaList("schema_name")
.tableList("schema_name.table_name")
.username("username")
.password("password")
.startupOptions(StartupOptions.latest())
.debeziumProperties(properties)
.deserializer(deserialization)
.build();
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
streamEnv.getCheckpointConfig().setCheckpointInterval(2*60*1000);
DataStreamSource streamSource = streamEnv.addSource(source);
针对Oracle的Number类型字段,必须要指定properties.put("decimal.handling.mode", "double");属性,要不然该类型的字段解析出来的是字节数组。
HDFS Sink
// org.apache.flink.configuration.Configuration conf = new org.apache.flink.configuration.Configuration();
// conf.setString("flink.hadoop.fs.defaultFS", "hdfs://emr-cluster");
// conf.setString("flink.hadoop.dfs.nameservices", "emr-cluster");
// conf.setString("flink.hadoop.dfs.ha.namenodes.emr-cluster", "nn1,nn2");
// conf.setString("flink.hadoop.dfs.namenode.rpc-address.emr-cluster.nn1","nn1_ip:port");
// conf.setString("flink.hadoop.dfs.namenode.rpc-address.emr-cluster.nn2", "nn2_ip:port");
// conf.setString("flink.hadoop.dfs.client.failover.proxy.provider.emr-cluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
// FileSystem.initialize(conf, null);
ParquetWriterFactory<RowData> factory = ParquetRowDataBuilder.createWriterFactory(rowType, new Configuration(), true);
Path basePath = new Path("hdfs://ip:port/user/hive/warehouse/stringvalue");
FileSink<RowData> fileSink = FileSink.forBulkFormat(basePath, factory)
// 为了解决小文件,加入了文件生成策略 最大256MB, 10分钟生成一次文件,但是好像没有效果,不知道是否和checkpoint的时间有关系
.withRollingPolicy(new FileSystemTableSink.TableRollingPolicy(true, 256*1024*1024, 10*60))
.withBucketAssigner(new BasePathBucketAssigner<>()).build();
streamSource .sinkTo(fileSink);
对于写入HDFS高可用,需要在程序里面加入以下代码
org.apache.flink.configuration.Configuration conf = new org.apache.flink.configuration.Configuration();
conf.setString("flink.hadoop.fs.defaultFS", "hdfs://emr-cluster");
conf.setString("flink.hadoop.dfs.nameservices", "emr-cluster");
conf.setString("flink.hadoop.dfs.ha.namenodes.emr-cluster", "nn1,nn2");
conf.setString("flink.hadoop.dfs.namenode.rpc-address.emr-cluster.nn1","nn1_ip:port");
conf.setString("flink.hadoop.dfs.namenode.rpc-address.emr-cluster.nn2", "nn2_ip:port");
conf.setString("flink.hadoop.dfs.client.failover.proxy.provider.emr-cluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
FileSystem.initialize(conf, null);
总结
1、对于Number字段默认情况下不会解析出来,需要设置properties.put(“decimal.handling.mode”, “double”);解析出来的字段变成double类型,对于数据比较大的,会以科学计数法显示。
2、高可用设置,如果不想在项目中引入core-site.xml和hdfs-site.xml文件,则需要在代码中引用。
边栏推荐
猜你喜欢
【练一下1】糖尿病遗传风险检测挑战赛 【讯飞开放平台】
vscode+pytorch使用经验记录(个人记录+不定时更新)
【NFT开发】设计师无技术基础保姆级开发NFT教程在Opensea上全套开发一个NFT项目+构建Web3网站
Mesos学习
第四讲 反向传播随笔
Lecture 4 Backpropagation Essays

Multi-threaded query results, add List collection
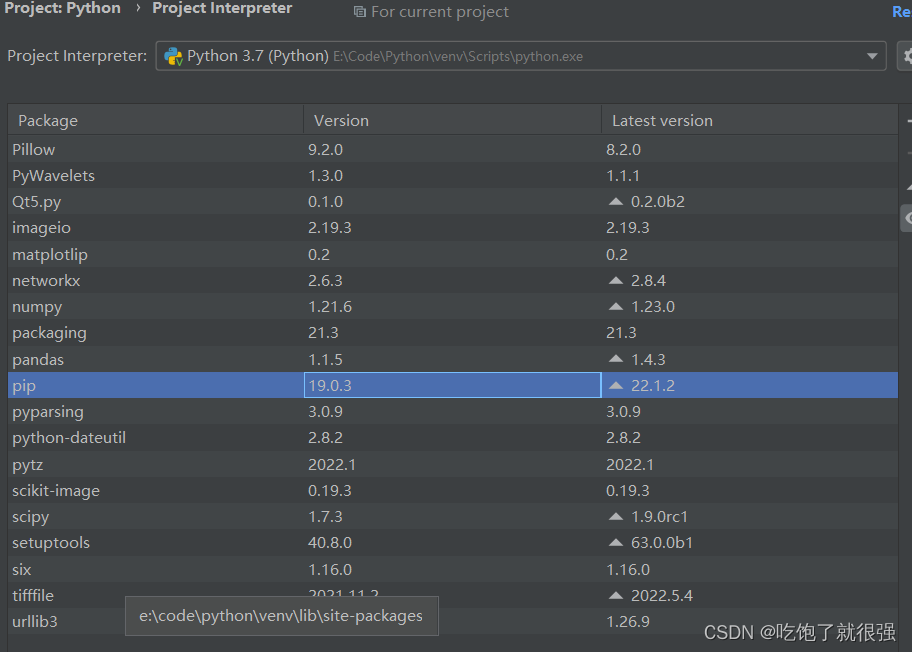
Pycharm中使用pip安装第三方库安装失败:“Non-zero exit code (2)“的解决方法
【过一下9】卷积
2022 Hangzhou Electric Multi-School 1st Session 01
随机推荐
[Go through 9] Convolution
【记一下1】2022年6月29日 哥和弟 双重痛苦
学习总结week3_3迭代器_模块
Mesos learning
将照片形式的纸质公章转化为电子公章(不需要下载ps)
redis 持久化
[Remember 1] June 29, 2022 Brother and brother double pain
range函数作用
CAP+BASE
Flink HA配置
redis persistence
Using pip to install third-party libraries in Pycharm fails to install: "Non-zero exit code (2)" solution
[Let's pass 14] A day in the study room
Mysql5.7 二进制 部署
flink项目开发-配置jar依赖,连接器,类库
Flink 状态与容错 ( state 和 Fault Tolerance)
2022 The 4th C.Easy Counting Problem (EGF+NTT)
转正菜鸟前进中的经验(废话)之谈 持续更新中... ...
【读书】长期更新
BFC(Block Formatting Context)