当前位置:网站首页>Flink HA配置
Flink HA配置
2022-08-05 05:14:00 【bigdata1024】
JobManager 高可用(HA)
jobManager协调每个flink任务部署。它负责调度和资源管理。
默认情况下,每个flink集群只有一个JobManager,这将导致一个单点故障(SPOF):如果JobManager挂了,则不能提交新的任务,并且运行中的程序也会失败。
使用JobManager HA,集群可以从JobManager故障中恢复,从而避免SPOF 。 用户在standalone或 YARN集群 模式下,配置高可用性
- Standalone集群的高可用
- 配置
- Yarn集群高可用
- 配置
- zookeeper的安全配置
- zookeeper选举
Standalone集群的高可用
Standalone模式(独立模式)下JobManager的高可用性的基本思想是,任何时候都有一个一个 Master JobManager ,并且多个Standby JobManagers 。 Standby JobManagers可以在Master JobManager 挂掉的情况下接管集群成为Master JobManager。 这样保证了没有单点故障,一旦某一个Standby JobManager接管集群,程序就可以继续运行。 Standby JobManager和Master JobManager实例之间没有明确区别。 每个JobManager可以成为Master或Standby节点。
举例,使用三个JobManager节点的情况下,进行以下设置:

配置
要启用JobManager高可用性,必须将高可用性模式设置为zookeeper, 配置一个ZooKeeper quorum,并配置一个masters文件 存储所有JobManager hostname 及其Web UI端口号。
Flink利用ZooKeeper 实现运行中的JobManager节点之间的分布式协调。 ZooKeeper是独立于Flink的服务,它通过领导选举制和轻量级状态一致性存储来提供高度可靠的分布式协调。有关ZooKeeper的更多信息,请查看 ZooKeeper入门指南。 Flink包含安装简单ZooKeeper 的引导脚本。
Masters File(masters)
为了启动集群的高可用(HA),需要配置conf/masters中的masters文件 :
- masters file: masters file 文件中包含所有启动JobManager节点的hosts,以及对应Web UI的端口号
jobManagerAddress1:webUIPort1
[...]
jobManagerAddressX:webUIPortX
默认情况下,JobManager会选择 随机端口号 作为内部进程通信。我们可以通过修改参数recovery.jobmanager.port的值来修改。这个参数的配置接受为单个端口号(比如50010),也可以设置一段范围比如 50000~50025,或者端口号组合(比如50010,50011,50020~50025,50050~50075)。
配置文件(flink-conf.yaml)
为了启动集群的高可用(HA),需要对文件conf/flink-conf.yaml做一下配置:
- 高可用模式 (必须): 要启用高可用,需要配置文件 conf/flink-conf.yaml 中的 high-availability mode 设置为 zookeeper。
high-availability: zookeeper
- ZooKeeper 仲裁 (必须的): 一个ZooKeeper quorum 是一组可以复制的ZooKeeper服务器,提供分布式协调服务。
high-availability.zookeeper.quorum: address1:2181[,...],addressX:2181每组 addressX:port 表示一个ZooKeeper服务, Flink必须可通过对应的地址和端口通信。
- ZooKeeper root (推荐的): ZooKeeper节点根目录,其下放置所有集群节点的namespace。
high-availability.zookeeper.path.root: /flink
- ZooKeeper 集群id (推荐的): ZooKeeper节点集群id,其中放置了集群所需的所有协调数据。
high-availability.cluster-id: /default_ns # important: customize per cluster
重要: 。 当你在yarn集群中运行的时候,不建议手工修改这个值。默认情况下,Yarn集群和Yarn会话会根据Yarn应用程序ID自动生成命名空间。 可以手动配置覆盖了Yarn中默认配置。 或可以使用-z CLI选项指定集群id,这样可以反过来覆盖手动配置。如果你运行了多个单独的Flink HA 集群,你必须为每个集群配置单独的集群id。
- 存储目录 (required): JobManager的元数据保存在文件系统存储目录 storageDir 中,只有一个指向此状态的指针存储在ZooKeeper中。
high-availability.zookeeper.storageDir: hdfs:///flink/recoverystorageDir存储了所有恢复一个JobManager挂掉所需的元数据。
配置主机和ZooKeeper quorum后,可以照常使用提供的集群启动脚本。 他们将启动一个HA集群。 请记住,当您调用脚本时 ZooKeeper quorum 必须已经启动,并确保为您启动的每个HA群集配置单独的ZooKeeper根路径
例子: Standalone 集群有2个JobManagers
- 配置文件 conf/flink-conf.yaml 中的 high-availability mod 和 ZooKeeper quorum:
high-availability: zookeeper high-availability.zookeeper.quorum: localhost:2181 high-availability.zookeeper.path.root: /flink high-availability.cluster-id: /cluster_one # important: customize per cluster high-availability.zookeeper.storageDir: hdfs:///flink/recovery - 配置conf/masters文件中的Configure masters:
localhost:8081 localhost:8082 - 配置conf/zoo.cfg文件中的 ZooKeeper server (目前只能在每台机器上运行一个ZooKeeper服务器):
server.0=localhost:2888:3888 - 启动 ZooKeeper quorum:
$ bin/start-zookeeper-quorum.sh Starting zookeeper daemon on host localhost. - 启动一个高可用(HA) 集群:
$ bin/start-cluster.sh Starting HA cluster with 2 masters and 1 peers in ZooKeeper quorum. Starting jobmanager daemon on host localhost. Starting jobmanager daemon on host localhost. Starting taskmanager daemon on host localhost. - 停止ZooKeeper quorum 和集群:
$ bin/stop-cluster.sh Stopping taskmanager daemon (pid: 7647) on localhost. Stopping jobmanager daemon (pid: 7495) on host localhost. Stopping jobmanager daemon (pid: 7349) on host localhost. $ bin/stop-zookeeper-quorum.sh Stopping zookeeper daemon (pid: 7101) on host localhost.
