当前位置:网站首页>【数据库和SQL学习笔记】10.(T-SQL语言)函数、存储过程、触发器
【数据库和SQL学习笔记】10.(T-SQL语言)函数、存储过程、触发器
2022-08-05 05:15:00 【takedachia】
工具:SQL Server 2019 Express
操作系统:Windows 10
用到的数据库备份: teaching.bak
回顾一下表结构:
t_student (S#, Sname, Sex, Age, Major)
t_teacher (T#, Tname, Age, Title)
t_course (C#, Cname, T#)
t_student_course (S#, C#, Score)
函数(function)
函数是由一个或多个T-SQL语句组成的子程序,可用于封装代码以便重新使用。
T-SQL提供了丰富的现成的数据操作函数(比如之前已经接触过的getdate()等),以完成各种数据管理工作。
我们也可以自己定义函数。
根据返回值形式的不同,用户自定义函数分为:
- 标量函数:返回一个确定类型的标量值
- 内嵌表值函数:返回一张表
- 多语句表值函数:以上两者结合
例1:
create function average(@cn char(7)) returns float
as
begin
declare @aver float
select @aver=(select avg(Score) from t_student_course
where C#[email protected])
return @aver
end
解释:
创建标量函数average。定义了一个参数@cn,类型char(7)。returns后定义返回值类型,类型为float。
as后接函数语句块。
语句块中传入参数@cn作为选课表的课程号,计算该课程号的平均分,作为return的返回值。
我们在查询框中输入以上代码执行后,这个函数就会在对象资源管理器中的对应位置查看到: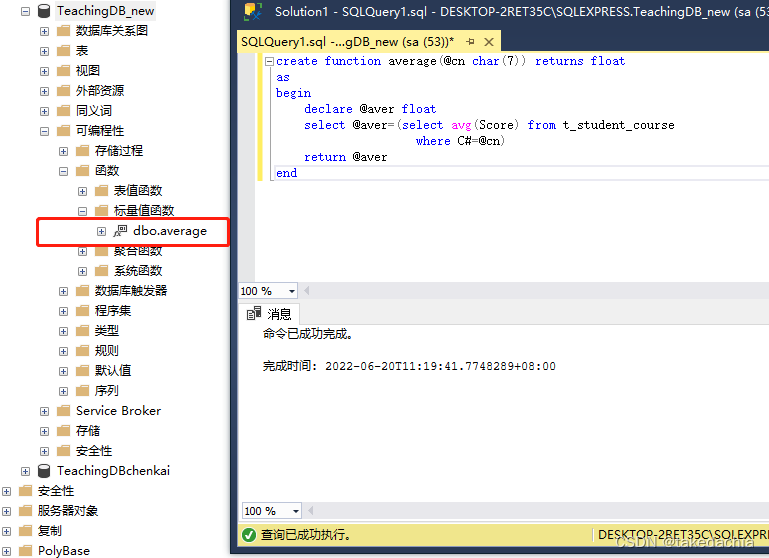
调用函数:
注意调用自定义标量值函数时,必须指定所有者。这里就叫 dbo.average 。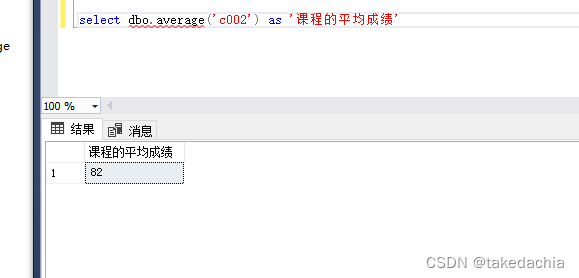
例2:
create function st_func(@major char(10)) returns table
as
return
(select t_student.S#, Sname, C#, Score
from t_student, t_student_course
