当前位置:网站首页>Isprs2020/ cloud detection: transferring deep learning models for cloud detection between landsat-8 and proba-v
Isprs2020/ cloud detection: transferring deep learning models for cloud detection between landsat-8 and proba-v
2022-07-05 18:37:00 【HheeFish】
ISPRS2020/ Cloud detection :Transferring deep learning models for cloud detection between Landsat-8 and Proba-V stay Landsat-8 and Proba-V Inter transfer cloud detection deep learning model
0. Abstract
Accurate cloud detection algorithm is a necessary condition for analyzing large data streams from different optical Earth Observation Satellites . Based on deep learning (DL) Our cloud detection scheme provides a very accurate cloud detection model . However , Training these models for a given sensor requires a large number of manually labeled sample data sets , It's very expensive , It's not even possible to create it before the satellite is launched . In this work , We propose a way , Use a satellite's manually labeled data set to train the deep learning model , For cloud detection , Can be applied ( Or transfer ) To other satellites . Considering the physical properties of the acquired signal , We propose a simple method of transfer learning , Use Landsat-8 and Proba-V sensor , Their images have different but similar spatial and spectral features .
This paper proves the two-way effect of transfer learning through three types of experiments :(a) from Landsat-8 To Proba-V, In which we show , Use only Landsat-8 The cloud mask generated by the data training model is larger than that of the current operation Proba-V Cloud mask method is more accurate 5 spot ;(b) from Proba-V To Landsat8, Only... Is used Proba-V The data training model has a similar publicly available Biome Operations in data sets FMask The accuracy of the (87.79-89.77% vs 88.48%), And from Proba-V and Landsat-8 Unite to ProbaV, We prove , Use these two data sources together , When there are few Proba-V When the marked image is available , Improved accuracy 1-10 spot . These results highlight , Utilize existing publicly available cloud mask tag datasets , We can create an accurate cloud detection model based on deep learning for new satellites , But there is no need to collect and tag a large number of image data sets .
1. summary
The number of new satellites and sensors aimed at monitoring the earth system and understanding its dynamics has increased exponentially . Among these sensors , Optical instruments measure the visible and infrared radiation of the electromagnetic spectrum from the earth . Data from optical sensors are used in a wide range of applications , Such as estimating biophysical parameters , Monitor the long-term use of land , Assess the damage after natural disasters , Or monitoring urban areas . In most of these applications , The presence of clouds and their shadows will affect the signal , And is considered a source of uncertainty (Gómez-Chova et al., 2007). However , In a single scene , Cloud shielding can be handled manually , In an operation application that utilizes image time series or multiple locations , It's not feasible . therefore , In order to automatically process images from optical sensors , Accurate and automatic cloud masking algorithm is necessary .
Cloud masking algorithm assigns a clear or fuzzy binary label to each pixel in the satellite image . The most basic method of cloud masking is the so-called threshold based method , It includes a set of thresholds , One or more spectral bands applied to an image , Or used to extract features that try to enhance the physical properties of the cloud . Generally speaking , The threshold method is simple and easy , When the spectral information provided by the satellite is rich enough , Threshold method is effective in cloud resolution . Current cloud masking methods based on operational thresholds include FMask (Zhu and Woodcock, 2012;Zhu et al., 2015) be used for Landsat-7 and Landsat-8, Sen2Cor (Richter et al., 2012) be used for Sentinel-2, And several recent works to improve them ( for example Zhai et al., 2018; Qiu et al ,2019;Frantz wait forsomeone ,2018). On the other hand , Based on machine learning (ML) The method deals with cloud detection as a statistical classification problem . These methods learn cloud detection models based on a set of examples : Observation data pairs and labels . When the quality of training data is good enough , The method based on machine learning is better than the method based on threshold (GómezChova etc. ,2007;Li wait forsomeone ,2019;Jeppesen wait forsomeone ,2019 year ). Machine learning methods for cloud detection can be further divided into classical learning methods and deep learning methods . The classical method is to extract a set of manually selected spatial and spectral features for each pixel in the training set , Then optimize the classifier , The labels of these pixels are distinguished according to these features . In the simplest case , Only two classes are considered : Clouds and clear pixels ; However , Some works consider a wider range , Including cirrus 、 Cloud shadow 、 ice / snow 、 Water, etc (Hollstein wait forsomeone ,2016; Hughes and Hayes ,2014;Wieland wait forsomeone ,2019 year ). Classical machine learning methods are usually pixelated , In this sense , The trained classifier can be independently applied to each pixel in the test image after feature extraction . These methods use different classifiers , Include : Kernel method and support vector machine (Azimi and Zekavat, 2000;Bai wait forsomeone ,2016; Ishida et al ,2018;Gómez-Chova etc. ,2010), neural network (Torres Arriaza etc. ,2003;Hughes and Hayes, 2014) Or tree and set methods (Ghosh wait forsomeone ,2006;Hollstein wait forsomeone ,2016;2018 year ,Ghasemian and Akhoondzadeh;Wieland wait forsomeone ,2019 year ). On the other hand , The deep learning method for cloud mask is end-to-end model , The input is the original image , The output is a cloud mask . If the model is defined as a set of stacked convolution operations , Then it constitutes a complete convolutional neural network (FCNN) (Long et al., 2015). In these models , The weight of convolution filter is the parameter that needs to be optimized , Therefore, the model can learn to use the spatial information of surrounding pixels directly from the data . Applied to cloud detection FCNNs It has shown the most advanced performance for several satellites , Such as Landsat-7 (Li wait forsomeone ,2019 year )、Landsat-8 (Jeppesen wait forsomeone ,2019 year ;Li et al., 2019)、 High marks 1 (Li et al., 2019) or MSG SEVIRI (Drönner et al., 2018).
Independent of the selected cloud shielding method , This method must be verified . For most satellite sensors , This is the bottleneck of cloud masking algorithm development , Because usually there is no independent and simultaneous information about the existence of cloud in the image . therefore , For quantitative verification , The standard method is to manually mark a group of pixels or images by human experts , These pixels or images will constitute the true value of the ground . This method has been widely used in the literature , Such as Landsat7 (Irish wait forsomeone ,2006 year )、Envisat/MERIS (Gómez-Chova wait forsomeone ,2007 year )、landsat8 (Foga wait forsomeone ,2017 year )、Proba-V (Iannone wait forsomeone ,2017 year ) or Sentinel-2 (Coluzzi wait forsomeone ,2018 year ;Baetens wait forsomeone ,2019 year ). In some cases , Only some pixels in the image are marked as cloudy or cloudless , And in other cases , All pixels in the image are marked , It also captures the spatial distribution of clouds . In either case , This process cannot avoid mistakes : for example , stay Scaramuzza wait forsomeone (2012) in , The author reports three completely labeled by different experts 11 individual Landsat-7 The average overall error of the scene is 7%. Marking pixels individually is more accurate , But it needs higher dedication , Therefore, the total number of marked pixels is usually quite low . This makes the results less statistically significant , When our goal is to verify globally effective cloud detection algorithms in different seasons and climatic conditions , This could be a problem .
Besides , If the cloud detection method proposed in this paper is based on machine learning , In addition to verifying the data , We also need a group of independent 、 Comprehensive labeled samples to train the model . If the goal is to provide an accurate global cloud detection method , Then this training set should be sufficiently representative of natural statistics , Including from different land cover 、 Data on climatic zones and seasons . therefore , For machine learning methods , Efforts to generate ground truth and develop cloud detection algorithms are enormous . Another disadvantage of machine learning methods is , Before satellite launch and data availability , They cannot be applied , Because the development model needs a comprehensive image archive with the corresponding ground reality . For these reasons , It is still very common for most satellite missions to use empirically designed threshold based cloud detection methods when launching . after , If there is an operational cloud detection performance problem , Replace the original algorithm with an improved algorithm based on data acquisition during the task life cycle . This is it. Proba-V Mission (Sterckx et al., 2014) The situation of , under these circumstances , European space agency (ESA) Recently, a cloud detection round robin experiment was organized (Iannone et al., 2017), It aims to compare different cloud detection algorithms , To improve the current operation algorithm (Wolters et al., 2015)
Considering the above , We can come to a conclusion , For specific satellite sensors , The lack of accurate and representative ground truth will hinder the development of accurate machine learning models . However , The amount of earth observation data available today is huge , Publishing algorithms and manually tagged cloud mask datasets are becoming more and more common , This is a good practice to promote research in the field of remote sensing . Especially for cloud detection , stay Foga wait forsomeone (2017) in , The author has published more than 250 picture Landsat-7 and Landsat-8 Scene ; stay Mohajerani and Saeedi(2019 year ), They released Landsat-8 Extra 38 A scenario ; works (Li et al., 2017, 2019) Respectively published 108 Zhang Gaofen 1 No. image and 150 A high-resolution scene from Google Earth ; And works (Hollstein et al., 2016;Liu wait forsomeone ,2019;Baetens wait forsomeone ,2019 year ) Also released the sentinel -2 Manual tag cloud mask . under these circumstances , We recommend taking advantage of the wealth of information contained in existing tag datasets , Transfer previous knowledge about the problem between similar satellites . This approach allows us to address some of the shortcomings of machine learning methods . First , From the perspective of methodology , The size of the manually labeled training set required to establish an accurate cloud detection model for the new satellite is greatly reduced . secondly , From an operational point of view , Since the training data of existing satellites are available , So we can develop cloud detection algorithm based on machine learning before satellite launch , Therefore, it can be applied from the first day .
