当前位置:网站首页>A complete tutorial for getting started with redis: hyperloglog
A complete tutorial for getting started with redis: hyperloglog
2022-07-04 22:53:00 【Gu Ge academic】
HyperLogLog It's not a new data structure ( The actual type is string type ), and
Is a cardinality algorithm , adopt HyperLogLog You can use very little memory space to complete the independent total number
The statistics of , Data sets can be IP、Email、ID etc. .HyperLogLog Provides 3 An order :
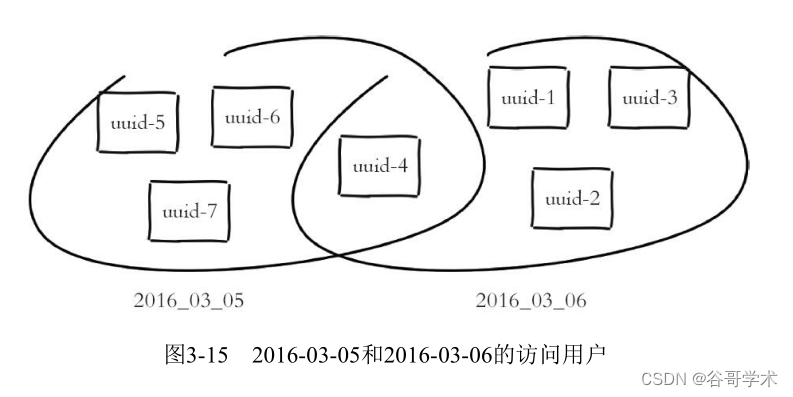
pfadd、pfcount、pfmerge. for example 2016-03-06 The access user is uuid-1、uuid-2、
uuid-3、uuid-4,2016-03-05 The access user is uuid-4、uuid-5、uuid-6、uuid-7, Such as
chart 3-15 Shown .
Be careful
HyperLogLog The algorithm is composed of Philippe
Flajolet(https://en.wikipedia.org/wiki/Philippe_Flajolet) stay The analysis of a
near-optimal cardinality estimation algorithm In this paper , If the reader is interested
You can read it yourself .
1. add to
pfadd key element [element … ]
pfadd Used to direct to HyperLogLog Additive elements , If the addition is successful, return 1:
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
2. Count the number of independent users
pfcount key [key … ]
pfcount Used to calculate one or more HyperLogLog Independent total of , for example
2016_03_06:unique:ids The total number of independents is 4:
127.0.0.1:6379> pfcount 2016_03_06:unique:ids
(integer) 4
If at this time to 2016_03_06:unique:ids Insert uuid-1、uuid-2、uuid-3、uuid-
90, The result is 5( newly added uuid-90):
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-90"
(integer) 1
127.0.0.1:6379> pfcount 2016_03_06:unique:ids
(integer) 5
At present, the effect of memory saving in this example is not very obvious , Now use the script to
HyperLogLog Insert 100 m id, Record before inserting info memory:
127.0.0.1:6379> info memory
# Memory
used_memory:835144
used_memory_human:815.57K
... towards 2016_05_01:unique:ids Insert 100 Million users , Insert... Every time 1000 strip :
elements=""
key="2016_05_01:unique:ids"
for i in `seq 1 1000000`
do
elements="${elements} uuid-"${i}
if [[ $((i%1000)) == 0 ]];
then
redis-cli pfadd ${key} ${elements}
elements=""
fi
done
When the above code is executed , You can see that the memory is only increased 15K about :
127.0.0.1:6379> info memory
# Memory
used_memory:850616
used_memory_human:830.68K
however , And you can see that pfcount The result is not 100 ten thousand :
127.0.0.1:6379> pfcount 2016_05_01:unique:ids
(integer) 1009838
It can be done to 100 m uuid Use the collection type to test , The code is as follows :
elements=""
key="2016_05_01:unique:ids:set"
for i in `seq 1 1000000`
do
elements="${elements} "${i}
if [[ $((i%1000)) == 0 ]];
then
redis-cli sadd ${key} ${elements}
elements=""
fi
done
You can see the memory usage 84MB:
127.0.0.1:6379> info memory
# Memory
used_memory:88702680
used_memory_human:84.59M
But the number of independent users is 100 ten thousand :
127.0.0.1:6379> scard 2016_05_01:unique:ids:set
(integer) 1000000
surface 3-6 Lists the use of set types and HperLogLog Count the occupied space of millions of users
Than .

You can see ,HyperLogLog Memory footprint is surprisingly small , But with such a small space
Such a huge amount of data , It must not be 100% Right , There must be an error rate .Redis Officer,
The number given by Fang is 0.81% The error rate of .
3. Merge
pfmerge destkey sourcekey [sourcekey ...]
pfmerge You can find multiple HyperLogLog And assign to destkey, For example, to calculate
2016 year 3 month 5 Day and 3 month 6 Number of independent users per day , This can be done as follows , Sure
See that the number of end independent users is 7:
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
127.0.0.1:6379> pfadd 2016_03_05:unique:ids "uuid-4" "uuid-5" "uuid-6" "uuid-7"
(integer) 1
127.0.0.1:6379> pfmerge 2016_03_05_06:unique:ids 2016_03_05:unique:ids
2016_03_06:unique:ids
OK
127.0.0.1:6379> pfcount 2016_03_05_06:unique:ids
(integer) 7
HyperLogLog Memory footprint is very small , But there is an error rate , Developers are working on data
During structure selection, only the following two items need to be confirmed :
· Just to calculate the independent total , No need to get a single piece of data .
· Can tolerate a certain error rate , After all HyperLogLog It has a great advantage in the occupation of memory
potential .
边栏推荐
- Redis入门完整教程:事务与Lua
- Logo Camp d'entraînement section 3 techniques créatives initiales
- Close system call analysis - Performance Optimization
- 质量体系建设之路的分分合合
- Analog rocker controlled steering gear
- Sword finger offer 67 Convert a string to an integer
- Redis入门完整教程:客户端通信协议
- Microservices -- Opening
- leetcode 72. Edit distance edit distance (medium)
- String类中的常用方法
猜你喜欢
Advanced area of attack and defense world misc 3-11

