当前位置:网站首页>Speed up your programs with bitwise operations
Speed up your programs with bitwise operations
2022-08-02 02:00:00 【crossoverJie】

Foreword
The JSON parsing library xjson, which was recently written before continuous optimization, is mainly optimized in two aspects.
The first is to support outputting a JSONObject object as a JSON string.
In the previous version, the data was printed using the built-in Print function:
func TestJson4(t *testing.T) { str := `{"people":{"name":{"first":"bob"}}}` first:= xjson.Get(str, "people.name.first") assert.Equal(t, first.String(), "bob") get := xjson.Get(str, "people") fmt.Println(get.String()) //assert.Equal(t, get.String(),`{"name":{"first":"bob"}}`)}Output:
map[name:map[first:bob]]After this optimization, the JSON string can be output directly:
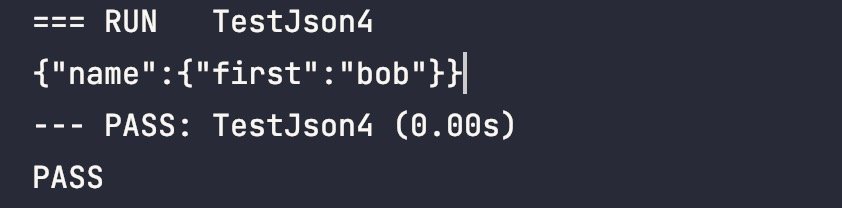
The implementation process is also very simple, just need to recursively traverse the data in the object, and then splicing strings, the core code is as follows:
func (r Result) String() string { switch r.Token { case String: return fmt.Sprint(r.object) case Bool: return fmt.Sprint(r.object) case Number: i, _ := strconv.Atoi(fmt.Sprint(r.object)) return fmt.Sprintf("%d", i) case Float: i, _ := strconv.ParseFloat(fmt.Sprint(r.object), 64) return fmt.Sprintf("%f", i) case JSONObject: return object2JSONString(r.object) case ArrayObject: return object2JSONString(r.Array()) default: return "" }}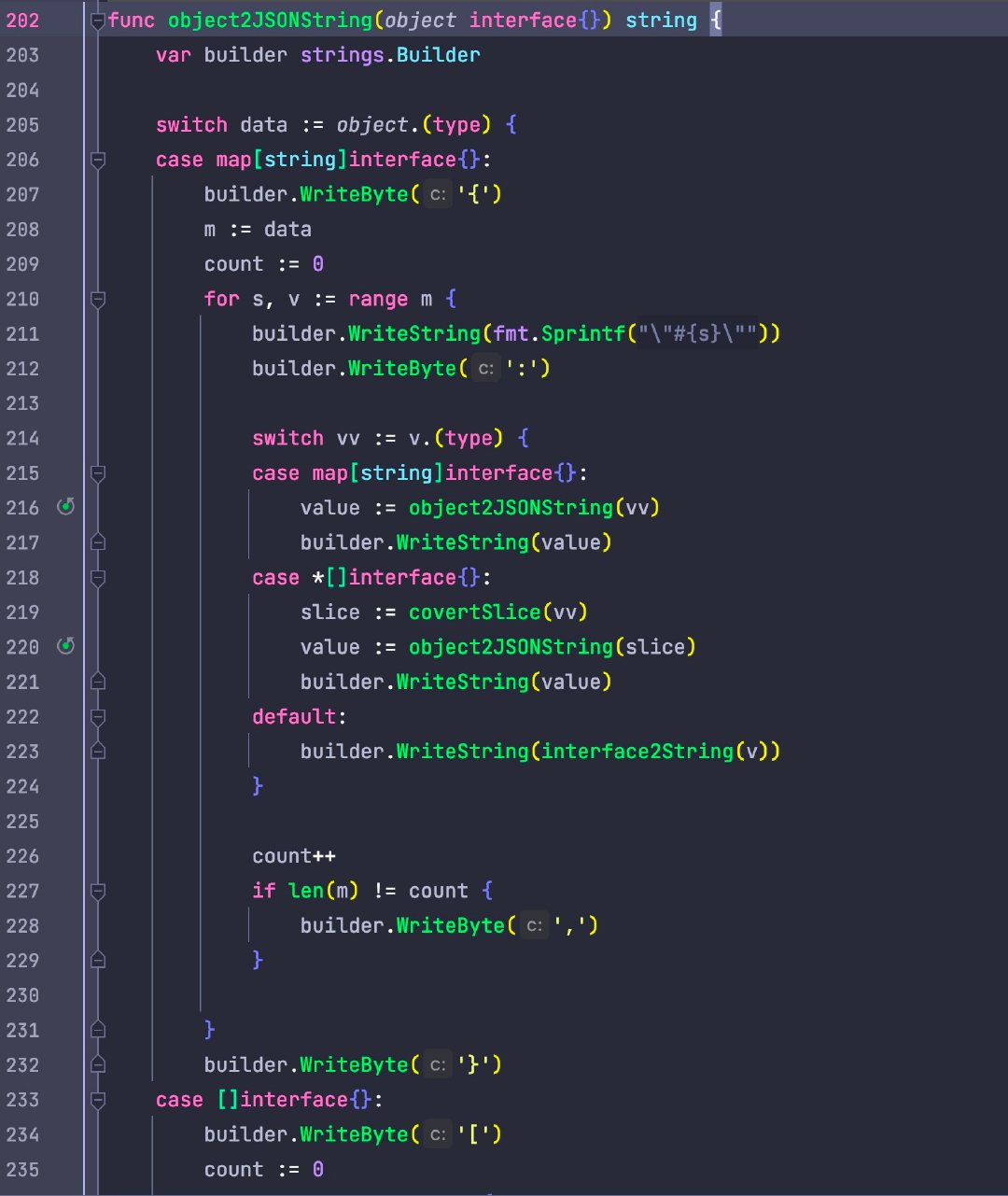