where [email protected] and t_student.S#=t_student_course.S#)
解释:
创建表值函数,returns指定为table。
as后直接定义了return的内容。
该函数查询了指定专业名称(@major)的学生的学号、姓名、课程号、成绩。
调用函数:
注意调用表值函数时,无需指定所有者: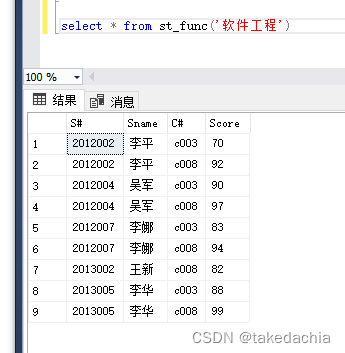
存储过程(procedure)
存储过程是一类数据库对象,其独立存储在数据库内。
存储过程可接受输入参数、输出参数,返回单个或多个结果集以及返回值,由应用程序通过调用执行。
存储过程的特点:
- 模块化程序设计
- 更快速的执行
- 减少网络流量
- 保证数据库安全
存储过程可分为:
系统存储过程(存在master库中,以’sp_'开头命名)
本地存储过程(用户自行创建,存储在用户数据库中)
临时存储过程
远程存储过程(位于远程服务器,用于分布式查询)
扩展存储过程
系统存储过程
系统存储过程存在master库中,以’sp_'开头命名。例子:
sp_help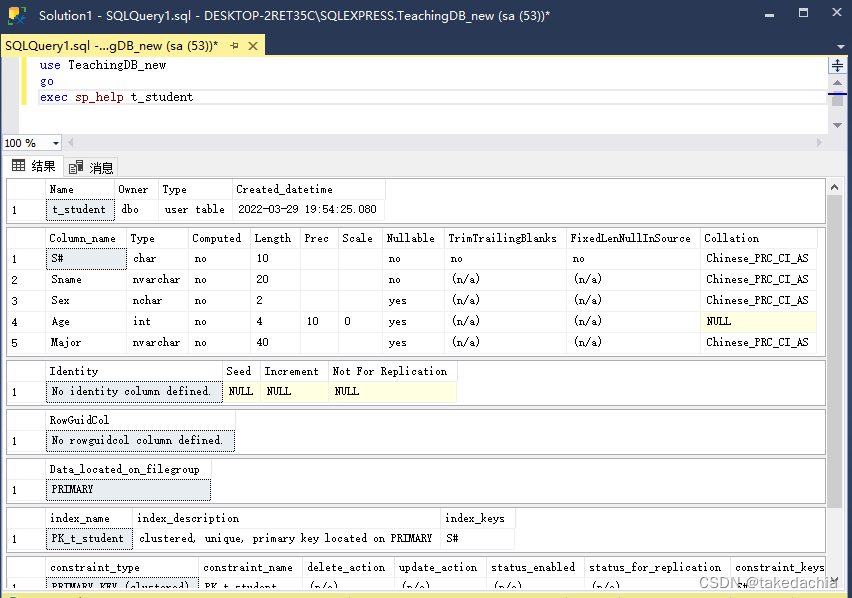
本地存储过程(自定义存储过程)
例1:
create procedure student_avg
as
select S#, avg(Score) as 平均分
from t_student_course
group by S#
这是一个无参存储过程。
存储过程保存位置: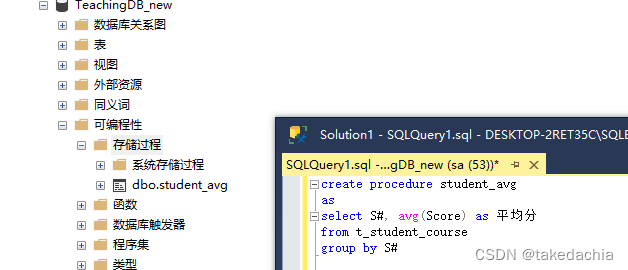
执行: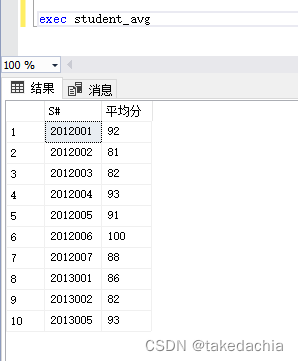
例2:
create procedure GetStudent
@number char(10)
as
select * from t_student
where S#[email protected]
创建有参存储过程。
执行:
存储过程传入的参数直接跟在存储过程名字隔一个空格后面。
例3:
create procedure Student_Name
@name varchar(30) = '%'
as select * from t_student
where Sname like @name
设定默认参数,设为通配符。
执行:
传入的参数同样含通配符。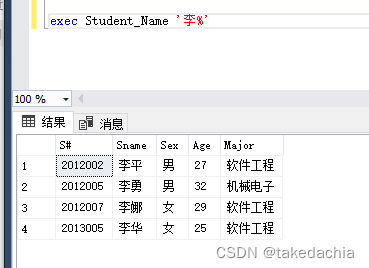
例4(带输入输出参数的情况):
create procedure Student_avg2
@number char(10), @avgscore int output
as
select @avgscore=avg(Score)
