当前位置:网站首页>Label Semantic Aware Pre-training for Few-shot Text Classification
Label Semantic Aware Pre-training for Few-shot Text Classification
2022-07-03 10:11:00 【InfoQ】

brief introduction
Pictures and articles
The whole structure

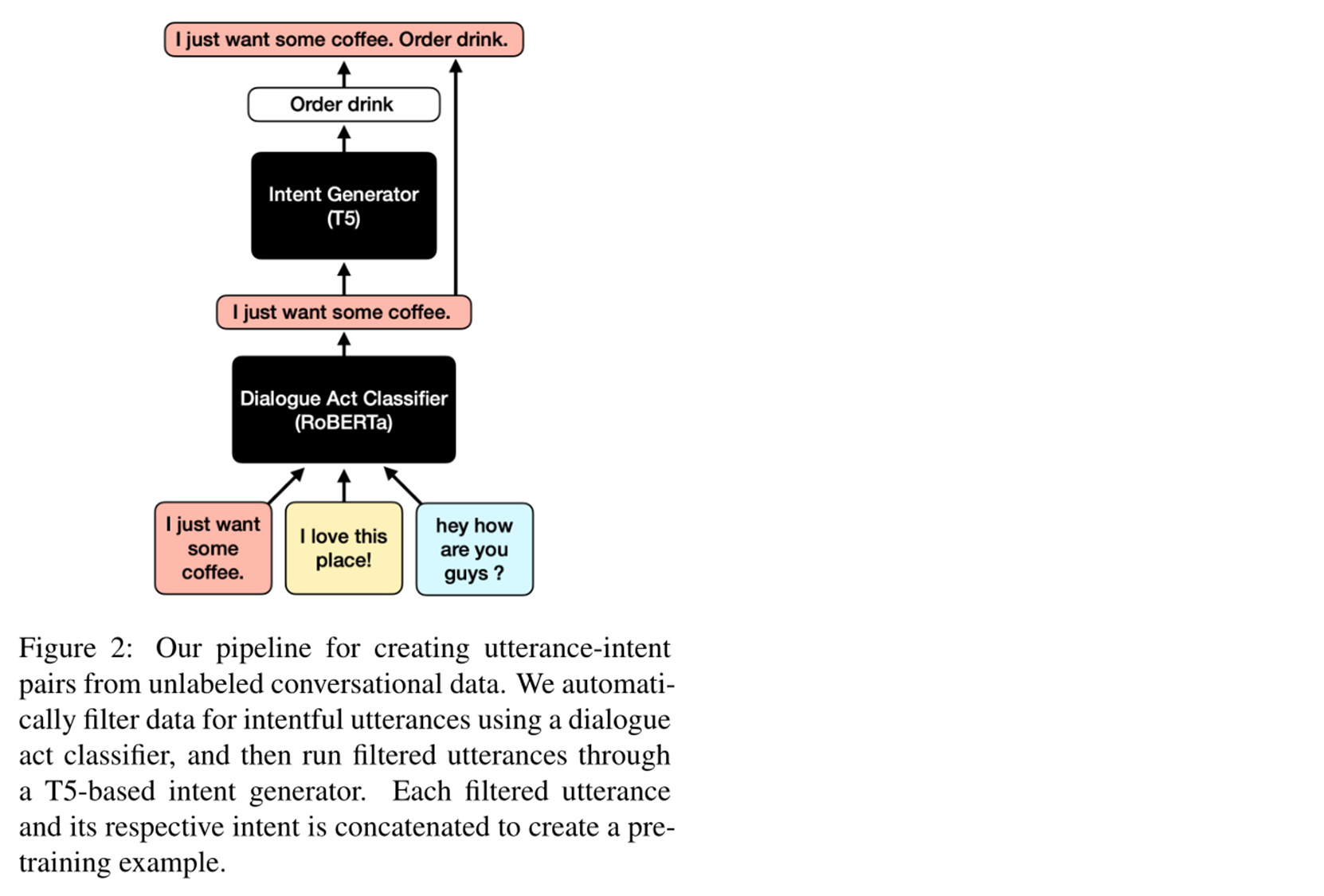
pipeline
- Gold data : By an undisclosed benchmark Data set and a public data set . The annotation quality of manual annotation of gold data is higher .
- Silver data : It is also a public data set . Silver data is annotated with heuristic .
- Bronze data : Because tagged data is expensive , And the number is rare . Therefore, this paper also obtains pre training data from a large number of unlabeled data . Figure 2 is the framework used .
- Dialog intention filter : Is based on RoBERTa Of . It is to divide the dialogue into positive examples and negative examples . Because not all conversations have a certain intention . such as “ It's a beautiful day .” This sentence has no intention ; however “ It's a beautiful day , So I want to go to the park .” This sentence is with a clear intention . If you put a data label on the data without intention , It will adversely affect the pre training and subsequent downstream tasks . Therefore, the unintentional sentences should be removed .
- Intention generator : Because unlabeled data has no intention to label , So use a based on T The intention generator of five generates the intention of the corresponding dialogue sentence .
Pre training form


