当前位置:网站首页>数据在内存中的存储
数据在内存中的存储
2022-07-07 06:26:00 【一只大喵咪1201】
作者:一只大喵咪1201
专栏:《C语言学习》
格言:你只管努力,剩下的交给时间!

文章目录
描述
我们在使用C语言的时候,会使用到一些数据,这些数据有很多的类型,每一个数据都是存在内存里的,就像是我们每一个人都有自己居住的房子一样,数据在内存中也是有居住的地方的,而且还有各自的存储方式,下面本喵先来介绍一部分数据的存储。
数据类型
数据是有类型的,它们可以分为几大类。
1️⃣整型家族
- char类型:
我们一直的印象中char类型就是字符类型,这类型的变量中放的是字符,例如’a’,’ ‘,‘b’,‘i’,‘g’,’ ',‘c’,‘a’,‘t’。包括字母空格等,一个字符占一个字节大小。
但是这些字符在内存中的样子就不是字符本来的面目了,它是以ASCII码值的方式存放,ASCII码值从0到127代表不同的字符,所以char类型也是整型。
它分为:
char
unsigned char
signed char
char类型是比较特殊的,在C语言标志里没有规定char是有符号的还是无符号的,不同的编译器有不同的标准,本喵使用的VS2019的编译器里char就是有符号类型的。
- short类型:
unsigned short
signed short
short类型只有无符号和有符号类型,short属于有符号类型的,大小是2个字节。
- int类型:
unsigned int
signed int
int类型只有无符号和有符号类型,int属于有符号类型的,大小是4个字节。
- long类型:
unsigned long
signed long
long类型只有无符号和有符号类型,long属于有符号类型的,大小是4或者8个字节。
C语言标准规定,long>=int就行,所以它在32位平台是4个字节,在64位平台是8个字节大小。
- long long类型:
这个类型是C99标准才有的,大小是8个字节,一般是用不到的。
2️⃣浮点家族
- float类型:
叫做单精度浮点型数据,它的精度比较低,默认的输出是小数点后六位。
- double类型:
叫做双精度浮点型数据,它的精度比较高,默认的输出也是小数点后六位。在后面本喵会讲解为什么它的精度高。
只要你的数据是小数,就得使用这俩种中的一种。
3️⃣构造类型
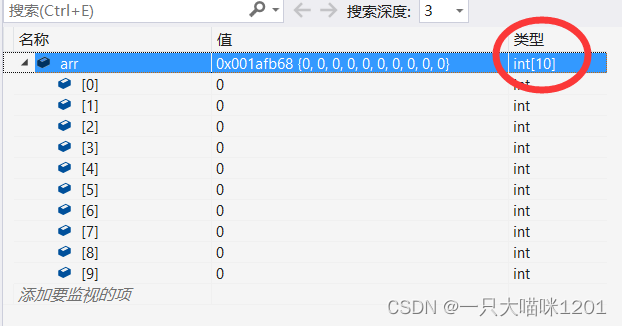
- 数组类型
这是一个有10个元素的数组,它的类型就是int[10],也就是数组去掉数组名字,剩下的就是该数组的类型,所以数组类型是多样的,不同元素类型,不同元素个数,数组类型多种多样,它的类型是由用户决定的,所以它是一种构造类型。- 结构体类型 stuct
- 联合体类型 union
- 枚举类型 enum
这些都是构造类型,它们的类型多样,用户想要什么样的类型就可以构造什么样的类型。后面三种类型在以后会有专门的专题来讲解。
4️⃣指针类型
- int *pi;
- char *pc;
- float* pf;
- void* pv;
指针在后面也会有专题来详细讲解。
5️⃣空类型
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
在这里本喵先仅介绍整型数据和浮点型数据在内存中的存储。
整型数据的存储
首先得知道,一个数有很多种表示方式,有
10进制表示(最常用)
8进制表示
16进制表示
2进制表示
…
计算机是由很多的电路元件组成,电路状态一般由高电平或者低电平俩种稳定且可以或许转换的状态来表示,所以将0看作是低电平,1看作是高电平。
所以,内存中存放的数据都是0或者1,也就是按2进制的方式来存储数据。
而2进制又有三种表现形式:
原码
反码
补码
上代码:
#include <stdio.h>
int main()
{
int a = 10;
int b = -10;
return 0;
}
这是我们创建的两个整型,分别是10和-10。
接下来本喵说一下它们的表示规则:
因为是int类型,大小是4个字节,所以转换成2进制或是由32个0和1组成。
正数10
原码:00000000000000000000000000001010
反码:00000000000000000000000000001010
补码:00000000000000000000000000001010
以上是正数的原码,反码,补码,它都一样,最高位0代表符号为,其余31个数组是数值位。
负数-10
原码:10000000000000000000000000001010
反码:111111111111111111111111111111110101
补码:111111111111111111111111111111110110
以上是负数的原码,反码,补码,它们是不同的,需要计算。正常表示出原码后,反码是最高位也就是符号为保持不变,其他位按位取反,补码就是反码加1。
那么这些0和1是怎么在内存中储存的呢?
