当前位置:网站首页>close系统调用分析-性能优化
close系统调用分析-性能优化
2022-07-04 21:35:00 【51CTO】
今天被拉过来加班处理性能问题:
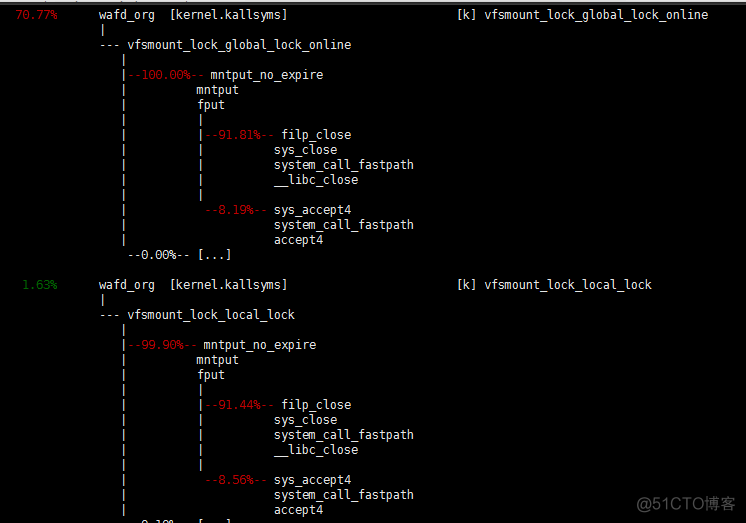
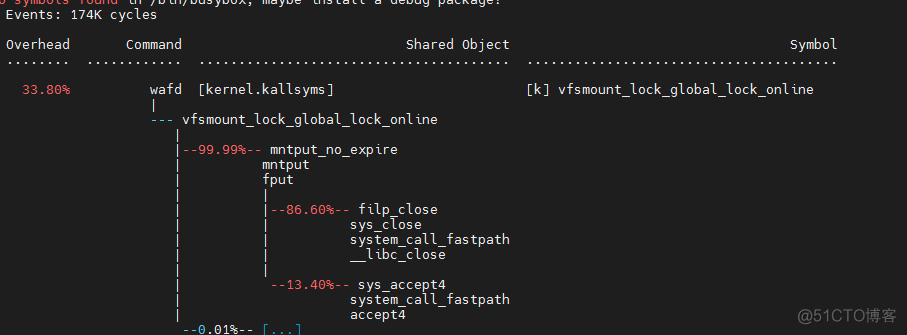
优化后对比的结果为:同样在5wcps的情况下,以前的cpu 使用率为90%, 现在cpu使用率为30%! 从cpu 角度看提高了很多, 同时perf top 结果看, close系统调用所占cpu也降低了不少
由于之前采用多线程架构存在如下问题:
1、批量的close系统调用导致问题;此处是业务没有处理好,同时close确实存在vfs的lock冲突
2、 多线程批量accept open fd 也会触发vfs的全局锁
/*
* cloning flags:
*/
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */
#define CLONE_VM 0x00000100 /* set if VM shared between processes */
#define CLONE_FS 0x00000200 /* set if fs info shared between processes 每个进程都有自己的根目录和当前工作目录,内核使用struct fs_struct来记录这些信息,进程描述符的fs字段便是指向该进程的fs_struct结构。*/
#define CLONE_FILES 0x00000400 /* set if open files shared between processes 进程还需要记录自己打开的文件。进程已经打开的所有文件使用struct files_struct来记录*/
#define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */
#define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */
#define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */
#define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */
#define CLONE_THREAD 0x00010000 /* Same thread group? */
#define CLONE_NEWNS 0x00020000 /* New namespace group? */
#define CLONE_SYSVSEM 0x00040000 /* share system V SEM_UNDO semantics */
#define CLONE_SETTLS 0x00080000 /* create a new TLS for the child */
#define CLONE_PARENT_SETTID 0x00100000 /* set the TID in the parent */
#define CLONE_CHILD_CLEARTID 0x00200000 /* clear the TID in the child */
#define CLONE_DETACHED 0x00400000 /* Unused, ignored */
#define CLONE_UNTRACED 0x00800000 /* set if the tracing process can't force CLONE_PTRACE on this clone */
#define CLONE_CHILD_SETTID 0x01000000 /* set the TID in the child */
/* 0x02000000 was previously the unused CLONE_STOPPED (Start in stopped state)
and is now available for re-use. */
#define CLONE_NEWUTS 0x04000000 /* New utsname group? */
#define CLONE_NEWIPC 0x08000000 /* New ipcs */
#define CLONE_NEWUSER 0x10000000 /* New user namespace */
#define CLONE_NEWPID 0x20000000 /* New pid namespace */
#define CLONE_NEWNET 0x40000000 /* New network namespace */
#define CLONE_IO 0x80000000 /* Clone io context */
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
