当前位置:网站首页>Close system call analysis - Performance Optimization
Close system call analysis - Performance Optimization
2022-07-04 22:31:00 【51CTO】
Today, I was pulled to work overtime to deal with performance problems :
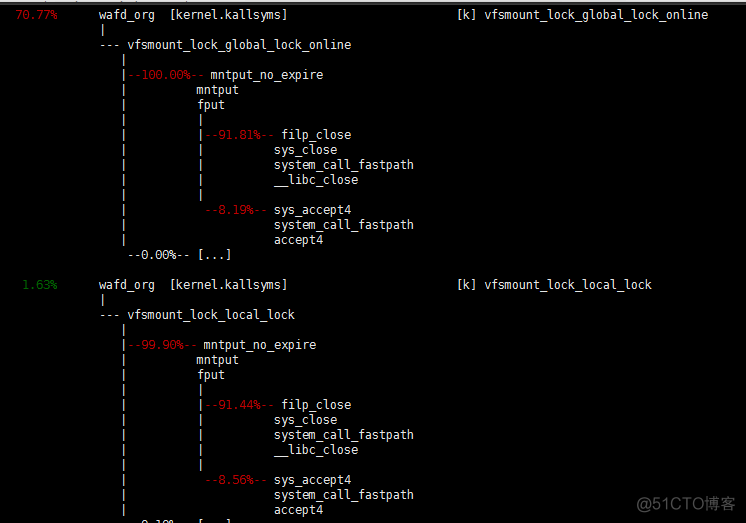
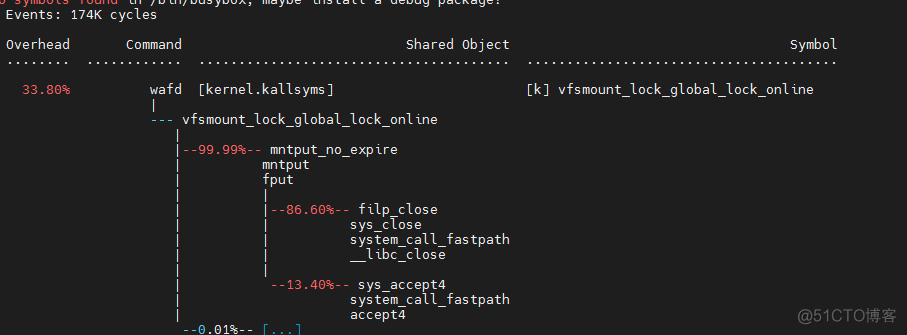
The comparison result after optimization is : Also in 5wcps Under the circumstances , Former cpu Usage rate is 90%, Now? cpu Usage rate is 30%! from cpu From the angle of view, it has been improved a lot , meanwhile perf top It turns out , close Percentage of system calls cpu Also reduced a lot
There are the following problems due to the previous multi-threaded architecture :
1、 In bulk close System calls cause problems ; Here is the business that has not been handled well , meanwhile close Do exist vfs Of lock Conflict
2、 Multithreaded batch accept open fd It will also trigger vfs The global lock of
/*
* cloning flags:
*/
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */
#define CLONE_VM 0x00000100 /* set if VM shared between processes */
#define CLONE_FS 0x00000200 /* set if fs info shared between processes Each process has its own root directory and current working directory , The kernel using struct fs_struct To record this information , Of the process descriptor fs Field refers to the process fs_struct structure .*/
#define CLONE_FILES 0x00000400 /* set if open files shared between processes The process also needs to record the files it opens . All files opened by the process are used struct files_struct To record */
#define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */
#define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */
#define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */
#define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */
#define CLONE_THREAD 0x00010000 /* Same thread group? */
#define CLONE_NEWNS 0x00020000 /* New namespace group? */
#define CLONE_SYSVSEM 0x00040000 /* share system V SEM_UNDO semantics */
#define CLONE_SETTLS 0x00080000 /* create a new TLS for the child */
#define CLONE_PARENT_SETTID 0x00100000 /* set the TID in the parent */
#define CLONE_CHILD_CLEARTID 0x00200000 /* clear the TID in the child */
#define CLONE_DETACHED 0x00400000 /* Unused, ignored */
#define CLONE_UNTRACED 0x00800000 /* set if the tracing process can't force CLONE_PTRACE on this clone */
#define CLONE_CHILD_SETTID 0x01000000 /* set the TID in the child */
/* 0x02000000 was previously the unused CLONE_STOPPED (Start in stopped state)
and is now available for re-use. */
#define CLONE_NEWUTS 0x04000000 /* New utsname group? */
#define CLONE_NEWIPC 0x08000000 /* New ipcs */
#define CLONE_NEWUSER 0x10000000 /* New user namespace */
#define CLONE_NEWPID 0x20000000 /* New pid namespace */
#define CLONE_NEWNET 0x40000000 /* New network namespace */
#define CLONE_IO 0x80000000 /* Clone io context */
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
int sys_fork(struct pt_regs *regs)
{
return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL);
}
/*
* This is trivial, and on the face of it looks like it
* could equally well be done in user mode.
