当前位置:网站首页>Data to enhance Mixup principle and code reading
Data to enhance Mixup principle and code reading
2022-08-05 02:32:00 【00000cj】
paper:mixup: Beyond Empirical Risk Minimization
存在的问题
- 经验风险最小化(Empirical Risk Minimization, ERM)Allows large neural networks to forcefully memorize training data(rather than learning、泛化),Even with strong regularization,Or in a classification problem where labels are randomly assigned,这个问题也依然存在.
- 使用ERMPrinciples for training neural networks,When evaluating on data outside the distribution of training samples,Predictions can vary significantly,This is called an adversarial example.
One solution to this problem is neighborhood risk minimization(Vicinal Risk Minimization, VRM),That is to construct more samples based on the original samples through data augmentation,But data augmentation requires human knowledge to describe the neighborhood of each sample in the training data,比如翻转、缩放等.因此VRM也有两点不足
- The data augmentation process relies on datasets,Expert knowledge is therefore required
- Data augmentation only models neighborhood relationships between the same class
Mix-up
针对上述问题,本文提出一种data-agnostic的数据增强方法mixup,
![]()
其中\(x_{i},x_{j}\)are two images randomly selected from the training set,\(y_{i},y_{j}\)是对应的one-hot标签,通过先验知识:The linear interpolation of the feature vector and the linear interpolation of the corresponding target are still a corresponding relationship,A new sample is constructed\((\widetilde{x},\widetilde{y})\).其中\(\lambda\)通过\(\beta(\alpha, \alpha)\)distribution gain,\(\alpha\)是超参.
此外,The author mentions some conclusions obtained through experiments
- It is found through experiments that the combination of three or more samples cannot bring about further accuracy improvement,On the contrary, it will increase the computational cost.
- The author's implementation method is through a separatedata loader获得一个batch的数据,然后在random shufflepost on this onebatchdata usage withinmixup,The authors found that this strategy worked well,同时减少了I/O.
- Only on samples of the same classmixupThere is no improvement in accuracy.
实现
torchvision版本
这里通过roll方法将batchThe picture inside is panned back one,然后与原batch进行mixup,相当于batchEach picture inside is compared with the adjacent onemixup,roll方法详见
class RandomMixup(torch.nn.Module):
"""Randomly apply Mixup to the provided batch and targets.
The class implements the data augmentations as described in the paper
`"mixup: Beyond Empirical Risk Minimization" <https://arxiv.org/abs/1710.09412>`_.
Args:
num_classes (int): number of classes used for one-hot encoding.
p (float): probability of the batch being transformed. Default value is 0.5.
alpha (float): hyperparameter of the Beta distribution used for mixup.
Default value is 1.0.
inplace (bool): boolean to make this transform inplace. Default set to False.
"""
def __init__(self, num_classes: int, p: float = 0.5, alpha: float = 1.0, inplace: bool = False) -> None:
super().__init__()
if num_classes < 1:
raise ValueError(
f"Please provide a valid positive value for the num_classes. Got num_classes={num_classes}"
)
if alpha <= 0:
raise ValueError("Alpha param can't be zero.")
self.num_classes = num_classes
self.p = p
self.alpha = alpha
self.inplace = inplace
def forward(self, batch: Tensor, target: Tensor) -> Tuple[Tensor, Tensor]:
"""
Args:
batch (Tensor): Float tensor of size (B, C, H, W)
target (Tensor): Integer tensor of size (B, )
Returns:
Tensor: Randomly transformed batch.
"""
if batch.ndim != 4:
raise ValueError(f"Batch ndim should be 4. Got {batch.ndim}")
if target.ndim != 1:
raise ValueError(f"Target ndim should be 1. Got {target.ndim}")
if not batch.is_floating_point():
raise TypeError(f"Batch dtype should be a float tensor. Got {batch.dtype}.")
if target.dtype != torch.int64:
raise TypeError(f"Target dtype should be torch.int64. Got {target.dtype}")
if not self.inplace:
batch = batch.clone()
target = target.clone()
if target.ndim == 1:
target = torch.nn.functional.one_hot(target, num_classes=self.num_classes).to(dtype=batch.dtype)
if torch.rand(1).item() >= self.p:
return batch, target
# It's faster to roll the batch by one instead of shuffling it to create image pairs
batch_rolled = batch.roll(1, 0)
target_rolled = target.roll(1, 0)
# Implemented as on mixup paper, page 3.
lambda_param = float(torch._sample_dirichlet(torch.tensor([self.alpha, self.alpha]))[0])
batch_rolled.mul_(1.0 - lambda_param)
batch.mul_(lambda_param).add_(batch_rolled)
target_rolled.mul_(1.0 - lambda_param)
target.mul_(lambda_param).add_(target_rolled)
return batch, target
def __repr__(self) -> str:
s = (
f"{self.__class__.__name__}("
f"num_classes={self.num_classes}"
f", p={self.p}"
f", alpha={self.alpha}"
f", inplace={self.inplace}"
f")"
)
return smmclassification版本
这里是通过randperm将batchThe pictures inside are scrambled,然后与原batch进行mixup,并且得到\(\lambda\)的方法与torchvision也不一样.
