当前位置:网站首页>OD-Model【4】:SSD
OD-Model【4】:SSD
2022-08-02 03:08:00 【zzzyzh】
前言
本文主要对论文进行解读,并解释有关SSD网络的框架部分
原论文链接:
SSD: Single Shot MultiBox Detector
1. Abstract & Introduction
1.1. Abstract
我们提出了一种利用单一的深度神经网络来检测图像中的目标的方法。我们的方法名为SSD,它将不同的高宽比和比例的边界框的输出空间离散为一组默认框。在预测时,网络为每个默认框中每个对象类别的存在生成分数,并对该框进行调整,以更好地匹配对象形状。此外,该网络结合了来自不同分辨率的多个特征地图的预测,以自然地处理不同大小的对象。相对于需要对象建议的方法,SSD很简单,因为它完全消除了建议生成和后续的像素或特征重采样阶段,并将所有计算封装在单个网络中。这使得SSD易于训练,并可以直接集成到需要一个检测组件的系统中。
1.2. Introduction
本文介绍了第一个基于深度网络的对象检测器,它不为边界框假设和重新采样像素或特征,并且与其他方法一样准确。这使得高精度检测的速度显著提高。
我们并不是第一个这样做的人,但是通过增加一系列的改进,我们设法比以前的尝试大大提高了精确度。我们的改进包括使用小卷积滤波器来预测对象类别和边界框位置中的偏移,对不同的纵横比检测使用单独的预测器(滤波器),以及将这些滤波器应用于来自网络后期阶段的多个特征图,以便在多个尺度上执行检测。通过这些修改——特别是使用多层进行不同尺度的预测——我们可以使用相对较低分辨率的输入实现高精度,从而进一步提高检测速度。
贡献总结如下:
- 我们引入了SSD,这是一种用于多个类别的单次检测器,比之前的单次检测器(YOLO)更快,更准确,实际上与执行显式区域建议和合并的较慢技术(包括更快的R-CNN)一样准确。
- SSD的核心是使用应用于特征地图的小型卷积过滤器来预测一组固定默认边界框的类别分数和框偏移量。
- 为了实现高检测精度,本文从不同比例的特征地图中生成不同比例的预测,并通过纵横比明确地分离预测。
- 这些设计特性带来了简单的端到端训练和高精度,即使在低分辨率输入图像上也是如此,进一步改善了速度与精度之间的平衡。
Faster RCNN存在的问题:
- 对小目标检测效果很差
- 只在一个特征层上预测
- feature map抽象到一个比较高的维度,导致细节信息损失
- 预测小目标需要依靠细节信息
- 只在一个特征层上预测
- 模型大,检测速度较慢
- 预测过程分为两步
2. The Single Shot Detector (SSD)
2.1. Model