This article takes The spatial resolution is different 、 Spectral bands are different Proba-V Satellites and Landsat-8 Satellite is the research object , The model is trained and evaluated using manually labeled cloud detection data sets .Proba-V It is a small satellite with medium spatial resolution , Only 4 A spectral band (Sterckx et al., 2014); We will take advantage of the recent ESA Round Robin In the experiment, manually labeled data sets are used for cloud detection (Iannone et al., 2017). And Proba-V comparison ,Landsat-8 (Irons et al., 2012) With higher spatial and spectral resolution , And as mentioned earlier , There are a large number of manually labeled cloud detection image sets ( U.S. Geological Survey ,2016a,b).
What we proposed Landsat-8 and Proba-V The knowledge transfer method between is based on two parts . The first one is right Lansdsat-8 Domain adaptation transformation of data , Make it in spectral and spatial characteristics with Proba-V Image similarity . Our goal is to simply Physics based transformation , To facilitate the manual marking of datasets from available ( That is, the source domain ) To the satellite images we want to detect clouds ( The target domain ) Transfer learning . The second part is a neural network model of complete convolution , can Learn as much spectral and spatial information as possible from the training data .FCNNs Good at image segmentation tasks (Xie wait forsomeone ,2017;Chen etc. ,2018a,b; Lin et al ,2018;Drozdzal wait forsomeone ,2016;Breininger wait forsomeone ,2018;Schuegraf and Bittner, 2019), They integrate spectral information and spatial information in a hierarchical way : In our view , Spatial information is especially in Proba-V It's crucial in the context of , It has a limited number of spectral bands .
Use domain adaptation transformation and FCNN Model , We conducted three types of transfer learning experiments :(a) from Landsat-8 To Proba-V Transduction transfer learning , We only use Landsat-8 Annotate data to develop an in Proba-V The model of domain work ;(b) from Proba-V To Landsat-8 Transduction transfer learning , Marked Proba-V Data is used for training Landsat-8 Cloud detection model ; from Landsat-8 To Proba-V Inductive transfer learning , Among them, we use a small amount Proba-V Marked image and annotated Landsat-8 Data sets are generated together Proba-V Cloud detection model .
In these experiments , We show the proposed model Only in Landsat-8 data ( Previous projects a) Training , Its accuracy is at least better than the current Proba-V The operation cloud detection algorithm is higher than 5 A little bit (Wolters wait forsomeone ,2015). This model does not use any Proba-V Image training . In a more challenging Proba-V towards Landsat-8 Shifting direction , Use only Proba-V data ( the aforesaid b) Training model , It works at low 10 Times the spatial resolution scale , Only better than the most advanced Landsat-8 The accuracy of deep learning model is low 2 spot (Jeppesen wait forsomeone ,2019;Li wait forsomeone ,2019 year ), On the analyzed data set , It is related to operable FMask (Zhu and Woodcock, 2012 year ) Same accuracy . Last , Performance of the model using labeled data from two sensors ( The previous one c) indicate , Use only a small amount Proba-V The accuracy of the image training model is significantly lower than that of these few Proba-V Images and available Landsat-8 Data joint training model . Specially , Results show , When using two data sources to jointly train the network , According to the Proba-V Data volume , The detection accuracy is improved 1 To 10 A little bit .
The organizational structure of this paper is as follows . In the 2 In the festival , We have constructed our proposal in the context of the current literature , And introduced our contribution in detail . In the 3 In the festival , We introduced Physics based image conversion scheme , This scheme is conducive to the migration and learning between sensors 、 The transfer learning scheme and the proposed network architecture . In the 4 In the festival , We showed Landsat-8 and Proba-V Data sets . The first 5 Section is experimental design , Describe the transfer learning experiment in detail . In the 6 In the festival , The results are shown and discussed . Last , The first 7 Section gives a conclusion .
2. Method
In this section , Let's start with Proba-V and Landsat-8 Characteristics of . then , We propose two kinds of transfer learning (TL) programme : The first will be used to learn from Landsat-8 Migrate to Proba-V, The second will learn from Proba-V Migrate to Landsat-8. these TL The plan specifies how to train and test in the source and target areas respectively . According to whether the domain adaptation is from the source domain to the target domain or the reverse , Each scheme can be applied to different situations . then , We will introduce in detail the two TL The domain adaptation transformation used in the experiment of the scheme . The conversion is based on the instrument characteristics of the sensor , Adapt to Landsat-8 Graphic Proba-V Domain . Last , The first 3.4 Section explains the complete convolutional neural network architecture used in the experiment . In this paper , Our main concern is Landsat-8 and Proba-V The situation of , However , This process of transfer learning can be reproduced in other sensors with similar characteristics , Because we only need two sensors with some spectral bands with overlapping responses .
2.1.Landsat-8 and Proba-V sensor
Proba-V It is a small satellite for global vegetation monitoring (Sterckx et al., 2014). It's on 2013 launch , To bridge Envisat/MERIS、SPOT Vegetation and recently launched Sentinel-3 The gap between .Proba-V It is an experimental satellite with a limited budget , Its design scale is larger than that before MERIS and SPOT Much smaller . It gets visible light (BLUE and RED)、 The near infrared (NIR) And short wave infrared (SWIR) The top of the atmosphere in four bands (TOA) Radiance .Proba-V There are three cameras : A central camera , Point to the lowest point , The other two are on the side . These three cameras are Proba-V Provides a wide viewing distance , Can achieve 1-2 A short revisit cycle of days . The central ( The lowest point ) The camera in 100 rice ( from 90 To 110 rice ) get data , The spatial resolution range of cameras on both sides ranges from 110 M to 350 rice .2A Level operation processing utilization Lanczos Interpolate these data with different resolutions Project into a unified 333 rice plate Carrée Projection (Dierckx wait forsomeone ,2014). Due to the limited spectrum information ,Proba-V Cloud detection in is particularly challenging . Currently running threshold based Proba-V Cloud detection algorithm (Wolters et al., 2015) Modified many times , There are still some flaws , Such as dependence on illumination and observation geometry 、 Edge detection and a large number of debugging errors (Stelzer et al., 2016)
Landsat-8 (Irons et al., 2012) With 15 The diplopia period of days measures the electromagnetic spectrum 11 A band of TOA radiation .Landsat-8 There are two sensors : Business land imager (OLI), from 9 Spectral bands in 30 Meter resolution collecting data ; The target of thermal infrared sensor is thermal imaging , It can be 100 Measure the data of the other two wavelengths within the spatial resolution range of meters . And Proba-V comparison , There are two factors that make Landsat-8 Cloud detection is easier to solve . First ,OLI Sensors 9 The band is specially designed for detecting cirrus clouds . secondly , The tropics are particularly discriminating against clouds , Because some clouds are obviously colder than the underlying surface .FMask And so on (Zhu wait forsomeone ,2015) Using these facts, a simple and robust threshold based cloud detection algorithm is designed , Can be applied worldwide .
2.2. Transfer learning strategies
As we mentioned in the first 2 As discussed in section , Transfer learning includes using information from a ( Source ) Domain data to solve similar but different ( The goal is ) Problems in the field . however , According to the relationship between the source domain and the target domain , perform TL There are different possibilities . In this study , We considered two different TL programme . These scenarios assume that we are already in the source domain (S) Marked with data , We want to be in the target domain (T) To make predictions , And domain adaptation transformation can be applied between two domains (DA). each TL The applicability of the scheme depends on the direction of domain adaptation transformation :
- programme 1: Training model in target domain . In this case , We have a domain adaptation transformation from the source domain to the target domain . Let's start with the domain Adaptive transformation adapts the labeled data from the source domain to the target domain , Then use the adaptive data training model . Since both images and labels are converted to the target domain to train the model , Therefore, it is very simple to apply the learned model to the data in the target field ( Because the model has been built in this field ). On the other hand , If we want to test the model in the source domain , We need to convert the source domain input to the target domain , Apply the prediction model , And convert the prediction back to the source domain .
- programme 2: Train the model in the source domain . The scheme is based on training the model directly in the source domain . In the scheme , We perform a domain adaptation transformation from the target domain to the source domain . In order to apply the model to the new data of the target domain , You must first apply the input sample to the source domain , Then apply the prediction model , Finally, convert the prediction back to the target field . Be careful , under these circumstances , Testing the model on data from the source domain is straightforward .
In this study , We will use Scheme 1 Conduct Landsat-8 To Proba-V Migration study , Use Scheme 2 Reverse transfer learning . The scheme is summarized in the figure 1 Shown . Specially , In this work ,X It's a satellite image ( Whether it's Landsat or Proba-V);Y Is the cloud mask tag ;DAX From Landsat-8 Image to Proba-V( chapter 3.3) To adapt to ;DAY Is to adjust the label by increasing or decreasing the mask ( The first 3.3 section );f For the prediction model ,Y=f(X), Using a fully convoluted neural network ( The first 3.4 section ) Realization . Besides , chart 1 Explain the data conversion of the training model , And the process of testing them in the data set from the target domain or source domain .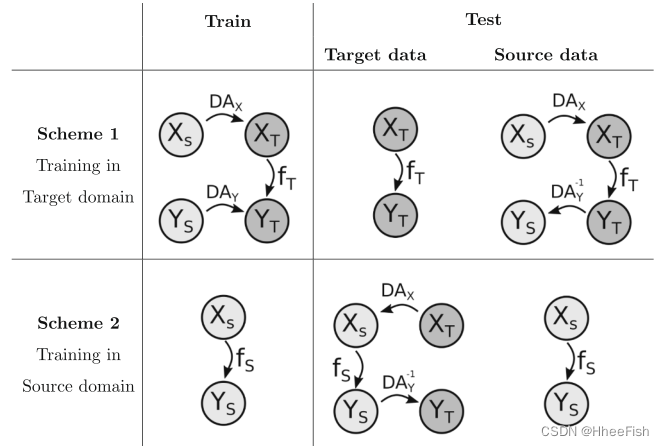
chart 1 Shown . Transfer learning plan . In both cases , We all assume that the source (S) There is tag data in the field , But we hope in the goal (T) Make predictions in the domain . Images X And labels Y The adaptations of DAX and DAY Transform to execute . After training ML The models use fT or fS Express , It depends on whether it trains in the source domain or the target domain .