Optimize with bitwise operations
The second optimization is mainly to improve performance. When querying a complex JSON data, the performance is improved by about 16%.
# BenchmarkDecode-12 before optimization 90013 66905 ns/op 42512 B/op 1446 allocs/op# BenchmarkDecode-12 after optimization 104746 59766 ns/op 37749 B/op 1141 allocs/opHere are some important changes:
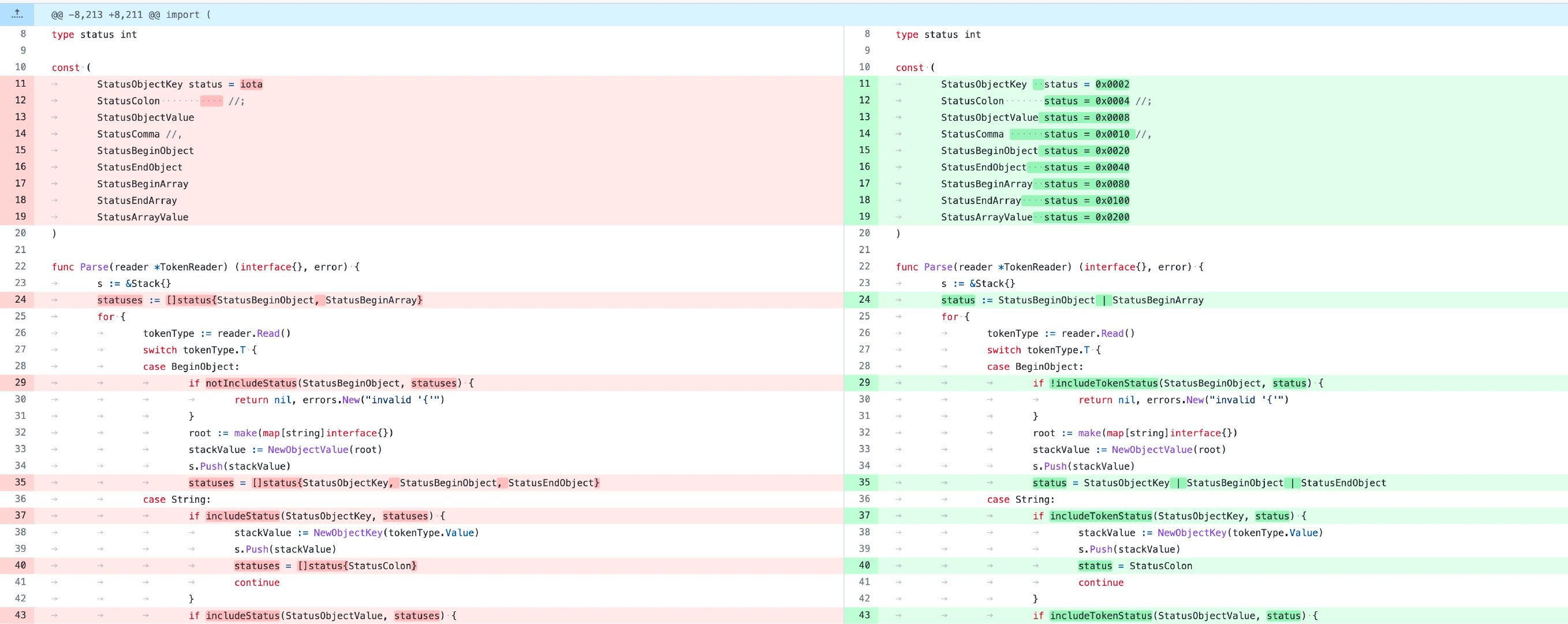
There will be a finite state machine state transition process during JSON parsing, and there may be multiple states during the transition.
For example, the currently parsed token value is {, then its next token may be ObjectKey:"name", or BeginObject:{, of course it may also be EndObject:}, so before optimization, I store all the states in a collection. During the parsing process, if I find that the state does not meet the expectationsA syntax exception error will be thrown.

So before optimization, we traverse this set to make judgments. This time complexity is O(N), but when we switch to bit operations, it is different, and the time complexity is directlyIt becomes O(1), while saving the storage space of a slice.