SSD方法基于前馈卷积网络,该网络产生固定大小的边界框集合,并对这些边界框中存在的目标类别实例进行评分,然后进行非极大值抑制步骤来产生最终的检测结果。早期的网络层基于用于高质量图像分类的标准架构(在任何分类层之前被截断),我们将其称为基础网络。然后,我们将辅助结构添加到网络中以产生具有以下关键特征的检测:
2.1.1. Multi-scale feature maps for detection
在截断的基础网络的末端添加卷积特征层。这些层的尺寸逐渐减小,并允许在多个尺度上进行探测预测。用于预测检测的卷积模型对于每个要素图层而言都是不同的
- 输入
- 输入网络的图像必须是大小为 300x300 的RGB图像(在输入网络之前对输入的图像进行Resize)
- 网络结构
- 以VGG16作为基础网络,将VGG16的两个全连接层换成了普通的卷积层并在网络结构最后添加多个卷积层以获取更多feature map用于预测
- Convx_y
- x:第x组卷积层
- y:第x组卷积层的第y个卷积层
- Convx_y
- VGG16-16 through Conv5_3 layer -> VGG16模型中Conv5_3之前的所有层
- Conv4_3输出的大小为 38 × 38 × 512 38 \times 38 \times 512 38×38×512 特征矩阵即SSD的第1个特征预测层
- 将VGG16的max_pool5从原本的 2 × 2 − s 2 2 \times 2 - s2 2×2−s2 修改成 3 × 3 − s 1 3 \times 3 - s1 3×3−s1,此时 Conv5_3 layer 的输出矩阵的大小与Conv5_3 layer的大小相同
- Conv6 -> VGG16模型中的FC6
- 因为修改过后的max_pool5,我们可以发现, Conv6卷积层的大小为Conv4_3大小的一半
- 通过一个 3 × 3 × 1024 3 \times 3 \times 1024 3×3×1024 的卷积层
- Conv7 -> VGG16模型中的FC7
- Conv7输出的大小为 19 × 19 × 1024 19 \times 19 \times 1024 19×19×1024 特征矩阵即SSD的第2个特征预测层
- 通过一个 1 × 1 × 1024 1 \times 1 \times 1024 1×1×1024 的卷积层
- Conv8_2
- Conv8_2输出的大小为 10 × 10 × 512 10 \times 10 \times 512 10×10×512 特征矩阵即SSD的第3个特征预测层
- 通过一个 1 × 1 × 256 1 \times 1 \times 256 1×1×256 的卷积层
- 通过一个 1 × 1 × 1024 1 \times 1 \times 1024 1×1×1024 的卷积层