class BatchMixupLayer(BaseMixupLayer):
r"""Mixup layer for a batch of data.
Mixup is a method to reduces the memorization of corrupt labels and
increases the robustness to adversarial examples. It's
proposed in `mixup: Beyond Empirical Risk Minimization
<https://arxiv.org/abs/1710.09412>`
This method simply linearly mix pairs of data and their labels.
Args:
alpha (float): Parameters for Beta distribution to generate the
mixing ratio. It should be a positive number. More details
are in the note.
num_classes (int): The number of classes.
prob (float): The probability to execute mixup. It should be in
range [0, 1]. Default sto 1.0.
Note:
The :math:`\alpha` (``alpha``) determines a random distribution
:math:`Beta(\alpha, \alpha)`. For each batch of data, we sample
a mixing ratio (marked as :math:`\lambda`, ``lam``) from the random
distribution.
"""
def __init__(self, *args, **kwargs):
super(BatchMixupLayer, self).__init__(*args, **kwargs)
def mixup(self, img, gt_label):
one_hot_gt_label = one_hot_encoding(gt_label, self.num_classes)
lam = np.random.beta(self.alpha, self.alpha)
batch_size = img.size(0)
index = torch.randperm(batch_size)
mixed_img = lam * img + (1 - lam) * img[index, :]
mixed_gt_label = lam * one_hot_gt_label + (
1 - lam) * one_hot_gt_label[index, :]
return mixed_img, mixed_gt_label
def __call__(self, img, gt_label):
return self.mixup(img, gt_label)目标检测中的mixup
在文章Bag of Freebies for Training Object Detection Neural Networks 中,for two picturesmixupThen just merge all of the two graphsgt box,and did not do it for category labelsmixup.But the article mentions"weighted loss indicates the overall loss is the summation of multiple objects with ratio 0 to 1 according to image blending ratio they belong to in the original training images",即在计算losstime for each objectloss按mixupThe coefficients are weighted and summed.

参考
边栏推荐
- View handler stepping record
- Hypervisor related knowledge points
- Using OpenVINO to implement the flying paddle version of the PGNet inference program
- 数据增强Mixup原理与代码解读
- LPQ (local phase quantization) study notes
- 意识形态的机制
- Industry case | insurance companies of the world's top 500 construction standards can be used to drive the business analysis system
- LPQ(局部相位量化)学习笔记
- VSCode Change Default Terminal how to modify the Default Terminal VSCode