*
* Not so, for quite unobvious reasons - register pressure.
* In user mode vfork() cannot have a stack frame, and if
* done by calling the "clone()" system call directly, you
* do not have enough call-clobbered registers to hold all
* the information you need.
*/
int sys_vfork(struct pt_regs *regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs->sp, regs, 0,
NULL, NULL);
}
long
sys_clone(unsigned long clone_flags, unsigned long newsp,
void __user *parent_tid, void __user *child_tid, struct pt_regs *regs)
{
if (!newsp)
newsp = regs->sp;
return do_fork(clone_flags, newsp, regs, 0, parent_tid, child_tid);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
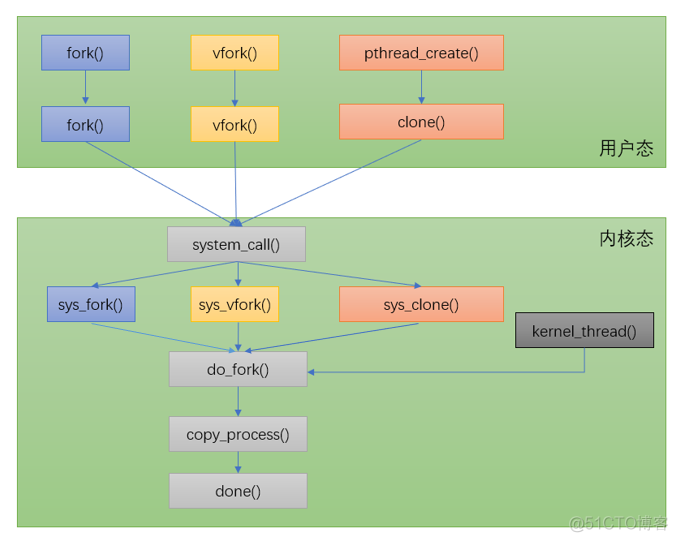
Generally speaking fork The post parent-child process is separated
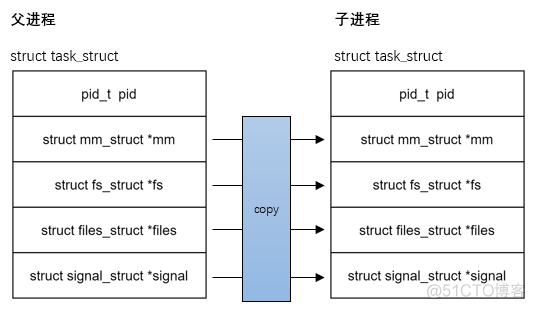
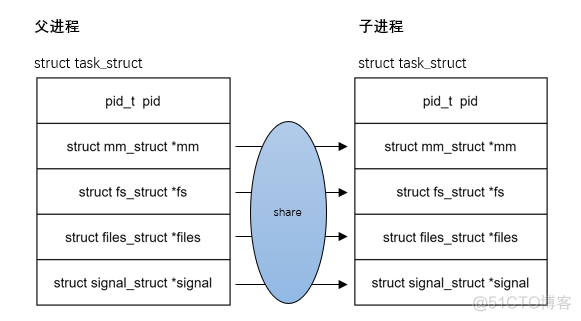
vfork: The parent-child process shares mm;vfork System call is different from fork, use vfork The child processes created share the address space , That is, the child process runs entirely in the address space of the parent process , The modification of any data in the virtual address space by the child process is also seen by the parent process . But with vfork After creating a subprocess , The parent process is blocked until the child process calls exec or exit. This benefit is in Zijin
After the procedure is created, it is only for calling exec When executing another program , Because it will not have any reference to the address space of the parent process , So copying the address space is redundant , adopt vfork Can reduce unnecessary expenses .