- Conv9_2
- Conv9_2输出的大小为 5 × 5 × 256 5 \times 5 \times 256 5×5×256 特征矩阵即SSD的第4个特征预测层
- 通过一个 1 × 1 × 128 1 \times 1 \times 128 1×1×128 的卷积层
- 通过一个 3 × 3 × 256 − s 2 3 \times 3 \times 256 - s2 3×3×256−s2 的卷积层
- Conv10_2
- Conv10_2输出的大小为 3 × 3 × 256 3 \times 3 \times 256 3×3×256 特征矩阵即SSD的第5个特征预测层
- 通过一个 1 × 1 × 128 1 \times 1 \times 128 1×1×128 的卷积层
- 通过一个 3 × 3 × 256 − s 1 3 \times 3 \times 256 - s1 3×3×256−s1 的卷积层
- Conv11_2
- Conv11_2输出的大小为 1 × 1 × 256 1 \times 1 \times 256 1×1×256 特征矩阵即SSD的第6个特征预测层
- 通过一个 1 × 1 × 128 1 \times 1 \times 128 1×1×128 的卷积层
- 通过一个 3 × 3 × 256 − s 1 3 \times 3 \times 256 - s1 3×3×256−s1 的卷积层
- 需要注意的是:
- Conv8_2、Conv9_2 所通过的卷积层的步长 stride = 2,padding = 1
- Conv10_2、Conv11_2 所通过的卷积层的步长 stride = 1, pading = 0
- 第一层往往用于检测较小的目标,随着抽象程度的增加,后面的预测层将会检测较大目标
- VGG16模型结构图
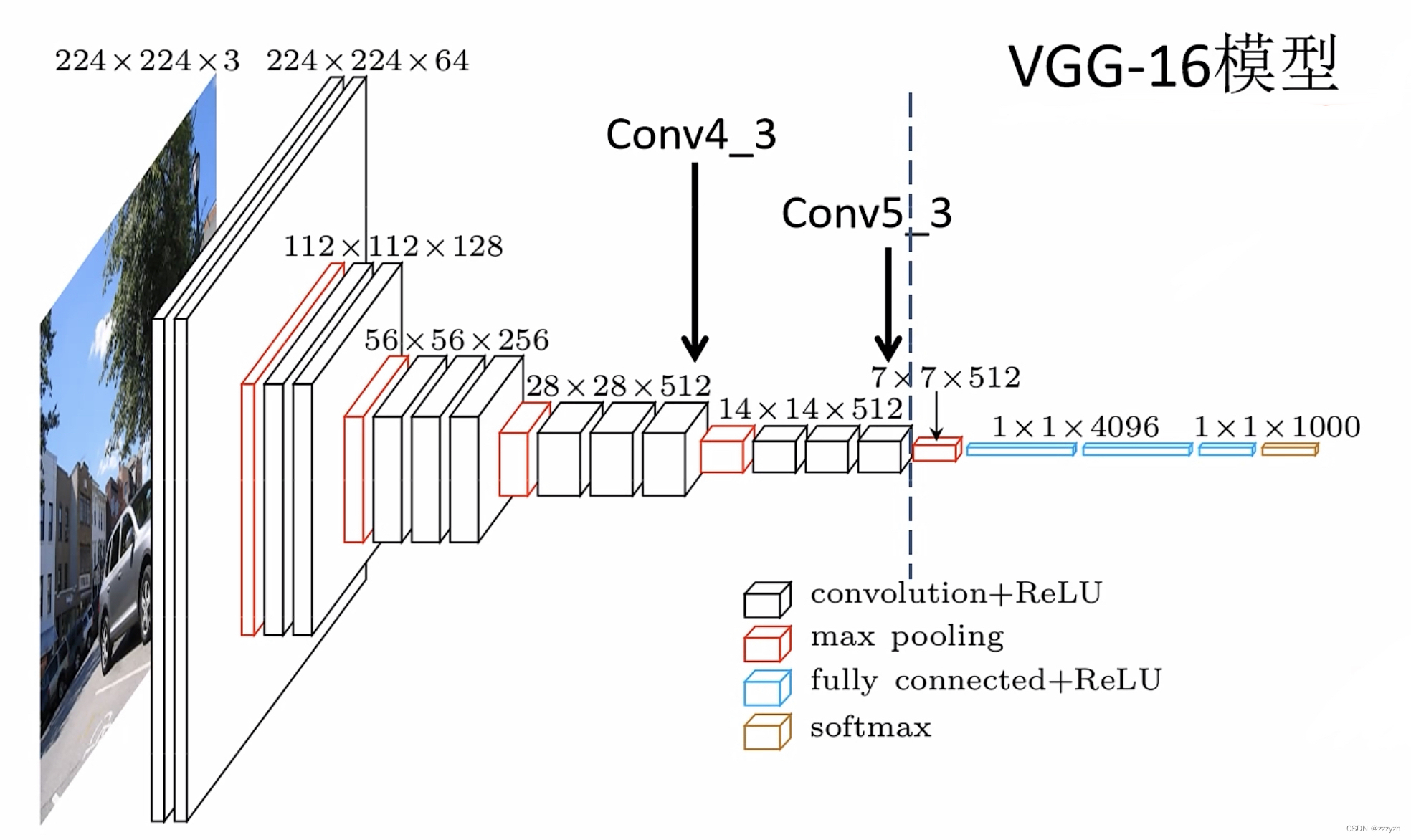
- 以VGG16作为基础网络,将VGG16的两个全连接层换成了普通的卷积层并在网络结构最后添加多个卷积层以获取更多feature map用于预测
- 输出
- 经过最后一层池化之后,会输出8732个预测框(文中称为Default box,与Faster RCNN中的anchor概念是一样的),然后网络会用一组小卷积滤波器对这些预测框进行对象类别和位置偏移的预测(分类和定位),经过NMS(非极大值抑制)算法之后输出检测结果。
2.1.2. Convolutional predictors for detection
