当前位置:网站首页>JVM 内存结构 详细学习笔记(一)
JVM 内存结构 详细学习笔记(一)
2022-07-07 06:28:00 【白蝶丶】
本篇博客记录个人学习jvm的过程,如有错误,敬请指正
文章目录
一、程序计数器
1.程序计数器介绍
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。总而言之,它是帮助线程记录下一条jvm指令的执行地址行号,如果没有程序计数器,那么jvm都不知道下一条该执行什么指令
此外,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。所以程序计数器是线程私有的
将类反编译后,在终端输入javap -v 类名.class就可以查看二进制字节码文件(Java字节码文件 .class)
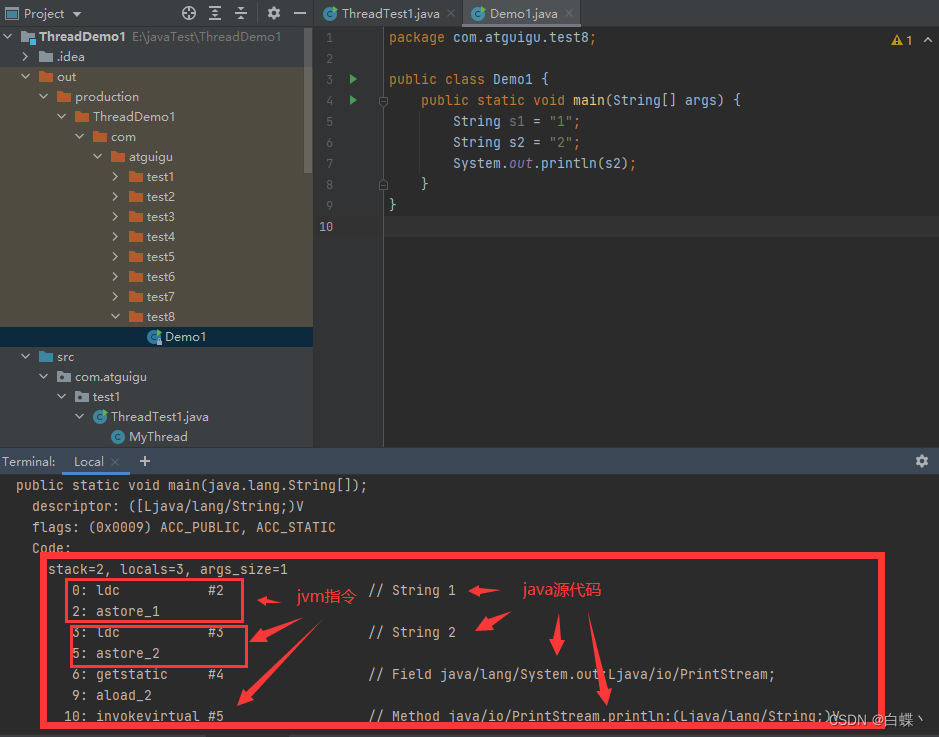
jvm指令前面的数字就是存入程序技术器的顺序
2.程序计数器作用
简而言之,程序技术器有两个作用:
- 通过改变程序计数器来依次读取指令,从而实现代码的流程控制
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了
注意:程序计数器是唯一一个不会出现内存溢出的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡
二、Java 虚拟机栈
1.虚拟机栈简介
