当前位置:网站首页>决策树与随机森林
决策树与随机森林
2022-07-05 18:39:00 【Bayesian小孙】
决策树与随机森林
文章目录
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import tree # 导入决策树
from sklearn.datasets import load_iris # 导入datasets创建数组
一、知识概要(一)
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
信息熵: H = − ( p 1 l o g p 1 + p 2 l o g p 2 + . . . p 3 l o g p 3 ) H = -(p_1logp_1+p_2logp_2+...p_3logp_3) H=−(p1logp1+p2logp2+...p3logp3)
H称之为信息熵,单位为比特。
32支球队,log32=5比特;64支球队,log64=6比特
当这32支球队夺冠的几率相同时,对应的信息熵等于5比特
决策树的划分依据之一:信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,
即公式为: g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
二、决策树使用的算法
ID3—信息增益 最大的准则
C4.5—信息增益比 最大的准则
CART—回归树:平方误差 最小
分类树:基尼系数 最小的准则 在sklearn中可以选择划分的原则
三、sklearn决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
method:
decision_path:返回决策树的路径
四、决策树的案例
《泰坦尼克号乘客生存分类模型》
1、pd读取数据
2、选择有影响的特征,处理缺失值
3、进行特征工程,pd转换字典,特征抽取
x_train.to_dict(orient=“records”)
4、决策树估计器流程
titan= pd.read_csv('./Titanic_Data-master/train.csv')
PassengerId 乘客编号
Survived 是否幸存
Pclass 船票等级
Name 乘客姓名
Sex 乘客性别
SibSp 亲戚数量(兄妹、配偶数)
Parch 亲戚数量(父母、子女数)
Ticket 船票号码
Fare 船票价格
Cabin 船舱
Embarked 登录港口
print(titan.head(5))
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
print(titan.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
print(titan.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
1. 数据清洗
# 使用平均年龄来填充年龄中的 nan 值
titan['Age'].fillna(titan['Age'].mean(), inplace=True)
# 使用票价的均值填充票价中的 nan 值
titan['Fare'].fillna(titan['Fare'].mean(), inplace=True)
print(titan['Embarked'].value_counts())
# 使用登录最多的港口来填充登录港口的 nan 值
titan['Embarked'].fillna('S', inplace=True)
S 644
C 168
Q 77
Name: Embarked, dtype: int64
2. 特征工程
# 特征选择
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
x = titan[features] # train features
y= titan['Survived'] # train labels
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
dict=DictVectorizer(sparse=False) # one-hot编码(对于类别型变量)
# 进行特征工程,pd转换为字典,特征抽取x_train_dict(orient = "records")
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
x_test = dict.transform(x_test.to_dict(orient="records"))
print(dict.get_feature_names_out())
print("*"*50)
# 或者使用这个方法来查看特征名称
print(dict.feature_names_)
['Age' 'Embarked=C' 'Embarked=Q' 'Embarked=S' 'Fare' 'Parch' 'Pclass'
'Sex=female' 'Sex=male' 'SibSp']
**************************************************
['Age', 'Embarked=C', 'Embarked=Q', 'Embarked=S', 'Fare', 'Parch', 'Pclass', 'Sex=female', 'Sex=male', 'SibSp']
3. 调用决策树API
# 用决策树进行预测
dec = DecisionTreeClassifier()
j = dec.fit(x_train, y_train)
# 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
预测的准确率: 0.7847533632286996
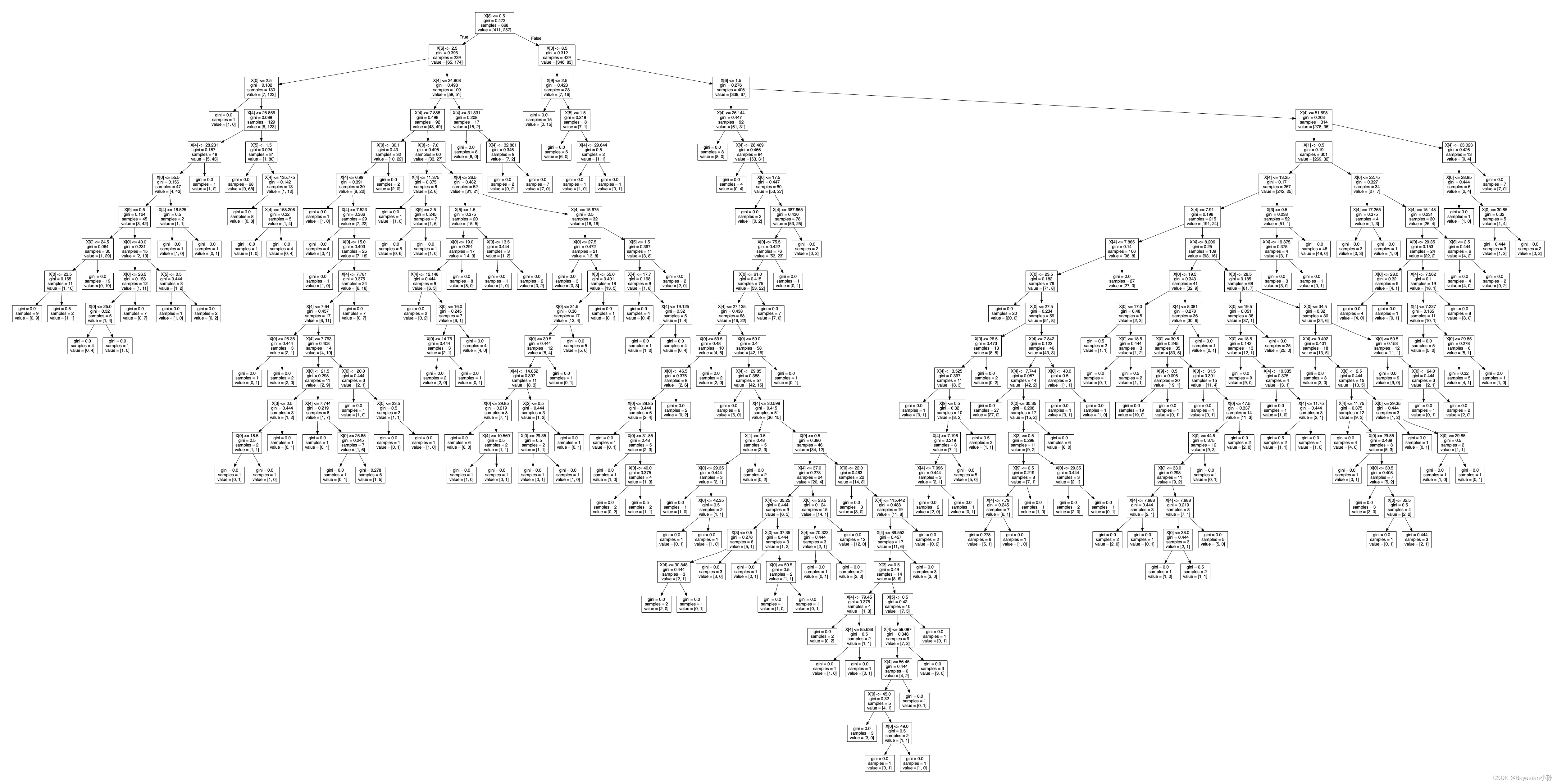
dot_data = tree.export_graphviz(j, out_file=None) # 以DOT格式导出决策树
graph = graphviz.Source(dot_data)
graph.render("./output_tree") # 使用garDphviDz将决策树转存PDF存放到当前文件夹目录下,文件名叫"output_tree"