Let's simply analyze why this bit operation achieves the same effect of judging whether a data is in a set.
Take these two states as an example:
StatusObjectKey status = 0x0002 StatusColon status = 0x0004The corresponding binary data are:
StatusObjectKey status = 0x0002 //0010 StatusColon status = 0x0004 //0100When we perform the | operation on these two data, the data obtained is 0110:
A:0010B:0100C:0110At this time, if we use these two original data and C:0110 to do the & operation, it will be restored to the two data just now.
// input:A:0010C:0110// output:A:0010----------// input:B:0100C:0110//output:B:0100But when we change a D and C to find &:
D: 1000 // 0x0008 corresponds to binary 1000C: 0110D':0000will get a 0 value, as long as the data obtained is greater than 0, we can judge whether a data is in the given set.
> Of course, there is a precondition here that the high bit of the data we input is always 1, which is a power of 2.
The same optimization is used when parsing query syntax:
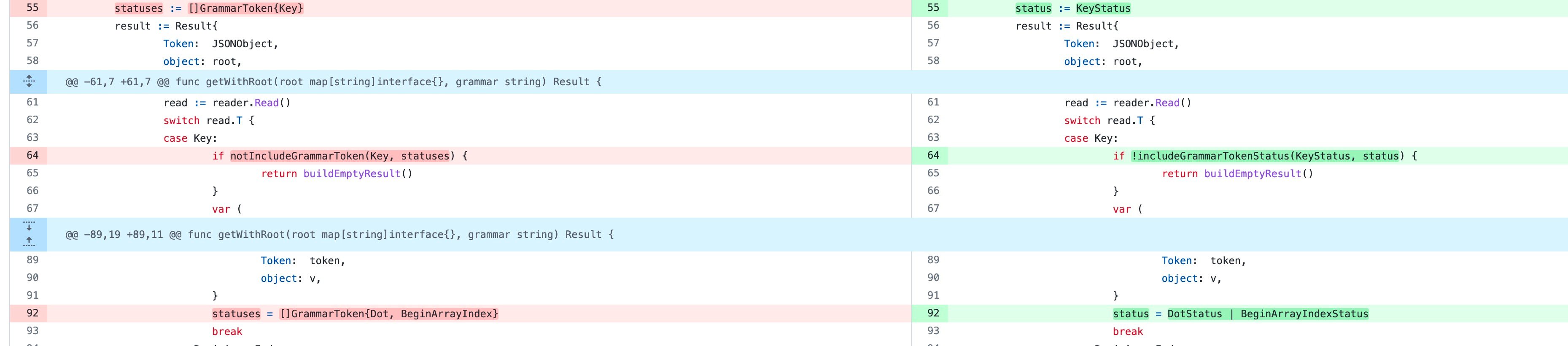
Other strange tricks
Of course, there are some other tricks for bit operations, such as judging odd and even numbers:
// even a & 1 == 0// odd a & 1 == 1Multiplication and division, right shift 1 bit is divided by 2, left shift is multiplied by 2.
