当前位置:网站首页>OMS系统实战的三两事
OMS系统实战的三两事
2022-07-04 20:31:00 【keycasiter】
OMS系统实战的三两事
1. 前言
这是一篇关于供应链业务相关的OMS系统实战技术文章,整理自近半年的开发实践,由于业务背景的差异化、具体落地的独特性以及个人业务知识的局限性,这里不做普适性供应链业务领域的深入讨论,仅论述自身业务场景中技术方案的实现过程,不可避免会出现部分内容略带一些特殊性和局限性。
首先,从业务架构和系统架构出发,简单鸟瞰业务构成和系统构建。其次,在庞大复杂的供应链业务中梳理出较为核心的单据业务、库存管理的演进过程。再次,从技术视角抽取了关联数据映射、状态数据隔离、分布式事务业务化、幂等改造、防重键扩展、动态库存挑战等一般功能实践,进行技术方案设计的讨论。最后,整理了一些比较典型的问题,给出自己的一些思考。
2. 架构设计
2.1 业务架构
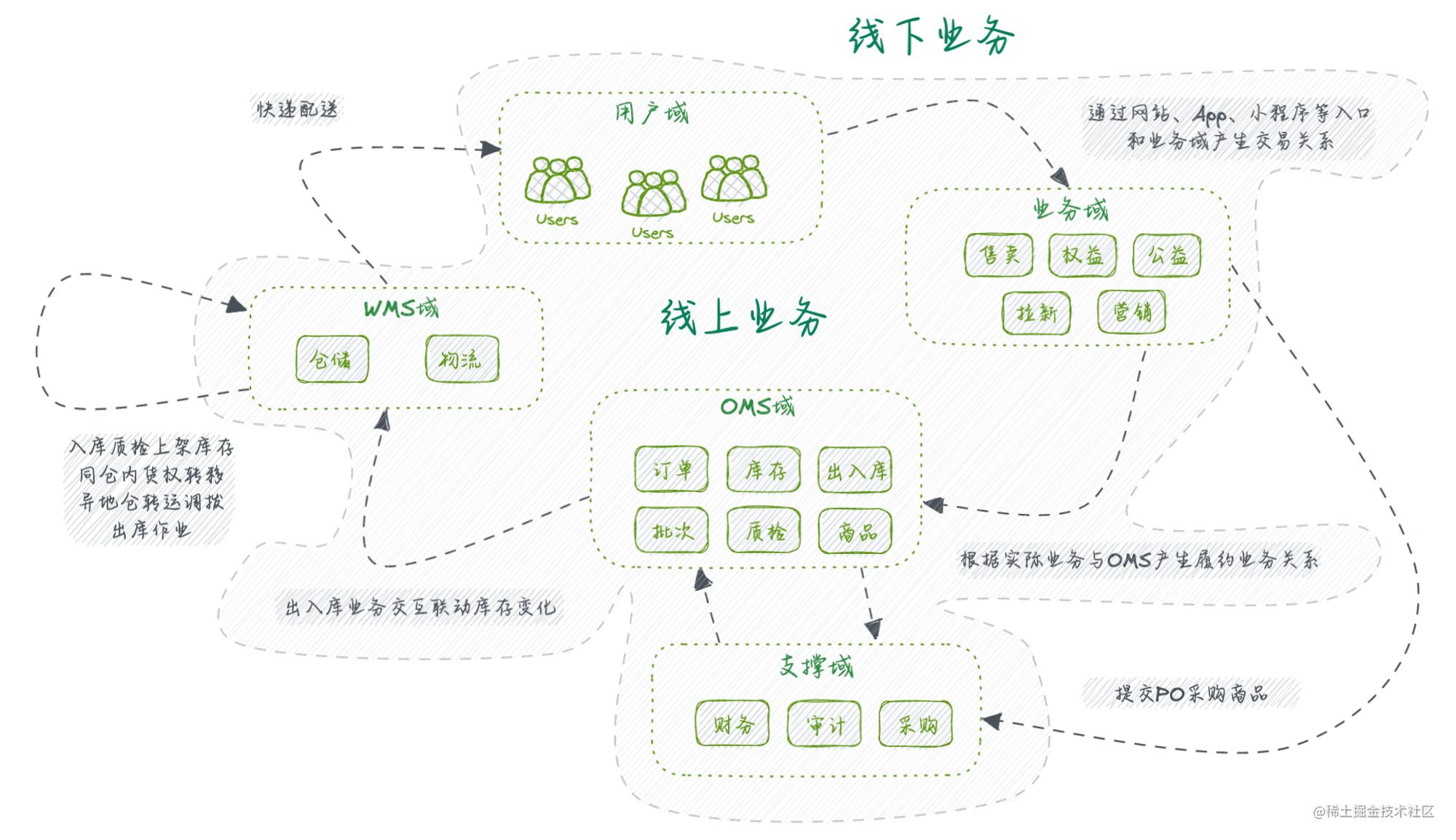
整体参与供应链业务范畴的领域可以大致划分为用户域、业务域、OMS域、WMS域、支撑域。在整个供应业务的核心链路可以简单概括为:用户参与业务域提供的售卖、营销、权益活动等与其产生交易关系,业务域便产生履约职责并将该诉求下沉,OMS域负责将履约诉求进行分发,由WMS域完成出货动作,经由快递服务完成用户履约。
由于供应链业务有着自身的特殊性,并不是所有业务都能够通过纳入到线上系统管理来解决具体现实问题,领域间需要通过线上、线下两部分进行协作完成业务流转。