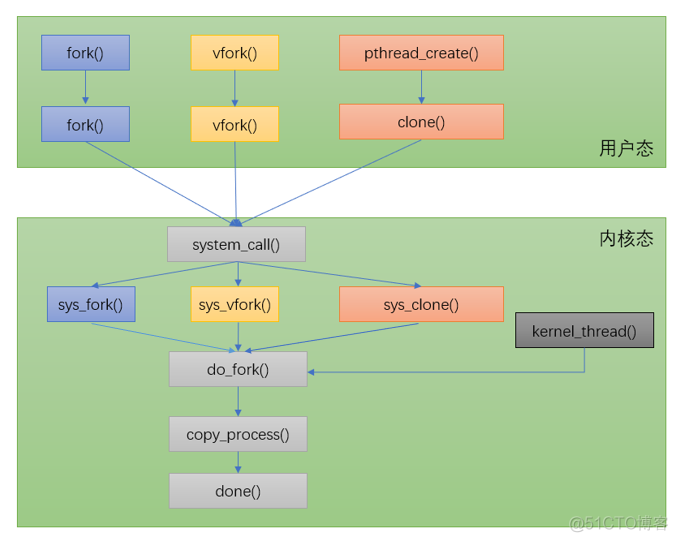
int sys_fork(struct pt_regs *regs)
{
return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL);
}
/*
* This is trivial, and on the face of it looks like it
* could equally well be done in user mode.
*
* Not so, for quite unobvious reasons - register pressure.
* In user mode vfork() cannot have a stack frame, and if
* done by calling the "clone()" system call directly, you
* do not have enough call-clobbered registers to hold all
* the information you need.
*/
int sys_vfork(struct pt_regs *regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs->sp, regs, 0,
NULL, NULL);
}
long
sys_clone(unsigned long clone_flags, unsigned long newsp,
void __user *parent_tid, void __user *child_tid, struct pt_regs *regs)
{
if (!newsp)
newsp = regs->sp;
return do_fork(clone_flags, newsp, regs, 0, parent_tid, child_tid);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
一般来说 fork 后父子进程隔离开
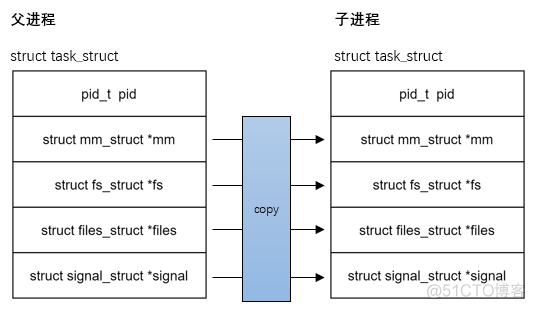
vfork:父子进程共享mm;vfork系统调用不同于fork,用vfork创建的子进程共享地址空间,也就是说子进程完全运行在父进程的地址空间上,子进程对虚拟地址空间任何数据的修改同样为父进程所见。但是用vfork创建子进程后,父进程会被阻塞直到子进程调用exec或exit。这样的好处是在子进
程被创建后仅仅是为了调用exec执行另一个程序时,因为它就不会对父进程的地址空间有任何引用,所以对地址空间的复制是多余的,通过vfork可以减少不必要的开销。
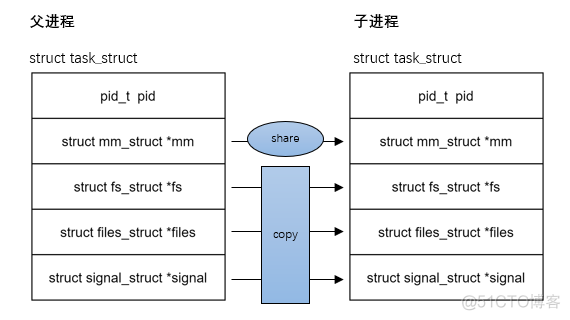
pthread_create:父子进程共享主要 mm fs file signal 等资源
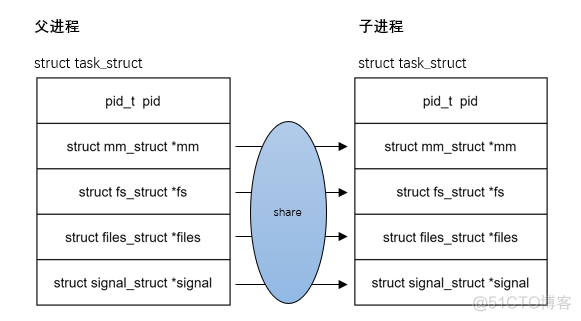
所以在open以及close fd是 全局的files文件锁需要加锁;
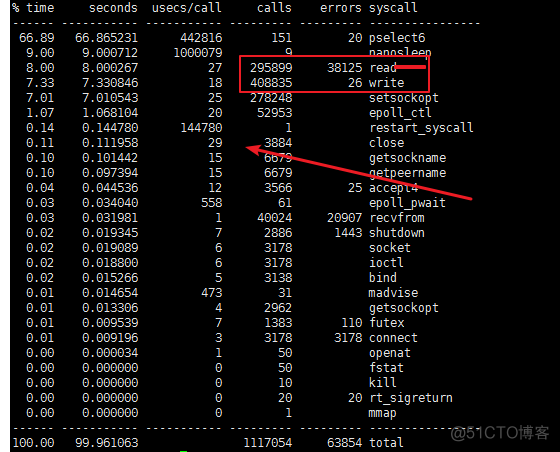
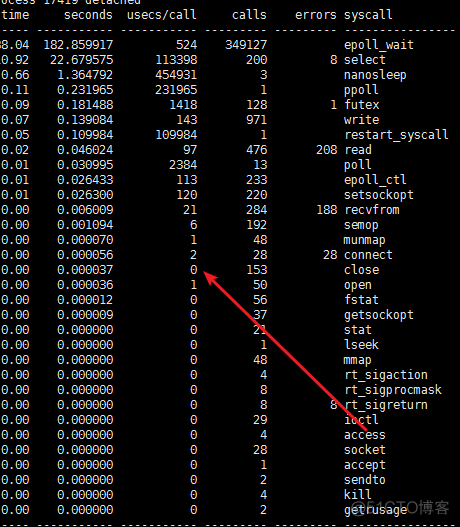
同时参考: 这篇文章的分析;对比下面两张图: 发现一个close为30us一个为ns级别(显示0us)
close系统调用分析
SYSCALL_DEFINE1(close, unsigned int, fd)
{
struct file * filp;
struct files_struct *files = current->files;
struct fdtable *fdt;
int retval;
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
if (fd >= fdt->max_fds)
goto out_unlock;
filp = fdt->fd[fd];
if (!filp)
goto out_unlock;
rcu_assign_pointer(fdt->fd[fd], NULL);
FD_CLR(fd, fdt->close_on_exec);
__put_unused_fd(files, fd);
spin_unlock(&files->file_lock);
retval = filp_close(filp, files);
/* can't restart close syscall because file table entry was cleared */
if (unlikely(retval == -ERESTARTSYS ||
retval == -ERESTARTNOINTR ||
retval == -ERESTARTNOHAND ||
retval == -ERESTART_RESTARTBLOCK))
retval = -EINTR;