与程序技术器相同,Java虚拟机栈也是线程私有的,他的生命周期和线程相同,随着线程的创建而创建,随着线程的死亡而死亡;
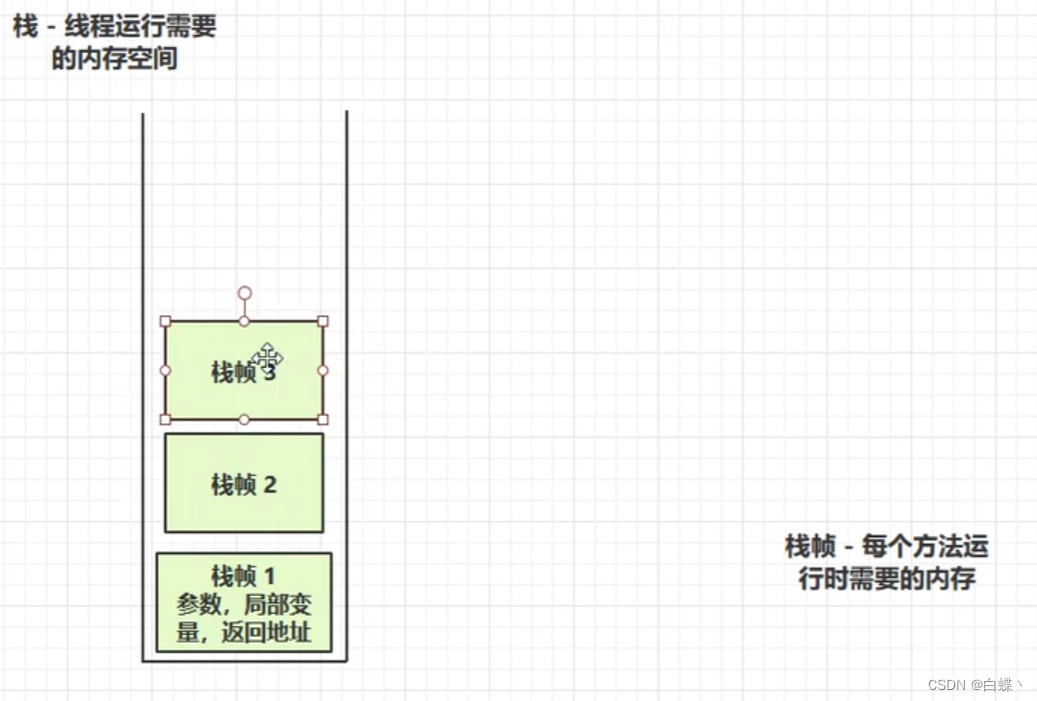
那么它到底是什么呢?**Java虚拟栈由栈帧组成,**在线程运行过程中每个方法所需要的内存就称之为栈帧,方法调用的数据需要通过栈进行传递,每一次方法调用都会有一个对应的栈帧被压入栈中,每一个方法调用结束后,都会有一个栈帧被弹出。
运行如下程序
public class Main {
public static void main(String[] args) {
method1();
}
private static void method1() {
method2(1, 2);
}
private static int method2(int a, int b) {
int c = a + b;
return c;
}
}
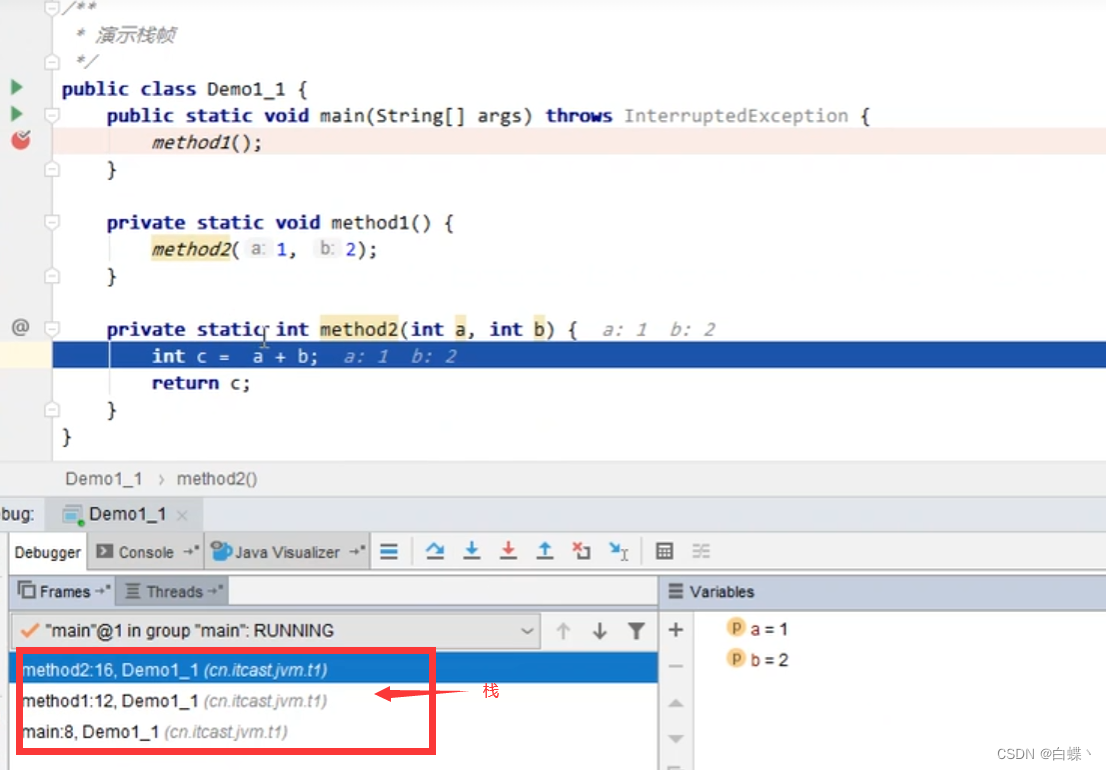
Java 方法有两种返回方式,一种是 return 语句正常返回,一种是抛出异常。不管哪种返回方式,都会导致栈帧被弹出。也就是说, 栈帧随着方法调用而创建,随着方法结束而销毁。无论方法正常完成还是异常完成都算作方法结束。
2.问题辨析
1.垃圾回收是否涉及栈内存?
不会。栈内存是方法调用产生的,方法调用结束后会弹出栈。
2.栈内存分配越大越好吗?
不是。因为物理内存是一定的,栈内存越大,虽然可以支持更多的递归调用,但是可执行的线程数就会越少。
3.方法内的局部变量是否是线程安全的?