比如采购商品入库、仓内货品盘点调配、商品派送等都需要有现实人力作为整个信息流的支点来进行串联,使得线上系统驱动、线下人工作业能够互相配合协作,从而完成业务全链路的闭环。研发人员除了做好线上系统的良好交付,还有保持好与线下人员的高效沟通,让每一个点位都能够朝着降本、提效这个供应链的核心目标靠近,实现业务价值的最大产出,最终收获技术价值的最大存在。
2.2 系统架构
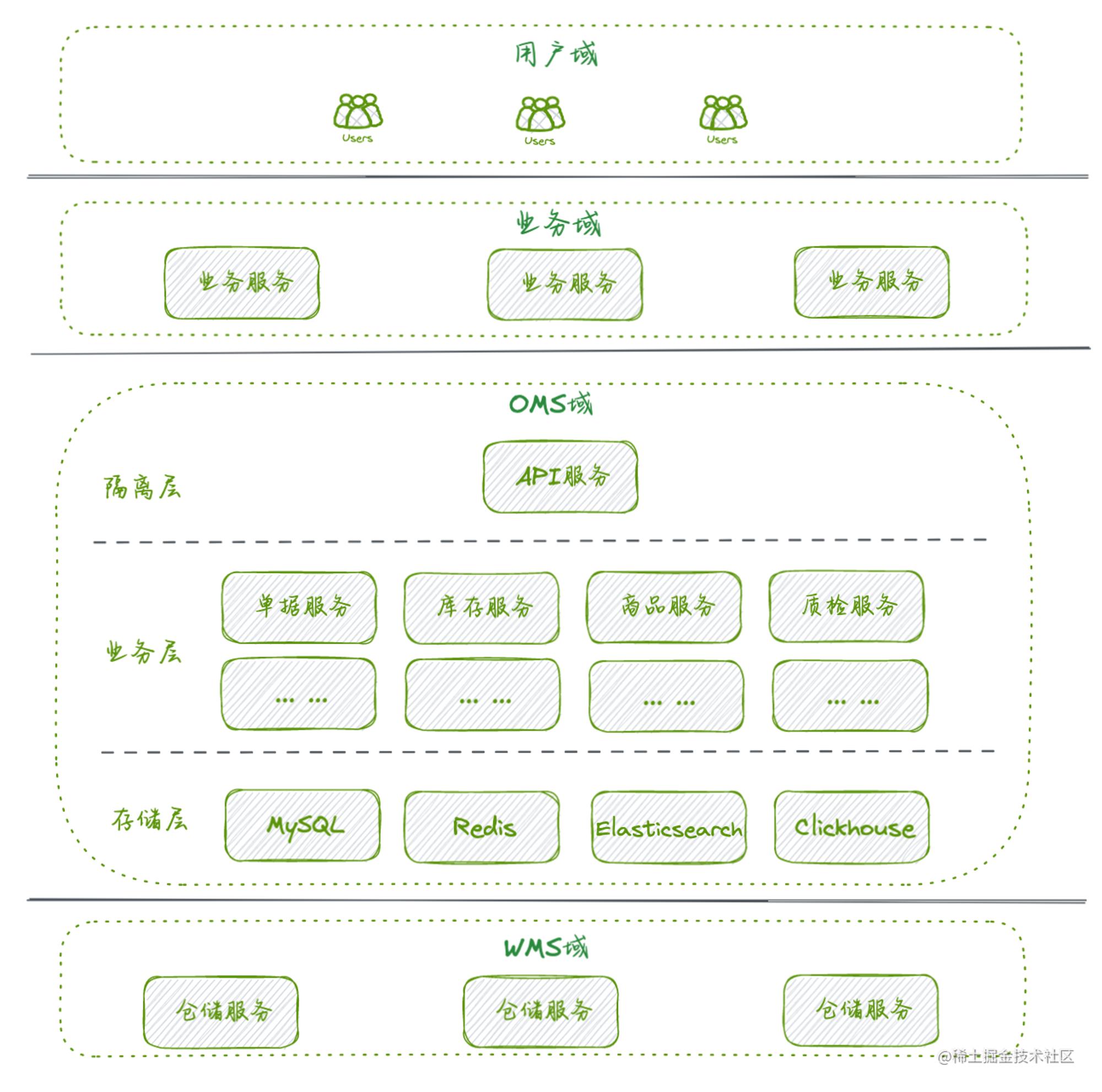
整体的系统架构按照传统的隔离层、业务层、存储层进行分层拆分:
隔离层 主要通过一个Facade API进行服务能力的输出,是外部领域与内部逻辑交互的边界,主要职责是做数据有效性校验、数据聚合等 