为了方便看,我们将这俩个数写成16进制的形式,只是形式变了,但是它们的本质还是2进制。
正数10
原码:00 00 00 0a
反码:00 00 00 0a
补码:00 00 00 0a
将10按照上面的二进制写成十六进制。
负数-10
原码:00 00 00 0a
反码:ff ff ff f5
补码:ff ff ff f6
将-10按照上面的二进制写成十六进制。
接下来我们调试一下,观察下内存中这俩个数是什么样子。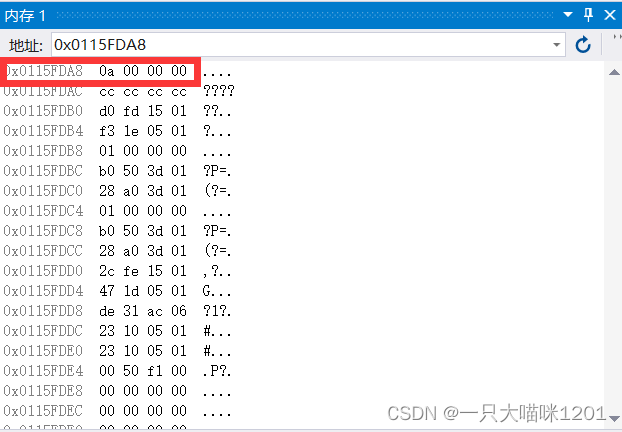
这是a也就是正数10在内存中的样子,它是0a 00 00 00,与上面分析的10的原码,反码,补码相同,大小是4个字节(先忽略它是倒着存放这个问题)。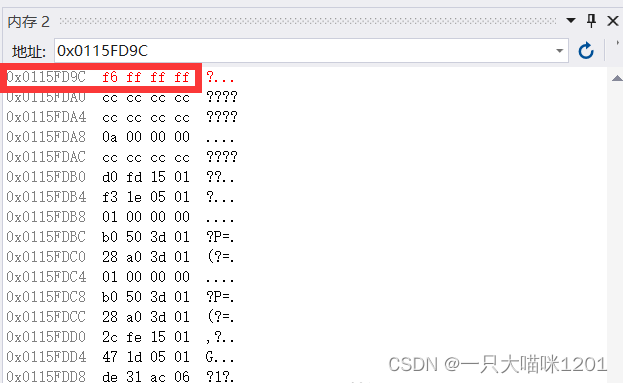
这是b也就是负数-10在内存中的样子,它是f6 ff ff ff,与上面分析的-10的的补码是相同的,大小是4个字节(先忽略它是倒着存放这个问题)。
通过观察正数10和负数-10在内存中的样子,我们发现内存中的样子是这俩个数的补码。
所以得出结论,整型数据在内存中是以补码的方式存放的。上面谈到的整个整型家族都是以这种方式来储存放数据的。
是否会有这样一个疑问,内存中存放的为什么不是原码呢?原码多方便使用啊,拿出来就能用,如果是负数都不需要转换,这样确实是方便了用户,但是计算机硬件就会更加的复杂,存放的补码有几个原因:
- 补码可以将数据的符号域与数值域进行统一处理。也就是在计算的过程中符号位也是直接参与运算的,不用把符号位和数值位区分开来。
- CPU只有加法器。也就是说,CPU只能进行加法的运算,不能进行减法的运用,当俩个数想减时,CPU将其看作是一个正数的补码和一个负数的补码进行相加运算的,实质就是俩个数相减。
- 原码与补码的转换逻辑是相同的,不需要额外的硬件电路。原码转换成补码上面已经说过了,补码转换成原码的逻辑也是一样的,因为补码的补码就是原码。
在调试中,有没有发现一个奇怪的现象?
这是正数10存放在内存中的样子,10的补码是00 00 00 0a,图中框住的部分是4个字节大小,也就是1个int类型,它的地址是int类型中第一个字节的地址,所以10这个int类型所占空间的地址及里面的内容是
0x0115FDA8 0a
0x0115FDA9 00
0x0115FDAA 00
0x0115FDAB 00
啊?