from t_student, t_student_course
where t_student.S#=t_student_course.S# and t_student.S#[email protected]
带输入输出参数的存储过程,定义参数的时候指明为output,然后在定义过程时为输出参数赋值。
执行:
调用带输入输出参数的存储过程,先定义一个变量。
传入输出参数的位置(指定output),用以赋值,最后用select打印。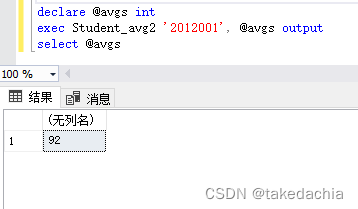
例5: 为学生的平均分评个等级
create procedure getgrade
@sid char(9), @grade char(1) output
as
declare @avgs int
select @avgs=avg(Score) from t_student_course where S#[email protected]
if @avgs>90 set @grade='A'
else if @avgs>80 set @grade='B'
else if @avgs>60 set @grade='C'
else set @grade='D'
定义了一个中间变量@avgs,然后作判断。
也可以用case语句写:
create procedure getgrade2
@sid char(9), @grade char(1) output
as
declare @avgs int
select @avgs=avg(Score) from t_student_course where S#[email protected]
set @grade = case
when @avgs>90 then 'A'
when @avgs>80 and @avgs<=90 then 'B'
when @avgs>60 and @avgs<=80 then 'C'
else 'D'
end
执行:
获取学号为2021001的学生的成绩等级:
触发器(trigger)
触发器本质上也是一种存储过程,是一种在基本表被修改时自动执行的内嵌过程,主要通过事件进行触发而被执行。
(个人觉得可以类比python的魔法方法)
触发器常用于保证数据的完整性。
分类:
- DML触发器:
当数据库服务器中发生INSERT、UPDATE、DELETE等事件(数据操作语言事件)时被触发。
表层面。 - DDL触发器
当数据库服务器中执行DDL数据定义语言时触发,如添加、删除或修改数据库时。
数据库层面。
我们可以定义触发器,下面是例子。
DML触发器
例1:定义修改触发器,打印提示:
create trigger reminder1
on t_student
for
update
as print '你在修改学生表的数据'
定义完的触发器可在对象资源管理器中对应的表中找到: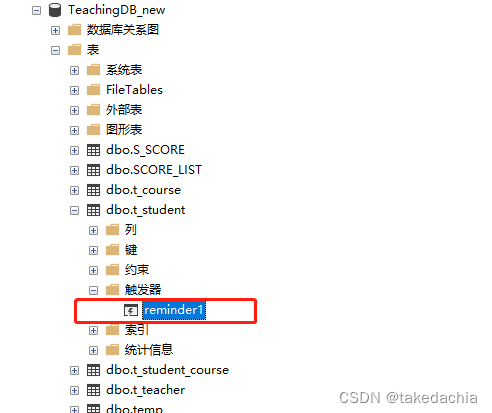
执行效果: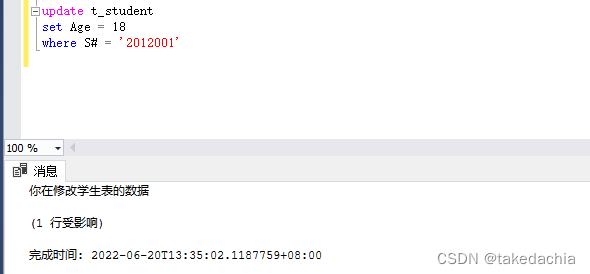
例2:定义插入数据触发器,打印提示并撤销操作:
create trigger reminder2
on t_student
for
insert
as print '你在新增学生表的数据'
rollback
写上rollback语句可执行回滚,予撤销操作。
执行效果: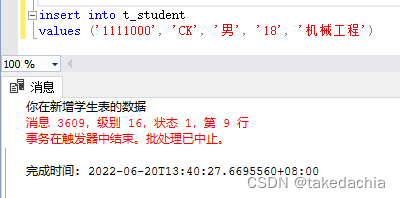
例3:删除表中数据时,执行一个select操作:
create trigger print_table
on t_student
for
delete
as select * from t_student
效果略。
临时表
需要了解的是,SQL Server为每个DML触发器定义了两个特殊的临时表:inserted 和 deleted,存于数据库服务器的内存中,为只读。
触发器执行过程中,系统会建立和维护这两张临时表,trigger执行完毕就会删除。
用户执行insert时,所有被添加的记录被存储于inserted表中;
执行delete时,所有被删除的记录被存储于deleted表中;
执行update时,被修改记录首先被存储于deleted,修改后的数据则存储予inserted中。
DDL触发器
例:在当前数据库中建立删表、改表的触发器,撤销删除和修改操作:
create trigger limited
on database
for drop_table, alter_table
as print '不允许修改表或删除表'
rollback
效果略。
在触发器中调用存储过程
我们在触发器中可以调用存储过程,直接在as后面写上 exec + 存储过程 即可。
例:
create proc p1 as
select * from t_student
create trigger tr1 on t_student
for insert, update, delete
as exec p1
边栏推荐
猜你喜欢
Thread handler句柄 IntentServvice handlerThread
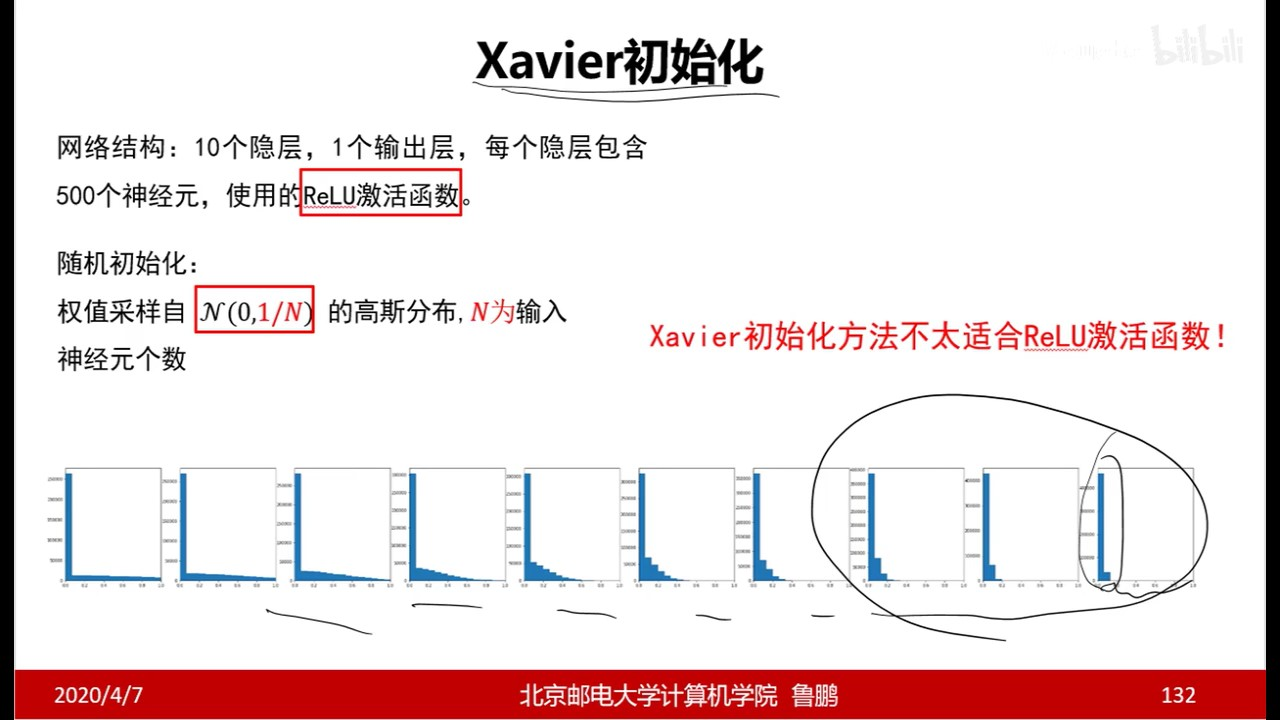
【过一下8】全连接神经网络 视频 笔记
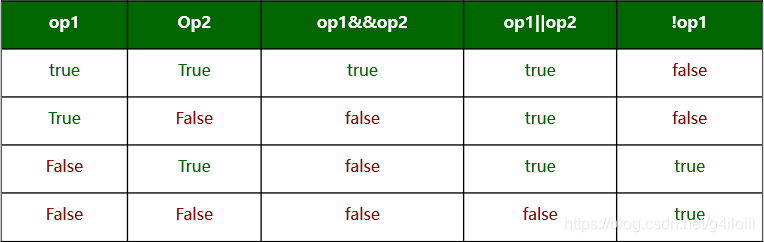