Yarn 集群高可用
当运行高可用性的YARN集群时,我们不运行多个JobManager(ApplicationMaster)节点,而是只有一个,当YARN挂了会导致这个JobManager重新启动。 具体的行为取决于不同的YARN版本。
配置
Maximum Application Master Attempts (yarn-site.xml)
必须在YARN的配置文件yarn-site.xml 中设置提交应用程序的最大尝试次数:
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>当前YARN版本的默认值为2(表示允许JobManager失败一次)。
Application Attempts (flink-conf.yaml)
除了HA配置(see above), 您必须配置文件conf/flink-conf.yaml中的最大尝试次数:
yarn.application-attempts: 10这意味着应用程序可以在YARN应用程序失败之前重新启动9次(9次重试+1次初始化)。额外的重启可以由yarn参数来控制,针对节点硬件故障重启,或者NodeManager同步。这些重启并没有被计算在yarn.application-attempts的次数中,可以查看此博客Jian Fang blog post。注意的是“yarn.resourcemanager.am.max-attempts”是应用程序重新启动的上限。 因此,在Flink中设置的应用程序尝试次数不能超过YARN启动的YARN集群设置。
容器关闭行为
- YARN 2.3.0 <version <2.4.0 。 如果应用程序管理器出现故障,则所有容器都将重新启动。
- YARN 2.4.0 <version <2.6.0。 TaskManager容器在应用程序管理器故障时依然保持存活。 这具有的优点是启动时间更快,并且用户不必等待再次获取容器资源。
- YARN 2.6.0 <= version:将尝试失败有效期间设置为Flinks的Akka超时值。 尝试失败有效性间隔表示,在系统在一个时间间隔内,应用程序尝试的次数超过最大次数之后,应用程序才被杀死。 这样可以避免耗时长的工作会耗尽其尝试次数。
Note: Hadoop YARN 2.4.0有一个主要漏洞(2.5.0中被修复),应用程序管理器/任务管理器容器(container)重启后,
容器无法重启. 查看更多细节FLINK-4142[https://issues.apache.org/jira/browse/FLINK-4142].
我们建议至少在YARN上使用Hadoop 2.5.0进行高可用性设置.
例子: 高可用 YARN Session
- 配置文件 conf/flink-conf.yaml 中的 high-availability mod 和 ZooKeeper quorum:
high-availability: zookeeper
high-availability.zookeeper.quorum: localhost:2181
high-availability.zookeeper.storageDir: hdfs:///flink/recovery
high-availability.zookeeper.path.root: /flink
yarn.application-attempts: 10
- 配置conf/zoo.cfg文件中的 ZooKeeper server (目前只能在每台机器上运行一个ZooKeeper服务器):
server.0=localhost:2888:3888- 启动 ZooKeeper quorum:
$ bin/start-zookeeper-quorum.sh
Starting zookeeper daemon on host localhost.- 启动 HA-cluster集群:
$ bin/yarn-session.sh -n 2
Zookeepe的安全配置
如果ZooKeeper使用Kerberos运行在安全模式下,可以根据需要覆盖flink-conf.yaml中的以下配置:
zookeeper.sasl.service-name: zookeeper # 默认是 "zookeeper". 如果ZooKeeper quorum被设置为不同的服务名字. 可以修改该参数
zookeeper.sasl.login-context-name: Client # 默认是 "Client". 这个参数需要和"security.kerberos.login.contexts"中的一个参数 有关Kerberos安全性的Flink配置的更多信息,请参阅这里. 也可以在这里进一步了解Flink如何内部设置基于Kerberos的安全性。
Bootstrap ZooKeeper
如果您没有安装正在运行的ZooKeeper,可以使用Flink附带的帮助脚本。
在conf/zoo.cfg中有一个ZooKeeper配置模板。 可以使用通过把hosts配置到server.X参数中来运行ZooKeeper,其中X是每个服务器的唯一ID:
server.X=addressX:peerPort:leaderPort
[...]