- 如果方法内部的变量没有逃离方法的作用访问(变量是局部变量),它是线程安全的
- 如果是局部变量引用了对象,并逃离了方法的访问(比如static修饰的变量,对象作为参数传递,方法有返回值),那就要考虑线程安全问题。
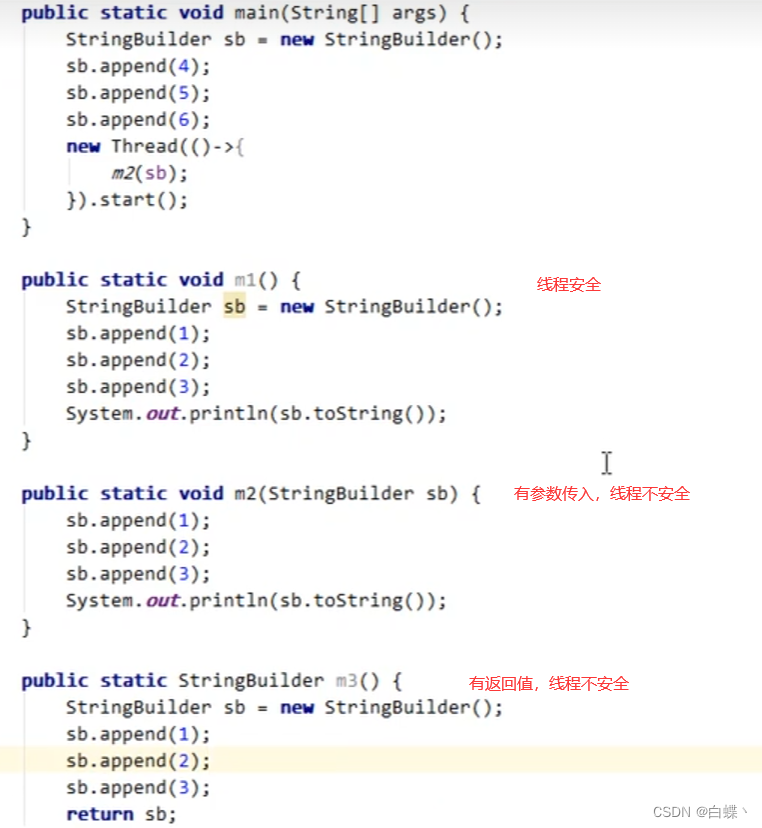
在上面的m2方法中,形参的引用指向堆中的对象,外部可以修改这个对象,从而导致线程不安全,那么如果是基本数据类型作为形参呢?我猜不会造成线程不安全?不过总体来说,当你传递对象时,就会有不安全的情况。
3.栈内存溢出
程序运行时,栈可能会出现两种错误
- StackOverFlowError:栈帧数量过多,例如,在递归过程中没有终止条件的话,就会造成这种问题
- OutOfMemoryError:栈帧内存过大,虚拟机在动态扩展栈时无法申请到足够的内存空间
4.线程运行诊断
案例一:cpu 占用过多 解决方法:Linux 环境下运行某些程序的时候,可能导致 CPU 的占用过高,这时需要定位占用 CPU 过高的线程
top 命令,查看是哪个进程占用 CPU 过高
第一步:使用top命令查看是哪个进程占用 CPU 过高,不过不能精确到哪个具体的线程
第二步:ps H -eo pid(进程id), tid(线程id), %cpu(占用cpu的百分数) | grep 刚才通过top查到的进程号
使用ps命令可以进一步定位是哪个线程引起的cpu占用过高
第三步:jstack 进程id(刚刚查询到的cpu占用过高的进程号)
可以根据第二步查出来的线程id找到有问题的线程,然后结合第三步输出的内容对比,可以找到第二步显示的cpu使用过高的线程以及对应的源代码行号,然后去Java的源代码中查找就行,注意jstack查找出的线程id是16进制的,需要转换
5.本地方法栈