The difference between the operators and logical operators
Lecture 5 Using pytorch to implement linear regression

Flink HA配置
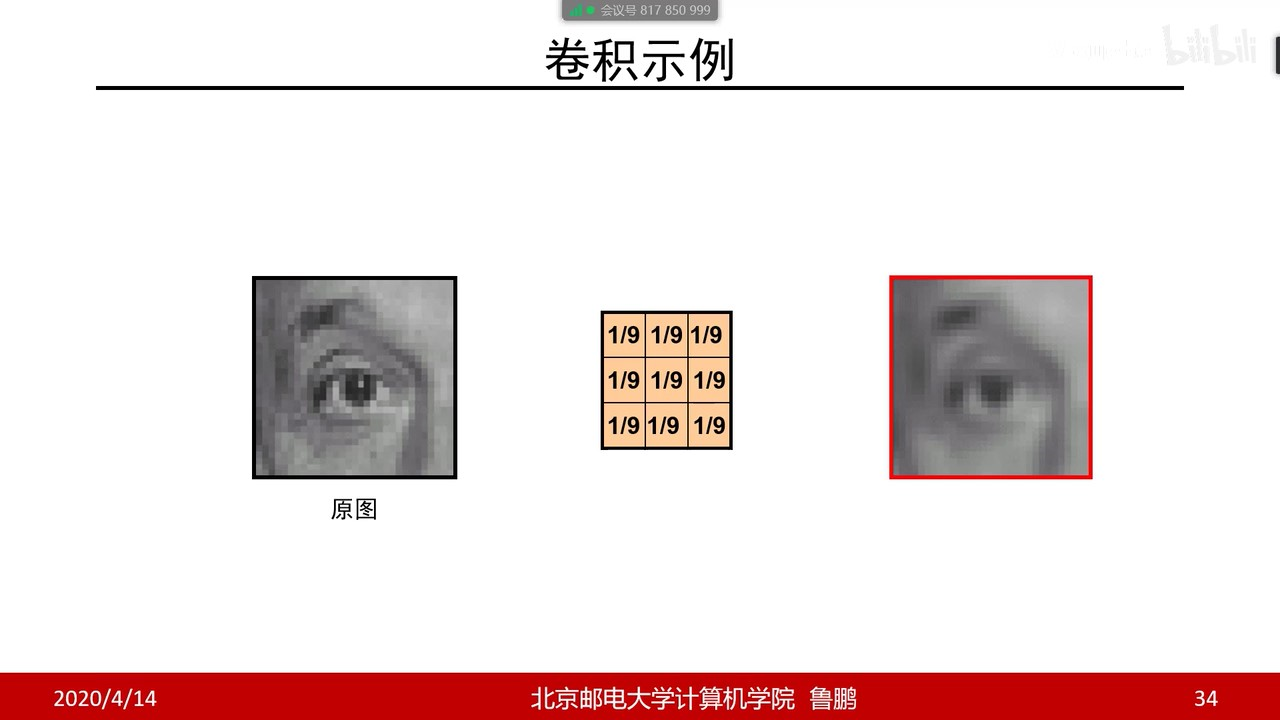
【过一下3】卷积&图像噪音&边缘&纹理
![[Go through 9] Convolution](/img/84/e6d99793aacf10a7b099f60bcaf290.png)
[Go through 9] Convolution
Convert the paper official seal in the form of a photo into an electronic official seal (no need to download ps)
spingboot 容器项目完成CICD部署
![[Go through 4] 09-10_Classic network analysis](/img/f2/e6e71869b8ab014cc1eea0537fc2e7.png)
[Go through 4] 09-10_Classic network analysis
随机推荐
第四讲 反向传播随笔
[Go through 7] Notes from the first section of the fully connected neural network video
Flutter 3.0升级内容,该如何与小程序结合
The difference between the operators and logical operators
AWS 常用服务
通过Flink-Sql将Kafka数据写入HDFS
flink项目开发-配置jar依赖,连接器,类库
基于Flink CDC实现实时数据采集(三)-Function接口实现
对数据排序
如何跟踪网络路由链路&检测网络健康状况
Redux
【过一下8】全连接神经网络 视频 笔记
spark-DataFrame数据插入mysql性能优化
服务网格istio 1.12.x安装
flink项目开发-flink的scala shell命令行交互模式开发
鼠标放上去变成销售效果
第三讲 Gradient Tutorial梯度下降与随机梯度下降
轻松接入Azure AD+Oauth2 实现 SSO
[Go through 8] Fully Connected Neural Network Video Notes
基于Flink CDC实现实时数据采集(一)-接口设计