我们发现数据是倒着放的,不是按照00 00 00 0a的顺序放在这4个地址中的,这就涉及到了下一个内容,大小端存储。
大(小)端字节序存储方式
我们先来介绍下它的概念
大端字节序储存:是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中。
小端字节序存储:是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
而正数10表示成十六进制后00 00 00 0a中,最低位字节是0a,最左边便的00是最高位字节。
以图的形式表示出来就是这样的,很显然,这是一个小端字节序储存方式。所以我们看到数据在内存中的样子是倒着的。
大(小)端字节序储存方式中,字节序是关键,它是以字节为单位来存储的,所以不只是整型,浮点型也是按照这样的方式储存的,也是以1个字节为单位来存放。
既然它只是一种顺序方式,那么也可以不按照这俩个顺序来存放,比如按照
先存最高位,再存最低位,再存次高位,在存次低位的顺序来存放,只要在使用的时候再按照这个存放顺序取出来就可以。但是正常人都不会这样放的,只会选择大端或者小端其中之一的方式来存放。
到底是采用大端字节序存储方式还是使用小端字节序存储方式取决于编译器,本喵使用的VS2019编译器是使用的小端存储方式,相keil5采用的就是大端字节序存储方式。
有关整型存储一些例子(可略过)
示例1:
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}
上面的例子输出结果是什么?你的第一反应是不是-128呢?如果是,恭喜你,掉坑里了
下面我们来分析一下。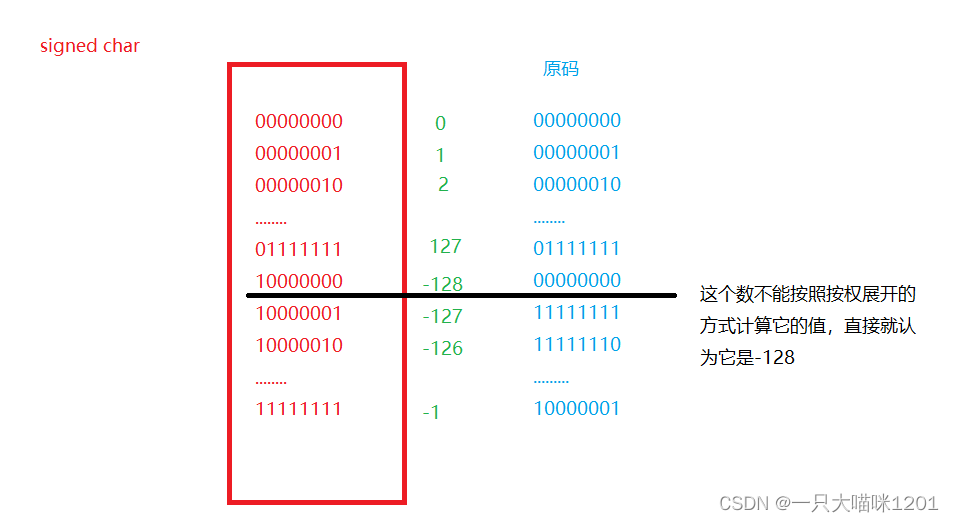
这是char类型,也就是signed char类型中可以储存的数值范围,大小是-128到127。
首先我们给a赋值的是一个int类型-128,它的
原码:10000000000000000000000010000000
反码:111111111111111111111111101111111
补码:111111111111111111111111110000000
因为要将这个4个字节大小的int类型数据的补码放在1个字节大小的char类型中,所以要发生截断,从第位开始截断,所以a在内存中的样子是
补码:10000000
而要打印出来的数据类型是%u,是unsigned int类型的数据,所以内存中的a会发生整型提升,提升是根据符号位来提升的,此时内存中的a的符号位是1,所以提升后的结果是
补码:11111111111111111111111110000000
因为它是unsigned int类型的,是无符号的整型,此时最高位代表的就不是符号位,而是数值位,所以此时补码中的所以0和1都是数值位,所以结果转换成十进制后是4,294,967,168。

可以看到,运行的结果与我们分析的一致。
示例2:
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n", a);
return 0;
}
这个的结果是什么?是128吗?我们来分析下。
int类型 128的
原码:00000000000000000000000010000000
反码:00000000000000000000000010000000
补码:00000000000000000000000010000000
因为是正数,所以原码,反码,补码相同。
放在char类型的a变量中发生截断后
补码:10000000
打印的是unsgined int类型,发生整型提升后
补码:11111111111111111111111110000000
全部当作数值位后的结果是4,294,967,168。
可以看到,在发生截断以后,内存中的数据与示例1是一样的,所以最后的结果也一样。
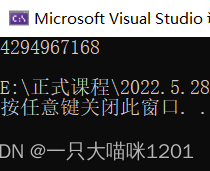
这是它的结果,果然与示例1的一样。