和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。
一些带有 native 关键字的方法就是需要 JAVA 去调用本地的C或者C++方法,因为 JAVA 有时候没法直接和操作系统底层交互,所以需要用到本地方法栈,服务于带 native 关键字的方法。
三、堆
1.简介
此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
特点:
- 它是线程共享的,堆内存中的对象都要考虑线程安全问题
- 具有垃圾回收机制
堆这里最容易出现的就是 OutOfMemoryError 错误,并且出现这种错误之后的表现形式还会有几种,比如:
- java.lang.OutOfMemoryError: GC Overhead Limit Exceeded : 当 JVM 花太多时间执行垃圾回收并且只能回收很少的堆空间时,就会发生此错误。
- java.lang.OutOfMemoryError: Java heap space :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发此错误。(和配置的最大堆内存有关,且受制于物理内存大小。最大堆内存可通过-Xmx参数配置,若没有特别配置,将会使用默认值)
2.堆内存诊断
对于堆内存诊断可以使用以下工具
- jps 工具 查看当前系统中有哪些 java 进程
- jmap 工具 查看堆内存占用情况 jmap - heap 进程id
- jconsole 工具 图形界面的,多功能的监测工具,可以连续监测,jdk自带的;
- jvisualvm 工具
在terminal中输入jconsole就可以打开jconsole工具
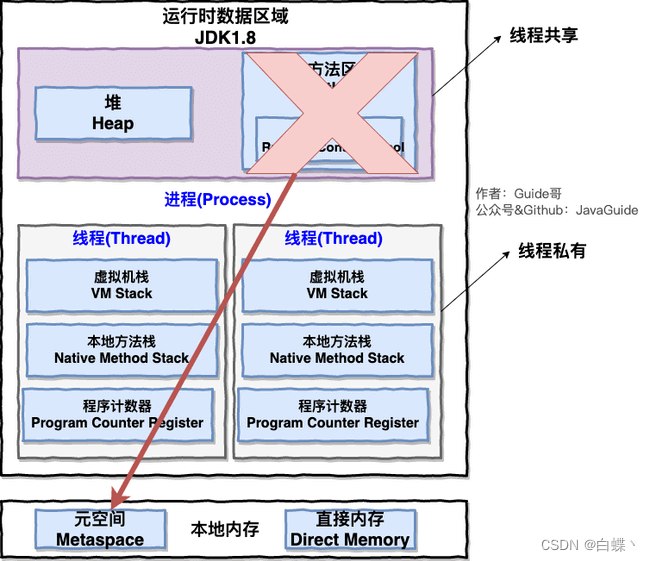
