当前位置:网站首页>FCN: Fully Convolutional Networks for Semantic Segmentation
FCN: Fully Convolutional Networks for Semantic Segmentation
2022-07-05 18:23:00 【00000cj】
paper: Fully Convolutional Networks for Semantic Segmentation
Innovation points
The structure of full convolution is proposed , That is, the last full connection layer of the classified network is replaced by the convolution layer , Thus, the input of any size can be processed .
Up sampling by deconvolution or interpolation , Restore the output back to the original input size .
Modify on the classification network , Replace the full connection layer with the convolution layer , You can share the weight of the previous layer , So as to carry out finetune.
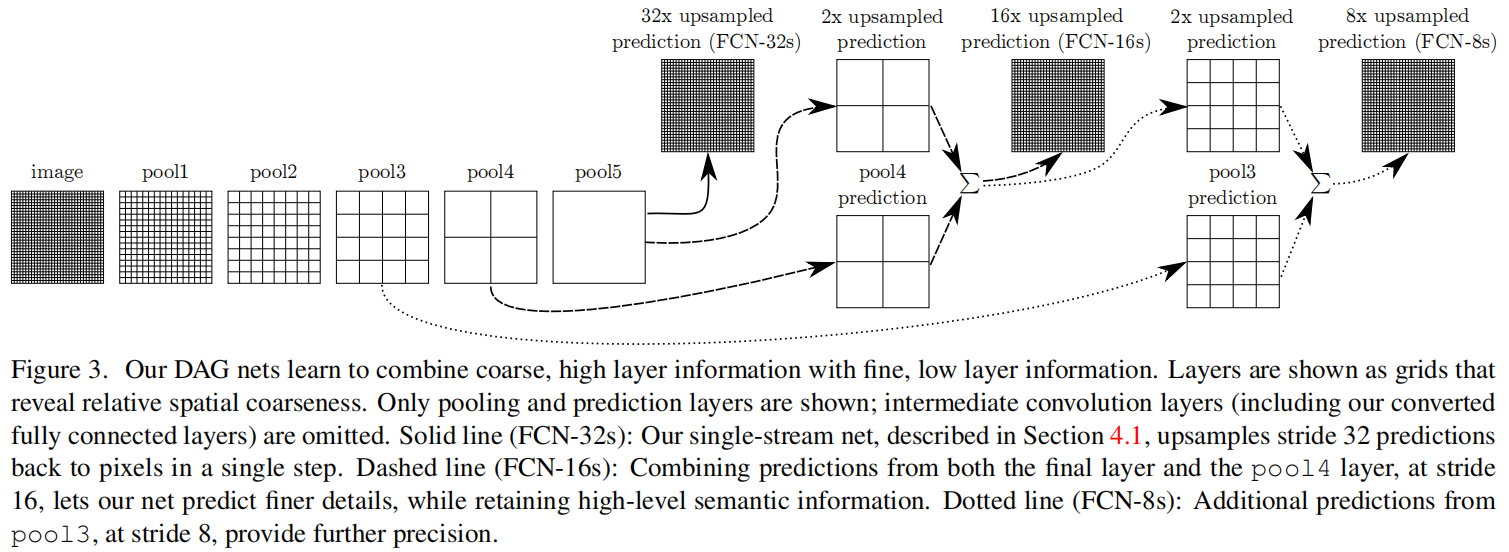
Put forward skip structure , By combining shallow and deep features , It takes into account the shallow spatial details and deep semantic information , Make the final segmentation result more refined .