return retval;
out_unlock:
spin_unlock(&files->file_lock);
return -EBADF;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
/*
* "id" is the POSIX thread ID. We use the
* files pointer for this..
*/
int filp_close(struct file *filp, fl_owner_t id)
{
int retval = 0;
if (!file_count(filp)) {
printk(KERN_ERR "VFS: Close: file count is 0\n");
return 0;
}
if (filp->f_op && filp->f_op->flush)
retval = filp->f_op->flush(filp, id);
if (likely(!(filp->f_mode & FMODE_PATH))) {
dnotify_flush(filp, id);
locks_remove_posix(filp, id);
}
fput(filp);
return retval;
}
void fput(struct file *file)
{//注意下fput函数,该函数会先现将文件的引用计数-1,然后判断是否为0,为0的时候才会进行继续的流程,也就是说当socket存在多个引用的时候,只有最后一个close才会触发后面的调度销毁流程,
if (atomic_long_dec_and_test(&file->f_count))
__fput(file);
}
/* the real guts of fput() - releasing the last reference to file
*/
static void __fput(struct file *file)
{
struct dentry *dentry = file->f_path.dentry;
struct vfsmount *mnt = file->f_path.mnt;
struct inode *inode = dentry->d_inode;
might_sleep();
fsnotify_close(file);
/*
* The function eventpoll_release() should be the first called
* in the file cleanup chain.
*/
eventpoll_release(file);
locks_remove_flock(file);
if (unlikely(file->f_flags & FASYNC)) {
if (file->f_op && file->f_op->fasync)
file->f_op->fasync(-1, file, 0);
}
if (file->f_op && file->f_op->release)
file->f_op->release(inode, file);//在close系统调用中会调用文件的release操作
security_file_free(file);
ima_file_free(file);
if (unlikely(S_ISCHR(inode->i_mode) && inode->i_cdev != NULL &&
!(file->f_mode & FMODE_PATH))) {
cdev_put(inode->i_cdev);
}
fops_put(file->f_op);
put_pid(file->f_owner.pid);
file_sb_list_del(file);
if ((file->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_dec(inode);
if (file->f_mode & FMODE_WRITE)
drop_file_write_access(file);
file->f_path.dentry = NULL;
file->f_path.mnt = NULL;
file_free(file);
dput(dentry);
mntput(mnt);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
在close系统调用中会调用文件的release操作;socket实现的文件操作结构如下所示,其中本文讨论的release函数实现为sock_close;
/*
* Socket files have a set of 'special' operations as well as the generic file ones. These don't appear
* in the operation structures but are done directly via the socketcall() multiplexor.