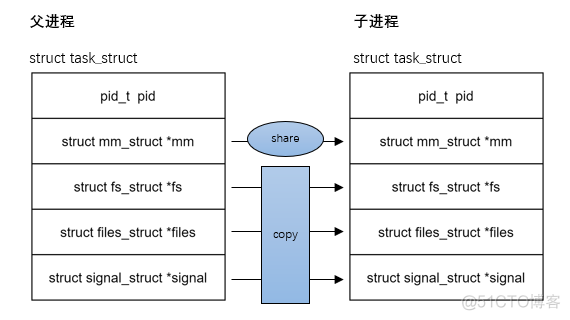
pthread_create: Parent child processes share the main mm fs file signal And so on
So in open as well as close fd yes Overall files File lock needs to be locked ;
Also refer to : The analysis of this article ; Compare the following two pictures : Find a close by 30us One for ns Level ( Show 0us)
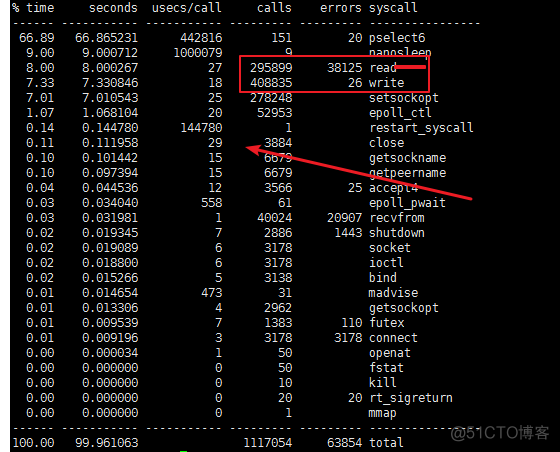
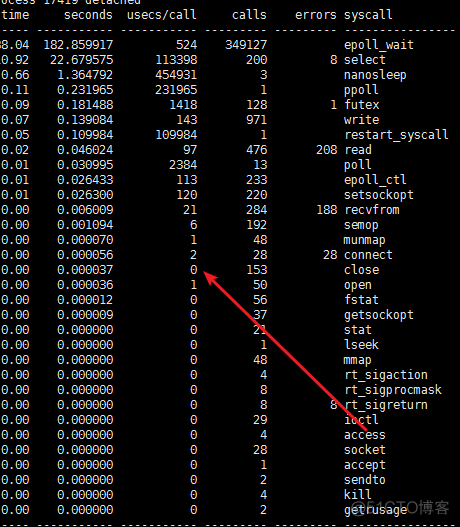
close System call analysis
SYSCALL_DEFINE1(close, unsigned int, fd)
{
struct file * filp;
struct files_struct *files = current->files;
struct fdtable *fdt;
int retval;
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
if (fd >= fdt->max_fds)
goto out_unlock;
filp = fdt->fd[fd];
if (!filp)
goto out_unlock;
rcu_assign_pointer(fdt->fd[fd], NULL);
FD_CLR(fd, fdt->close_on_exec);
__put_unused_fd(files, fd);
spin_unlock(&files->file_lock);
retval = filp_close(filp, files);
/* can't restart close syscall because file table entry was cleared */
if (unlikely(retval == -ERESTARTSYS ||
retval == -ERESTARTNOINTR ||
retval == -ERESTARTNOHAND ||
retval == -ERESTART_RESTARTBLOCK))
retval = -EINTR;
return retval;
out_unlock:
spin_unlock(&files->file_lock);
return -EBADF;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
/*
* "id" is the POSIX thread ID. We use the
* files pointer for this..
*/
int filp_close(struct file *filp, fl_owner_t id)
{
int retval = 0;
if (!file_count(filp)) {
printk(KERN_ERR "VFS: Close: file count is 0\n");
return 0;
}
if (filp->f_op && filp->f_op->flush)
retval = filp->f_op->flush(filp, id);
if (likely(!(filp->f_mode & FMODE_PATH))) {
dnotify_flush(filp, id);
locks_remove_posix(filp, id);
}
fput(filp);
return retval;
}
void fput(struct file *file)
{// Pay attention to fput function , This function will first count the references of the file -1, Then judge whether it is 0, by 0 And then continue the process , That is to say, when socket When there are multiple references , Only the last one close Will trigger the subsequent scheduling destruction process ,
if (atomic_long_dec_and_test(&file->f_count))
__fput(file);
}
/* the real guts of fput() - releasing the last reference to file
*/
static void __fput(struct file *file)
{
struct dentry *dentry = file->f_path.dentry;
struct vfsmount *mnt = file->f_path.mnt;
struct inode *inode = dentry->d_inode;
might_sleep();
fsnotify_close(file);
/*
* The function eventpoll_release() should be the first called
* in the file cleanup chain.