2.3.Landsat-8 to Proba-V Domain adaptation
In order to apply TL programme ( The first 3.2 section ), We need a program to adjust the image from one domain to another ( chart 1 Medium DAX). Although there are a lot of ways to learn adaptive domain transformation from data ( for example ,Tuia wait forsomeone ,2014 year ;Hoffman wait forsomeone ,2018 year ;Csurka,2017 year ), But in this article , The method we adopt is only based on the physical characteristics of the collected signal . Learning transformation means getting data from two sensors to train the model , In some cases, it may not be feasible ( for example , If our target satellite has not been launched ). therefore , Several parts of this study assume that there is no data from the target domain ( Or very little ). When the learning field can adapt to the transformation , This simpler method can be used as a baseline for comparing such methods . When the collected signals in two domains When there is spectrum overlap , The transformation we proposed can usually be applied . In our special circumstances , These fields are Proba-V and Landsat-8 satellite image . Adapt the transformation in two possible domains ( from Landsat-8 To Proba-V Or from Proba-V To Landsat-8) in , Whereas Landsat-8 and Proba-V The characteristics of the image , from Landsat-8 To Proba-V The transformation of seems more natural , Because it comes from Higher spatial and spectral resolution to lower spatial and spectral resolution . The opposite transformation is also possible ; However , from Proba-V The image is interpolated to 30 Meter spatial resolution is an ill posed problem , Interpolated images are unlikely to have Landsat -8 Spatial spectral quality of image . therefore , In all papers , We will only consider from Landsat-8 To Proba-V Domain adaptation , To transform TOA Reflection image .
We propose from Landsat 8 To Proba-V Image conversion for ( chart 3) Based on the instrument characteristics of two sensors . The transformation includes two adaptation steps : First , Choose a more appropriate spectral band , secondly , We zoom Landsat-8 Image to match Proba-V Spatial properties of . Spectral conversion takes into account the spectral response functions of the two satellites (SRF). It basically includes selecting the overlapping spectral bands between two satellites , Finally, its contribution is weighted as a function of its spectral overlap . chart 2( Left ) Shows Proba-V( Solid ) and Landsat-8( Dotted line ) Spectral response function of common bands in . stay SWIR Good consistency can be seen in the case of band and red band . In the case of near-infrared band ,Proba-V Wider spectral response of , Its peak value is similar to Landsat-8 B5 Band inconsistency , This may result in retrieved radiation differences . Last , about Proba-V Blue band , In the same spectral range , Landsat -8 There are two bands . under these circumstances ,Landsat-8 Of B1 and B2 The contribution of the band is weighted according to the overlapping area of the spectral response , Pictured 2( Right ) Shown , It corresponds to B1 Of 25% and B2 Of 75%.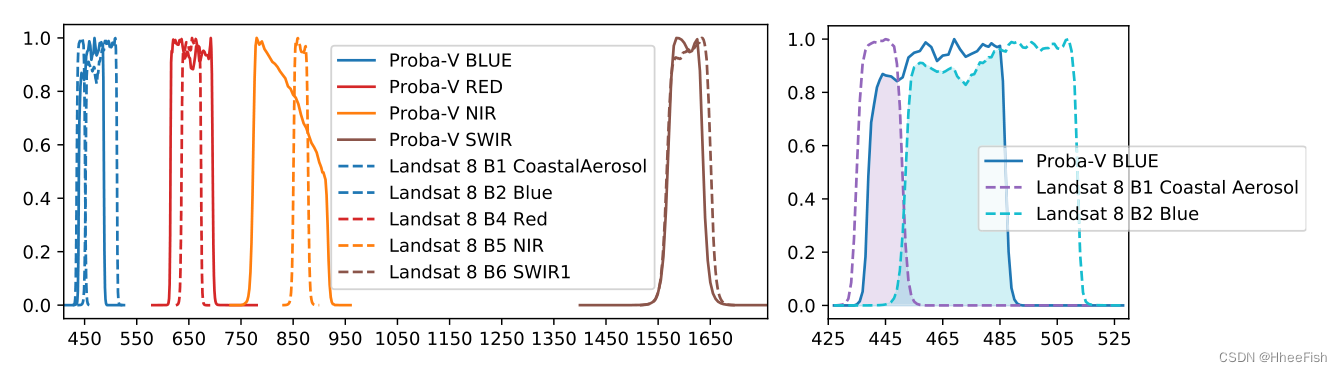
chart 2. Left :Landsat-8 and Proba-V Spectral response of . Right : Scaling of blue areas of the spectrum ; According to Landsat -8 Of B1 and B2 Band and ProbaV The contribution is weighted by the overlap of spectral response functions .
The second adaptive step changes Landsat-8 Spatial resolution of image . In order to be as similar as possible Proba-V Spatial properties of , We will use Landsat 8 Zoom in to a thicker image Proba-V The resolution of the . First , We use each Proba-V Point spread function of spectral band (PSF) Put Landsat -8 The observed value is converted to the nominal value of the lowest point Proba-V Spatial resolution . For blue 、 Red and near infrared channels ,Proba-V The ground sampling distance of the central camera (GSD) about 96.9 rice , and SWIR The resolution of the central camera is 184.7 rice (Wouter Dierckx personal communication(Dierckx wait forsomeone ,2014),2018 year 6 month 26 Japan ).SWIR PSF The width of is about that of other frequency bands PSF Twice as many , This underscores the fact that , That is, different spatial adaptations can be applied to each frequency band . The power spectral functions of these bands are modeled as two-dimensional Gaussian filters , be applied to 30 Landsat with a resolution of meters -8 Band . Through every 3 Pixels 1 individual , Enlarge the filtered image to the lowest nominal 90 Meter resolution . Last , application Lanczos Interpolation enlarges the image to the final 333 m Proba-V The resolution of the . Please note that ,Lanczos yes Proba-V Interpolation method used in ground segment processing , Used to get the original Proba-V The data is upgraded to 333 m Flat car grid (Dierckx wait forsomeone ,2014).
We used basically the same program to convert Landsat-8 The relevant ground truth value of the data set (DAY In the figure 1 in ). For binary cloud masks , We apply Gaussian filtering 、 3×3 Up sampling and lanczos Interpolation generation 333 m Resolution image ; then , Apply threshold to binarize the image , For cloudy pixels , Threshold set to 0.5. For cloud mask from 333 m Resolution Proba-V The switch to 30 m The resolution of the , We use simple bicubic interpolation . chart 3 It describes Landsat-8 Spectral and spatial transformations of images and related cloud masks .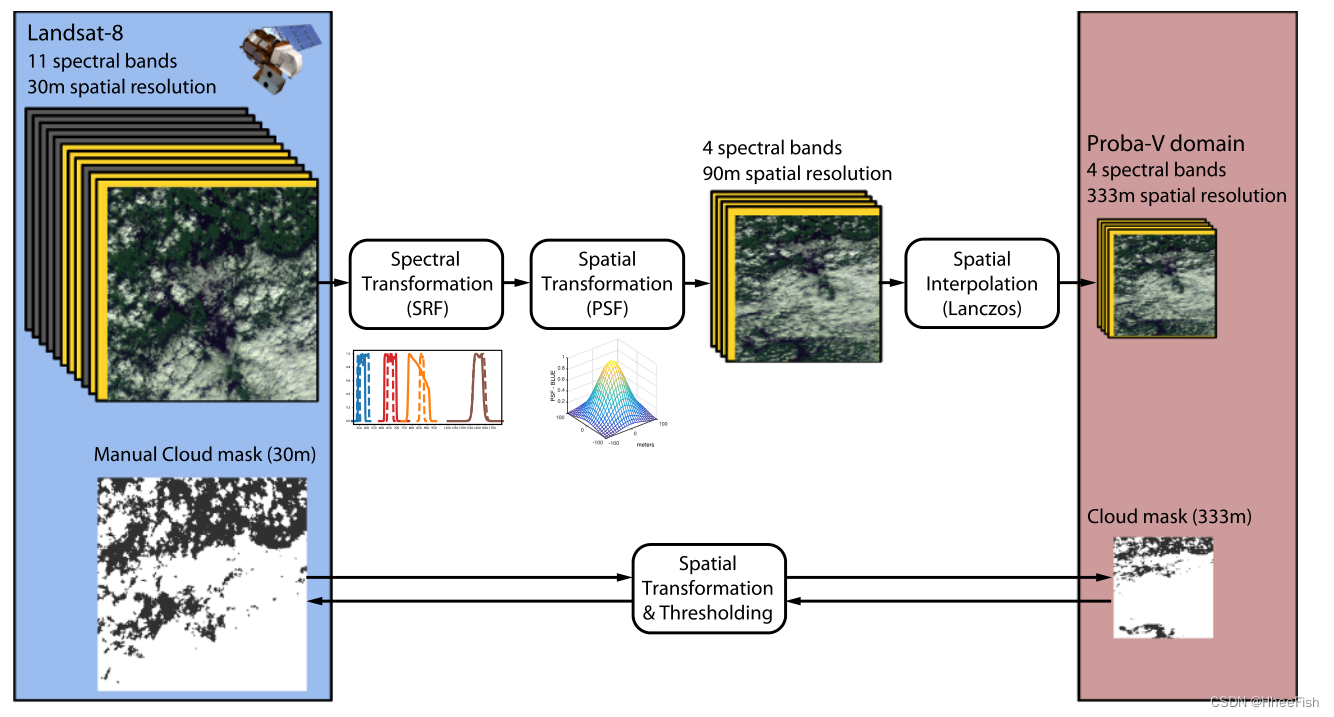
chart 3 Shown . take Landsat-8 The product and mask are transformed into similar Proba-V characteristic .
