当前位置:网站首页>Simple query cost estimation
Simple query cost estimation
2022-07-05 18:39:00 【InfoQ】
Query cost estimate —— How to choose an optimal execution path
- Lexical analysis: Describe the lexical analyzer *.l Document management Lex Tool build lex.yy.c, Again by C The compiler generates an executable lexical analyzer . The basic function is to set a bunch of strings according to the reserved keywords and non reserved keywords , Convert to the corresponding identifier (Tokens).
- Syntax analysis: Syntax rule description file *.y the YACC Tool build gram.c, Again by C The compiler generates an executable parser . The basic function is to put a bunch of identifiers (Tokens) According to the set grammar rules , Into the original syntax tree .
- Analysis rewrite: Query analysis transforms the original syntax tree into a query syntax tree ( Various transform); Query rewriting is based on pg_rewrite Rules in rewrite tables and views , Finally, we get the query syntax tree .
- Query optimization: After logical optimization and physical optimization ( Generate the optimal path ).
- Query plan generation: Transform the optimal query path into a query plan .
- Query execution: Execute the query plan through the executor to generate the result set of the query .
Why do you need these statistics , Is this enough ?
- Is it an empty array
- Is it a constant array
- Is it the only one without repetition
- Is it orderly
- Is it monotonous , Isochromatic , Equivalency
- What are the most frequent numbers
- Distribution law of data ( The data growth trend is depicted in the dotted way )
How to estimate query cost based on statistical information
- The statistics are only from part of the sampled data , Can not accurately describe the global characteristics .
- Statistics are historical data , The actual data may change at any time .
The simplest table row count estimate ( Use relpages and reltuples)
SELECT relpages, reltuples FROM pg_class WHERE relname = 'tenk1'; --- Sampling estimation has 358 A page ,10000 Bar tuple
relpages | reltuples
----------+-----------
358 | 10000
EXPLAIN SELECT * FROM tenk1; --- Query and estimate that the table has 10000 Bar tuple
QUERY PLAN
-------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..458.00 rows=10000 width=244)- First, calculate the actual number of pages by the size of the physical file of the table actual_pages = file_size / BLOCKSIZE
- Calculate the tuple density of the page
- a. If relpages Greater than 0, density = reltuples / (double) relpages
- b. If relpages It's empty ,density = (BLCKSZ - SizeOfPageHeaderData) / tuple_width, Page size / Tuple width .
- Estimate the number of table tuples = Page tuple density * Actual pages = density * actual_pages
The simplest range comparison ( Use histogram )
SELECT histogram_bounds FROM pg_stats WHERE tablename='tenk1' AND attname='unique1';
histogram_bounds
------------------------------------------------------
{0,993,1997,3050,4040,5036,5957,7057,8029,9016,9995}
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 1000; --- Estimate less than 1000 There are 1007 strip
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=24.06..394.64 rows=1007 width=244)
Recheck Cond: (unique1 < 1000)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..23.80 rows=1007 width=0)
Index Cond: (unique1 < 1000) Selection rate = ( Total number of barrels in front + The range of the target value in the current bucket / The range of the current bucket ) / Total number of barrels
selectivity = (1 + (1000 - bucket[2].min) / (bucket[2].max - bucket[2].min)) / num_buckets
= (1 + (1000 - 993) / (1997 - 993)) / 10
= 0.100697
Estimate the number of tuples = Number of base table tuples * Conditional selection rate
rows = rel_cardinality * selectivity
= 10000 * 0.100697
= 1007 (rounding off)The simplest equivalent comparison ( Use MCV)
SELECT null_frac, n_distinct, most_common_vals, most_common_freqs FROM pg_stats WHERE tablename='tenk1' AND attname='stringu1';
null_frac | 0
n_distinct | 676
most_common_vals | {EJAAAA,BBAAAA,CRAAAA,FCAAAA,FEAAAA,GSAAAA,JOAAAA,MCAAAA,NAAAAA,WGAAAA}
most_common_freqs | {0.00333333,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003}
EXPLAIN SELECT * FROM tenk1 WHERE stringu1 = 'CRAAAA'; ---
QUERY PLAN
----------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=30 width=244)
Filter: (stringu1 = 'CRAAAA'::name)CRAAAA be located MCV No 3 term , The proportion is 0.003
selectivity = mcf[3]
= 0.003
rows = 10000 * 0.003
= 30EXPLAIN SELECT * FROM tenk1 WHERE stringu1 = 'xxx'; --- Search does not exist in MCV The value in
QUERY PLAN
----------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=15 width=244)