示例3:
#include <stdio.h>
int main()
{
int i = -20;
unsigned int j = 10;
printf("%d\n", i + j);
return 0;
}
这个代码输出的结果是什么?是不是不敢说是-10了,被坑 怕了?哈哈,结果就是-10。
我们来分析一下
int类型i = -20的
原码:10000000000000000000000000010100
反码:11111111111111111111111111101011
补码:11111111111111111111111111101100
unsigned int类型j = 10的
原码:00000000000000000000000000001010
反码:00000000000000000000000000001010
补码:00000000000000000000000000001010
int类型与unsigned int类型相加时会发生算术转换,int类型转为位unsigned int类型,转换后,int类型也就是i中的最高位不再是符号位,而是数值位。相加后的
补码:11111111111111111111111111110110
而打印的是%d了些也就是int类型,所以需要计算出内存中补码的原码
补码:11111111111111111111111111110110
反码:10000000000000000000000000001001
原码:10000000000000000000000000001010
转换成十进制后结果是-10。

我们可以看到,结果就是-10。
示例4:
#include <stdio.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}
这个代码的结果是什么?是从9到0吗?我们来分析一下
首先肯定会打印从9到0,当i是0的时候,它的
补码:00000000000000000000000000000000
️
除了循环后0还会再减1,减1后的
补码:11111111111111111111111111111111
️
因为i的类型是unsgined int类型,没有符号位,最高位也看作是数值位,所以这减1后的结果并不是一个负数,而是4,294,967,295这么大一个数。将这个数逐渐减一再打印,当减到0时,再减1就又变成了这么大一个数,所以它是一个死循环。
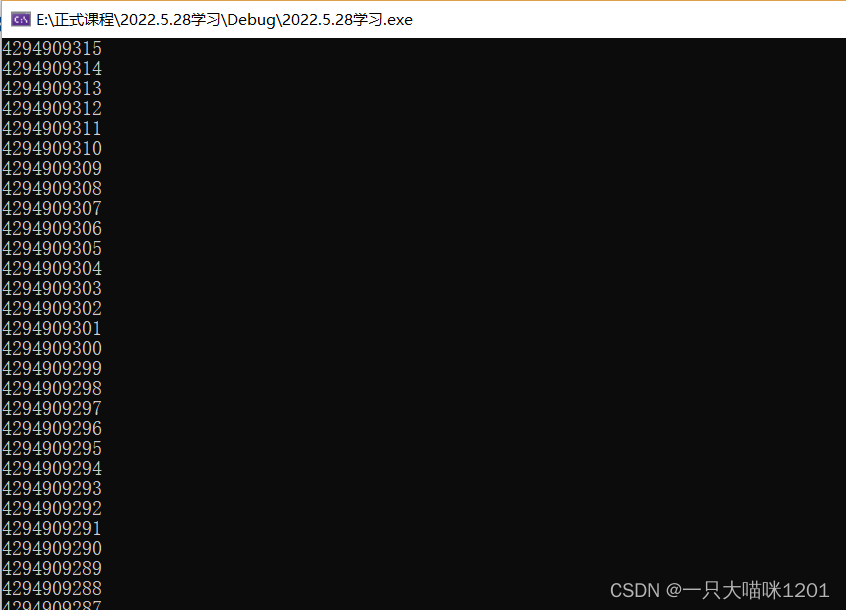
可以看到,数字在不停的减小。
示例5:
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
这个代码的结果是什么呢?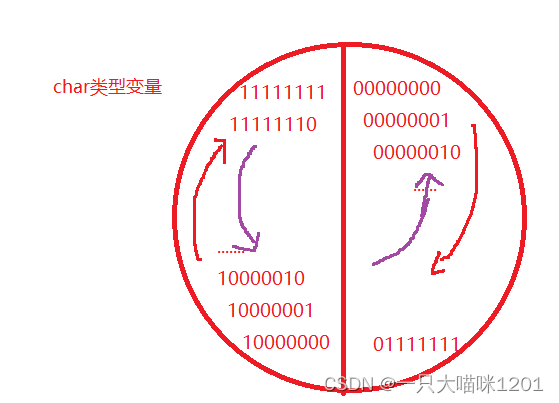
这个圆盘模仿的是一个char类型的变量,当按红色箭头顺实质旋转时,就是从0开始加1,当加到01111111也就是127的时候,再加1就变成了10000000也就是-128了,再逐渐加1就变成了-1,再加1就又变成了0。因为char类型是数值范围就是-128到127,怎么着都不会出了这个范围。
当按紫色箭头逆时针旋转时,也就是减1时
从11111111也就是-1开始减1,当减到10000000也就是-128的时候,再减1就变成了0111111也就是127了,再继续减1就会减到00000000也就是0。
️
strlen()函数统计的是‘\0’以前的字符个数,而’\0’的ASCII码值就是0,所以数值a中的值以ASCII码值的形式表示就是从-1到-128,再从127到0,一共256个字符,又因为不统计0也就是‘\0’,所以共有255个字符,所以该字符串的长度就是255。

结果就是255。
示例6:
#include <stdio.h>
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
这个代码的结果又是什么呢?