2.4. Full convolution neural network
Complete convolution neural network (FCNN) Learning mapping function ( chart 1 Medium fS and fT) The preferred model for .FCNN It is the most advanced image segmentation model , Because it can use the spatial spectral information of the input data . When providing a large amount of training data ,FCNNs It shows a very high level of accuracy in several image segmentation tasks (Chen wait forsomeone ,2018a; Lin et al ,2018;Chen wait forsomeone ,2018b). Although the reasons for their success are still poorly understood (Zhang et al., 2017;Szegedy et al., 2014), as everyone knows , The hierarchical structure of spatial spectral convolution stack is a good a priori of visual system (Yosinski et al., 2014). Besides , Many studies show that , They usually achieve higher performance than classification methods that manually design spatial spectral features (Wieland wait forsomeone ,2019;Mateo-García et al., 2017).
In this work , The full convolution neural network solves a standard multi output binary classification problem , Where the input is 4 Band image , Output as 2D map . The value of this output is between 0 To 1 Between , It can be explained as the cloud probability of basic pixels . The superimposed set of convolutional filters seeks to use the spatial information of nearby pixels to provide the cloud mask of each pixel , This is critical when spectral information is reduced , Such as Proba-V Only 4 A spectral band .
Since the outbreak of deep learning application of image segmentation , Full convolution neural network design has been developing (Farabet wait forsomeone ,2013;Long wait forsomeone ,2015;Chen wait forsomeone ,2015). In most applications ,FCNN The architecture includes an encoder module , This module is composed of convolution filter , Convolution filter collects images many times , Plus a decoder module , The decoder module demodulates the reduced feature vector to the original image size , To meet the forecast . Because all operations are convolution and pointwise nonlinearity , Therefore, the network can be applied to images of any size , Reasoning time is fast .Ronneberger wait forsomeone (2015) Proposed U-Net Architecture is a well-known complete convolution architecture , It has been applied in many fields, from computer vision to medical images (Ronneberger wait forsomeone ,2015;Drozdzal wait forsomeone ,2016;Breininger wait forsomeone ,2018). It is also widely used in remote sensing (Schuegraf and Bittner,2019 year ;Wieland wait forsomeone ,2019 year ;Jeppesen wait forsomeone ,2019 year ;Drönner wait forsomeone ,2018 year ), Especially the cloud detection of remote sensing network (Jeppesen wait forsomeone ,2019 year ), And Landsat 8 The no. Wieland wait forsomeone (2019 year ). It has 5 Multiple pooling / Non pooling stage , And add skip connection between feature maps with the same resolution . in general ,U-Net Conceptually simple but accurate , And provide fast prediction , This is mandatory in remote sensing, especially cloud detection . In this work , We use Separable convolution layer (Chollet,2017), take The number of pooling steps is reduced from five to two , And by replacing the output of the network with binary classification instead of multi class classification , To adjust U-Net framework . These modifications follow the assumption that ,333 Meter resolution cloud detection can be solved with fewer parameters and smaller downscaling steps .Landsat-8 Remote sensing network (Jeppesen wait forsomeone ,2019) Used 5 Downscaling steps , And we used it 2 individual , It makes sense , Because they use 30 Meter resolution data .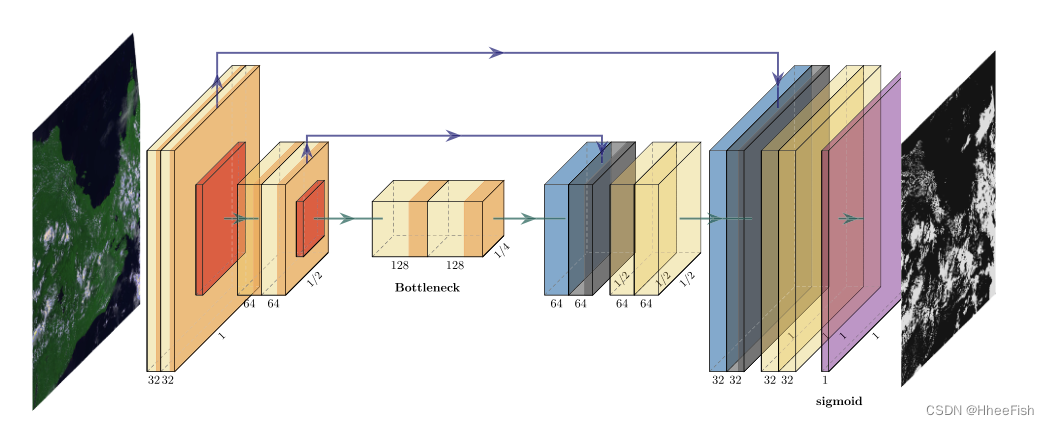
chart 4 Shown . be based on Ronneberger wait forsomeone (2015) Proposed for cloud detection FCNN framework : Input is 4 Band TOA Reflection image
chart 4 Shows the scheme of the proposed architecture . The encoder part consists of two blocks , two 3×3 Separable convolution 、 Batch normalization (Ioffe and Szegedy,2015) and ReLU Activate , And then there was 2×2 Maximum pool . There are also two bottlenecks 3×3 Separable convolution 、 Batch normalization and ReLU Active block . The decoder consists of two transposed convolution blocks , Transpose the convolution block and the previously activated connection of the encoder , And twice 3×3 Separable convolution 、 Batch normalization and ReLU Activate . Last , application 1×1 Convolution to get through sigmoid Activate to get the output of the final cloud probability . All in all , our FCNN The architecture has 95769 Three trainable parameters , And implement 2.18 M Floating point operation to calculate 256×256 Cloud mask of image . And Jeppesen wait forsomeone (2019)、Wieland wait forsomeone (2019) Proposed U-Net Architecture compared to , The parameters of our proposed architecture are reduced 99%, Floating point operations are reduced 92%.U-Net There are about 780 All the parameters , need 27.97 M Floating point operation to calculate 256×256 Cloud mask of image
In this work , Two different training strategies are used : The network can either start training from scratch , Or use fine tuning . Training from scratch refers to randomly initializing the weights of the network , Fine tuning corresponds to initialization using the weights of the previous training network . Because the optimization of neural network is usually a non convex problem , Different initialization of weights may lead to different local minima of the loss function , This may have different test performance .
Once the weight is initialized , We use small batch random gradient descent to minimize the standard binary cross entropy loss relative to these weights . This loss is defined as :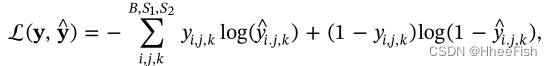
among ,y^i,j,k It is the... In the batch i A picture of (j,k) Prediction network output in pixels ;yi,j,k Is the ground truth value in its corresponding label ;B It's batch ;S1×S2 Is the size of the image .
3. Tag data sets
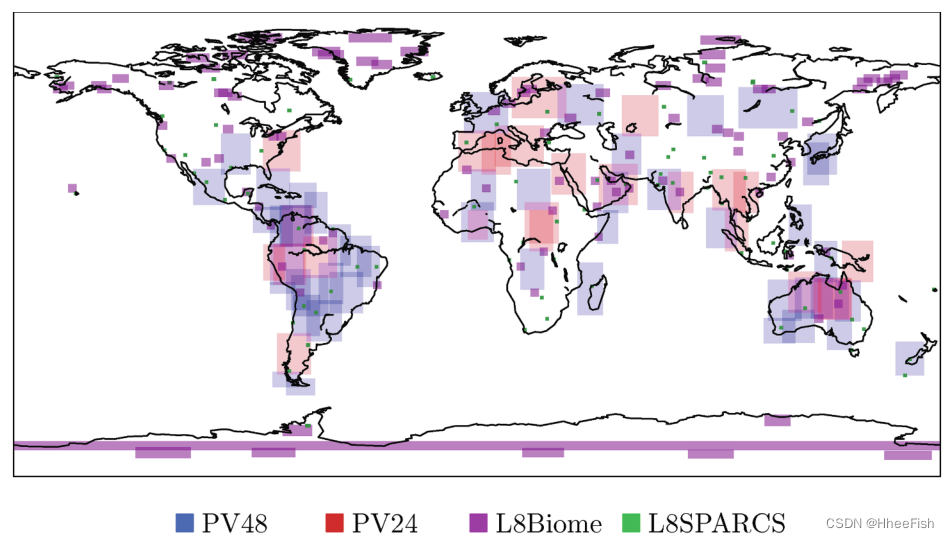
chart 5. Landsat used 8 Number and Proba-V The location of the data set . Each image has a manually generated cloud mask .
This section describes the use of Landsat-8 and Proba-V Tag data set . Manually annotated cloud masks are designed for training and validation worldwide 、 Cloud detection algorithm under different land cover and different atmospheric conditions is very important . In this work , We will make it publicly available L8Biome( U.S. Geological Survey ,2016b) and L8SPARCS( U.S. Geological Survey ,2016a) Data sets are used for Landsat-8, And will conduct a circular exercise in ESA (Iannone wait forsomeone ,2017) An improved version of the dataset developed in the context of Proba-V( chart 5).
3.1. Landsat -8 Datasets and ground truth
As mentioned earlier , stay Landsat-8 and Proba-V Explore in TL One of the motivations of is the public with the corresponding cloud mask Landsat-8 Availability of image data sets , These image datasets are used as ground truth through supervised machine learning algorithms . We use Foga wait forsomeone (2017) Open access provided L8Biome( U.S. Geological Survey ,2016b) and L8SPARCS( U.S. Geological Survey ,2016a) Data sets .
