
![]()
![]()
PyGrid is a peer-to-peer network of data owners and data scientists who can collectively train AI models using PySyft. PyGrid is also the central server for conducting both model-centric and data-centric federated learning.
A quick note about PySyft 0.3.x: Currently, PyGrid is designed to work with the PySyft 0.2.x product line only. We are working on support for 0.3.x and hope to have this released by early 2021. Thanks for your patience!
Architecture
PyGrid platform is composed by three different components.
- Network - A Flask-based application used to manage, monitor, control, and route instructions to various PyGrid Nodes.
- Node - A Flask-based application used to store private data and models for federated learning, as well as to issue instructions to various PyGrid Workers.
- Worker - An ephemeral instance, managed by a PyGrid Node, that is used to compute data.
Use Cases
Federated Learning
Simply put, federated learning is machine learning where the data and the model are initially located in two different locations. The model must travel to the data in order for training to take place in a privacy-preserving manner. Depending on what you're looking to accomplish, there are two types of federated learning that you can perform with the help of PyGrid.
Model-centric FL
Model-centric FL is when the model is hosted in PyGrid. This is really useful when you have data located at an "edge device" like a person's mobile phone or web browser. Since the data is private, we should respect that and leave it on the device. The following workflow will take place:
- The device will request to train a model
- The model and a training plan may be sent to that device
- The training will take place with private data on the device itself
- Once training is completed, a "diff" is generated between the new and the original state of the model
- The diff is reported back to PyGrid and it's averaged into the model
This takes place potentially with hundreds, or thousands of devices simultaneously. For model-centric federated learning, you only need to run a Node. Networks and Workers are irrelevant for this specific use-case.
Note: For posterity sake, we previously used to refer to this process as "static federated learning".

Data-centric FL
To view the current roadmap for data-centric FL, please click here.
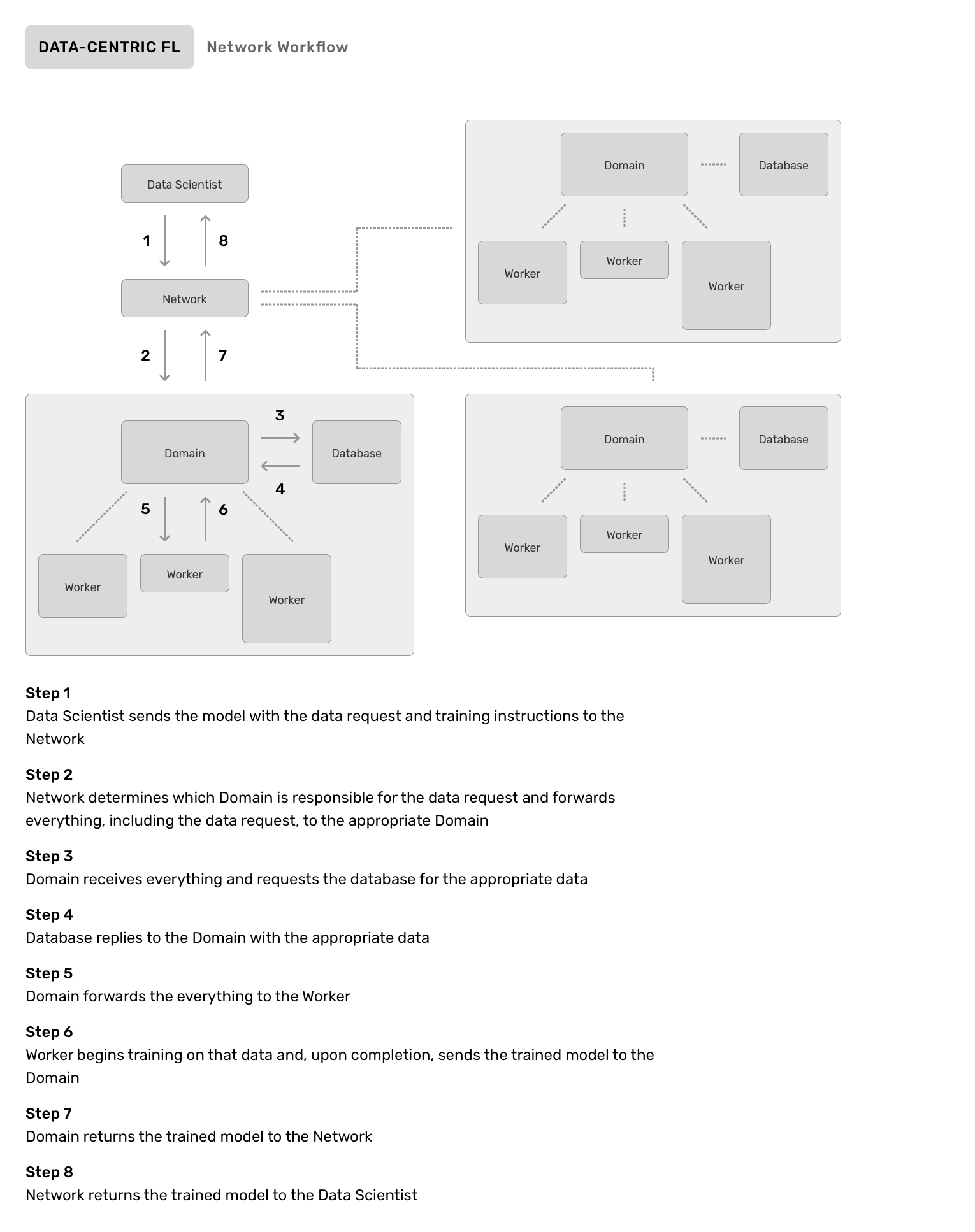
Data-centric FL is the same problem as model-centric FL, but from the opposite perspective. The most likely scenario for data-centric FL is where a person or organization has data they want to protect in PyGrid (instead of hosting the model, they host data). This would allow a data scientist who is not the data owner, to make requests for training or inference against that data. The following workflow will take place:
- A data scientist searches for data they would like to train on (they can search either an individual Node, or a Network of Nodes)
- Once the data has been found, they may write a training plan and optionally pre-train a model
- The training plan and model are sent to the PyGrid Node in the form of a job request
- The PyGrid Node will gather the appropriate data from its database and send the data, the model, and the training plan to a Worker for processing
- The Worker performs the plan on the model using the data
- The result is returned to the Node
- The result is returned to the data scientist
For the last step, we're working on adding the capability for privacy budget tracking to be applied that will allow a data owner to "sign off" on whether or not a trained model should be released.
Note: For posterity sake, we previously used to refer to this process as "dynamic federated learning".
Node-only data-centric FL
Technically speaking, it isn't required to run a Network when performing data-centric federated learning. Alternatively, as a data owner, you may opt to only run a Node, but participate in a Network hosted by someone else. The Network host will not have access to your data.

Network-based data-centric FL
Many times you will wat to use a Network to allow multiple Nodes to be connected together. As a data owner, it's not strictly necessary to own and operate mulitple Nodes. PyGrid doesn't prescribe one way to organize Nodes and Networks, but we expose these applications to allow you and various related stakeholders to make the correct decision about your infrastructure needs.
Getting started
Currently, we suggest two ways to run PyGrid locally: Docker and manually running from source. With Docker, we can organize all the services we'd like to use and then boot them all in one command. With manually running from source, we have to run them as separate tasks.
Docker
To install Docker, just follow the docker documentation.
1. Setting the your hostfile
Before start the grid platform locally using Docker, we need to set up the domain names used by the bridge network. In order to use these nodes from outside of the containers context, you should add the following domain names on your /etc/hosts
127.0.0.1 network
127.0.0.1 alice
127.0.0.1 bob
127.0.0.1 charlie
127.0.0.1 dan
Note that you're not restricted to running 4 nodes and a network. You could instead run just a single node if you'd like - this is often all you need for model-centric federated learning. For the sake of our example, we'll use the network running 4 nodes underneath but you're welcome to modify it to your needs.
2. Run Docker Images
The latest PyGrid Network and Node images are also available on the Docker Hub.