上面分析了好几个例子,相小伙伴们一眼就看出了答案
答案是死循环打印
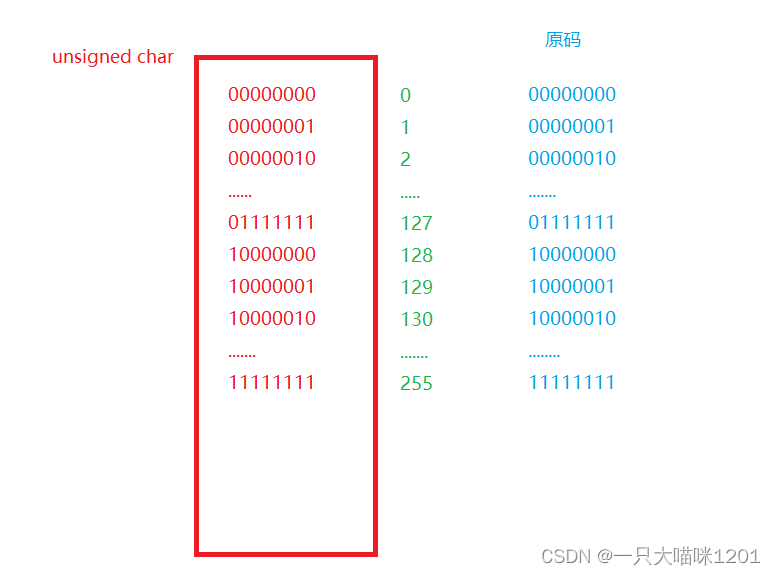
这是unsigned char类型的数据存放,数值范围是0到255。
所以上面代码首先会循环0-255共266次,也就是打印266次,当i变成255以后,再加1就会溢出,又会变成00000000也就是0,又重新开始一轮的打印,如此往复就成了死循环打印。
示例7设计一个小程序来判断当前机器的字节序。
#include <stdio.h>
int check_sys(int a)
{
char* p = (char*)&a;//取变量a的地址,并且强制转换为char*类型的指针变量
return *p;
}
int main()
{
int a = 1;
int ret = check_sys(a);
if (ret)
printf("小端\n");
else
printf("大端\n");
return 0;
}
思路就是判断int类型的4个字节的空间里,最低地址中的数是什么。如果是1,说明存储方式就是01 00 00 00采用的是小端存储方式,如果是0,说明储存方式就是00 00 00 01采用的是大端存储方式。
浮点型数据的存储
先抛出一个问题:
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}
这个代码的结果是什么呢?可以先尝试着猜一下。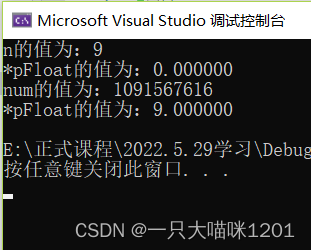
结果是这个,意外吧?接下来本喵讲讲它位什么会出现这样一个结果。
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。E表示小数点移动了几位,向左移动是正数,向又移动是负数。
接下来举个例子来说明一下怎么求S,E,M。
十进制数:101.5
转为为二进制后:1100101.1
表示成科学计数法后:1.1001011
按照IEEE754标准表示后:(-1)0 * 1.1001011 * 26
对照公式,S=0,M=1.1001011,E=6。
求出的S,E,M有什么用呢?
用处非常的大,因为浮点数在内存中存放的就是S,E,M三个值。
float类型数据的存储
float类型的浮点数是单精度浮点数,它大小是4个字节,也就是32个二进制位。下面的图是它的存储模型。
我们在上面将浮点数101.5的S,E,M求出以后放到了内存里。
- 储存S:最高位存的是符号位,也就是存的S的值。如101.5中,存放在最高位的S是0。
- 储存M:M的值存放在低23位中,由于任何小数的数值部分都可以表示成1.xxxxxx。
所以存放的时候只存放M中的小数部分,也就是去掉了1,只存放小数点后面的二进制数值。
按照从左到右是顺序存放,23位中没有数值的位用0来补充,相当于在小数的后面加0,并不影响小数值的大小。
如101.5中存放在低23位中的值是10010110000000000000000
- 储存E:E的储存就比较复杂,float类型的数据分给E的部分只有8位,如果都是正数,它的取值范围就是0到255,但是我们知道,E是有负数的情况的。
例如:float类型的数据0.5。
转化位二进制后:0.1
表示成科学计数法后:1.0
按照IEEE754标准表示后:(-1)0 * 1.0 *2-1
对照公式:S=0,E=-1,M=1.0
这里已经有了符号位(最高位的S),所以再用8存放E的8位中的最高位表示负数显然不是很合理。
所以,找了一个中间数127。
在存放E的时候,将E的值加上127后再存放都S后面的8位中。
如101.5中的最E是6,加127后的结果是133,那么这八位中存放的就是133的二进制形式。
所以最高位后的8位中存放的是10000101。
所以101.5在内存中的样子就是下图中的样子
转化成16进制的形式
由于本喵使用的VS2019编译器是采用小端字节序存储方式的,所以在内存中的样子应该是