L8Biome Data set from Foga wait forsomeone (2017) Developed by . It contains 96 individual Landsat-8 1T Class a products , All three categories are used for marking : Transparent cloud 、 Thin clouds and clouds . We merged the last two ( Thin clouds and clouds ) To get binary cloud mask . Products are distributed all over the world , cover 8 Three major biological communities . The average size of each product is 8000×8000 Pixels . For some experiments , We used and Li wait forsomeone (2019) The same training test segmentation , Each contains 73 Training and 19 A test image .
Collected L8SPARCS Data sets , To verify Hughes and Hayes(2014) Proposed method . It contains 80 Landsat -8 1T Level sub scene . They use five different categories to manually mark : cloud 、 Cloud shadow 、 snow / ice 、 water 、 Floods and clear skies . For this job , We will all non cloud classes ( Cloud shadow 、 snow / ice 、 water 、 Floods and clear skies ) Merge into clear Class . Each sub scene is 1000×1000 Pixels , Therefore, L8Biome Data set comparison , The amount of data is much lower .
3.2.Proba-V Datasets and ground truth
Proba-V The dataset is manually marked by the author 72 individual Proba-V 2A Class a products ( Processing version v101) form . This data set is a corrected and extended version of the data set created within the framework of the ESA round robin exercise (Iannone wait forsomeone ,2017),Mateo García wait forsomeone (2017)、MateoGarcía and Gómez Chova(2018) The dataset is also used . In this work , Two different experts have made extensive improvements to manual labels according to manual procedures .72 All pixels in the scene are marked as cloudy 、 Clear or uncertain . For uncertain pixels , Human experts cannot clearly determine whether they are cloud polluted or cloudless . therefore , Uncertain pixels are not used for training or testing purposes .
In order to evaluate the quality of the ground situation , The independent expert is also interested in 12 Different images 950 Pixels are marked pixel by pixel (Stelzer wait forsomeone ,2017 year ). The difference between these pixel level labels and the fully labeled scene is 6.62%. This error is similar to Scaramuzza wait forsomeone (2012 year ) Reported 7% The error is similar . Besides , Further analysis of the differences shows , They mainly appear in translucent clouds above the ocean , There? , Even experienced users have difficulty distinguishing between clouds . However , This error constitutes the lower limit of error that the model can achieve using these labels ;i、 e. We cannot use this data set to truly distinguish errors less than 6% Model of .
We will Proba-V Data sets are divided into training and testing . The train data set consists of 48 It's made up of images : We call this dataset PV48. The test data set consists of the remaining 24 Product composition , Let's call this PV24. chart 5 Shows the location of training and testing products . These labeled products are also available for inspection .3.
4. Experimental setup
The experimental design attempts to answer several questions , These problems can be summarized into three :
(1) Use Landsat-8 Whether the data training model can adapt Proba-V Work in the field ?
(2) Use Proba-V Images (333 Meter resolution ) Can the training model be applied to Landsat -8 Images (30 Meter resolution )?
(3) Whether merging the data of the source domain and the target domain will improve the accuracy of the training model ?
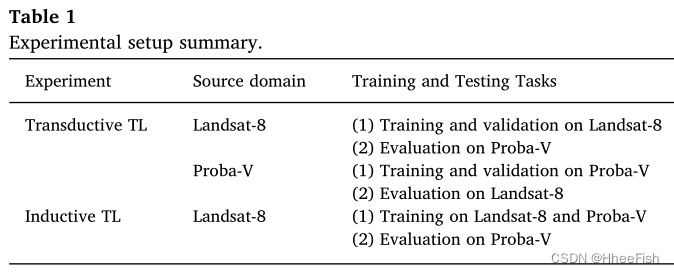
therefore , problem 1 and 2 And transductive TL The problem is relevant , And the problem 3 Involving induction TL. To answer these questions , We made a table 1 Two groups of experiments summarized in : One set for transductive TL, The other group is for induction TL.
stay transductive TL in , We explored two different scenarios :(1) Only with Landsat-8 Mark data and (2) Only with Proba-V Tag data . For each scene , Once the model is trained , We will perform two tasks : First , We validate the model in the source domain , Then evaluate them in the target domain , They are designed to work in the target domain . As mentioned earlier , In the first scenario , We will use TL programme 1, In the second scenario , We will use TL programme 2( The first 3.2 section ).
Inductive TL The experiment answers the third question mentioned above . It includes simultaneous use Proba-V Data and adaptation Landsat-8 The data is in Proba-V Training model in domain . Use 3.3 The spatial spectral transformation explained in section will Landsat-8 Data conversion to Proba-V Domain for training .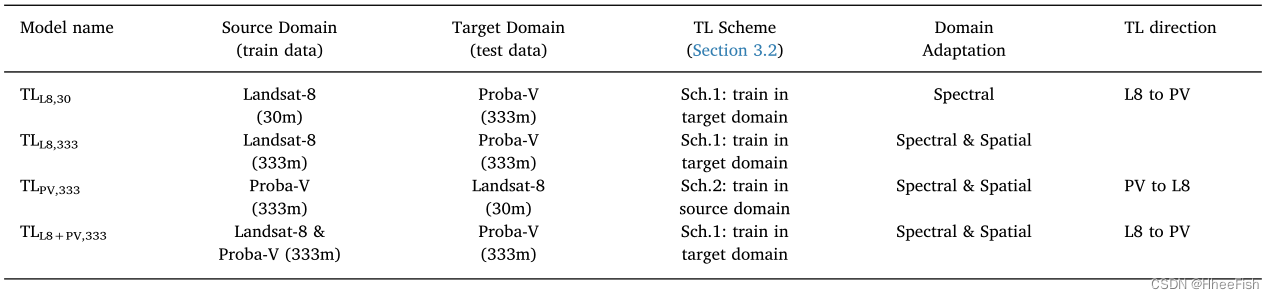
surface 2 According to the transfer between sensors, learn the direction ( That is, the data used for training and testing ), Experimental setup of different training models .
Of each experiment TL The model is shown in table 2 Shown . The model is expressed as TLSat,SR, among Sat It refers to the satellite from which the training data comes (L8, Landsat-8 and PV, Proba-V);SR It refers to the spatial resolution used in training the model , It can be 30 rice (Landsat-8 The resolution of the ) or 333 rice (Proba-V The resolution of the ). Be careful , When the satellite is L8, A resolution of 333 m when , It means , To train the model ,L8 Image and ground truth values have been used 3.3 Space in section - Spectral domain adaptation conversion to Proba-V Domain .
4.1. Transductive transfer learning : from Landsat-8 To Proba-V
In this experiment , We assume that we only use Landsat-8 Training with labeled data . In this setup , We trained two people to follow TL programme 1 Model of . The first model TLL8,30 Only use spectral transformation As a domain adaptation step , Instead of using spatial transformations (3.3 section ). The second model ,TLl8,333, Used Spectrum and space Two steps , send Landsat-8 Tagged image adaptation Proba-V Domain . Both models can be directly applied to Proba-V data . For the first model , This is technically possible , Although it is trained on images with different spatial resolutions , Because the model is based on the complete convolution architecture ( The first 3.4 section ), Therefore, it can be applied to images of any size .
To ensure that the model works properly , We are right. Landsat-8 The data were preliminarily tested . Be careful , This is a realistic situation , Because we assume that only tag data from this domain . stay Landsat-8 Testing the first model in the domain is simple ( That is, the spatial resolution of the predicted cloud mask is the same as that of the original model ), But in Landsat-8 Test the second model in the domain , We have to Undo space adaptation . To do this , We use simple bicubic interpolation ( The first 3.3 section ), Reduce the obtained cloud mask to 30 m The resolution of the . say concretely , We are right. Landsat-8 The source domain was tested twice , In order to compare with the work (Li wait forsomeone ,2019 Years and Jeppesen wait forsomeone ,2019 year ): In the first test , We are in accordance with the Li wait forsomeone (2019 year ) The experimental setup of , Including the use of information from L8Biome Data sets 73 Images for training , rest 19 Zhang for testing 4. The second is according to Jeppesen wait forsomeone (2019) Set up , Use all the L8Biome Image training , Use L8SPARCS To test
Once we check that the trained model works in the source domain , We will evaluate their performance in the target domain ( From PV24 Of test data sets ProbaV Images ). Through this experiment , We want to prove (1) from Landsat8 To Proba-V Of Transductive transfer learning is effective ,(2)** Two domain adaptation steps ( Spectrum and space )** All need to make transfer learning possible .
4.2. Transductive transfer learning : from Proba-V To Landsat-8
Suppose we only have Proba-V The marked data is used for training (Proba-V It's the source domain ,Landsat-8 It's the target domain ), We will apply TL Scheme 2( chapter 3.2). This model (TLPV,333 In the table 2 in ) use first PV48 and PV24 Dataset in Proba-V Training and evaluation in the domain . And then , We are in Landsat-8 The performance in the image is evaluated . In order to apply this model to Landsat-8 Images ,TL programme 2 Include :(1) Yes Landsat-8 Image application Space - Spectral domain adaptation transformation ( The first 3.3 section ),(2) application Proba-V Training models ,(3) Through simple bicubic interpolation, the obtained cloud mask prediction is scaled down to 30 m The resolution of the .
4.3. Inductive transfer learning : from Landsat-8 To Proba-V
Last , In the inductive block , We evaluated the use of data from Proba-V And all Landsat-8 Data of more and more data training of several models . Please note that , And transduction TL The first scene of the experiment is the same , We use TL Scheme 1 Train the model in the target domain ; therefore , from Proba-V It is very simple to add additional labeled images to the joint training experiment . We analyzed two different training strategies :(1) Train the model from scratch , Also include Landsat-8 and Proba-V Images ,(2) Using the model TLL8,333 Parameter initialization model , And use Proba-V Image trimming model . Besides , We also use the same Proba-V The models of image training from scratch are compared . The training details of all models can be found in the appendix A Find .