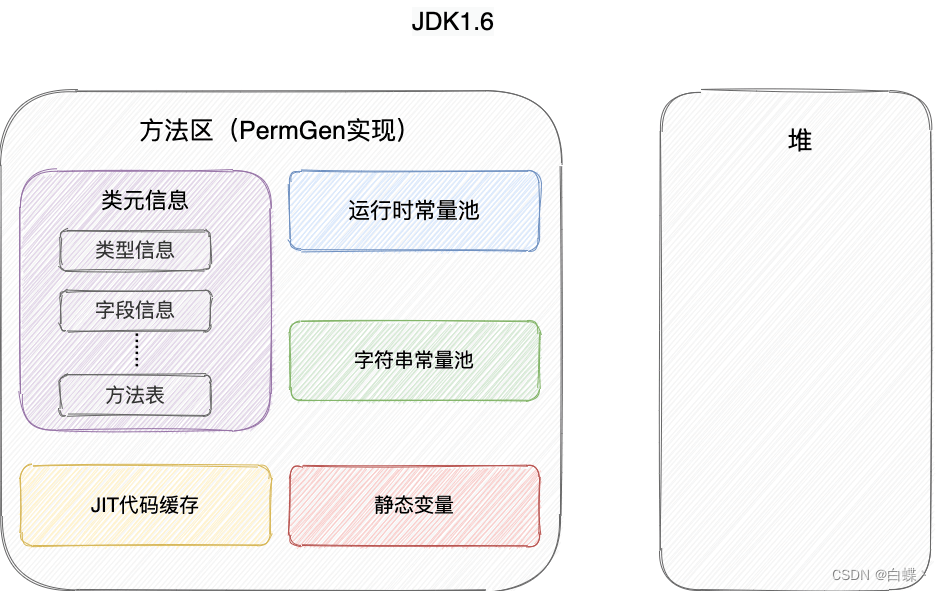
四、方法区
1.简介
方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域
当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。方法区会存储已被虚拟机加载的 类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
方法区看作是一块独立于Java堆的内存空间
- 方法区(Method Area) 与Java堆一样,是各个线程共享的内存区域
- 方法区在JVM启动的时候被创建,并且它的实际的物理内存空间中和Java堆区一样都可以是不连续的。
- 方法区的大小,跟堆空间一样,可以选择固定大小或者可扩展。.
- 方法区的大小决定了系统可以保存多少个类,如果系统定义了太多的类,导致方法区溢出,虚拟机同样会抛出内存溢出错误: java.lang .OutofMemoryError:PermGenspace(1.8之前)或者java.lang.OutOfMemoryError: Metaspace(1.8之后),关闭JVM就会释放这个区域的内存。例如:加载大量的第三方的jar包; Tomcat 部署的工程过多(30-50个) ;大量动态的生成反射类都有可能造成内存溢出
下图的常量池是指运行时常量池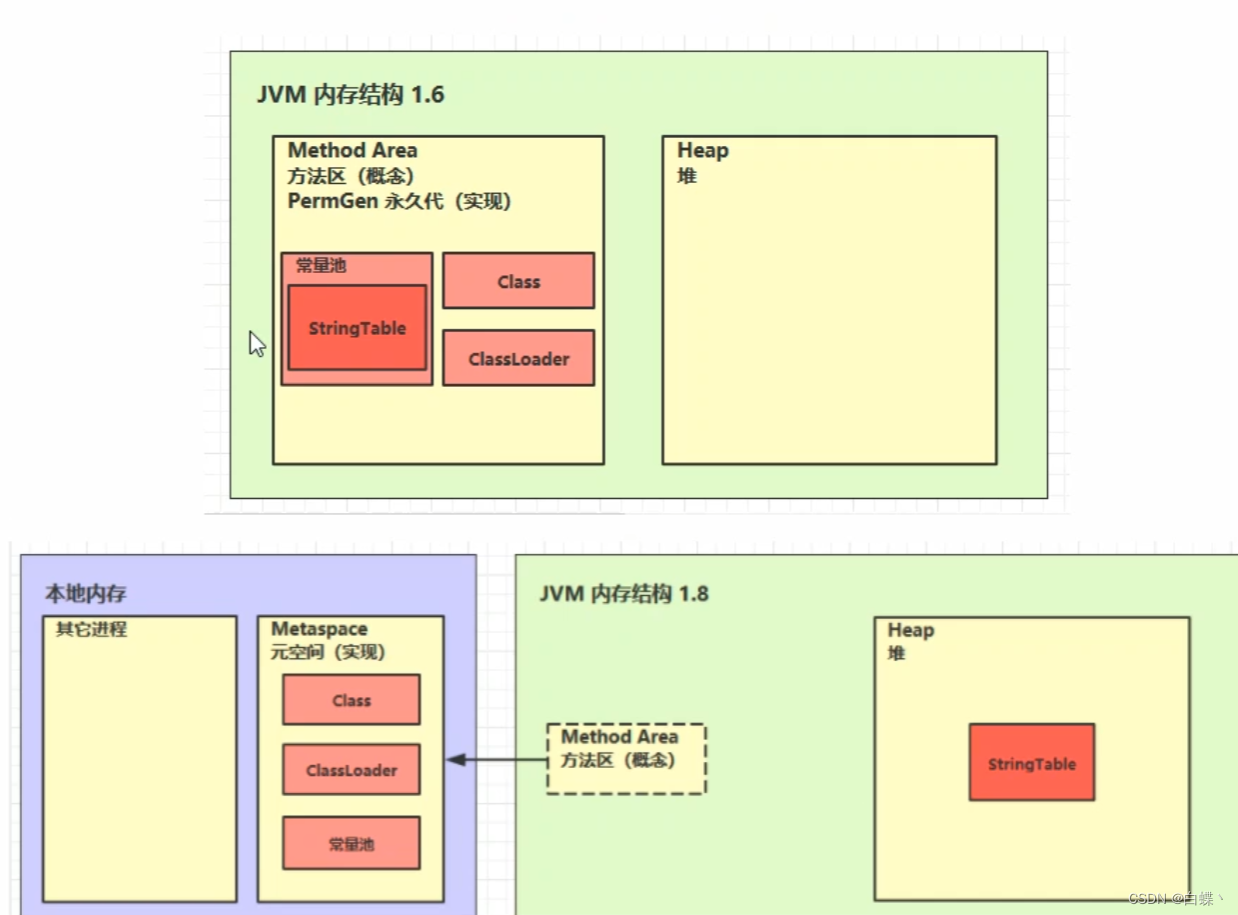
方法区和永久代以及元空间是什么关系呢? 方法区和永久代以及元空间的关系很像 Java 中接口和类的关系,类实现了接口,这里的类就可以看作是永久代和元空间,接口可以看作是方法区,也就是说永久代以及元空间是 HotSpot 虚拟机对虚拟机规范中方法区的两种实现方式。并且,永久代是 JDK 1.8 之前的方法区实现,JDK 1.8 及以后方法区的实现变成了元空间。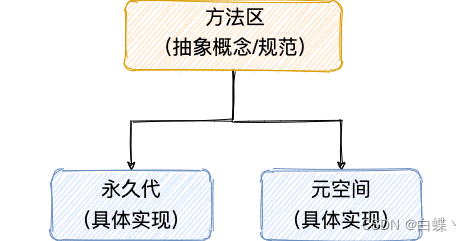