To setup and start the PyGrid platform you just need start the docker-compose process.
$ docker-compose up
This will download the latest Openmined Docker images and start a grid platform with a network and 4 nodes. You can modify this setup by changing the docker-compose.yml file.
3. Optional - Build your own images
If you want to build your own custom images, you may do so using the following command for the Node:
docker build ./apps/node --file ./apps/node/Dockerfile --tag openmined/grid-node:mybuildname
Or for the Network:
docker build ./apps/network --file ./apps/network/Dockerfile --tag openmined/grid-network:mybuildname
Manual Start
Running a Node
Installation
First install
poetryand runpoetry installinapps/node
To start the PyGrid Node manually, run:
cd apps/node
./run.sh --id bob --port 5000 --start_local_db
You can pass the arguments or use environment variables to set the network configs.
Arguments
-h, --help- Shows the help message and exit-p [PORT], --port [PORT]- Port to run server on (default: 5000)--host [HOST]- The Node host--num_replicas [NUM]- The number of replicas to provide fault tolerance to model hosting--id [ID]- The ID of the Node--start_local_db- If this flag is used a SQLAlchemy DB URI is generated to use a local db
Environment Variables
GRID_NODE_PORT- Port to run server onGRID_NODE_HOST- The Node hostNUM_REPLICAS- Number of replicas to provide fault tolerance to model hostingDATABASE_URL- The Node database URLSECRET_KEY- The secret key
Running a Network
To start the PyGrid Network manually, run:
cd apps/network
./run.sh --port 7000 --start_local_db
You can pass the arguments or use environment variables to set the network configs.
Arguments
-h, --help- Shows the help message and exit-p [PORT], --port [PORT]- Port to run server on (default: 7000)--host [HOST]- The Network host--start_local_db- If this flag is used a SQLAlchemy DB URI is generated to use a local db
Environment Variables
GRID_NETWORK_PORT- Port to run server onGRID_NETWORK_HOST- The Network hostDATABASE_URL- The Network database URLSECRET_KEY- The secret key
PyGrid CLI
OpenMined PyGrid CLI is used for Infrastructure Management to deploy various PyGrid components to various cloud providers (AWS, GCP, Azure).
To get started, install the CLI first through this command:
pip install -e .
Running CLI
Install Terraform
Check Instructions here: https://learn.hashicorp.com/tutorials/terraform/install-cli
Deploy a Node to AWS
pygrid deploy --provider aws --app node
Deploy a Network to AWS
pygrid deploy --provider azure --app network
Contributing
If you're interested in contributing, check out our Contributor Guidelines.
Support
For support in using this library, please join the #lib_pygrid Slack channel. If you’d like to follow along with any code changes to the library, please join the #code_pygrid Slack channel. Click here to join our Slack community!






 Is there somewhere I missed to do?
Is there somewhere I missed to do?




 81 Dec 29, 2022
81 Dec 29, 2022
 86 Dec 21, 2022
86 Dec 21, 2022
 417 Dec 20, 2022
417 Dec 20, 2022
 5 Feb 10, 2022
5 Feb 10, 2022
 112 Dec 02, 2022
112 Dec 02, 2022
 148 Dec 28, 2022
148 Dec 28, 2022
 253 Jan 01, 2023
253 Jan 01, 2023
 14 Oct 24, 2022
14 Oct 24, 2022
 48 Dec 26, 2022
48 Dec 26, 2022
 7.4k Jan 01, 2023
7.4k Jan 01, 2023
 1 Nov 18, 2021
1 Nov 18, 2021
 41 Dec 14, 2022
41 Dec 14, 2022
 26 Dec 22, 2022
26 Dec 22, 2022
 2 Jan 07, 2022
2 Jan 07, 2022
 4 Nov 28, 2022
4 Nov 28, 2022
 48 Nov 06, 2022
48 Nov 06, 2022
 543 Dec 20, 2022
543 Dec 20, 2022
 11 Nov 25, 2022
11 Nov 25, 2022
 19 Oct 19, 2022
19 Oct 19, 2022