x := 2fmt.Println(x>>1) //1fmt.Println(x<<1) //4Summary
Bit operations not only improve program performance but also reduce code readability, so we have to choose whether to use it or not;
It is recommended to use some low-level libraries and framework codes that have the ultimate pursuit of performance. However, it is not necessary to use bit operations to add, subtract, multiply and divide data in business code, which will only make subsequent maintainers look confused..
Related code: https://github.com/crossoverJie/xjson
边栏推荐
- 『网易实习』周记(三)
- typescript30-any类型
- Use baidu EasyDL implement factory workers smoking behavior recognition
- typescript30 - any type
- Multi-Party Threshold Private Set Intersection with Sublinear Communication-2021: Interpretation
- AOF重写
- Image fusion based on weighted 】 and pyramid image fusion with matlab code
- Fundamentals of Cryptography: X.690 and Corresponding BER CER DER Encodings
- Day115.尚医通:后台用户管理:用户锁定解锁、详情、认证列表审批
- 创新项目实战之智能跟随机器人原理与代码实现
猜你喜欢
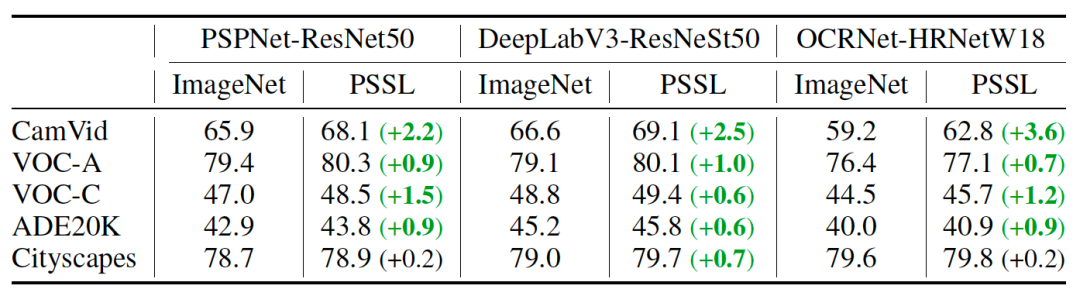
The ultra-large-scale industrial practical semantic segmentation dataset PSSL and pre-training model are open source!

