当前位置:网站首页>Knowledge Engineering Assignment 2: Introduction to Knowledge Engineering Related Fields
Knowledge Engineering Assignment 2: Introduction to Knowledge Engineering Related Fields
2022-08-02 03:33:00 【woshicaiji12138】
Natural Language Processing
Knowledge engineering is a research field formed from the construction of expert systems, and has now become an interdisciplinary comprehensive discipline.His main research fields include soft computing, natural language processing, logic and reasoning, etc. [1].This article mainly focuses on the field of natural language processing for relevant introductions.
I. Overview of Natural Language Processing
NLP for short, it is a science that integrates linguistics, computer science, and art.Therefore, it is very closely related to the study of linguistics, but has important differences.The research object of natural language processing is not the natural language in daily life, but the development of computer systems, especially the software systems, which can effectively realize natural language communication.Hence it is part of computer science [2].
At present, there are several classic tasks in the field of natural language processing: stemming, lemmatization, word vectorization, part-of-speech tagging, named entity disambiguation, named subject recognition, sentiment analysis, text semantic similarity analysis andText summary, etc.
Second, stem extraction
This paper mainly selects stem extraction for a detailed introduction.Stemming is the process of removing the inflection or derivative form of words and converting the original words into stems [3].(For example, in English: the stems of "beautiful" and "beautifully" are both "beauti"; "stemmer", "stemming" and "stemmed" are based on the stem "stem".)
Three.Porter Stemming
The classic approach to this task is Martin Porter's Porter stemming algorithm.Dr. Porter also received the 2000 Tony Kents Award for his work in stemming and information retrieval.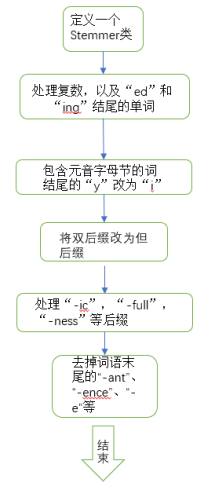 This method first requires us to define a file containing a to store stemThe class to extract the array of words before the formal processing of the algorithm can begin.The first step of the algorithm is to deal with plurals, and words ending in "ed" and "ing".The second step is to find out if there is a word that contains a vowel and ends in "y"; after finding it, change "y" to "i".The third step is to map words with double suffixes, such as preferred; to single suffixes.The fourth step is to deal with suffixes such as "-ic", "-full", and "-ness".Then remove "-ant", "-ence", "-e", etc. at the end of the word where appropriate.Finally, a stem() method is used to obtain the stem of the word transformation.
This method first requires us to define a file containing a to store stemThe class to extract the array of words before the formal processing of the algorithm can begin.The first step of the algorithm is to deal with plurals, and words ending in "ed" and "ing".The second step is to find out if there is a word that contains a vowel and ends in "y"; after finding it, change "y" to "i".The third step is to map words with double suffixes, such as preferred; to single suffixes.The fourth step is to deal with suffixes such as "-ic", "-full", and "-ness".Then remove "-ant", "-ence", "-e", etc. at the end of the word where appropriate.Finally, a stem() method is used to obtain the stem of the word transformation.
Fourth, the latest method
Since the advent of the Porter stemming method, new stemming methods have been emerging, and there are improved methods based on the Porter stemming method [4]; otherThere are some new and smarter methods, such as the method of n-gram parsing.The method exploits the context of a word to extract the correct stem, which undoubtedly greatly improves the practicality.
References
[1] Huang Ronghuai, Li Maoguo, Sha Jingrong, Knowledge Engineering: A New Important Research Field [E], Electronic Education Research, 2004, (10): 1-7
[2] Li Changyun, Wang Zhibing, Intelligent perception technology and its application in electrical engineering, University of Electronic Science and Technology of China Press, 2017.05, p. 163)
[3] Common 10 Natural Language Processing Technologies, September 2, 2021,https://blog.csdn.net/Harrytsz/article/details/120053267
[4] Widjaja M, Seng H. Implementation of Modified Porter Stemming Algorithm to Indonesian Word Error Detection Plugin Application[J]. Int J Hum CultStud, 2015, 6(2):139.
边栏推荐
- oracle内连接和外连接
- DSPE-PEG-DBCO 磷脂-聚乙二醇-二苯并环辛炔 一种线性杂双官能聚乙二醇化试剂
- MongoDB文档存储
- 「PHP基础知识」PHP中对象的使用
- np.unique()函数
- DSPE-PEG-PDP,DSPE-PEG-OPSS,磷脂-聚乙二醇-巯基吡啶供应,MW:5000
- Good Key, Bad Key (thinking, temporary exchange, classic method)
- Debian 10 NTP 服务配置
- Redis简单学习笔记
- UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the index ing argu
猜你喜欢







随机推荐
5. Hezhou Air32F103_LCD_key
TRICK second bullet
【深度学习】从LeNet-5识别手写数字入门深度学习
磷脂-聚乙二醇-醛基 DSPE-PEG-Aldehyde DSPE-PEG-CHO MW:5000
网站与服务器维护怎么做?
Week 7 Review
PowerManagerService灭屏超时流程
ModuleNotFoundError No module named ‘xxx‘可能的解决方案大全
MySQL占用CPU过高,排查原因及解决的多种方式法
cross-domain problem solving
多个el-select下拉框无法选中相同内容
Monaco Editor 的基本用法
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
磷脂-聚乙二醇-巯基,DSPE-PEG-Thiol,DSPE-PEG-SH,MW:5000
AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘
腾讯50题
LeetCode:1161. 最大层内元素和【BFS层序遍历】
Double Strings (don't always forget substr)
Deveco studio 鸿蒙app访问网络详细过程(js)
Chapter 10 Clustering