业务层 核心区域,是复杂的业务逻辑实现层,包括供应关系涉及的方方面面的微服务群组 存储层 数据沉淀、加工、传递的区域,支持诸多数据结构的存储介质和引擎
3. 功能演进
供应链业务庞大、功能复杂,这里抽取单据业务、库存管理的发展历程来概述下系统功能演进。
3.1 单据业务演进
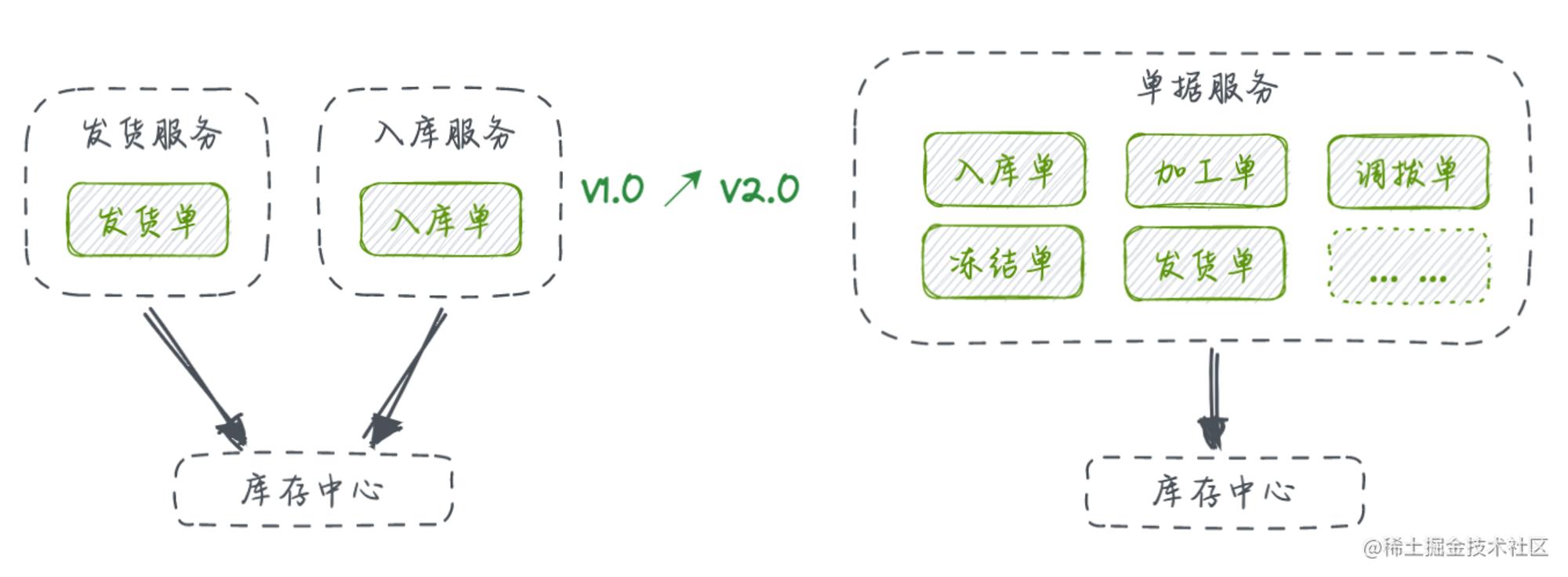
在整个供应链体系中,OMS域是较为核心的一环,OMS的全称为Order Management System,即订单管理系统,单据(Order) 是其核心所在,业务以单据为载体而展开。
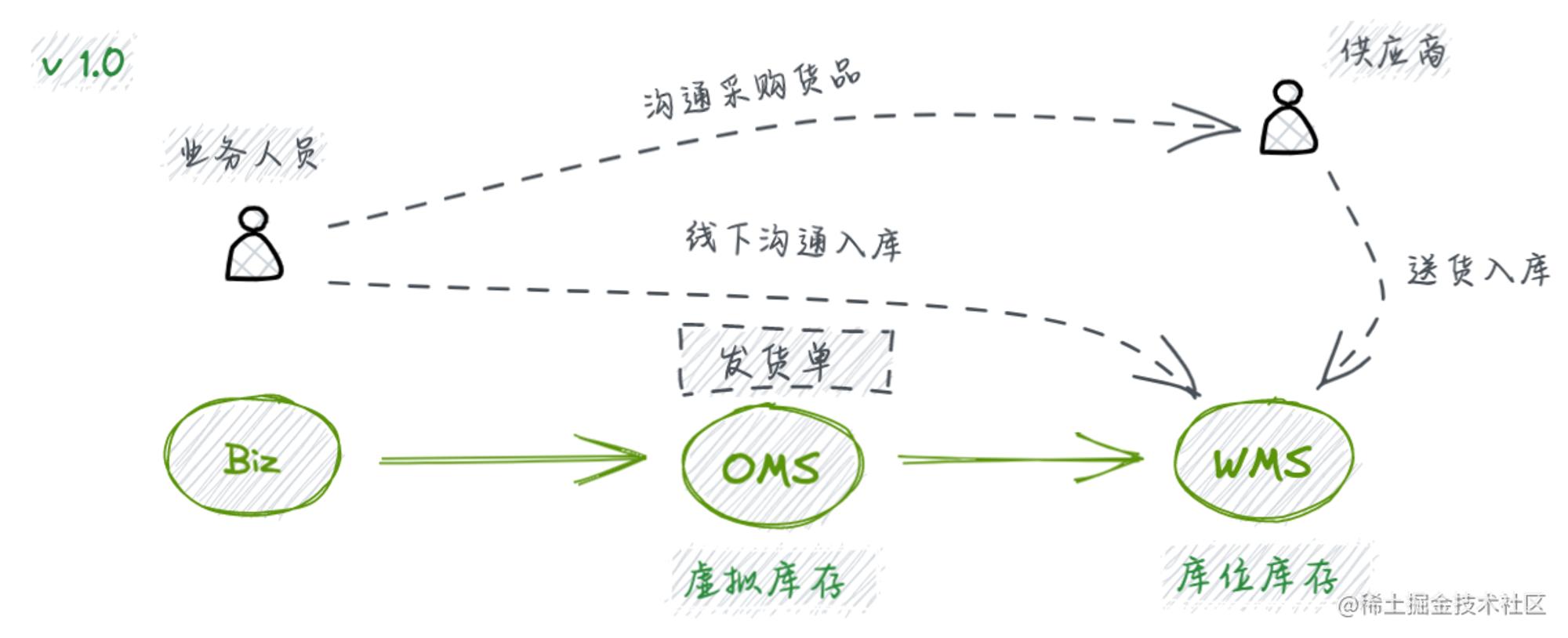