*/
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_sock_ioctl,
#endif
.mmap = sock_mmap,
.open = sock_no_open, /* special open code to disallow open via /proc */
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
static int sock_close(struct inode *inode, struct file *filp)
{
/*
* It was possible the inode is NULL we were
* closing an unfinished socket.
*/
if (!inode) {
printk(KERN_DEBUG "sock_close: NULL inode\n");
return 0;
}
sock_release(SOCKET_I(inode));
return 0;
}
/**
* sock_release - close a socket
* @sock: socket to close
*
* The socket is released from the protocol stack if it has a release
* callback, and the inode is then released if the socket is bound to
* an inode not a file.
*/
void sock_release(struct socket *sock)
{
if (sock->ops) {
struct module *owner = sock->ops->owner;
sock->ops->release(sock);/* 调用socket操作中的release 目前来看主要是对用 inet_release 如果使用tcp sock 最后
调用tcp_close*/
sock->ops = NULL;
module_put(owner);
}
if (rcu_dereference_protected(sock->wq, 1)->fasync_list)
printk(KERN_ERR "sock_release: fasync list not empty!\n");
percpu_sub(sockets_in_use, 1);/* 减少cpu的套接口数量 */
if (!sock->file) {
iput(SOCK_INODE(sock));
return;
}
sock->file = NULL; /* 套接口完成关闭,继续执行close系统调用其他流程 */
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
http代理服务器(3-4-7层代理)-网络事件库公共组件、内核kernel驱动 摄像头驱动 tcpip网络协议栈、netfilter、bridge 好像看过!!!! 但行好事 莫问前程 --身高体重180的胖子
边栏推荐
- What is the stock account opening process? Is it safe to use flush mobile stock trading software?
- Compréhension approfondie du symbole [langue C]
- Sorting and sharing of selected papers, systems and applications related to the most comprehensive mixed expert (MOE) model in history
- How to remove the black dot in front of the title in word document
- 【公开课预告】:视频质量评价基础与实践
- 做BI开发,为什么一定要熟悉行业和企业业务?
- 面试官:说说XSS攻击是什么?
- flink1.13 sql基础语法(一)DDL、DML
- Caduceus从未停止创新,去中心化边缘渲染技术让元宇宙不再遥远
- 大厂的广告系统升级,怎能少了大模型的身影
猜你喜欢




随机推荐
开户哪家券商比较好?网上开户安全吗
Acwing 2022 daily question
什么是商业智能(BI),就看这篇文章足够了
能源势动:电力行业的碳中和该如何实现?
类方法和类变量的使用
File read write
new IntersectionObserver 使用笔记
OMS系统实战的三两事
Flutter TextField示例
MongoDB聚合操作总结
Go language loop statement (3 in Lesson 10)
How to implement Devops with automatic tools
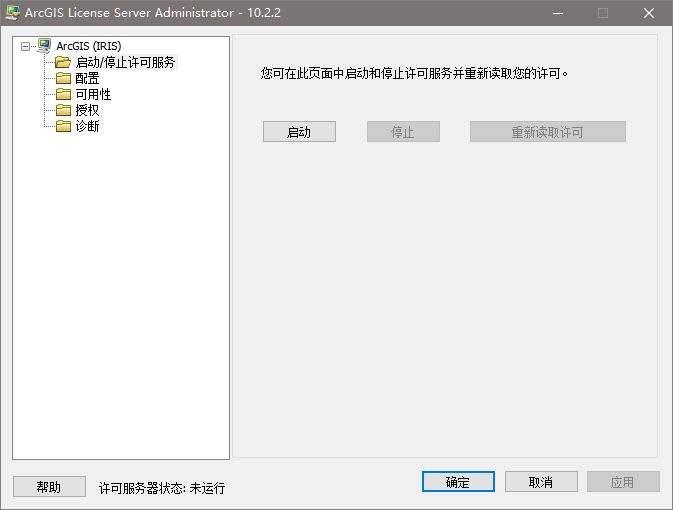
ArcGIS 10.2.2 | solution to the failure of ArcGIS license server to start
如何借助自动化工具落地DevOps
Analysis of maker education technology in the Internet Era
机器学习笔记 - 互信息Mutual Information
Bookmark
Shutter textfield example
【C语言进阶篇】数组&&指针&&数组笔试题
How much is the minimum stock account opening commission? Is it safe to open an account online