2.运行时常量池
首先常量池存在于反编译后的.class文件中,这个.class文件包含类基本信息,常量池,类方法定义,虚拟机指令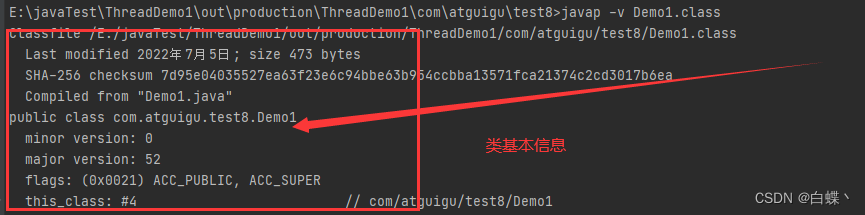
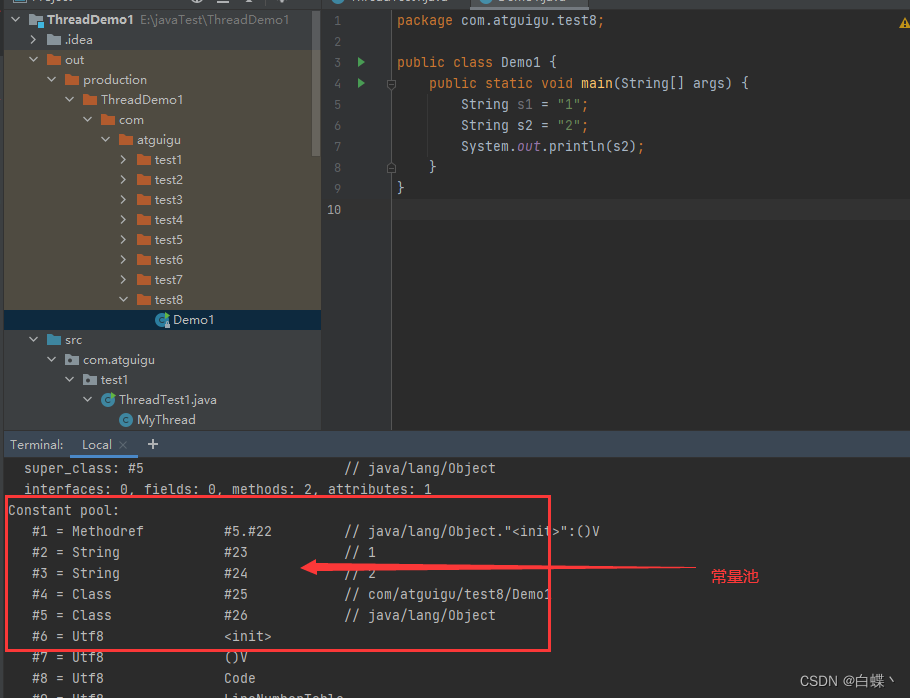
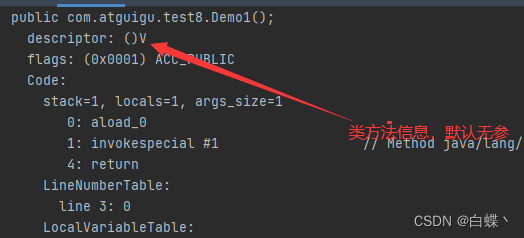
常量池的作用是为虚拟机解释这些指令的时候给它查询使用的
常量池:就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量信息;
运行时常量池:常量池是 *.class 文件中的,当该类被加载以后,它的常量池信息就会放入运行时常量池,并把里面的符号(比如#1)地址变为真实地址;常量池表会在类加载后存放到方法区的运行时常量池中。
3.字符串常量池(StringTable)
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
首先我们要了解 String str = “”这种形式,是直接指向常量池中
而String str = new String(“”) 则存储于堆中,但存储的是指向常量池的引用
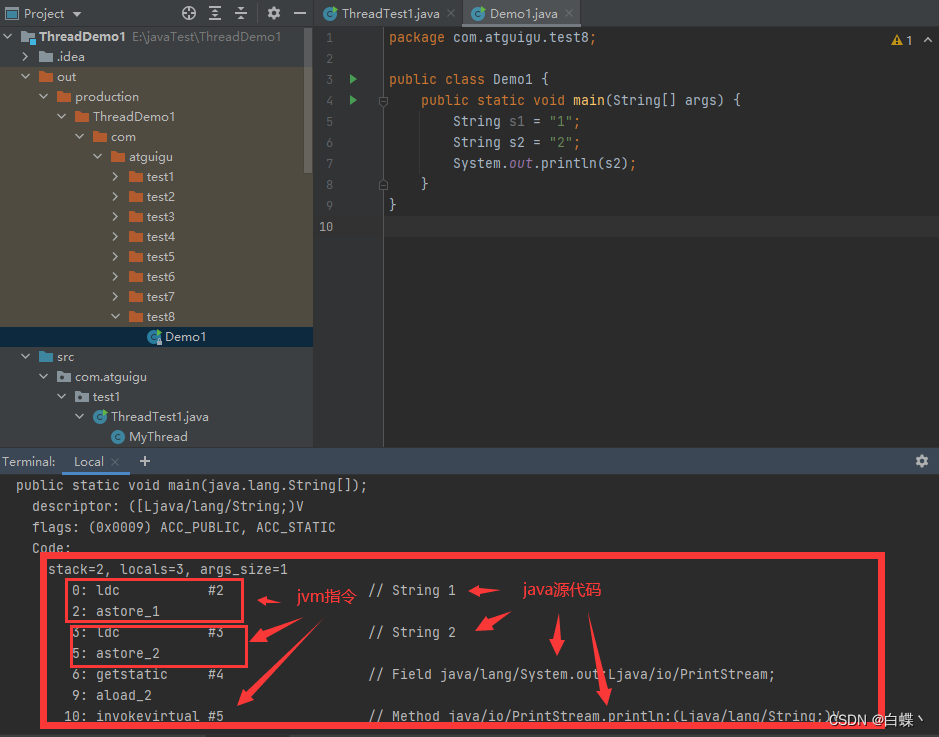
下面做个例子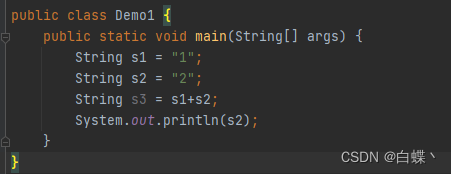
对上面的代码进行编译后查看字节码文件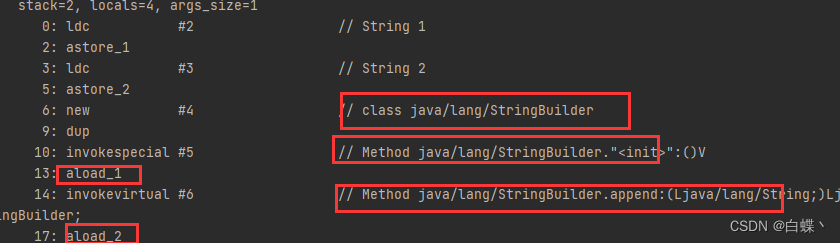
