当前位置:网站首页>Lecture 5 Using pytorch to implement linear regression
Lecture 5 Using pytorch to implement linear regression
2022-08-05 05:23:00 【A long way to go】
使用pytorch实现线性回归
The fifth lecture
广播机制
For example, adding between matrices of different shapes,will broadcast,Expand to the same shape and perform the operation
广播前: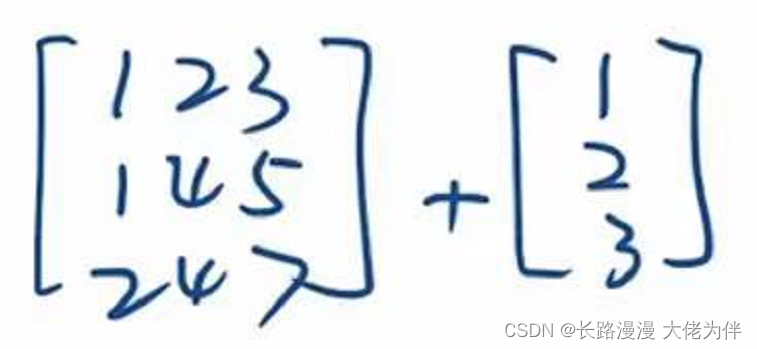
广播后: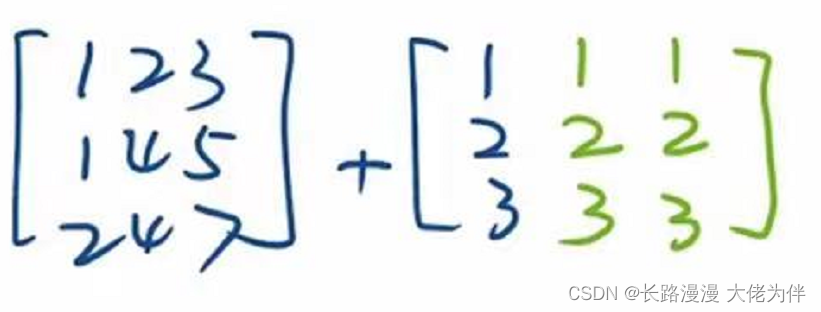
The broadcast mechanism is also used below,y1,y2,y3is not a vector,而是一个矩阵,因此w需要进行广播,再与x1,x2,x3进行数乘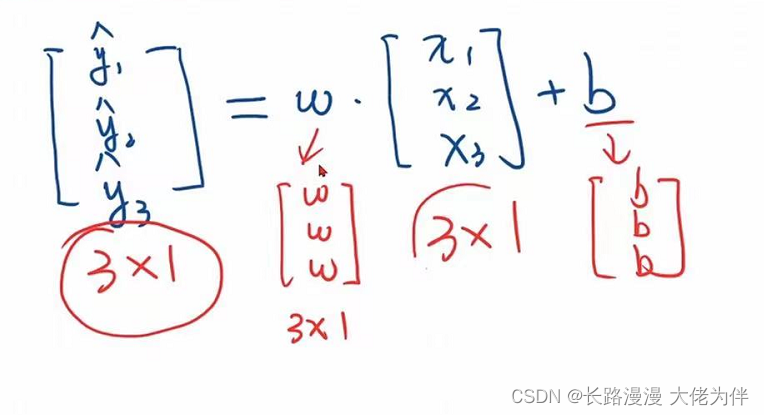
init构造函数
initConstructors are used to initialize objects
简述 init、new、call 方法
用Module构造的对象,automatically according to the calculation graph,实现backward的过程
使用pytorch实现线性回归
需要注意一些问题
- 1.#Module 中实现了forward,Therefore the following needs to be rewrittenforward函数覆盖掉Module中的forward,因此LinearModel必须重写forward
# Module 中实现了forward,Therefore the following needs to be rewrittenforward函数覆盖掉Module中的forward
# Linear also constructed in Module,Hence also a callable object
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
#torch.nn.Linearactually constructing an object,Weights and biases are included,继承自Module
# (1,1)refers to each input samplexand every output sampley的特征维度,这里数据集中的x和y的特征都是1维的
# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
#self.linear(x) add after the object()Means a callable object is implemented
y_pred = self.linear(x)
return y_pred
- 如果将torch.nn.MSELoss的参数设置为size_average=False,在pycharm中会报错size_average and reduce args will be deprecated, please use reduction=‘sum’ ,Maybe it's because of the compiler