- The first is random mask. Randomize sentences mask. And then use T5 Generate mask Content of the label .
- Here is a training method similar to the downstream task , Intention classification . Enter a sentence , And then sort it out , Output such intention natural language tags .
- Finally, denoising . The input sequence is composed of a sentence and the corresponding tag , But the label mask It fell off . Output to guess mask What is the content of .
Experimental design
Fine tuning part
baselines:
- XLNet
- LM-BFF
- seq2eq-PTR
- T5
- T5(adapt)
Add

summary
Introduction
motivation
- Pre training models are often used to encode input efficiently , But there is little work to let the model access the information representation of the tag .
- Other work is to use tagging in the fine-tuning and prediction stages .
- “ gold ” and “ Silver ” Data scarcity
contribution
- Incorporate tag semantics into the generation model during pre training .
- Create from unlabeled noise data “ word - Intention ” Yes , For label semantic awareness pre training .( Used for processing “ bronze ” data , Create for unlabeled text “ dialogue - Intention ” Yes )
- Intention and subject classification data set SOTA.
Approach
data:
- Gold data : Unpublished data sets + PolyAI Banking, It's with label The data of
- Silver data : Heuristically labeled datasets WikiHow, It's with heuristicallyp-label The data of
- Bronze data : Pseudo tag data , Create from unlabeled data utterance-intent pairs. yes seudo-label data
For the processing of unlabeled data :
- Dialog filter :
- Not all conversations are intentional (goal、intent).
- In order to prevent unintentional statements from being labeled with intent, thereby creating toxic data that affects downstream tasks , So first classify the dialogue into two categories (“non-intentful/negative” and “intentful/positive” ).
- Use Multi-Domain Goal-Oriented Dialogue (MultiDoGO) Schema-guided Dialogue(SGD) Yes, based on RoBERTa The dialog classifier is adjusted .
- Intention generator :
- Use gold and silver data to fine tune T5, Then throw the filtered data into it to generate intention labels . It also produced 37% Tags that don't appear in the training set .
Preliminary training ——label denoising
Experimental setup
fine-tuning :
baselines:
- XLNet
- LM-BFF
- seq2eq-PTR
- T5
- T5(adapt)
边栏推荐
- yocto 技术分享第四期:自定义增加软件包支持
- Serial port programming
- Serial communication based on 51 single chip microcomputer
- [combinatorics] Introduction to Combinatorics (combinatorial idea 3: upper and lower bound approximation | upper and lower bound approximation example Remsey number)
- Simulate mouse click
- QT setting suspension button
- YOLO_ V1 summary
- Opencv feature extraction sift
- Leetcode - 1670 design front, middle and rear queues (Design - two double ended queues)
- Open Euler Kernel Technology Sharing - Issue 1 - kdump Basic Principles, use and Case Introduction
猜你喜欢
LeetCode - 673. 最长递增子序列的个数

Adaptiveavgpool1d internal implementation
Octave instructions

QT self drawing button with bubbles

LeetCode - 900. RLE 迭代器
Opencv feature extraction sift

openCV+dlib實現給蒙娜麗莎換臉
LeetCode - 1670 設計前中後隊列(設計 - 兩個雙端隊列)

LeetCode - 895 最大频率栈(设计- 哈希表+优先队列 哈希表 + 栈) *
3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation
随机推荐
Markdown latex full quantifier and existential quantifier (for all, existential)
Google browser plug-in recommendation
Window maximum and minimum settings
使用sed替换文件夹下文件
51 MCU tmod and timer configuration
Leetcode - 1670 conception de la file d'attente avant, moyenne et arrière (conception - deux files d'attente à double extrémité)
Opencv note 21 frequency domain filtering
Interruption system of 51 single chip microcomputer
LeetCode - 1670 设计前中后队列(设计 - 两个双端队列)
3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation
Positive and negative sample division and architecture understanding in image classification and target detection
LeetCode - 715. Range 模块(TreeSet) *****
yocto 技術分享第四期:自定義增加軟件包支持
20220606数学:分数到小数
CV learning notes ransca & image similarity comparison hash
CV learning notes convolutional neural network
SCM is now overwhelming, a wide variety, so that developers are overwhelmed
Leetcode - 460 LFU cache (Design - hash table + bidirectional linked hash table + balanced binary tree (TreeSet))*
Yocto technology sharing phase IV: customize and add software package support
Opencv image rotation