5. Experimental results and discussion
In this section , We discussed the 4 The results of different transfer learning experiments described in section , And summarized in table 1 in . We first show the results of transductive transfer learning : We from Landsat-8 To Proba-V Of TL( chapter 6.1) Start , And then from Proba-V To Landsat-8 Of TL( chapter 6.2), Then there are the results related to the robustness of the transduction model ( chapter 6.3), Finally, all the transducing transfer learning models in the two fields are summarized , And compared with the latest independent model ( chapter 6.4). Last , We give the results of inductive transfer learning ( The first 6.4 section ).
In order to test the model , We are Proba-V Use in domain PV24 Data sets . stay Landsat-8 field , We use L8SPARCS and L8Biome Data sets , When they are not used for training . Tests are always performed in native parsing of a given domain ; therefore , about Proba-V, The prediction mask is in 333 m Resolution domain , about Landsat-8, The prediction mask is in 30 m The resolution of the Landsat-8 Obtained from the image .
5.1. Transduction transfer learning results :Landsat-8 To Proba-V
In this section , We will show 4.1 The results of the experimental setup explained in section . First , We show the results of our model , Use Li wait forsomeone (2019 year ) Yes L8Biome The dataset is evaluated using the same training test segmentation , And compare our results with their results . then , We show how to use from L8Biome The results of all image training models of the data set , These results are first in Landsat-8 Domain use L8SPARCS Data sets are evaluated , And then on the target Proba-V Domain use PV24 Test data sets for evaluation . The objective of this section is to demonstrate the use of the proposed space - The spectral domain is adapted to Landsat-8 and Proba-V Transfer learning between is useful . Besides , A complementary result is , Only using spectral domain adaptation is not enough to obtain an accurate model .
We are L8Biome Use... On datasets Li wait forsomeone (2019) The proposed training experiment segmentation method evaluates these models . especially , Let's use the same one 73 Images for training ,19 Zhang for testing , Therefore, the result can be directly related to (Li wait forsomeone ,2019) Compare . We are in accordance with the TL programme 1 Two models were trained : The first model TLL8,30 Only spectral steps are used as domain adaptation transforms , The second model TLL8,333, Use the entire spectrum and spatial adaptation ( See 2.3 section ). It is worth emphasizing that , In order to apply the model to Landsat-8 Images , The corresponding domain adaptation transformation must be carried out on the image first . After applying the model , The corresponding cloud mask must be converted back to the source domain . stay TLL8,333 Under the circumstances , The mask is reduced to 30 rice . surface 3 Shows Landsat-8 The result of the test image . You can see , These two models have similar performance . Although the model TLL8,333 Work at different spatial resolutions , But its accuracy is only better than that of direct use 30m Model of resolution data (TLL8,30) A little lower .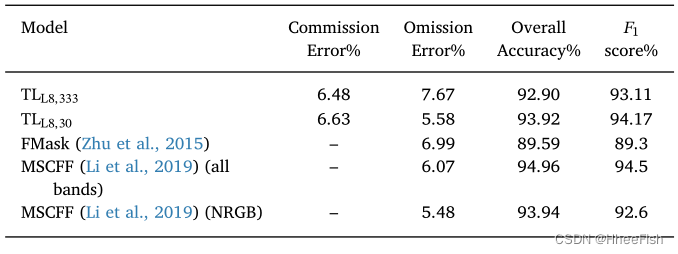
surface 3 Li wait forsomeone (2019 year ) The use of L8Biome Data sets 19 Results of test images . The proposed model (TLL8,333 and TTLL8,30) and Li wait forsomeone (2019) Model of (MSCFF) All use L8Biome The same data set 73 Images for training .
surface 3 It contains MSCFF The Internet (Li wait forsomeone ,2019 year ) and FMask The Internet (Zhu wait forsomeone ,2015 year ) Result , For comparison . about MSCFF The Internet , We considered using all bands and only NIR、Red、Green and Blue Band (NRGB) Result . We can see , We are 30m Network ratio of training under Resolution NRGB Band MSCFF With similar performance , It shows us that FCNN Architecture MSCFF Compressed a similar amount of information , Although its trainable parameters and pooling steps are much less . Besides , Use 333 m Resolution data (TLL8,333) The training network is better than that using all bands MSCFF Low precision 2 spot (Li wait forsomeone ,2019 year ). However , For this 19 Images , It provides more operable Landsat-8 Cloud detection algorithm FMask (Zhu et al., 2015) More accurate cloud mask . This emphasizes 333 m The resolution image retains enough information , It can be for 30m Our products provide accurate cloud masks ; in other words , The implicit smoothing effect of the scaling up and scaling down methods will not affect the overall cloud detection accuracy —— Although there may be some effects at the cloud boundary .
Because these preliminary results are satisfactory , We use the 4.1 Described in section L8Biome All images of the data set retrained these two networks from scratch . In order to analyze the robustness of the network to the initialization of different weights , We trained with different random seeds 10 Using spectral spatial domain adaptation (TLL8,333) Network copy of . The robustness result will be in 5.3 Section for further analysis .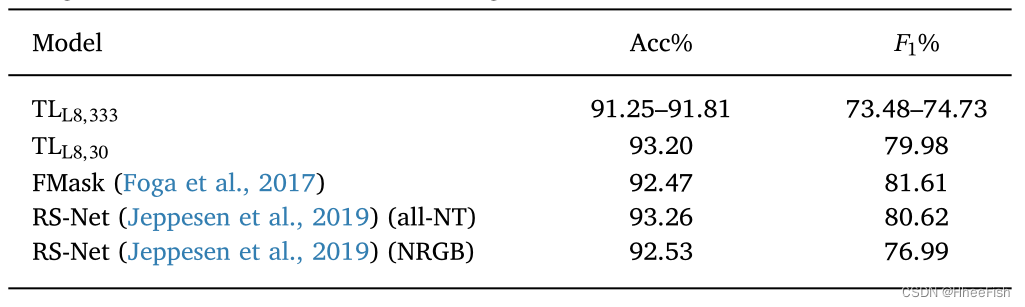
surface 4 Use L8Biome Data sets are trained and used L8SPARCS The data set is at the source Landsat-8 Model results of domain tests .RS-Net Both the model and our model use L8Biome Data sets are trained .
surface 4 Displayed in Landsat-8 L8SPARCS Results of testing these models on datasets . First , We see , As expected ,10 individual TLL8,333 The result of the copy is 10 It shows low variability in different operations . This is consistent with our hypothesis , That is, different weight initialization will lead to consistent training and test accuracy values . About network performance , Use space - Spectral domain adaptation (TLL8,333) The training network is better than working in 30m Resolution network (TLL8,30) And working RS-Net The Internet (Jeppesen wait forsomeone ,2019) About low 2 spot . about RS-Net, Let's think again about using RGB Band Plus near infrared (NRGB) Result , And the use of heat removal (all- nt) Results of all bands except , heat (all- nt) yes Jeppesen wait forsomeone (2019) Of L8SPARCS The best performing model in the dataset . under these circumstances , It is also worth mentioning that , Only use spectral domain to adapt the transformation (TLL8,30) Our network is almost the same as RS-Net (Jeppesen et al., 2019) With the same accuracy , even to the extent that (a) The trainable parameters of the network are reduced 99%,(b) It uses less Landsat-8 Spectral band .
surface 5 Use L8Biome The result of the model trained by the data set , And the use of PV24 Dataset in ProbaV Test results on the target domain .
Once we prove that the model trained in the transfer learning framework has competitive performance , Even models trained specifically for the source domain , We will also evaluate the performance of the model in the target field . surface 5 Shows Landsat-8 Model for Proba-V Data migration learning results . Specially , This table 5 Shows the use of Landsat-8 L8SPARCS Test results of data set training model , And use PV24 Test set in Proba-V Tested in the domain . First , We found that using space - Spectral domain adaptation (TLL8,333) The training model is better than using Operational Proba-V The cloud mask training model is more accurate . This shows that the proposed strategy can be used to design accurate ML Model , Even before the satellite was launched . On the other hand ,TLL8,333 The results are better than those of the model trained only with spectral transformation (TLL8,30) More precise 8 To 10 spot . This explanation FCNN The spatial pattern of learning depends on spatial resolution , therefore , In order to transfer learning between sensors with different spatial resolutions , It is necessary to carry out domain adaptation transformation considering spatial scale .10 The results of the second run of the network showed an unusual behavior : For different random initializations , Cloud detection accuracy and F1 Score at 3 Change within points . This dependence on initialization is related to the table 4 Shown Landsat-8 This in the domain 10 The results of this run are in contrast . Our assumption is , After the proposed adaptation ,Landsat-8 Adapt to the distribution of data and real Proba-V There is still data transfer between distributions (Torralba and Efros, 2011). In our view , For real Proba-V Some images in the domain , The network can be extrapolated . therefore , The prediction of these areas is correct for some networks , For other networks, it is wrong , It depends on its initialization . However , This implicit extrapolation does not significantly affect the quality of prediction ; We can see , Even in the worst case , Use spatial spectrum to adapt Landsat-8 Data training network , It is also superior to Proba-V Operate cloud detection algorithm (Wolters wait forsomeone ,2015).

chart 6 Shown . Real ground data and PV24 Differences between the three models applied at the three test sites of the test data set .
Last , chart 6 Some illustrative results of cloud masks of three different models are given , These apply to those not used for training Proba-V Images . These images are used to highlight key cloud detection cases , Such as cloud ice recognition 、 Bright impervious surface 、 Sand and coastal areas . We use white to show the consistency between the model prediction and the real value on the ground , Use orange to indicate missing error ( The model prediction is clear , The ground is really cloudy ), The delegation error is indicated in blue ( The prediction shows that the true values of clouds and ground are clear ). The first example shows how to operate on beach and water PV Debugging error of cloud mask . Convolution model does not have these problems , Although in L8Biome The model trained on the dataset still has several omission errors mainly at the cloud boundary . The second example shows the winter harvest in the Andes of South America . under these circumstances , The operation algorithm produces commission error in the snow mountain area correctly detected by the convolution model ; Especially with Proba-V Model of image training ,TLPV,333. The last example also highlights several committee errors in the operation algorithm over Istanbul, Turkey . Once again, , Convolution model shows a lower commission amount . In the appendix B in , We provide more information about Proba-V Examples of images .