每个添加的特征层(或可选地是来自基础网络的现有特征层)都可以使用一组卷积滤波器生成一组固定的检测预测。这些都显示在SSD网络架构的顶部对于大小为 m × n m \times n m×n 的具有 p p p 通道的特征层,预测潜在检测参数的基本元素是 3 × 3 × p 3 \times 3 \times p 3×3×p 小内核,它产生一个类别的分数,或相对于默认框坐标的形状偏移。在应用内核的每个 m × n m \times n m×n 位置,它产生一个输出值。边界框偏移输出值是相对于相对于每个特征图位置的默认框位置来测量的。
具体而言,对于给定位置处的 k k k 个 default box 中的每一个,我们计算 c c c 个类别分数和相对于原始默认边界框形状的 4 4 4 个偏移量。这导致在特征映射中的每个位置周围应用总共 ( c + 4 ) k (c+4)k (c+4)k 个滤波器,对于 m × n m \times n m×n 的特征映射取得 ( c + 4 ) k m n (c+4)kmn (c+4)kmn 个输出。

- ( c + 4 ) × k = c × k + 4 × k (c + 4) \times k = c \times k + 4 \times k (c+4)×k=c×k+4×k
- c × k c \times k c×k:预测每一个 default box 所对应的类别分数
- c 个目标分数
- 包括背景的分数(第一个分数即背景分数)
- 在 feature map 上的每个位置上都会生成 k 个 default box
- c 个目标分数
- 4 × k 4 \times k 4×k:每一个 default box 的边界框回归参数
- 对应的顺序为: ( x , y , w , h ) (x, y, w, h) (x,y,w,h)
- 对于每一个 default box 只生成 4 × k 4 \times k 4×k,并不关注每一个 default box 属于哪一个类别
- 与faster rcnn不同,faster rcnn 对于每一个 anchor 都会生成 4 × c 4 \times c 4×c 个边界框回归参数,因为考虑不同的类别
- c × k c \times k c×k:预测每一个 default box 所对应的类别分数
2.1.3. Default boxes and aspect ratios
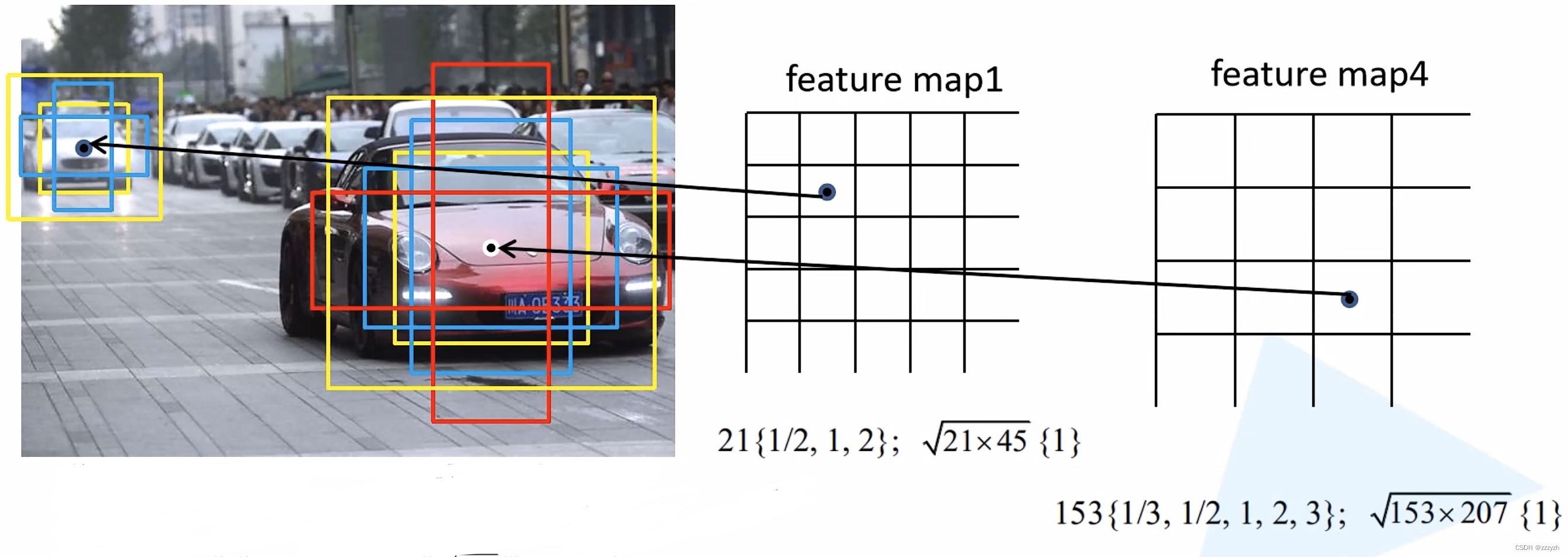
对于网络顶部的多个特征映射,我们将一组默认边界框与每个特征映射单元相关联。默认边界框以卷积的方式平铺特征映射,以便每个边界框相对于其对应单元的位置是固定的。在每个特征映射单元中,我们预测单元中相对于默认边界框形状的偏移量,以及指出每个边界框中存在的每个类别实例的类别分数。我们的默认边界框与 Faster R-CNN 中使用的 anchor 相似,但是我们将它们应用到不同分辨率的几个特征映射上。在几个特征映射中允许不同的默认边界框形状让我们有效地离散可能的输出框形状的空间。