可以看到它会创建一个StringBuffer对象,将是s1和s2拼接起来,这个StringBuffer当然是放堆中的,那么如下图,我们用==比较时,是比较的地址,他们当然不相同,一个在字符串常量池中,一个在堆中;不过jdk1.7后字符串常量池也在堆中,可能是在堆中的不同空间,才导致下图的不同?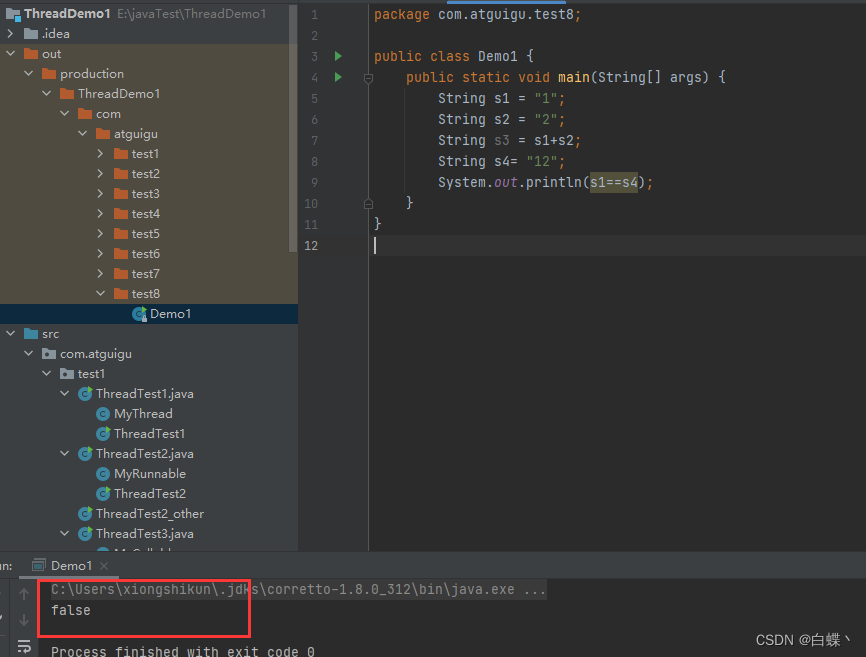
思考:这两个的结果为什么不同?
public static void main(String[] args) {
String a=new String("ab")+new String("c");
a.intern();
String b="abc";
System.out.println(a==b);//true
}
public static void main(String[] args) {
String a=new String("ab")+new String("c");
String b="abc";
a.intern();
System.out.println(a==b);//false
}
答:intern()方法,当调用 intern方法时,如果常量池已经包含一个等于此String对象的字符串,则返回池中的字符串。否则,将intern返回的引用指向当前字符串
第一个程序中,因为常量池中没有“abc”所以,会在常量池中创建“abc”,并将a指向它
第二个程序中,因为常量池中已经有了“abc”,在调用时,是有返回值的,但没有将a指向常量池中,所以a还是指向的堆中,最终结果不相等
4.StringTable的位置
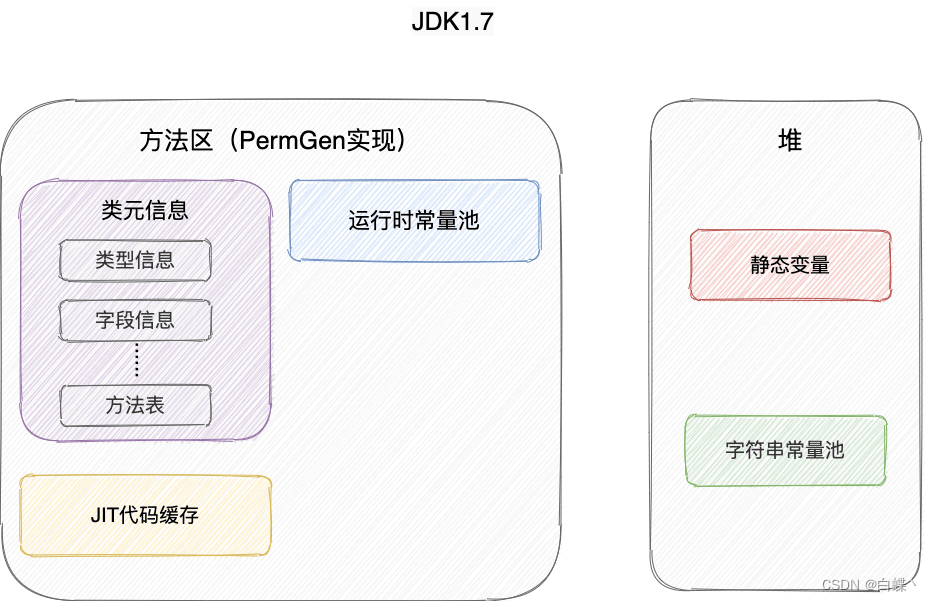
JDK1.7 之前,字符串常量池存放在永久代。JDK1.7 字符串常量池和静态变量从永久代移动了 Java 堆中。
JDK 1.7 为什么要将字符串常量池移动到堆中?