5.2. Transduction transfer learning results :Proba-V Yes Landsat-8
In this section , We introduce and analyze only Proba-V The result of data training network . These networks first use PV24 Test set in Proba-V Test in the source domain , And then use L8Biome The data set is in the target Landsat-8 Test in the domain . The purpose is to prove 10 Times lower resolution Proba-V The data training model can also be transferred to 30 m Landsat-8 The resolution of the , The loss of accuracy is negligible .
We're going to do it according to section 4.2 Section explains the settings , Use the transfer learning program 2( chart 1) Training models TLPV,333. especially , We use PV48 Data sets are trained , We also trained 10 A network copy , To evaluate the robustness to initialization . surface 6 Shows the use of PV24 The test data set is at the source Proba-V The result of this model in the domain . We can see , The model achieves very high accuracy , This is not very sensitive to network initialization .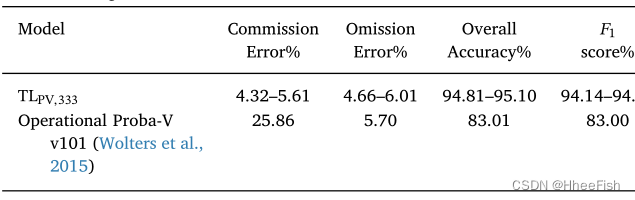
surface 6 In the use of PV24 Data sets Proba-V PV48 Data set on Proba-V Results of training model on source domain .
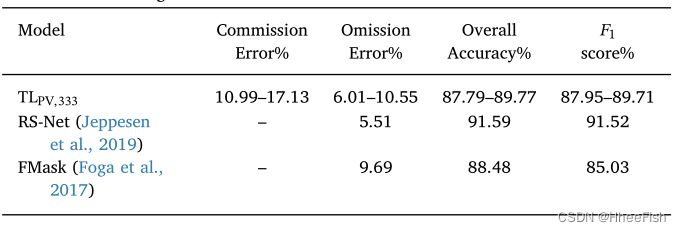
surface 7:L8Biome On dataset TLPV Model 333 Comparison of the results of with other published results .RS-Net(Jeppesen wait forsomeone ,2019) Model USES L8SPARCS Data sets are trained
In order to be in Landsat-8 Test the model in the domain , We follow the rule of 5.2 The process described in Section . Be careful , As we discussed earlier , Use 333 m Resolution data to distinguish 30 m The resolution of the image is an uncertain problem , Because there is information loss during resampling . surface 7 Shows the use of L8Biome Data set as test set Landsat-8 The performance index of the proposed model on the domain . We can see , use Proba-V data TLPV,333 The accuracy of the training model is FMask The accuracy is similar (Zhu and Woodcock, 2012), And it is not far from the deep learning method recently studied (Jeppesen et al., 2019). This shows that , Using low resolution data can solve the problem of cloud detection with a given resolution , This shows that most of the information loss caused by the upgrade will not affect the final cloud mask prediction . appendix B For some extra selected Landsat-8 The image provides the cloud mask of the model .
5.3.FCNN Robustness
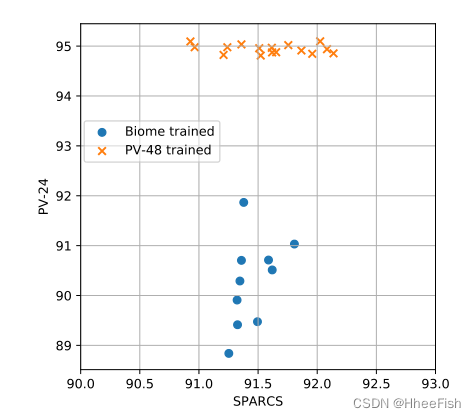
chart 7. Use from L8Biome Data sets TLL8333( Blue ) Of Landsat-8 Data and from PV48 Data sets TLPV,333( Orange ) Of Proba-V Test accuracy of data training model .X Axis :L8SPARCS Accuracy in the dataset ;Y Axis :PV24 Accuracy in the dataset .( A description of the colors in this legend , See the network version of this article .)
As mentioned earlier , We trained ten copies of the same network , Change two TL Random seeds of directional experiments , To test the robustness of the transduction transfer learning model to initialization . chart 7 These models are shown (TLPV,333 and TLL8,333) Separate use PV24 and SPARCS Dataset in Proba-V and Landsat-8 Test accuracy of domain . The clearest pattern we can see is , When the network is in the source domain ( That is, in the same domain where they are trained ) When testing , Its accuracy is higher than when testing in the target domain , And the variability is lower . As we explained before , We attribute this behavior to the implicit extrapolation of the target domain network : Different training networks give different predictions in some unknown parts of the target domain . When adjusting the super parameters of the network , These results should be taken into account , Because the difference between the hyperparametric configurations may be caused by the noise caused by this extrapolation effect . Another thing worth mentioning , stay Proba-V Domain (TLPV,333) Training network and in space - Spectral domain adaptation (TLL8,333) Of Landsat-8 Networks trained on data have similar accuracy , Although it has higher variability
5.4. Summary of transduction results
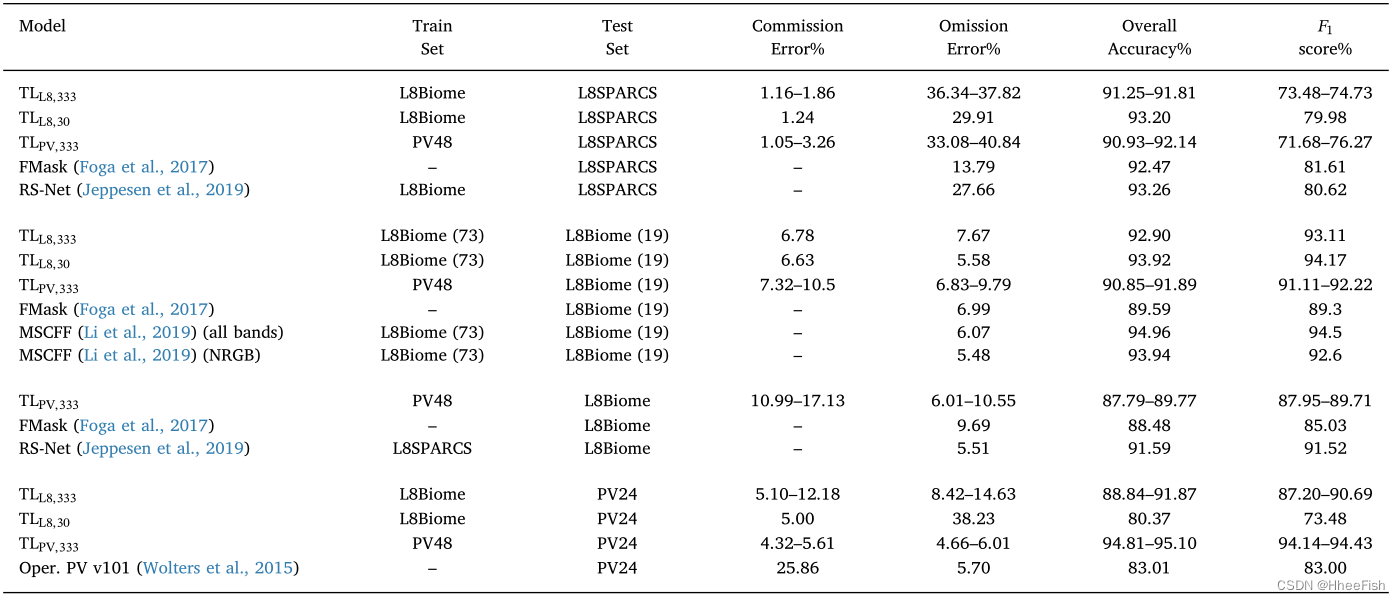
surface 8 The results of different test sets of the proposed model and selected models in the literature are listed . The range is shown in 10 The minimum and maximum values obtained in this run , Change the random seed value of network weight initialization .
In this section , We explore the connection between all previous experiments , And compare their results . Because the proposed model can be applied in two fields (Landsat-8 and Proba-V) To assess the , They can be compared with each other . surface 8 A summary of the results of the previous sections is shown . First column , Model , Refers to the specific architecture and TL programme . Model specific TL The scenario specifies how to test the model in the source and target domains ( See also 5 Learn more about ). The second column shows the data set used to train the model ; The third column shows the data set of the test model . The remaining columns are different measures of the performance of the test model . Be careful , If you use different data sets to train a given model , It will end with different parameters ( That is, the weight of the network will be different ).
First , stay Proba-V In the case of domain testing , We can see that only Landsat-8 The training model is still better than that based on threshold Proba-V Operating the cloud detection model is much better (Wolters et al., 2015); However , It's with real Proba-V There is still a big gap in the network of image training . therefore , It proved to be an effective strategy , And have an improved perspective . secondly , Rely on manual tagging procedures used by experts to develop basic truths : We see , The model trained with the same method and the data tested has significantly higher accuracy . for example , Use Li The training of others - Test segmentation (2019) Yes L8Biome Data training network than using all L8Biome Data training and in L8SPARCS Data set testing network (91.25-91.81%) With higher accuracy (92.90%). stay Proba-V Domain , We see the use of PV48 The network of dataset training is PV24 Data sets also have very high accuracy (94.81-95.10%), This may also be due to PV48 and PV24 Datasets were developed by the same experts using the same manual marking method . stay Recht wait forsomeone (2018)、Torralba and Efros(2011) Such dependencies have also been documented in other environments involving classification . In the case of cloud detection , The inclusion of different standards for thin clouds in data sets may exacerbate this situation , Because in a dataset , Very thin translucent clouds may be considered clear pixels , In other data sets , This pixel may be annotated as a cloud . Last , Among these results , It is important to consider the errors in the labeling process . It is estimated that ,Landsat The error of is about 7% (Scaramuzza wait forsomeone ,2012),Proba-V The error of is about 6.62%( See the first 4.2 section ). therefore , From a statistical point of view , Using these datasets , exceed 93% The accuracy of the model cannot be truly compared or ranked .