# 构造损失函数和优化器MSE
# MSELoss也继承自 nn.Module
#criterion = torch.nn.MSELoss(size_average=False)中不能设置size_average=False,会出现以下报错
#UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # model.parameters()自动完成参数的初始化操作
- The number of times the model is trained
Reduce the loss on the training set if needed,You can increase the number of training sessions,即 for epoch in range(1000)
But there are dangers in doing so,Because the loss on the training set is getting smaller and smaller,The loss on the test set may get bigger and bigger,产生过拟合问题
Linear regression implementation code
import torch
# prepare dataset
# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
# Module 中实现了forward,Therefore the following needs to be rewrittenforward函数覆盖掉Module中的forward
# Linear also constructed in Module,Hence also a callable object
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
#torch.nn.Linearactually constructing an object,Weights and biases are included,继承自Module
# (1,1)refers to each input samplexand every output sampley的特征维度,这里数据集中的x和y的特征都是1维的
# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
#self.linear(x) add after the object()Means a callable object is implemented
y_pred = self.linear(x)
return y_pred
#model是一个callable,即可调用的对象,可以model(x)
model = LinearModel()
# 构造损失函数和优化器MSE
# MSELoss也继承自 nn.Module
#criterion = torch.nn.MSELoss(size_average=False)中不能设置size_average=False,会出现以下报错
#UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # model.parameters()自动完成参数的初始化操作
# Reduce the loss on the training set if needed,You can increase the number of training sessions,即 for epoch in range(1000)
# But there are dangers in doing so,Because the loss on the training set is getting smaller and smaller,The loss on the test set may get bigger and bigger,产生过拟合问题
for epoch in range(100):
y_pred = model(x_data) # forward:predict
loss = criterion(y_pred, y_data) # forward: loss
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward() # backward: autograd,自动计算梯度
optimizer.step() # update 参数,即更新w和b的值
print('w = ', model.linear.weight.item())#weight是一个矩阵,So the value needs to be calleditem()
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
运行结果
0 35.37689208984375
1 15.92350959777832
2 7.260907173156738
3 3.402086019515991
4 1.6818101406097412
5 0.9135867357254028
6 0.569225549697876
............
94 0.08291453868150711
95 0.08172288537025452
96 0.08054838329553604
97 0.07939067482948303
98 0.07824991643428802
99 0.07712534815073013
w = 1.8151198625564575
b = 0.4202759563922882
y_pred = tensor([[7.6808]])
边栏推荐
猜你喜欢
How can Flutter parent and child components receive click events
【过一下10】sklearn使用记录
u-boot debugging and positioning means
将照片形式的纸质公章转化为电子公章(不需要下载ps)

Algorithms - ones and zeros (Kotlin)
第四讲 back propagation 反向传播
【过一下12】整整一星期没记录
RL强化学习总结(一)

The difference between span tag and p

MySQL Foundation (1) - Basic Cognition and Operation
随机推荐
【过一下10】sklearn使用记录
Cryptography Series: PEM and PKCS7, PKCS8, PKCS12
[Study Notes Dish Dog Learning C] Classic Written Exam Questions of Dynamic Memory Management
Dashboard Display | DataEase Look at China: Data Presents China's Capital Market
Detailed Explanation of Redis Sentinel Mode Configuration File
Basic properties of binary tree + oj problem analysis
判断语句_switch与case
Dephi reverse tool Dede exports function name MAP and imports it into IDA
开发一套高容错分布式系统
coppercam入门手册[6]
After controlling the export file in MySQL, it becomes \N. Is there any solution?
The software design experiment four bridge model experiment
SQL(二) —— join窗口函数视图
jvm three heap and stack
Qt produces 18 frames of Cupid to express his love, is it your Cupid!!!
Flutter 父子组件如何都能收到点击事件
Flutter learning - the beginning
redis 持久化
【过一下9】卷积
u-boot in u-boot, dm-pre-reloc