我们来调试一下,看看是不是这样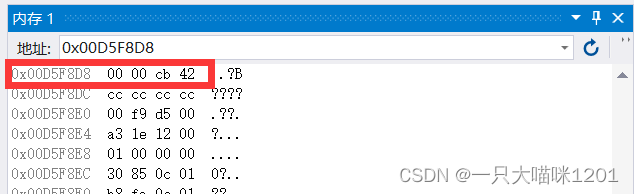
可以看到,确实是这样的。
double类型数据的存储
double类型的浮点数是双精度浮点数,它大小是8个字节,也就是64个二进制位。下面的图是它的存储模型。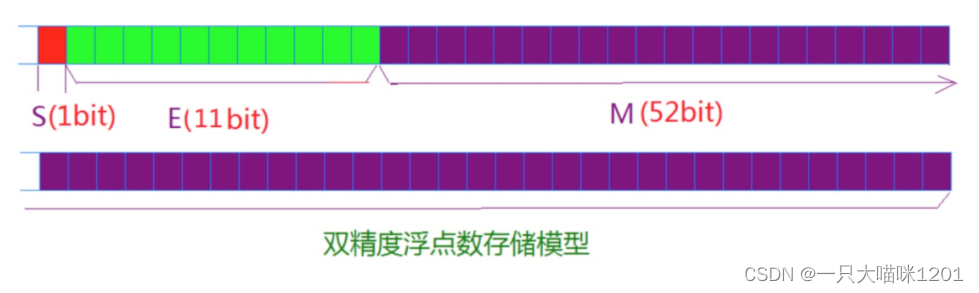
同样,我们将101.5设置成double类型的浮点数,也是使用IEEE754标准将上面求出的S,E,M放在内存里。
- 储存S:与float类型一样,S存在最高位,是符号位。如101.5,最高位的S是0。
- 储存M:与float类型一样,将整数部分去掉后,只将小数部分存储,但是double类型提供了低52位存放M的小数部分,没有用的位同样用0补充。如101.5中存放在低52位中的值是10010110000000000000000000000000000000000000000000000000。
- 储存E:与float类型一样,同样需要加一个中间值,但是double类型的中间值是1023,而且最高位后的11位用来存放相加后的值。如101.5中的E等于6+1023=1029,所以最高位后面的11位存放的就是1029,转化为二进制后是10000000101。
所以101.5在内存中的样子就是下图中的样子
转化成16进制的形式

由于VS2019使用的小端字节序存储方式,所以它在内存中的样子应该是
我们来调试一下,看看是不是这样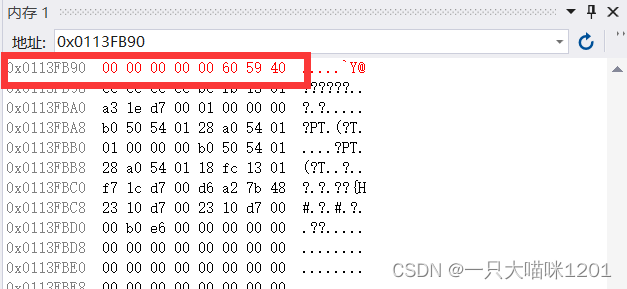
可以看到,和我们分析的一样。
浮点型数据的取出
在我们创建好一个浮点型数据后,它会按照上面本喵所讲的规则存放到的内存中。既然存好了,它就有被使用的时候,使用时就会内存中表示浮点数的二进制数取出来,还原成一个浮点数。取出来的规则并不仅仅是按照放的规则反过来那样,取出来时有三种情况。
E不全为0或者1
回忆一下,E代表的是小数点左移或者右移的位数在加上一个中间站127或者1023。这种情况下,取出的规则就是与放进去规则相反。
- S是符号位,存在最高位,正常取出。
- 再从接下来的8位或者11位中取出的值再减去加上去的127或者1023,得到的结果就是E的值。
- 将低23位或者52位中的值取出来,当作小数部分,整数部分编译器自动补1,得到的结果就是1.xxxxxx
最终取出来的样子
(-1)S * 1.xxxxxx * 2E
E全为0
求出来的E加了一个正数的中间值成了0,说明原本的E是一个负数,而且这个负数很小,也就是说,在写成科学计数方式的时候,E向右移动了127位或者1023位。
如此看来,原本这个数就是一个非常小的数。
1.xxxx * 2-127 或者1.xxxx * 2-1023。x不全是0
可以看出,这个是非常的小,接近于无穷小。
所以此时编译器在取出这样的一个数的时候,按照的规则就是取出一个非常小的数的规则。
- 首先S仍然表示的是符号位,正常取出。
- 取接下来的8位或者11位中的E时,取出的结果是1减去127或者1减去1023。
- 取接下来的23位或者52位中的M时,直接取出,并将取出的内容当作小数部分,正数部分编译器自动补一个0。
取出来的样子
(-1)S * 0.xxxxxx * 2(一个很小的负数)
如此一来,一个特别小的浮点数就从内存中取出来了。
E全为1
E如果都是1,也就是说内存中存的E是255或者是2047,那么原本的E是在这个值的基础上减去127或者1023,得出的结果也是一个很大的数,就是说这个浮点数在写成科学计数方式的时候,小数点向左移动了128位或者1024位。
那么这个数原本的值就很大。
1.xxxx * 2128 或者 1.xxxx * 21024。x不全是0
可以看出,这个数的非常大的,接近于无穷大。
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s)。
所以,编译器在取出这样一个数的时候按照的规则就是取出一个非常大的数的规则。
以上就是浮点数从内存中取出的规则。
一个例子(可略过)
此时我们再回顾前面抛出的那个例子