5.5. Inductive transfer learning results
In this section , We will show and discuss the results of the model trained with two data sets at the same time . This setup is designed to explore such a scenario : Given ( The goal is ) Satellite sensors rarely have tagged images , This happens all the time , The reason is that the cost of manually marking the cloud is very high , The corpus of labeled images from different but similar sensors is larger . In these experiments ,Proba-V Will be the target domain , There are few tag images with cloud mask available , and Landsat-8 The satellite will act as the source domain ,L8Biome Dataset as a large corpus of labeled images . therefore , The goal of the experiment is to test the use of fine-tuning or with L8Biome Whether the network of data set joint training is less than that used Proba-V The network of image ab initio training has significantly better performance .
In order to use Landsat-8 Data training model , We apply TL programme 1( The first 3.2 section ), And in the first place 5.3 The proposed spectral spatial domain adaptation is explained in section . In this setting , Model in Proba-V Training in domain , therefore , Joint training includes a few Proba-V Image data set and Landsat-8 Adaptive image data set merging .
We use it PV48 More and more truth in the data set Proba-V Images train several networks . For each group Proba-V Images d, We from PV48 Data set selection 8 A disjoint subset , contain d Zhang image . For each subset , Train three models respectively :(a) Use d Proba-V Image training starts from scratch ;(b) fine-tuning , Use these d Proba-V Before image fine tuning L8Biome A network of centralized training 5; Joint training , Use d Proba-V Images and L8Biome All images in the dataset are trained from scratch .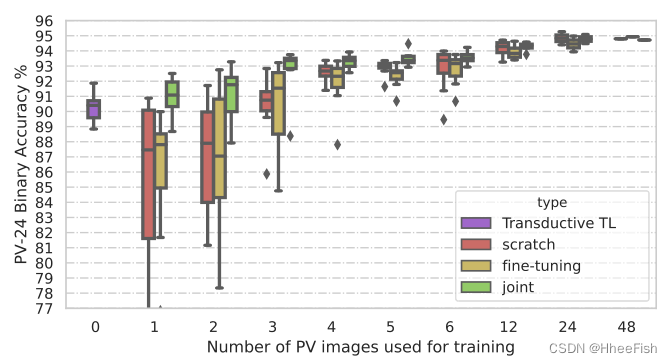
chart 8 Shown . Use a different number of Proba-V Image training FCNN Joint model PV24 Test set , Red means from nothing , Yellow is fine tuning , Green is joint training .( About the explanation of colors in this legend , Readers can refer to the web version of this article .)
chart 8 For this experiment, in PV24 Test results on the test set . in general , We found that joint training is better than training from scratch or using fine-tuning training , The latter shows similar accuracy . Specially , We can see , stay 1 To 3 In the rare data scene of an image , Using joint training can improve 2 To 4 Average accuracy between points . There is 4 To 6 Images in the training scene , Joint training still has a small improvement in accuracy , And reduce the variance of the result precision value . This shows that the joint training scheme has stronger robustness . In scenarios with a large amount of data , We see that these three methods have similar performance . It is also worth mentioning that , And use only Landsat-8 Data without using any Proba-V Compared with the model of image training , Joint training systematically improves the average accuracy ( The first 6.1 section ).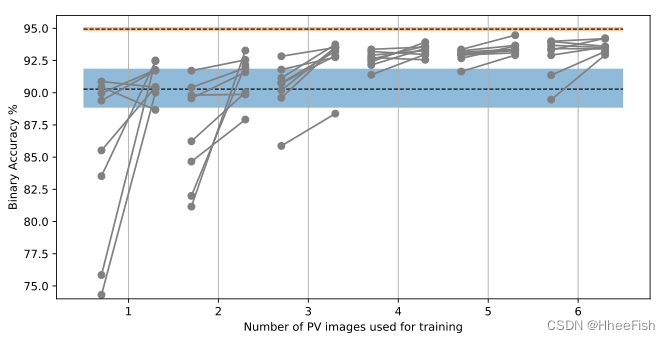
chart 9. The test uses a different number of Proba-V Accuracy of image training model . For each value on the left , Use only Proba-V data ; On the right side , The model is based on Landsat 8 Number and Proba-V Data joint training . The blue shaded area indicates that only L8Biome The accuracy of the model trained in the data set . The orange area indicates in all Proba-V Images (PV48) The accuracy of the model trained on .( A description of the colors in this legend , See the network version of this article .)
chart 9 Compared joint training with training from scratch . In this diagram , Each dot represents d A subset of the image , among d stay X Change in axis . The dot on the left shows that only these d Images of models trained from scratch PV24 The accuracy of the test set , And the point on the right will be these d Image and L8Biome The images in the dataset are used together for training ( Joint learning ). We see , For the vast majority of these subsets , The use of joint training has a positive impact on the final performance of the model ( Point on the right ). We see again , The variance of the joint model decreases , Joint training always takes advantage of new Proba-V data , It also performs better than the model without it , The model only uses L8Biome Data sets are trained , And described by the blue shaded area . Please note that , The orange area describes in all Proba-V Images (PV48) The accuracy of the model trained on , This provides an upper limit for cloud detection accuracy
6. summary
In this paper , We explored different transfer learning (TL) Methods to train machine learning for cloud detection in remote sensing images (ML) Method . especially , We use Landsat-8 and Proba-V For example, it analyzes transductive And induction TL frame . Both frameworks rely on domain adaptive transformation , The conversion converts the image from one satellite into an image similar to the image obtained by another satellite .
We propose an image conversion method , In order to make Landsat-8 Image adaptation Proba-V Spectral and spatial characteristics , So as to realize cross satellite TL. Our results show that , In order to make full use of TL The advantages of , Spatial and spectral adaptation must be used simultaneously .
transductive transfer learning The framework assumes that we only have data from one satellite . In this context , Two different TL programme , And successfully tested . According to the specific direction of domain adaptive conversion , Each scheme allows different TL: From source domain to target domain or from target domain to source domain . We show that , Use only Landsat-8 Data training ML Model in Proba-V The performance of the algorithm is better than that of the current algorithm (Wolters wait forsomeone ,2015). It means ML The method can even be trained before the satellite is launched , And get better performance than the threshold based method . We evaluated the results of the proposed method in the context of the first to cloud detection method based on deep learning (Jeppesen wait forsomeone ,2019;Li wait forsomeone ,2019).
In order to use Proba-V The data is in Landsat-8 Predict on the image , We put forward a kind of TL programme , The proposed Landsat8 To Proba-V Domain adaptive transformation . We show that , Use only Proba-V Data training ML Accuracy and operation of the model Landsat-8 Method ( Such as FMask) be similar ( Zhu He Woodcock,2012), And only than ( Li et al ,2019) Two points lower , Even if our method is to use low 11 Times spatial resolution data training .
边栏推荐
- 技术分享 | 接口测试价值与体系
- Use of print function in MATLAB
- LeetCode 6111. 螺旋矩阵 IV
- Image classification, just look at me!
- About Estimation with Cross-Validation
- Thoroughly understand why network i/o is blocked?
- Various pits of vs2017 QT
- Use QT to traverse JSON documents and search sub objects
- LeetCode 6109. 知道秘密的人数
- @Extension、@SPI注解原理
猜你喜欢

Let more young people from Hong Kong and Macao know about Nansha's characteristic cultural and creative products! "Nansha kylin" officially appeared
node_ Exporter memory usage is not displayed
2022最新中高级Android面试题目,【原理+实战+视频+源码】

第十届全球云计算大会 | 华云数据荣获“2013-2022十周年特别贡献奖”
Failed to virtualize table with JMeter
![Whether to take a duplicate subset with duplicate elements [how to take a subset? How to remove duplicates?]](/img/b2/d019c3f0b85a6c0d334a092fa6c23c.png)
Whether to take a duplicate subset with duplicate elements [how to take a subset? How to remove duplicates?]

视频自监督学习综述
Memory leak of viewpager + recyclerview
Tupu software digital twin | visual management system based on BIM Technology
@Extension、@SPI注解原理
随机推荐
项目中遇到的问题 u-parse 组件渲染问题
How to write good code defensive programming
LeetCode 6109. Number of people who know the secret
Cronab log: how to record the output of my cron script
[paddlepaddle] paddedetection face recognition custom data set
2022最新中高级Android面试题目,【原理+实战+视频+源码】
基于can总线的A2L文件解析(3)
生词生词生词生词[2]
The easycvr platform reports an error "ID cannot be empty" through the interface editing channel. What is the reason?
Whether to take a duplicate subset with duplicate elements [how to take a subset? How to remove duplicates?]
Writing writing writing
sample_rate(采样率),sample(采样),duration(时长)是什么关系
Crontab 日志:如何记录我的 Cron 脚本的输出
快速生成ipa包
FCN: Fully Convolutional Networks for Semantic Segmentation
Clickhouse (03) how to install and deploy Clickhouse
爱因斯坦求和einsum
How to obtain the coordinates of the aircraft passing through both ends of the radar
7-2 keep the linked list in order
[utiliser Electron pour développer le Bureau sur youkirin devrait]