当前位置:网站首页>[azure data platform] ETL tool (2) -- azure data factory "copy data" tool (cloud copy)
[azure data platform] ETL tool (2) -- azure data factory "copy data" tool (cloud copy)
2022-06-13 03:22:00 【Hair dung coating wall】
This paper belongs to 【Azure Data Platform】 series .
Continued above :【Azure Data Platform】ETL Tools (1)——Azure Data Factory brief introduction
This article demonstrates how to use ADF from Azure Blob Storage Copy data to Azure SQL DB.
In the last article , We have created ADF service , Here is a demonstration of the simplest ADF operation , except ADF Out of service , This article will create a Azure Blob Storage and Azure SQL Database As a demonstration of data transmission .
stay ADF in , There is one “ Copy the data ” Tools , With this tool , You can put them in different places ( Local or cloud ) To realize data transmission in different data sources . Basically support all the regular data sources you can think of , The specific list shall be subject to here :Supported data stores and formats.
Here we introduce a concept :Integration Runtime (IR), Integration runtime .
ADF The current support 3 class IR:
- Azure Integration Runtime: It mainly involves public network access .
- Self-Hosted Integration Runtime: It is used to access the local data source of the source or target table .
- Azure SSIS Integration Runtime: Used to run the SSIS package .
ADF Use IR Safely run replication activities in different network environments . And select the closest available area as the data source . It can be understood as IR Set up replication activities (copy activity) And link services (Linked services) The bridge .
Environmental preparation
Here is a very common requirement , from Azure Blob Copy data to SQL DB. This is based on cloud environment (Azure) Internal data replication operations . So , Let's quickly create a Azure Blob Storage and SQL DB, If you can use the default, use the default .
establish Blob Storage
This series assumes that you have basically created Azure service , And because the budget is limited , Will try to choose low configuration services . establish Blob Storage As shown in the figure below :
establish SQL DB
Again, the cheapest configuration is selected here :

Be careful “ The Internet ” In the options page , The default is “ Cannot access ”, In order to make Blob Storage Be able to access DB, Choose here “ Public endpoint ” And then in “ Firewall rules ” Chinese vs “ allow Azure Services and resources access this server ” choice “ yes ”
After the resource is created , We can start the operation .
Operation demo
First, let's connect DB And create a test table “ADFLab”, As shown in the figure below :
Check if there is data in the table :
Then prepare a test file and upload it to Blob Storage On . This is a txt file , And with a comma “,” As a separator , You'll see in the back , The reason for using commas , This is because the tool for copying data is separated by commas by default , If you use other as the separator , Need extra configuration , The contents of the document are as follows :
Upload to Blob Storage Of container(adflab) in :
When you're ready , Begin ADF The development work of .
ADF Development
To use the copy data tool , First create Pipeline( The Conduit ), Is used to blob container Copy the file in to Azure SQL DB in .
step 1: Open the studio of the data factory :
step 2: Click on 【 newly build 】 And select 【 The Conduit 】:
step 3: Click new pipe (pipeline1), Put... In the picture below 【 Copy the data 】 Drag to the right margin , Note here that due to time , There is no good name for each step , In a formal setting , Each component must be named with a meaningful identifier .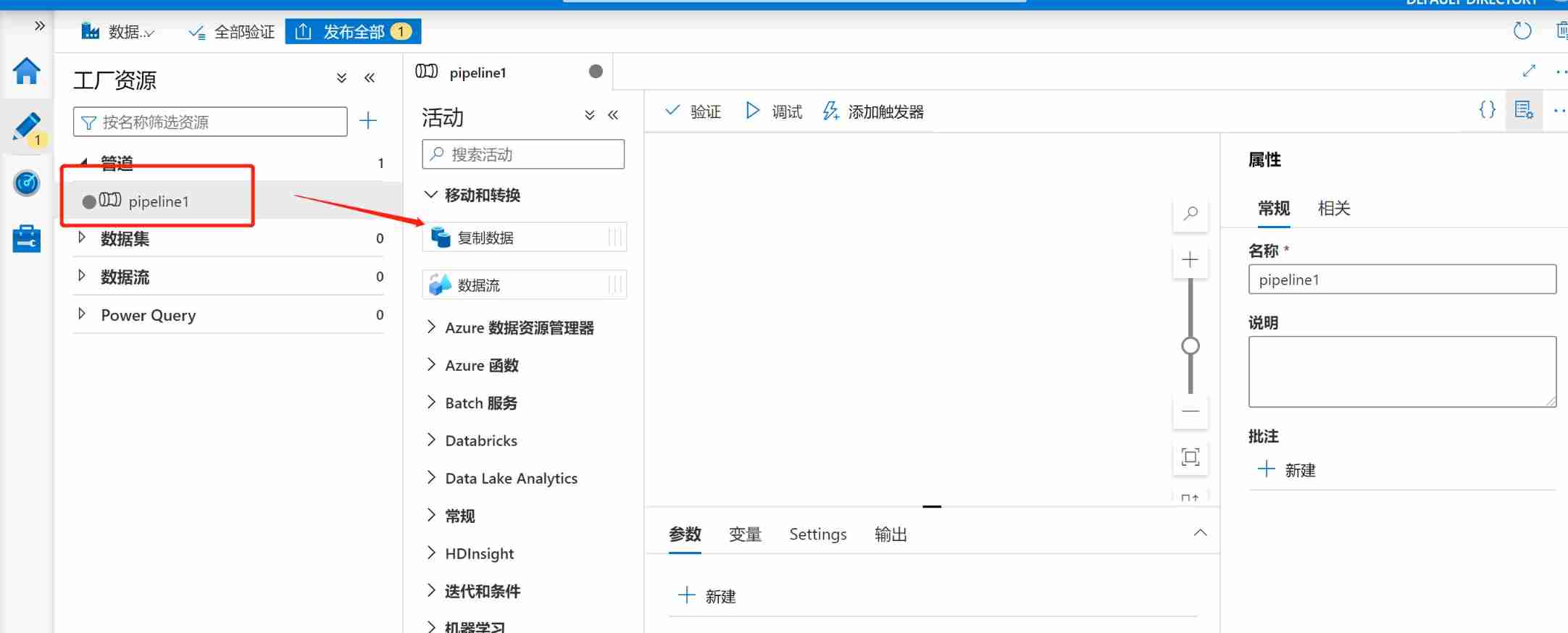
step 4: Configuration source , Click in the following order , choice Blob Storage As 【 Source 】:
step 5: Select the format type of the data , Because this time we use txt file , So choose DelimitedText, Then click on the bottom 【 continue 】:
step 6: Select or create a new linked service (linked service), Because of the new environment , So here's a new one :