server.Y=addressY:peerPort:leaderPort脚本bin/start-zookeeper-quorum.sh将在每个配置的主机上启动一个ZooKeeper服务器。 启动的进程通过Flink包装器启动ZooKeeper服务器,Flink包装器从conf/zoo.cfg读取配置,并确保设置一些所需的参数。 在生产环境中,建议自己管理ZooKeeper安装。
获取更多大数据资料,视频以及技术交流请加群:

边栏推荐
猜你喜欢


![coppercam primer [6]](/img/d3/a7d44aa19acfb18c5a8cacdc8176e9.png)
![[Study Notes Dish Dog Learning C] Classic Written Exam Questions of Dynamic Memory Management](/img/0b/f7d9205c616f7785519cf94853d37d.png)
随机推荐
el-table,el-table-column,selection,获取多选选中的数据
Distributed and Clustered
day11-函数作业
day9-字符串作业
Lecture 4 Backpropagation Essays
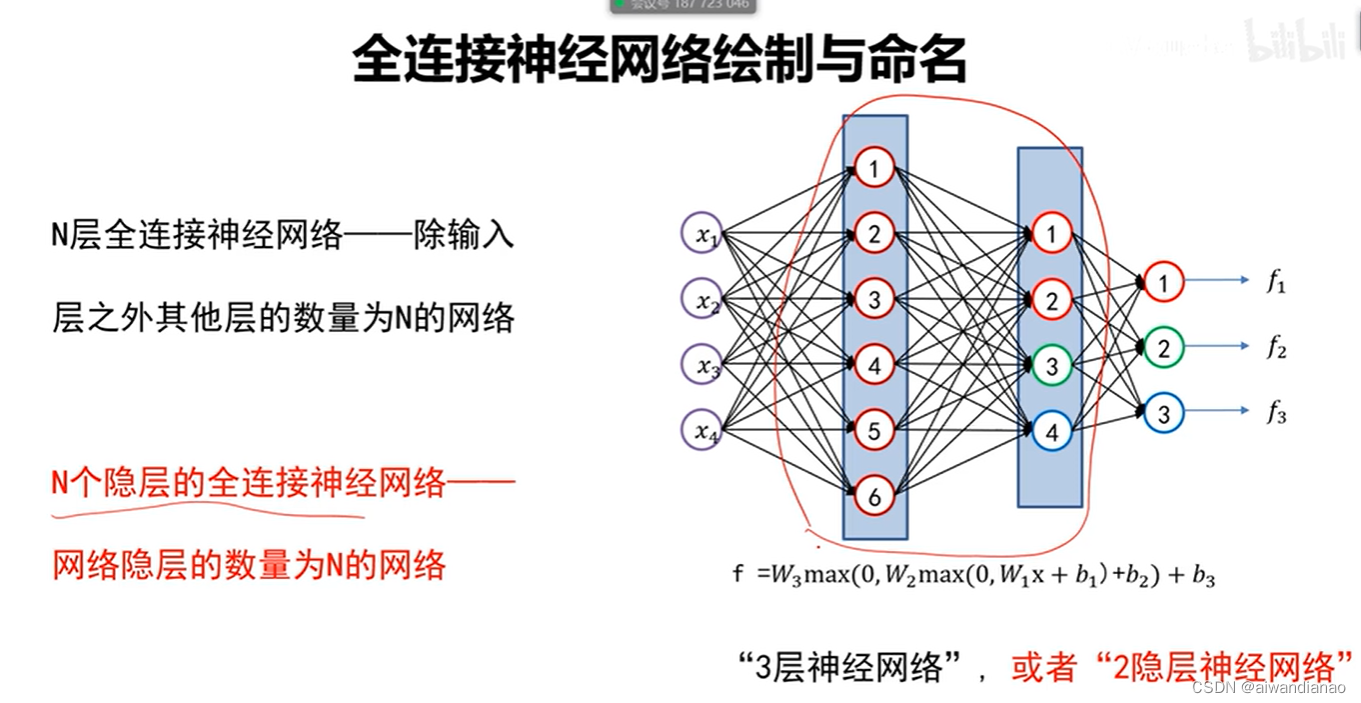
【过一下7】全连接神经网络视频第一节的笔记
机器学习(一) —— 机器学习基础
1.3 mysql batch insert data
Database experiment five backup and recovery
【过一下10】sklearn使用记录
day12函数进阶作业
day7-列表作业(1)
Error creating bean with name 'configDataContextRefresher' defined in class path resource
Flink 状态与容错 ( state 和 Fault Tolerance)
RDD和DataFrame和Dataset
day10-字符串作业
Lecture 3 Gradient Tutorial Gradient Descent and Stochastic Gradient Descent
数据库实验五 备份与恢复
server disk array
Mysql5.7 二进制 部署