*/
eventpoll_release(file);
locks_remove_flock(file);
if (unlikely(file->f_flags & FASYNC)) {
if (file->f_op && file->f_op->fasync)
file->f_op->fasync(-1, file, 0);
}
if (file->f_op && file->f_op->release)
file->f_op->release(inode, file);// stay close The file will be called in the system call release operation
security_file_free(file);
ima_file_free(file);
if (unlikely(S_ISCHR(inode->i_mode) && inode->i_cdev != NULL &&
!(file->f_mode & FMODE_PATH))) {
cdev_put(inode->i_cdev);
}
fops_put(file->f_op);
put_pid(file->f_owner.pid);
file_sb_list_del(file);
if ((file->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_dec(inode);
if (file->f_mode & FMODE_WRITE)
drop_file_write_access(file);
file->f_path.dentry = NULL;
file->f_path.mnt = NULL;
file_free(file);
dput(dentry);
mntput(mnt);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
stay close The file will be called in the system call release operation ;socket The file operation structure of the implementation is as follows , Among them, this paper discusses release The function is implemented as sock_close;
/*
* Socket files have a set of 'special' operations as well as the generic file ones. These don't appear
* in the operation structures but are done directly via the socketcall() multiplexor.
*/
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_sock_ioctl,
#endif
.mmap = sock_mmap,
.open = sock_no_open, /* special open code to disallow open via /proc */
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
static int sock_close(struct inode *inode, struct file *filp)
{
/*
* It was possible the inode is NULL we were
* closing an unfinished socket.
*/
if (!inode) {
printk(KERN_DEBUG "sock_close: NULL inode\n");
return 0;
}
sock_release(SOCKET_I(inode));
return 0;
}
/**
* sock_release - close a socket
* @sock: socket to close
*
* The socket is released from the protocol stack if it has a release
* callback, and the inode is then released if the socket is bound to
* an inode not a file.
*/
void sock_release(struct socket *sock)
{
if (sock->ops) {
struct module *owner = sock->ops->owner;
sock->ops->release(sock);/* call socket In operation release At present, it is mainly for use inet_release If you use tcp sock Last
call tcp_close*/
sock->ops = NULL;
module_put(owner);
}
if (rcu_dereference_protected(sock->wq, 1)->fasync_list)
printk(KERN_ERR "sock_release: fasync list not empty!\n");
percpu_sub(sockets_in_use, 1);/* Reduce cpu Number of sockets */
if (!sock->file) {
iput(SOCK_INODE(sock));
return;
}
sock->file = NULL; /* Socket is closed , Carry on close The system calls other processes */