- (a):标注好的原图
- (b): 8 × 8 8 \times 8 8×8 feature map,抽象程度更低,保留的细节信息更多,预测较小的目标
- 在 8 × 8 8 \times 8 8×8 feature map 上预测猫,生成的两个蓝色 default box 可以很好地预测猫的信息
- : 4 × 4 4 \times 4 4×4 feature map,抽象程度更高,保留的细节信息更少,预测较大的目标
- 在 4 × 4 4 \times 4 4×4 feature map 上预测狗,生成的一个红色 default box 可以很好地预测狗的信息
- default box 分别放置在不同的特征层上,进行预测
2.2. Training
2.2.1. Choosing scales and aspect ratios for default boxes
Default boxes 的 scale 以及 aspect 设定:
- scale:目标尺度
- 对于每一层,都有: ( s k , s k + 1 ) (s_k, s_{k+1}) (sk,sk+1)
- 对于长宽比为1,我们还添加了一个默认边界框,其尺度为: s k ′ = s k s k + 1 s_k' = \sqrt{s_k s_{k+1}} sk′=sksk+1
- aspect:每个尺度对应的一系列比例
- 对于Conv4_3、Conv10_2和Conv11_2
- 有4个default box
- 3种比例: 1 : 1 , 2 : 1 , 1 : 2 1:1, 2:1, 1:2 1:1,2:1,1:2
- 对于Conv7、Conv8_2和Conv9_2
- 有6个default box
- 5种比例: 1 : 1 , 2 : 1 , 1 : 2 , 3 : 1 , 1 : 3 1:1, 2:1, 1:2, 3:1, 1:3 1:1,2:1,1:2,3:1,1:3
- 对于Conv4_3、Conv10_2和Conv11_2

在预设特征层上的每一个元素的位置上都会生成所有尺寸的default box,即默认框的总数为:
38 × 38 × 4 + 19 × 19 × 4 + × 10 × 10 × 6 + 5 × 5 × 6 + 3 × 3 × 4 + 1 × 1 × 4 = 8732 38 \times 38 \times 4 + 19 \times 19 \times 4 + \times 10 \times 10 \times 6 + 5 \times 5 \times 6 + 3 \times 3 \times 4 + 1 \times 1 \times 4 = 8732 38×38×4+19×19×4+×10×10×6+5×5×6+3×3×4+1×1×4=8732