『网易实习』周记(一)
Check if IP or port is blocked

Analysis of volatile principle

Use baidu EasyDL implement factory workers smoking behavior recognition

『网易实习』周记(二)

Rust P2P网络应用实战-1 P2P网络核心概念及Ping程序
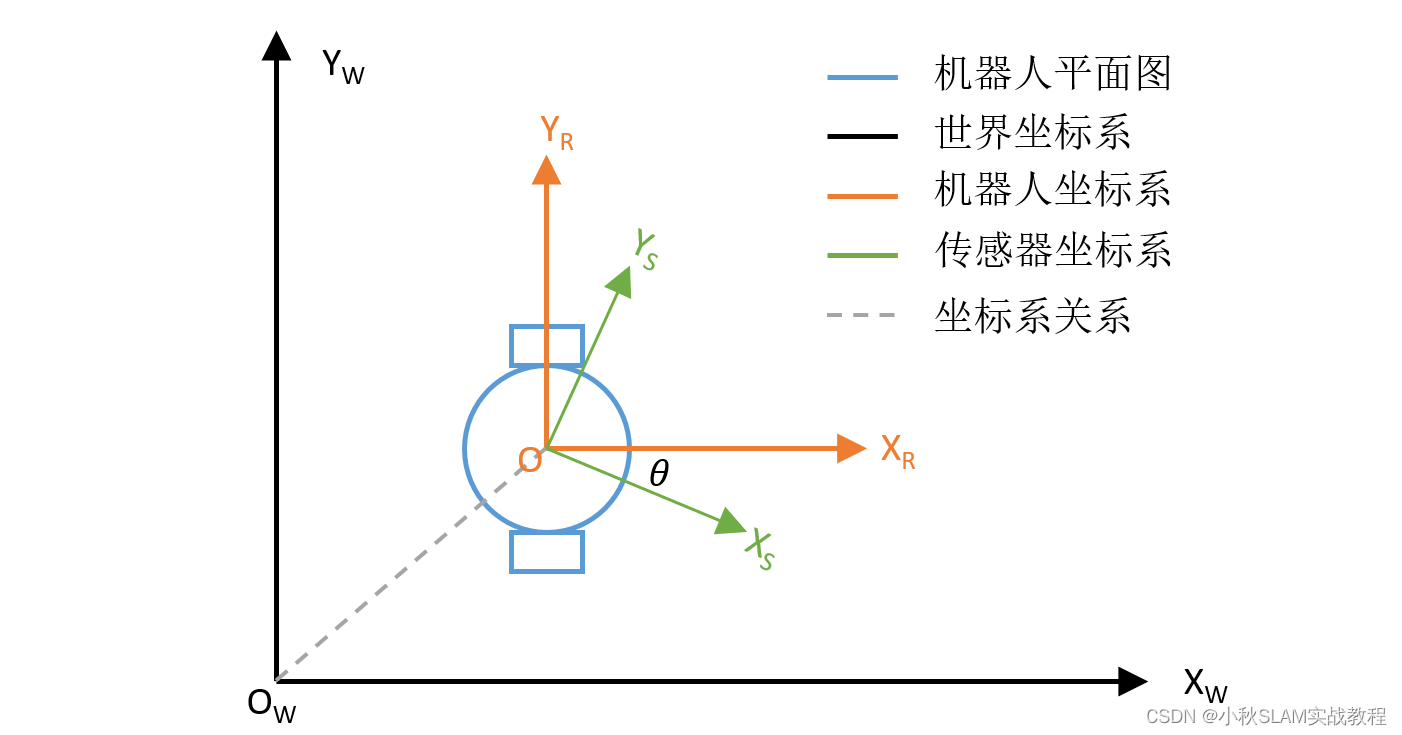
【轮式里程计】

字节给我狠狠上了一课:危机来的时候你连准备时间都没有...
Rust P2P Network Application Combat-1 P2P Network Core Concepts and Ping Program
随机推荐
Analysis of volatile principle
手写一个博客平台~第一天
LeetCode brushing diary: 53, the largest sub-array and
记录一次数组转集合出现错误的坑点,尽量使用包装类型数组进行转换
密码学的基础:X.690和对应的BER CER DER编码
秒懂大模型 | 3步搞定AI写摘要
typescript32-ts中的typeof
Redis 底层的数据结构
ofstream,ifstream,fstream读写文件
个人博客系统项目测试
6-25 Vulnerability Exploitation - irc Backdoor Exploitation
MySQL8 下载、启动、配置、验证
The ultra-large-scale industrial practical semantic segmentation dataset PSSL and pre-training model are open source!
5年自动化测试经验的一些感悟:做UI自动化一定要跨过这10个坑
Ask God to answer, how should this kind of sql be written?
typescript29-枚举类型的特点和原理
HSDC和独立生成树相关
2023年起,这些地区软考成绩低于45分也能拿证
Yunhe Enmo: Let the value of the commercial database era continue to prosper in the openGauss ecosystem
Pcie the inbound and outbound