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
http proxy server (3-4-7 Layer of the agent )- Network event library common component 、 kernel kernel drive Camera drive tcpip Network protocol stack 、netfilter、bridge Seems to have seen !!!! But he that doeth good Don't ask future -- Height and weight 180 Fat man
边栏推荐
- Alibaba launched a new brand "Lingyang" and is committed to becoming a "digital leader"
- Redis sentinel simply looks at the trade-offs between distributed high availability and consistency
- Introduction and application of bigfilter global transaction anti duplication component
- 卷积神经网络模型之——LeNet网络结构与代码实现
- Shell script implements application service log warehousing MySQL
- 国产数据库乱象
- Logo Camp d'entraînement section 3 techniques créatives initiales
- You don't have to run away to delete the library! Detailed MySQL data recovery
- PHP short video source code, thumb animation will float when you like it
- High school physics: linear motion
猜你喜欢
LOGO特训营 第五节 字体结构与设计常用技法
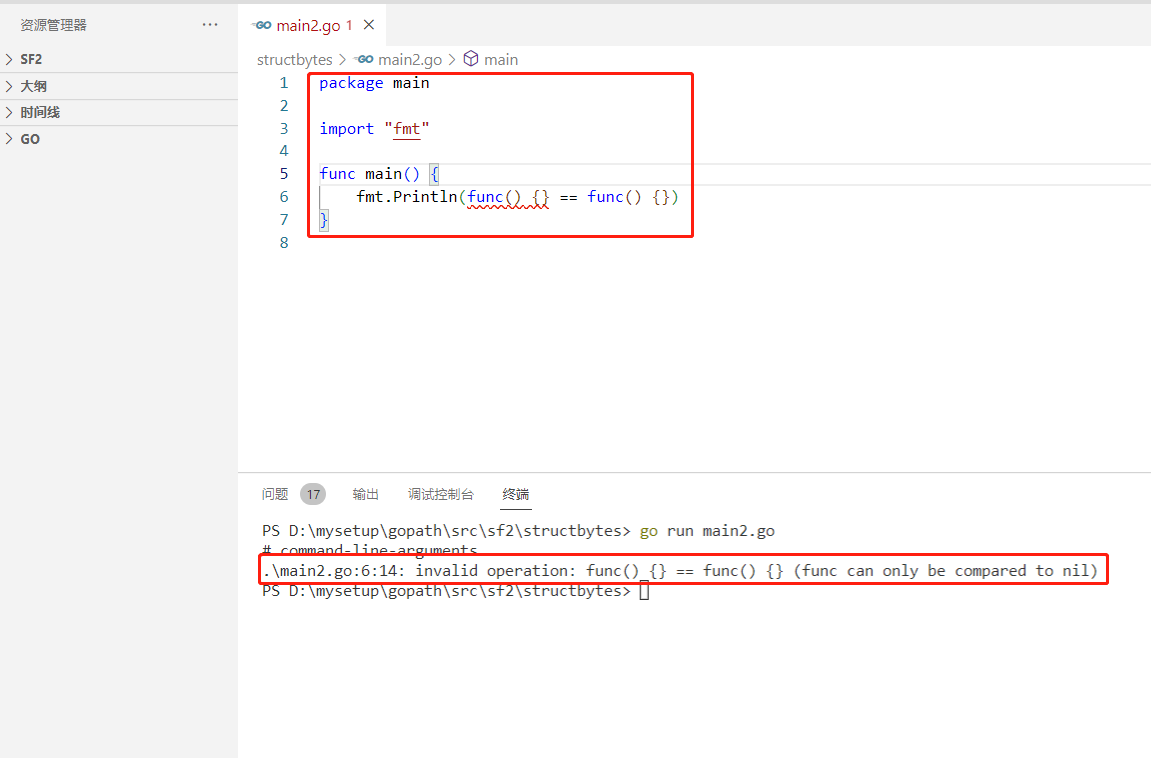
2022-07-04:以下go语言代码输出什么?A:true;B:false;C:编译错误。 package main import “fmt“ func main() { fmt.Pri

赋能数字经济 福昕软件出席金砖国家可持续发展高层论坛
Scala download and configuration

Challenges faced by virtual human industry

Xiangjiang Kunpeng joined the shengteng Wanli partnership program and continued to write a new chapter of cooperation with Huawei
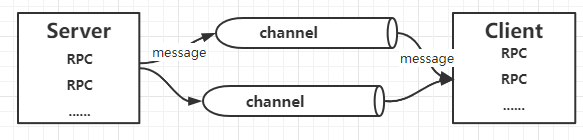
Play with grpc - go deep into concepts and principles
Kdd2022 | what features are effective for interaction?

Logo special training camp section III initial creative techniques
可视化任务编排&拖拉拽 | Scaleph 基于 Apache SeaTunnel的数据集成
随机推荐
Radio and television Wuzhou signed a cooperation agreement with Huawei to jointly promote the sustainable development of shengteng AI industry
ApacheCN 翻译、校对、笔记整理活动进度公告 2022.7
Alibaba launched a new brand "Lingyang" and is committed to becoming a "digital leader"
短视频系统源码,点击屏幕空白处键盘不自动收起
PostgreSQL服务端编程聚合和分组
Microservices -- Opening
Play with grpc - go deep into concepts and principles
凭借了这份 pdf,最终拿到了阿里,字节,百度等八家大厂 offer
i.MX6ULL驱动开发 | 24 - 基于platform平台驱动模型点亮LED
并发网络模块化 读书笔记转
使用 BlocConsumer 同时构建响应式组件和监听状态
Interview question 01.08 Zero matrix
The use of complex numbers in number theory and geometry - Cao Zexian
Interview question 01.01 Determine whether the character is unique
能源势动:电力行业的碳中和该如何实现?
力扣_回文数
A large number of virtual anchors in station B were collectively forced to refund: revenue evaporated, but they still owe station B; Jobs was posthumously awarded the U.S. presidential medal of freedo
Challenges faced by virtual human industry
机器人相关课程考核材料归档实施细则2022版本
close系统调用分析-性能优化