Filter: (stringu1 = 'xxx'::name)selectivity = (1 - sum(mvf)) / (num_distinct - num_mcv)
= (1 - (0.00333333 + 0.003 + 0.003 + 0.003 + 0.003 + 0.003 +
0.003 + 0.003 + 0.003 + 0.003)) / (676 - 10)
= 0.0014559
rows = 10000 * 0.0014559
= 15 (rounding off)The more complicated range is ( Use at the same time MCV And histogram )
SELECT null_frac, n_distinct, most_common_vals, most_common_freqs FROM pg_stats WHERE tablename='tenk1' AND attname='stringu1';
null_frac | 0
n_distinct | 676
most_common_vals | {EJAAAA,BBAAAA,CRAAAA,FCAAAA,FEAAAA,GSAAAA,JOAAAA,MCAAAA,NAAAAA,WGAAAA}
most_common_freqs | {0.00333333,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003}
SELECT histogram_bounds FROM pg_stats WHERE tablename='tenk1' AND attname='stringu1';
histogram_bounds
--------------------------------------------------------------------------------
{AAAAAA,CQAAAA,FRAAAA,IBAAAA,KRAAAA,NFAAAA,PSAAAA,SGAAAA,VAAAAA,XLAAAA,ZZAAAA}
EXPLAIN SELECT * FROM tenk1 WHERE stringu1 < 'IAAAAA'; --- Find one that does not exist in MCV The value in
QUERY PLAN
------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=3077 width=244)
Filter: (stringu1 < 'IAAAAA'::name)selectivity = sum(relevant mvfs)
= 0.00333333 + 0.003 + 0.003 + 0.003 + 0.003 + 0.003
= 0.01833333selectivity = mcv_selectivity + histogram_selectivity * histogram_fraction
= 0.01833333 + ((2 + ('IAAAAA'-'FRAAAA')/('IBAAAA'-'FRAAAA')) / 10) * (1 - sum(mvfs))
= 0.01833333 + 0.298387 * 0.96966667
= 0.307669
rows = 10000 * 0.307669
= 3077 (rounding off) Copy Example of multi condition joint query
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 1000 AND stringu1 = 'xxx';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=23.80..396.91 rows=1 width=244)
Recheck Cond: (unique1 < 1000)
Filter: (stringu1 = 'xxx'::name)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..23.80 rows=1007 width=0)
Index Cond: (unique1 < 1000)selectivity = selectivity(unique1 < 1000) * selectivity(stringu1 = 'xxx')
= 0.100697 * 0.0014559
= 0.0001466
rows = 10000 * 0.0001466
= 1 (rounding off)A use JOIN Example
EXPLAIN SELECT * FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 50 AND t1.unique2 = t2.unique2;
QUERY PLAN
--------------------------------------------------------------------------------------
Nested Loop (cost=4.64..456.23 rows=50 width=488)
-> Bitmap Heap Scan on tenk1 t1 (cost=4.64..142.17 rows=50 width=244)
Recheck Cond: (unique1 < 50)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.63 rows=50 width=0)
Index Cond: (unique1 < 50)
-> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.00..6.27 rows=1 width=244)
Index Cond: (unique2 = t1.unique2)selectivity = (0 + (50 - bucket[1].min)/(bucket[1].max - bucket[1].min))/num_buckets
= (0 + (50 - 0)/(993 - 0))/10
= 0.005035
rows = 10000 * 0.005035
= 50 (rounding off)SELECT tablename, null_frac,n_distinct, most_common_vals FROM pg_stats
WHERE tablename IN ('tenk1', 'tenk2') AND attname='unique2';
tablename | null_frac | n_distinct | most_common_vals
-----------+-----------+------------+------------------
tenk1 | 0 | -1 |
tenk2 | 0 | -1 |【*】 Selection rate = Multiply the non empty probabilities on both sides , Divide by the maximum JOIN Number of pieces .
selectivity = (1 - null_frac1) * (1 - null_frac2) * min(1/num_distinct1, 1/num_distinct2)
= (1 - 0) * (1 - 0) / max(10000, 10000)
= 0.0001
【*】JOIN The function estimation of is the Cartesian product of the input quantities on both sides , Multiply by the selection rate
rows = (outer_cardinality * inner_cardinality) * selectivity
= (50 * 10000) * 0.0001
= 50More details
边栏推荐
- node_ Exporter memory usage is not displayed
- ConvMAE(2022-05)
- The 11th China cloud computing standards and Applications Conference | cloud computing national standards and white paper series release, and Huayun data fully participated in the preparation
- Multithreading (I) processes and threads
- Thoroughly understand why network i/o is blocked?
- 生词生词生词生词[2]
- About Statistical Power(统计功效)
- Use JMeter to record scripts and debug
- ViewPager + RecyclerView的内存泄漏
- About Estimation with Cross-Validation
猜你喜欢
Use of websocket tool
![[HCIA cloud] [1] definition of cloud computing, what is cloud computing, architecture and technical description of cloud computing, Huawei cloud computing products, and description of Huawei memory DD](/img/b8/624799e4bf788e4476b155486f478b.png)
[HCIA cloud] [1] definition of cloud computing, what is cloud computing, architecture and technical description of cloud computing, Huawei cloud computing products, and description of Huawei memory DD
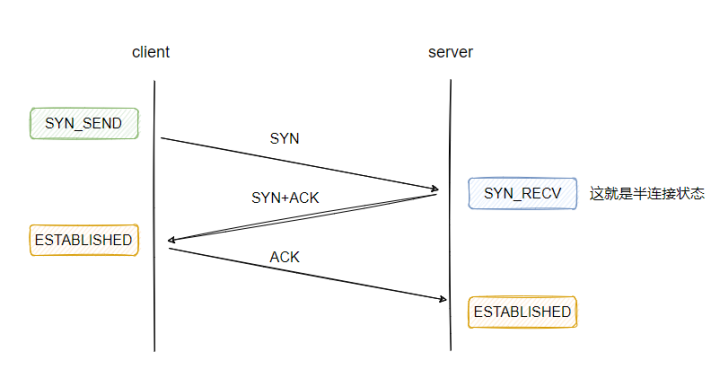
彻底理解为什么网络 I/O 会被阻塞?