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}
我们按照上面学到的浮点数的存储与取出的知识来分析一下。
首先创建了一个int类型的变量n=9,它的
原码:00000000000000000000000000001001
反码:00000000000000000000000000001001
补码:00000000000000000000000000001001
接着取n的地址,假设它的地址是0x00ff1240。
这个地址本来是一个int类型的,现在将它强制转化成float类型的,放在指针变量pFloat中,大小也是4个字节。
第一个打印语句
printf("n的值为:%d\n", n);打印的就是int类,打印的对象n也是int类型,所以结果直接是9。
第二个打印语句
printf("*pFloat的值为:%f\n", *pFloat);打印的是一个float类型,打印对象是指针变量pFloat指向地址中的值。
这个地址中的值就是n的补码00000000000000000000000000001001。
因为要用到这个值,所以需要取出,由于此时站在pFloat的角度认为这个内存中空间中的值就是一个float的值,所以按照浮点数的规则取出。
又发现它存储E的8位全部是0,按照上面所说的取出规则,取出的数就是
0.00000000000000000001001 * 2-127。
由于默认打印出的结果是保留小数点后6位,所以结果就是0.000000
然后语句
*pFloat = 9.0;按照浮点数的储存规则讲9.0放在了int类型变量n开辟的空间里。
浮点数9.0
写成二进制 1001.0
写成科学计数法 1.0010
S=0,E=3,M=1.0010
所以在这个变量空间中存放的值就是
01000001000100000000000000000000。
第三条打印语句
printf("num的值为:%d\n", n);要打印的数是一个int类型的数,打印对象就是变量n中的值,此时编译器认为n中的值就是int类型的
补码:01000001000100000000000000000000
反码:01000001000100000000000000000000
原码:01000001000100000000000000000000
转化成十进制后的结果是1,091,567,616。
最后一条打印语句
printf("*pFloat的值为:%f\n", *pFloat);打印的数是一个float类型的数据,打印对象是pFloat指针变量指向的地址中的值,也就是int类型变量n中的值。
此时编译器认为这个内存空间中放的就是一个float类型的变量,所以就按照float类型变量的取出规则来取这个数,并且打印出来。
恰好这个内存空间此时正好是一个按照浮点数储存规则放进去的浮点数,所以打印出的结果就是存进去的浮点数本身。
又由于浮点数默认打印小数点后6位,所以结果就是9.000000
我们再来看下运行的结果
结果与我们上面分析的结果一致。
至此,你明白了浮点数是怎么在内存中存储与取出的了吗?
总结
整型数据和浮点型数据在内存中都有各自的存储规则,不同类型的数据所开辟的空间大小也不一样。创建的什么类型,编译器就认为对应的空间里放的就是什么类型,而且大小也确定的。在使用变量的时候要准确使用变量类型,才能避免产生BUG。
如果本文对您有帮助,请您一键三连支持下本喵。
边栏推荐
- Simulation volume leetcode [general] 1567 Length of the longest subarray whose product is a positive number
- Pointer advanced, string function
- JS operation
- Speaking of a software entrepreneurship project, is there anyone willing to invest?