2.2.2. Selection of positive and negative samples
2.2.2.1. Matching strategy
正样本
- 对于每一个 Ground-Truth box,去匹配与之 IoU 值最大的 deafult box
- 对于任意的一个 default box,与任何一个 Ground-Truth box 的 IoU 值大于0.5,也认为它是正样本
2.2.2.2. Hard negative mining
负样本
正样本外的所有部分都可以认为是负样本。我们不使用所有负样本,而是使用每个默认边界框的最高置信度损失(highest confidence loss)来排序它们,并挑选最高的置信度,以便负例和正例之间的比例至多为 3 : 1 3:1 3:1。我们发现这会导致更快的优化和更稳定的训练。
2.2.3. Training objective

其中 N N N 为匹配到的正样本的个数, α = 1 \alpha = 1 α=1
- 类别损失
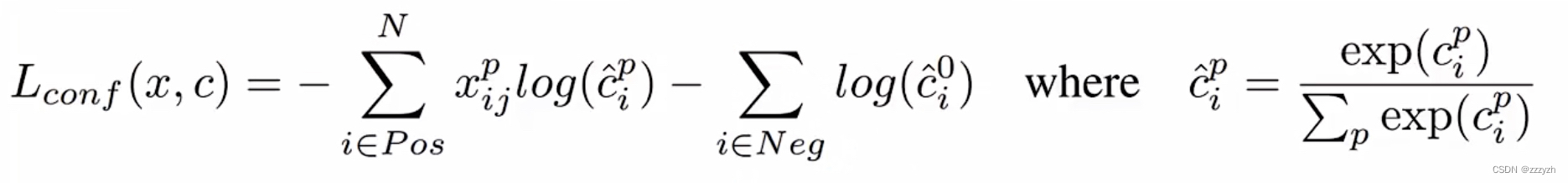
置信度损失是在多类别置信度 ( c ) (c) (c) 上的softmax损失。- 参数
- c ^ i p \hat{c}_i^p c^ip 为预测的第 i 个 default box 对应的 GT box(类别为P)的类别概率
- x i j p = { 0 , 1 } x_{ij}^p = \{ 0, 1 \} xijp={ 0,1} 为第 i 个 default box 匹配到的第 j 个 GT box(类别是P)的概率
- 匹配指示器
- 参数
- 定位损失
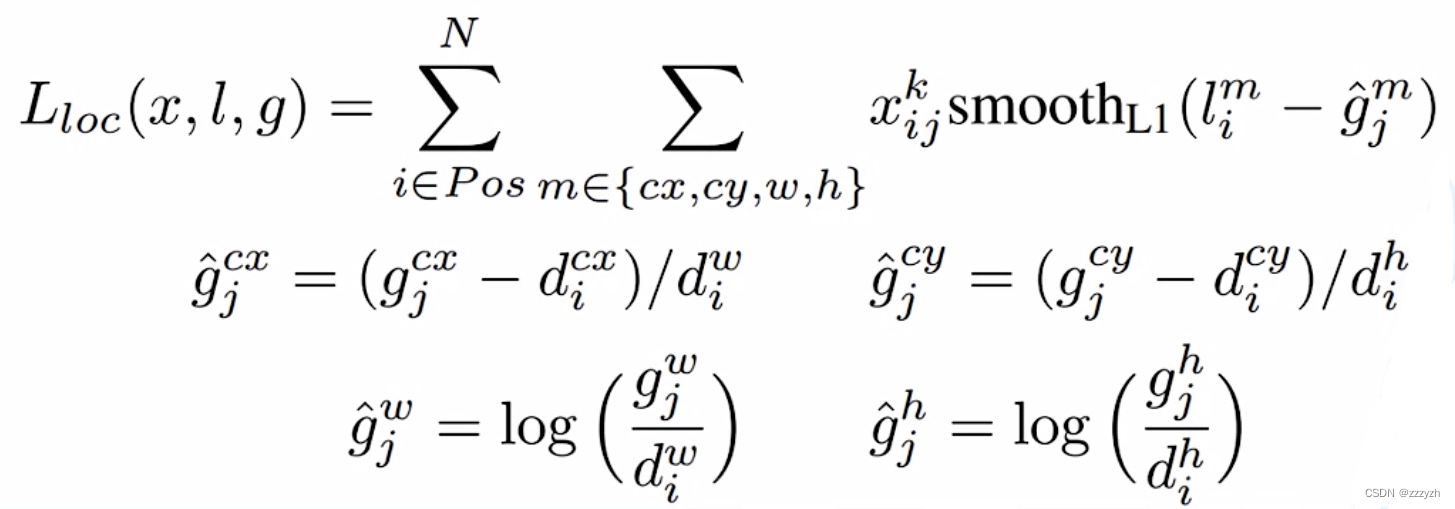
- 参数
- l i m l_i^m lim:为预测对应第 i i i 个正样本回归参数
- g ^ j m \hat{g}_j^m g^jm 为正样本 i i i 匹配的第 j j j 个 G T b o x GT box GTbox 的回归参数
- g ^ j c x \hat{g}_j^{cx} g^jcx
- g j c x g_j^{cx} gjcx:GT box中心点的x坐标
- d i c x d_i^{cx} dicx:第i个default box的中心点的x坐标
- d i w d_i^w diw:第i个default box的宽度
- g ^ j c y \hat{g}_j^{cy} g^jcy
- g j c y g_j^{cy} gjcy:GT box中心点的y坐标
- d i c y d_i^{cy} dicy:第i个default box的中心点的y坐标