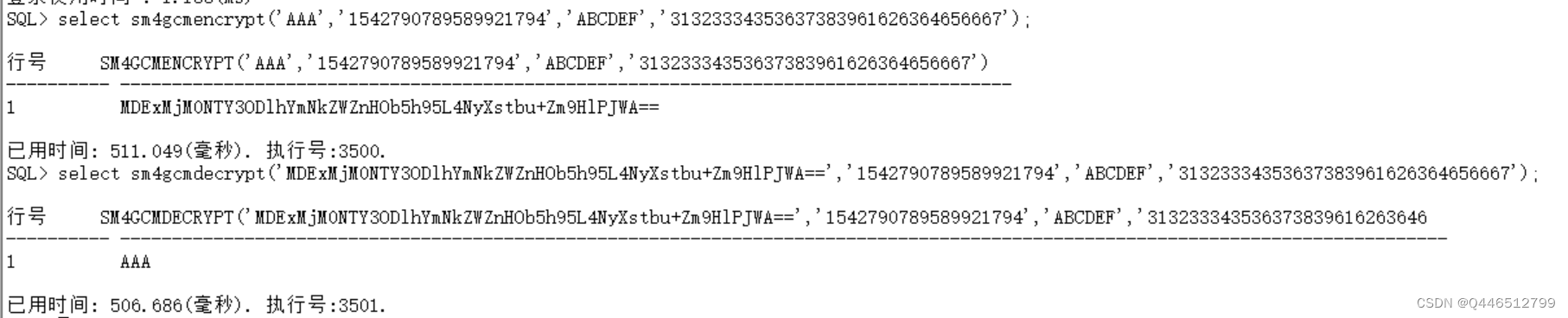
达梦数据库udf实现
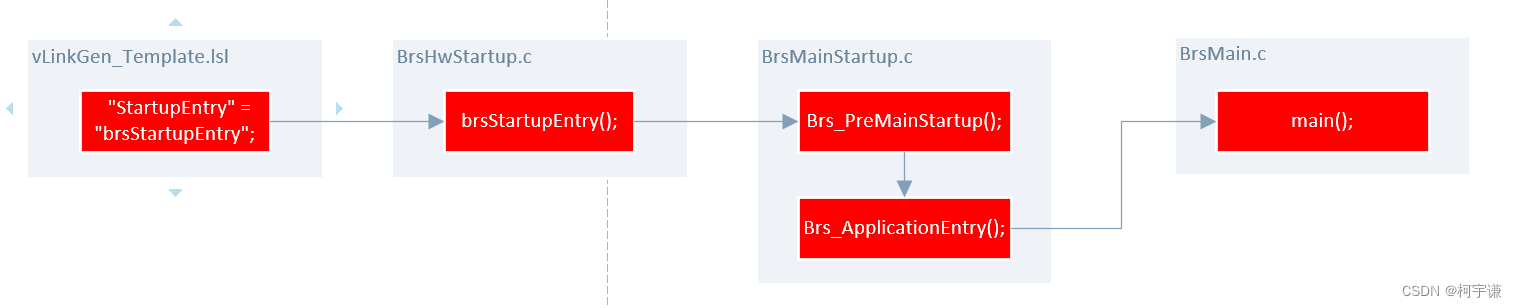
【Autosar 十四 启动流程详解】
2022最新Android面试笔试,一个安卓程序员的面试心得

解决 contents have differences only in line separators
node_ Exporter memory usage is not displayed
Record a case of using WinDbg to analyze memory "leakage"
AI表现越差,获得奖金越高?纽约大学博士拿出百万重金,悬赏让大模型表现差劲的任务
随机推荐
Thoroughly understand why network i/o is blocked?
What is the reason why the video cannot be played normally after the easycvr access device turns on the audio?
Pytorch yolov5 training custom data
Linear table - abstract data type
vs2017 qt的各种坑
Introduction to Resampling
基于can总线的A2L文件解析(3)
【在优麒麟上使用Electron开发桌面应】
Use of print function in MATLAB
英语句式参考
开户注册股票炒股安全吗?有没有风险的?靠谱吗?
About Estimation with Cross-Validation
A2L file parsing based on CAN bus (3)
RPC协议详解
Personal understanding of convolutional neural network
Common time complexity
文章中的逻辑词
ICML2022 | 长尾识别中分布外检测的部分和非对称对比学习
第十一届中国云计算标准和应用大会 | 华云数据成为全国信标委云计算标准工作组云迁移专题组副组长单位副组长单位
彻底理解为什么网络 I/O 会被阻塞?