Implementation details analysis
Here we use MMSegmentation As an example , Compared with the original paper ,backbone from Vgg-16 Instead of ResNet-50,skip The structure is replaced by expansion convolution ,pytorch The official implementation is also like this .
Backbone
- The original ResNet-50 in 4 individual stage Of strides=(1, 2, 2, 2), Do not use expansion convolution, that is dilations=(1, 1, 1, 1), And in the FCN in 4 individual stage Of strides=(1, 2, 1, 1),dilations=(1, 1, 2, 4).
- There's another one contract_dilation=True Set up , That is, when the hole >1 when , Compress the first convolution . Here are the third and fourth stage One of the first bottleneck Halve the expansion rate , The third stage One of the first bottleneck Expansion convolution is not used in , The fourth one stage One of the first bottleneck in dilation=4/2=2.
- In addition, here we use ResNetV1c, namely stem Medium 7x7 Convolution is replaced by 3 individual 3x3 Convolution .
- Last , Pay attention to the padding, In the original implementation, except stem in 7x7 Convolution padding=3, Everything else padding=1. stay FCN Because of the expansion convolution , The latter two stage Of stride=1, In order to keep the input and output resolution always , From the following formula padding=dilation.

- hypothesis batch_size=4, Model input shape=(4, 3, 480, 480), be backbone four stage The outputs of are (4, 256, 120, 120)、(4, 512, 60, 60)、(4, 1024, 60, 60)、(4, 2048, 60, 60).
FCN Head
- take ResNet The fourth one stage Output (4, 2048, 60, 60), after Conv2d(2048, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)、Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Two conv-bn-relu obtain (4, 512, 60, 60).
- The output of the previous step (4, 512, 60, 60) With the input (4, 2048, 60, 60) Spliced to get (4, 2560, 60, 60).
- Through a conv-bn-relu,Conv2d(2560, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False), obtain (4, 512, 60, 60).
- use dropout,dropout_ratio=0.1.
- Last , after Conv2d(512, num_classes, kernel_size=(1, 1), stride=(1, 1)) Get the final output of the model (4, num_classes, 60, 60), Note that the number of categories here includes the background .
Loss
- The output of the previous step (4, 2, 60, 60) After bilinear interpolation resize Input size , obtain (4, 2, 480, 480).
- use CrossEntropy loss
Auxiliary Head
- take ResNet Third stage Output (4, 1024, 60, 60), after Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) One conv-bn-relu obtain (4, 256, 60, 60).
- use dropout,dropout_ratio=0.1.
- after Conv2d(256, num_classes, kernel_size=(1, 1), stride=(1, 1)) Get the final output of the model (4, num_classes, 60, 60) Get the output of this branch .
边栏推荐
猜你喜欢
Trust counts the number of occurrences of words in the file
Nacos distributed transactions Seata * * install JDK on Linux, mysql5.7 start Nacos configure ideal call interface coordination (nanny level detail tutorial)

LeetCode 6111. 螺旋矩阵 IV
FCN: Fully Convolutional Networks for Semantic Segmentation

小林coding的内存管理章节
About Estimation with Cross-Validation

Star ring technology data security management platform defender heavy release
Tupu software digital twin | visual management system based on BIM Technology
rust统计文件中单词出现的次数
Memory management chapter of Kobayashi coding
随机推荐
The 11th China cloud computing standards and Applications Conference | cloud computing national standards and white paper series release, and Huayun data fully participated in the preparation
【PaddleClas】常用命令
JVM第三话 -- JVM性能调优实战和高频面试题记录
GIMP 2.10教程「建议收藏」
【HCIA-cloud】【1】云计算的定义、什么是云计算、云计算的架构与技术说明、华为云计算产品、华为内存DDR配置工具说明
最大人工岛[如何让一个连通分量的所有节点都记录总节点数?+给连通分量编号]
How can cluster deployment solve the needs of massive video access and large concurrency?
小林coding的内存管理章节
个人对卷积神经网络的理解
@Extension、@SPI注解原理
从类生成XML架构
Crontab 日志:如何记录我的 Cron 脚本的输出
Image classification, just look at me!
JDBC reads a large amount of data, resulting in memory overflow
Generate XML schema from class
[paddlepaddle] paddedetection face recognition custom data set
Record a case of using WinDbg to analyze memory "leakage"
sample_rate(采樣率),sample(采樣),duration(時長)是什麼關系
Thoroughly understand why network i/o is blocked?
南京大学:新时代数字化人才培养方案探讨