- Greenplum6.x-版本变化记录-常用手册
- 模拟卷Leetcode【普通】1567. 乘积为正数的最长子数组长度
- C语言指针(下篇)
- [wechat applet: cache operation]
- 【ChaosBlade:节点 CPU 负载、节点网络延迟、节点网络丢包、节点域名访问异常】
- OpenGL三维图形绘制
猜你喜欢
![[Nanjing University] - [software analysis] course learning notes (I) -introduction](/img/57/bf652b36389d2bf95388d2eb4772a1.png)
[Nanjing University] - [software analysis] course learning notes (I) -introduction
Troublesome problem of image resizing when using typora to edit markdown to upload CSDN

数字三角形模型 AcWing 275. 传纸条
Category of IP address
C语言指针(特别篇)
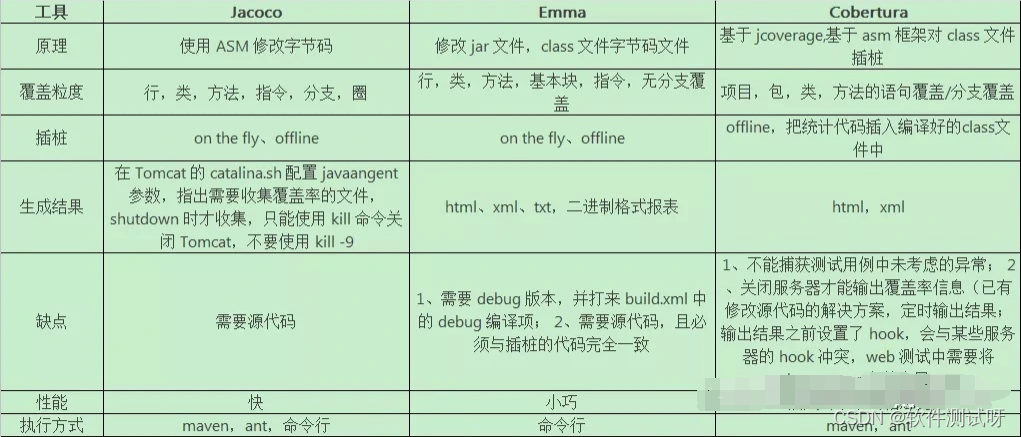
Recommended by Alibaba P8, the test coverage tool - Jacobo is very practical
The longest ascending subsequence model acwing 1017 Strange thief Kidd's glider
阿里p8推荐,测试覆盖率工具—Jacoco,实用性极佳
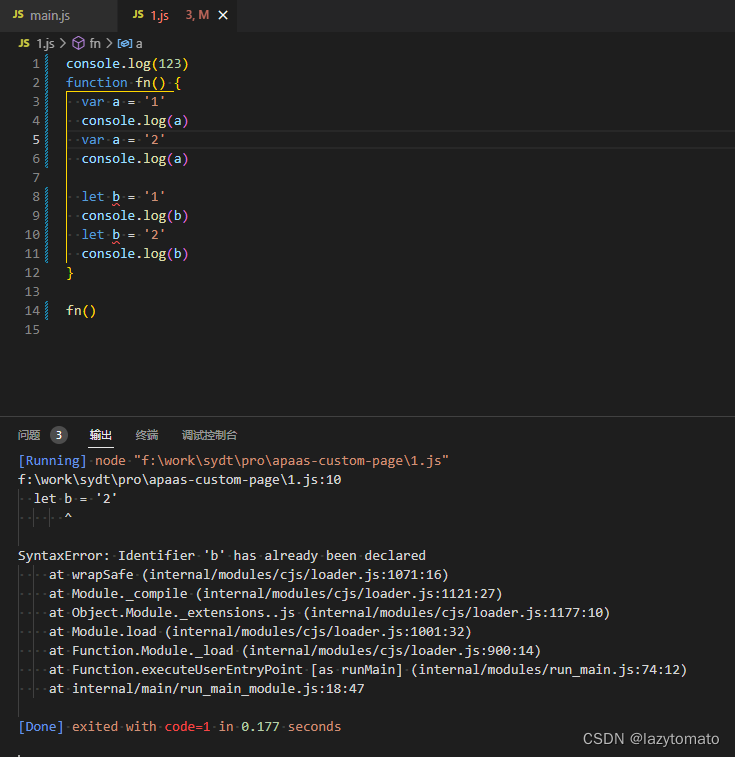
let const
How to realize sliding operation component in fast application
随机推荐
面试题:高速PCB一般布局、布线原则
C语言指针(特别篇)
Test pits - what test points should be paid attention to when adding fields to existing interfaces (or database tables)?
Count the number of words C language
NVIC中断优先级管理
Esp32-ulp coprocessor low power mode RTC GPIO interrupt wake up
Led analog and digital dimming
最长上升子序列模型 AcWing 1017. 怪盗基德的滑翔翼
Why choose cloud native database
2022-07-06 Unity核心9——3D动画
Required String parameter ‘XXX‘ is not present
Shell script for changing the current folder and the file date under the folder
Data analysis methodology and previous experience summary 2 [notes dry goods]
OpenGL 3D graphics rendering
LeetCode 736. Lisp 语法解析
C语言指针(中篇)
Markdown editor Use of MD plug-in
C语言指针(习题篇)
ncs成都新電面試經驗
Calculation s=1+12+123+1234+12345 C language