- 力扣-相同的树
猜你喜欢

正则表达式,匹配中间的某一段字符串
Access Characteristics of Constructor under Inheritance Relationship
【C语言】详解栈和队列(定义、销毁、数据的操作)
Flink 1.15.1 集群搭建(StandaloneSession)
Pisanix v0.2.0 released | Added support for dynamic read-write separation

HOG特征学习笔记
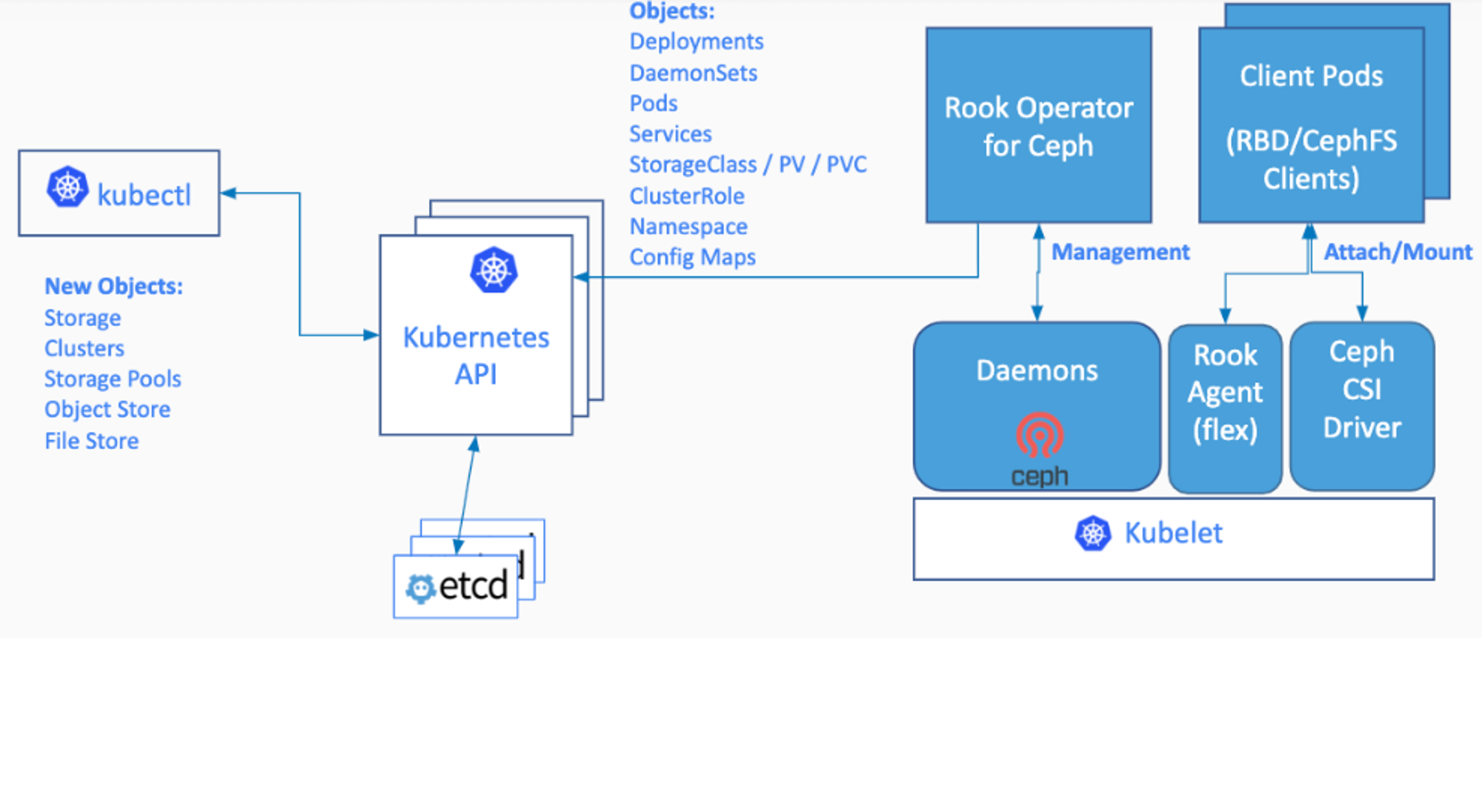
云原生(三十二) | Kubernetes篇之平台存储系统介绍
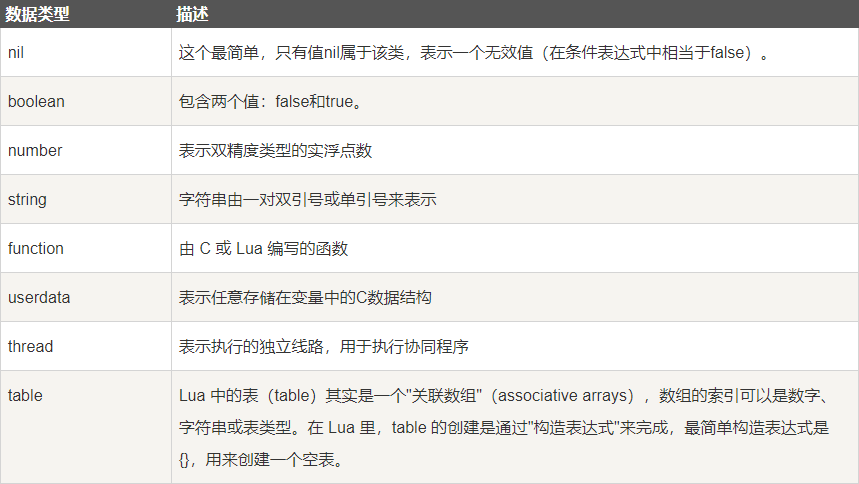
lua学习
Using OpenVINO to implement the flying paddle version of the PGNet inference program
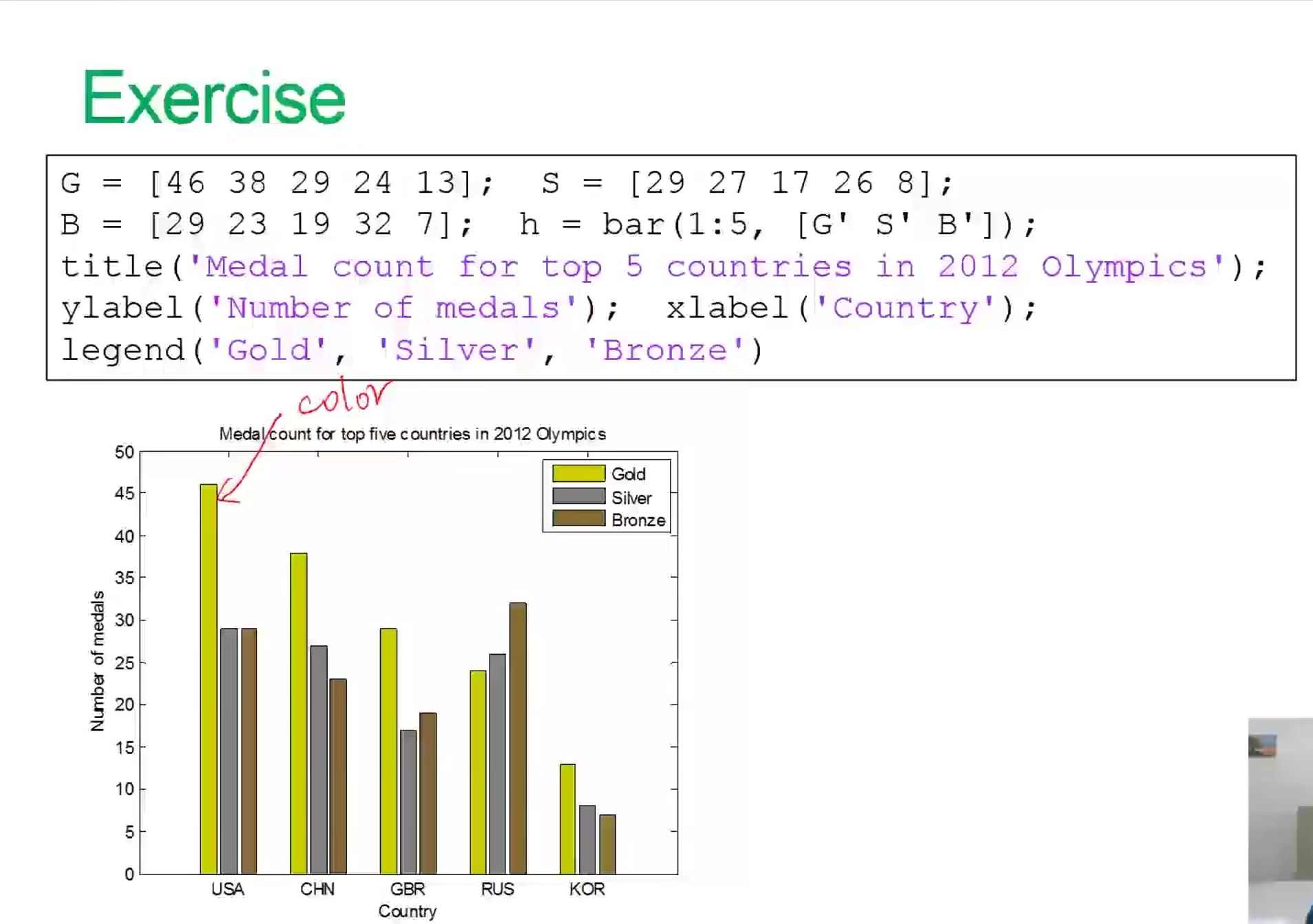
Matlab画图3
随机推荐
力扣-二叉树的前序遍历、中序遍历、后序遍历
注意潍坊开具发票一般需要注意
HOG feature study notes
LPQ (local phase quantization) study notes
leetcode 15
如何看待自己的羞愧感
Tree search (bintree)
nodeJs--encapsulate routing
View handler stepping record
VSCode Change Default Terminal how to modify the Default Terminal VSCode
.Net C# Console Create a window using Win32 API
网络安全与元宇宙:找出薄弱环节
力扣-二叉树的最大的深度
常见的硬件延迟
程序员失眠时的数羊列表 | 每日趣闻
Images using redis cache Linux master-slave synchronization server hard drive full of moved to the new directory which points to be modified
转:查尔斯·汉迪:你是谁,比你做什么更重要
Pisanix v0.2.0 发布|新增动态读写分离支持
js中try...catch和finally的用法
[ROS](10)ROS通信 —— 服务(Service)通信