攻防世界 misc 高手进阶区 a_good_idea

NFT insider 64: e-commerce giant eBay submitted an NFT related trademark application, and KPMG will invest $30million in Web3 and metauniverse

The sandbox has reached a cooperation with digital Hollywood to accelerate the economic development of creators through human resource development
Breakpoint debugging under vs2019 c release
Redis入门完整教程:GEO
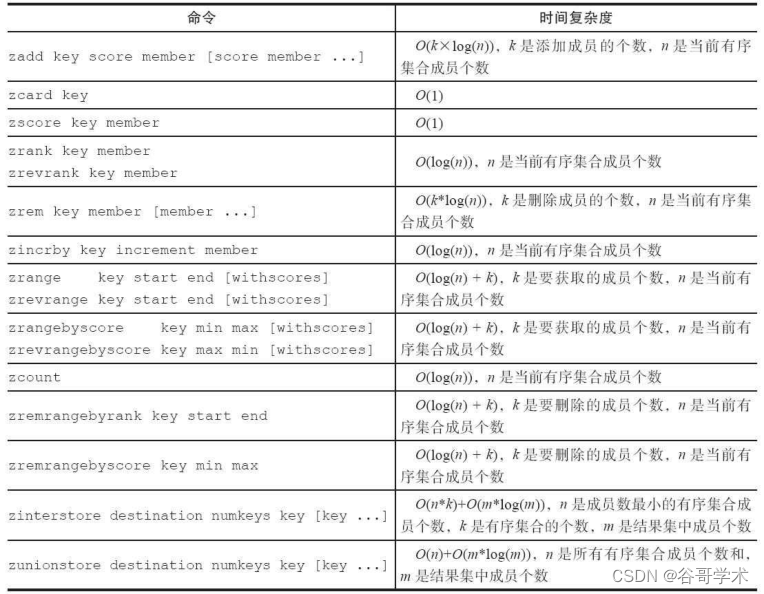
Redis入门完整教程:有序集合详解
Redis入门完整教程:HyperLogLog
Business is too busy. Is there really no reason to have time for automation?
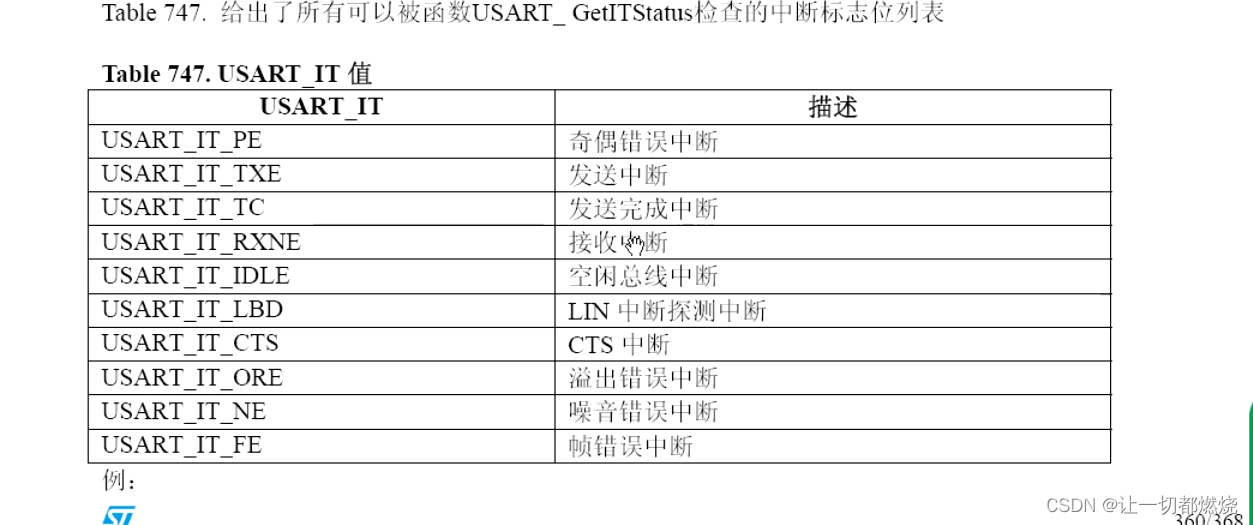
Serial port data frame
随机推荐
串口数据帧
Erik baleog and Olaf, advanced area of misc in the attack and defense world
Redis的持久化机制
Advanced area of attack and defense world misc 3-11
【机器学习】手写数字识别
The sandbox has reached a cooperation with digital Hollywood to accelerate the economic development of creators through human resource development
In Linux, I call odspcmd to query the database information. How to output silently is to only output values. Don't do this
About stack area, heap area, global area, text constant area and program code area
[try to hack] wide byte injection
High school physics: linear motion
It is said that software testing is very simple, but why are there so many dissuasions?
String类中的常用方法
Advanced area a of attack and defense world misc Masters_ good_ idea
Serial port data frame
Feature scaling normalization
The new version judges the code of PC and mobile terminal, the mobile terminal jumps to the mobile terminal, and the PC jumps to the latest valid code of PC terminal
Wake up day, how do I step by step towards the road of software testing
Common methods in string class
Detailed explanation of heap sort code
Install the gold warehouse database of NPC