step 7: Create a new link service and test the connection :
After passing the test , You can click the red box in the following figure to view the files inside the container in a graphical form :
We can see that there is a problem , It also means that the connection is successful , Select this file as the data source :
After configuring the source , Click on 【 Preview data 】, View the contents of the data , It can also be used as a verification process :
step 8: To configure 【 Receiver 】, That's the goal , As shown in the figure below , Select new and then select Azure SQL database :
step 9: Similar to the configuration source , Fill in the necessary information and click test link :

The following figure shows the configuration :
step 10: Configuration mapping , Mapping refers to how to parse files in the source ( Or other formats ) structure , In this case , Is to make ADF analysis Blob The process of setting up file structures and configuring database tables :
step 11: To configure 【 Set up 】, Just keep the default settings here for the time being :
step 12: To configure 【 User properties 】, Click on the user attribute 【 Automatic generation 】 You can load some attribute information , You can also add necessary information by yourself .
step 13: Then we verify and debug :
An error is reported during debugging , Viewing the information, you can find that the data type does not correspond well :
The error message is as follows :
Then look back at the configuration : The following figure was not checked , Check it out this time :
Click on 【 framework 】, And then click 【 Import schema 】, Refresh data source analysis results , You can see 【 Name 】 I have read it :
And then back to 【 mapping 】 in , Again 【 Import schema 】, Refresh structure , You can see that the source has also been updated :
Next, debug again , It turned out to be a success .
The last step is to release the program :
Then go back to the query results in the database , You can see that the database has been successfully imported :
up to now , Have already put one Blob Storage The simple file on is loaded into SQL DB in , The process is very simple , Very idealized , However, in enterprise use, various environmental requirements will bring a lot of additional configurations , Like authentication , Network connectivity, etc .
But as the first practical exercise for getting started , I think this level should be enough . From this practice , As ETL The entrant , Many details still need to be studied , practice , But you should not be discouraged just because you encounter various problems for the first time .
The next chapter will try to copy data from the local environment to the cloud . 【Azure Data Platform】ETL Tools (3)——Azure Data Factory Copy from local data source to Azure
边栏推荐
- Wechat applet switch style rewriting
- Level II C preparation -- basic concepts of program design
- Loading process of [JVM series 3] classes
- The most complete ongdb and neo4j resource portal in history
- Nuggets new oil: financial knowledge map data modeling and actual sharing
- Filters in PHP
- The use of curl in PHP
- English grammar_ Frequency adverb
- Detailed explanation of curl command
- MMAP usage in golang
猜你喜欢

Neo4j auradb free, the world's leading map database

This article takes you to learn DDD, basic introduction
![[JVM series 4] common JVM commands](/img/32/339bf8a2679ca37a285f345ab50f00.jpg)
[JVM series 4] common JVM commands

C # simple understanding - method overloading and rewriting
2-year experience summary to tell you how to do a good job in project management

C simple understanding - arrays and sets

Summary of virtualization technology development

Vs Code modify default terminal_ Modify the default terminal opened by vs Code

MySQL transaction isolation level experiment
![[JVM Series 5] performance testing tool](/img/94/b9a93fc21caacaf2a2e6421574de5c.jpg)
[JVM Series 5] performance testing tool
随机推荐
简述:分布式CAP理论和BASE理论
Vs 2022 new features_ What's new in visual studio2022
C method parameter: ref
Spark Foundation
Explode and implode in PHP
Brew tool - "fatal: could not resolve head to a revision" error resolution
[JVM Series 2] runtime data area
Using linked list to find set union
How to become a technological bull -- from the bull man
Rustup installation
Sparksql of spark
[JVM series 4] common JVM commands
Common command records of redis client
English语法_频率副词
English语法_方式副词-位置
【 enregistrement pytorch】 paramètre et tampon des variables pytorch. Self. Register Buffer (), self. Register Paramètre ()
C language function strcmp() (compare two strings)
DDL operation table
Use of interceptors webmvcconfigurer
Filters in PHP