- d i h d_i^h dih:第i个default box的高度
- g ^ j c x \hat{g}_j^{cx} g^jcx
- 参数
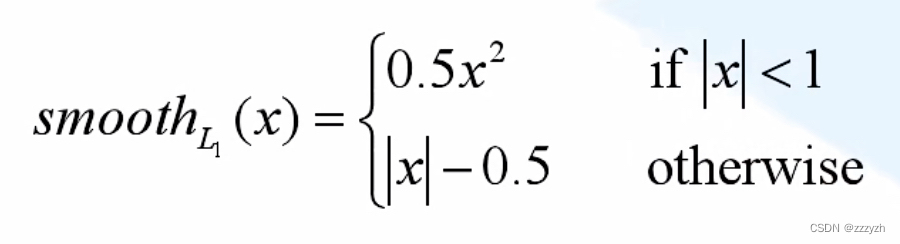
总结
SSD的优点:
- 因为同为one-stage方法(单网络),运行速度可以和YOLO媲美,同时对于不同横纵比的object的检测都有效,这是因为算法对于每个feature map cell都使用多种横纵比和不同尺寸的default boxes,这也是本文算法的核心。
SSD的缺点:
- 需要人工设置default boxes的初始尺度和长宽比的值。网络中default boxes的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层 feature使用的default box大小和形状恰好都不一样,导致调试过程非常依赖经验。
- 对小尺寸的目标识别仍比较差,还达不到 Faster R-CNN 的水准。这主要是因为小尺寸的目标多用较低层级的特征来训练(因为小尺寸目标在较低层级IOU较大),较低层级的特征非线性程度不够,无法训练到足够的精确度。
边栏推荐
猜你喜欢








随机推荐
MySQL8--Windows下使用压缩包安装的方法
(转帖)HashCode总结(1)
Difference between #{} and ${}
输入延迟切换系统的预测镇定控制
[LeetCode] 83. Delete duplicate elements in the sorted list
考虑饱和的多智能体系统数据驱动双向一致性
[Daily LeetCode]——1. The sum of two numbers
5.合宙Air32F103_LCD_key
MySQL index optimization in practice
Ribbon本地实现负载均衡
给你一个大厂面试的机会,你能面试上吗?进来看看!
利用WebShell拿Shell技巧
Chapter 10 聚类
MySQL8.0.26安装配置教程(windows 64位)
- daily a LeetCode 】 【 9. Palindrome
OperatingSystemMXBean to get system performance metrics
I will give you a chance to interview in a big factory. Can you interview?Come in and see!
JSP WebSehll 后门脚本
JDBC--Druid数据库连接池以及Template基本用法
嘉为蓝鲸携手东风集团、上汽零束再获信通院四项大奖