主要是因为永久代(方法区实现)的 GC回收效率太低,只有在整堆收集 (Full GC)的时候才会被执行 GC。Java 程序中通常会有大量的被创建的字符串等待回收,将字符串常量池放到堆中,能够更高效及时地回收字符串内存。
5.StringTable的性能调优
1.由于StringTable是由HashTable实现的,所以可以适当增加HashTable桶的个数,来减少字符串放入串池所需要的时间(减小哈希冲突的概率)
-XX:StringTableSize=桶个数(最少设置为 1009 以上,否则会抛异常)
2.考虑是否需要将字符串对象入池(可以通过 intern 方法减少重复入池(从而减少数据对内存的大量占用))
五、直接内存
1.直接内存简介
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。
未使用直接内存,会导致经历两遍缓冲区,效率不高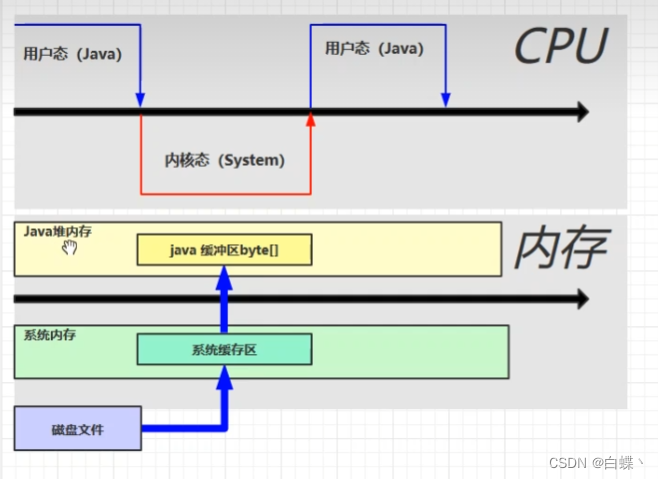
使用直接内存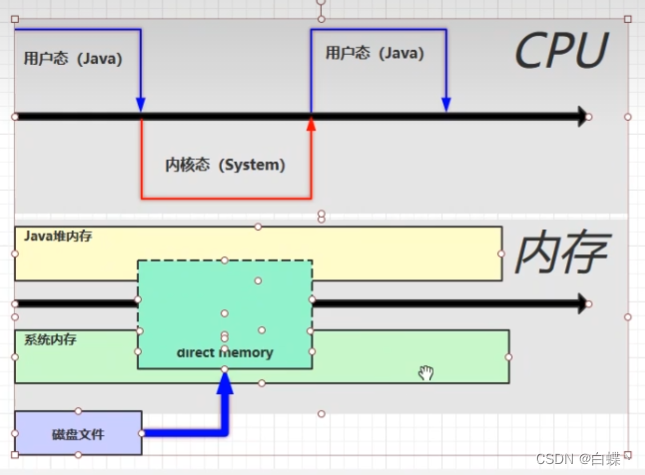
边栏推荐
- Count the number of words in the string c language
- Chaosblade: introduction to chaos Engineering (I)
- 面板显示技术:LCD与OLED
- 数据在内存中的存储
- Enterprise manager cannot connect to the database instance
- 9c09730c0eea36d495c3ff6efe3708d8
- Interview question: general layout and wiring principles of high-speed PCB
- H3C vxlan configuration
- LED模拟与数字调光
- Lenovo hybrid cloud Lenovo xcloud: 4 major product lines +it service portal
猜你喜欢
2022-06-30 unity core 8 - model import
Unityshader introduction essentials personal summary -- Basic chapter (I)

The longest ascending subsequence model acwing 1017 Strange thief Kidd's glider

Three updates to build applications for different types of devices | 2022 i/o key review
External interrupt to realize key experiment

LeetCode 715. Range module
C language for calculating the product of two matrices
Recommended by Alibaba P8, the test coverage tool - Jacobo is very practical

C语言指针(下篇)

Hard core sharing: a common toolkit for hardware engineers
随机推荐
Database storage - table partition
Screen automatically generates database documents
STM32的时钟系统
Oracle makes it clear at one time that a field with multiple separators will be split into multiple rows, and then multiple rows and columns. Multiple separators will be split into multiple rows, and
cmake命令行使用
【ChaosBlade:节点 CPU 负载、节点网络延迟、节点网络丢包、节点域名访问异常】
Synchronized underlying principle, volatile keyword analysis
Routing information protocol rip
Original collection of hardware bear (updated on May 2022)
C语言指针(中篇)
Un salaire annuel de 50 W Ali P8 vous montrera comment passer du test
channel. Detailed explanation of queuedeclare parameters
xray的简单使用
Goldbach conjecture C language
Redis fault handling "can't save in background: fork: cannot allocate memory“
H3C vxlan configuration
Data analysis methodology and previous experience summary 2 [notes dry goods]
实现自定义内存分配器
Esp32-ulp coprocessor low power mode RTC GPIO interrupt wake up
Mountaineering team (DFS)