'output_tree.pdf'
五、集成学习方法-随机森林
1. 知识概要(二)
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
学习算法:
根据下列算法而建造每棵树:
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
2. 集成学习API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’,
max_depth=None, bootstrap=True, random_state=None)
随机森林分类器
n_estimators:integer,optional(default = 10) 森林里的树木数量
criteria:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
3. 随机森林的案例
# 随机森林进行预测 (超参数调优)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1)
param = {
"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
# 网格搜索与交叉验证
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("准确率:", gc.score(x_test, y_test))
print("查看选择的参数模型:", gc.best_params_)
准确率: 0.8430493273542601
查看选择的参数模型: {'max_depth': 8, 'n_estimators': 120}
边栏推荐
- 中文版Postman?功能真心强大!
- 瞅一瞅JUC提供的限流工具Semaphore
- Reading notes of Clickhouse principle analysis and Application Practice (5)
- max31865模块RTD测温注意事项
- The road of enterprise digital transformation starts from here
- EMQX 5.0 正式发布:单集群支持 1 亿 MQTT 连接
- Powerful tool for collection processing
- Exemple Quelle est la relation entre le taux d'échantillonnage, l'échantillon et la durée?
- Isprs2020/ cloud detection: transferring deep learning models for cloud detection between landsat-8 and proba-v
- 7-1 linked list is also simple fina
猜你喜欢

The era of Web3.0 is coming. See how Tianyi cloud storage resources revitalize the system to enable new infrastructure (Part 2)
AI表现越差,获得奖金越高?纽约大学博士拿出百万重金,悬赏让大模型表现差劲的任务
Various pits of vs2017 QT
5. 数据访问 - EntityFramework集成
Mysql database indexing tutorial (super detailed)
FCN: Fully Convolutional Networks for Semantic Segmentation
Reading notes of Clickhouse principle analysis and Application Practice (5)
websocket 工具的使用
SAP 特征 特性 说明
![2022 latest intermediate and advanced Android interview questions, [principle + practice + Video + source code]](/img/c9/f4ab4578029cf043155a5811a64489.png)
2022 latest intermediate and advanced Android interview questions, [principle + practice + Video + source code]
随机推荐
Windows Oracle 开启远程连接 Windows Server Oracle 开启远程连接
R language uses lubridate package to process date and time data
Linear table - abstract data type
Insufficient picture data? I made a free image enhancement software
SAP 特征 特性 说明
Isprs2022/ cloud detection: cloud detection with boundary nets
The era of Web3.0 is coming. See how Tianyi cloud storage resources revitalize the system to enable new infrastructure (Part 2)
Precautions for RTD temperature measurement of max31865 module
IDEA配置npm启动
2022最新中高级Android面试题目,【原理+实战+视频+源码】
SAP feature description
Simple query cost estimation
瞅一瞅JUC提供的限流工具Semaphore
MYSQL中 find_in_set() 函数用法详解
Common time complexity
RPC协议详解
Idea configuring NPM startup
c语言简便实现链表增删改查「建议收藏」
Word查找红色文字 Word查找颜色字体 Word查找突出格式文本
7-1 linked list is also simple fina