单据业务的复杂度、具体实现是和它承载的业务、上下游能力息息相关的,如果只是做营销业务,卖卖货,用户付费了按时给用户发货做履约,那么单据的职责可以简单地理解为发货单或履约单,此时甚至可以将它叫做发货单系统,核心流程就是上游系统来做下单,然后再去调用下游,把发货诉求下沉到WMS完成最终的履约,此时OMS最核心的系统能力是发货履约。
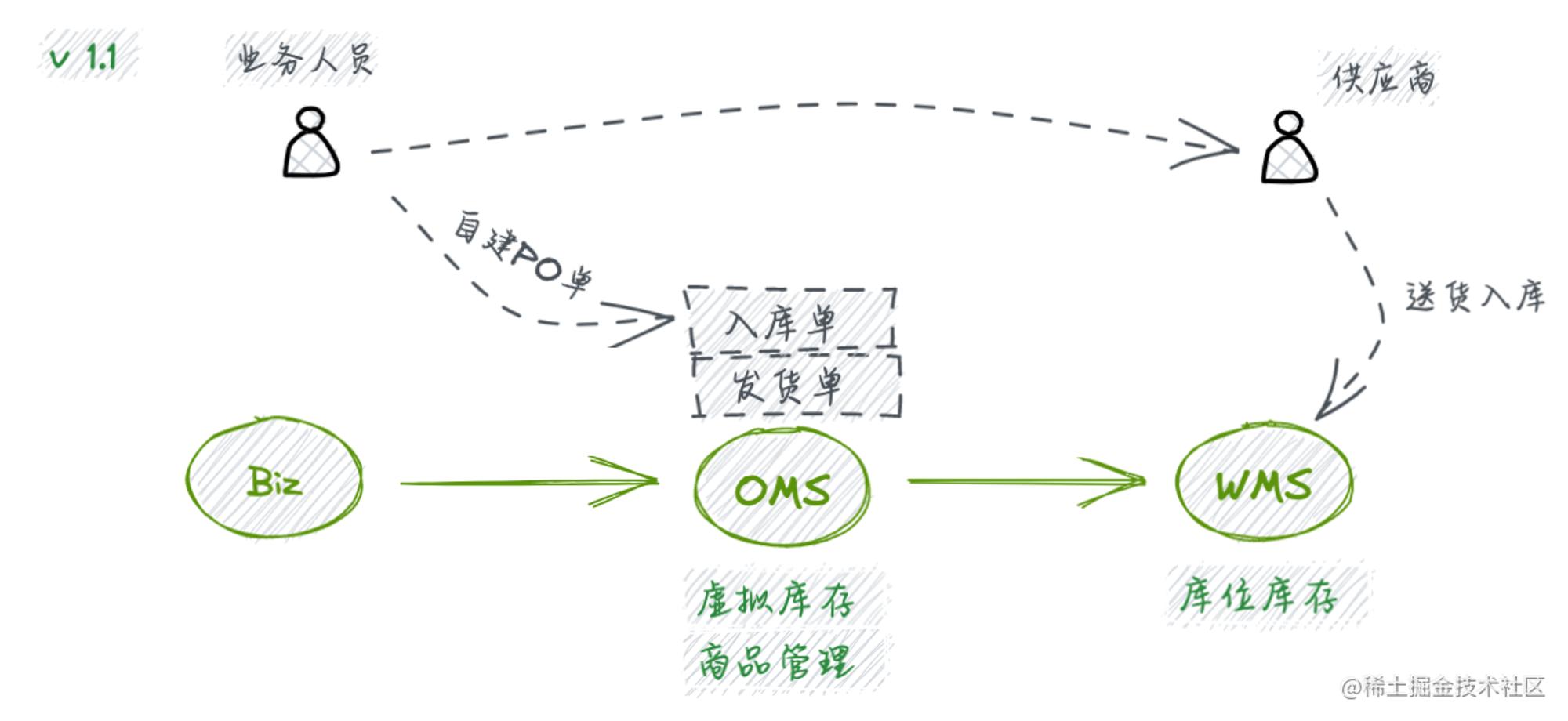
随着业务的发展,经过了萌芽期,发货的业务方越来越多,发货量越来越大,发货的品类也越来越广…此时会面临货品及库存管理等棘手问题,于是开始构建统一的商品管理、库存管理子模块来进行全局性治理,从此开始进行虚拟库存管理,初步形成在抽象层来进行资源管理的能力和可视化。
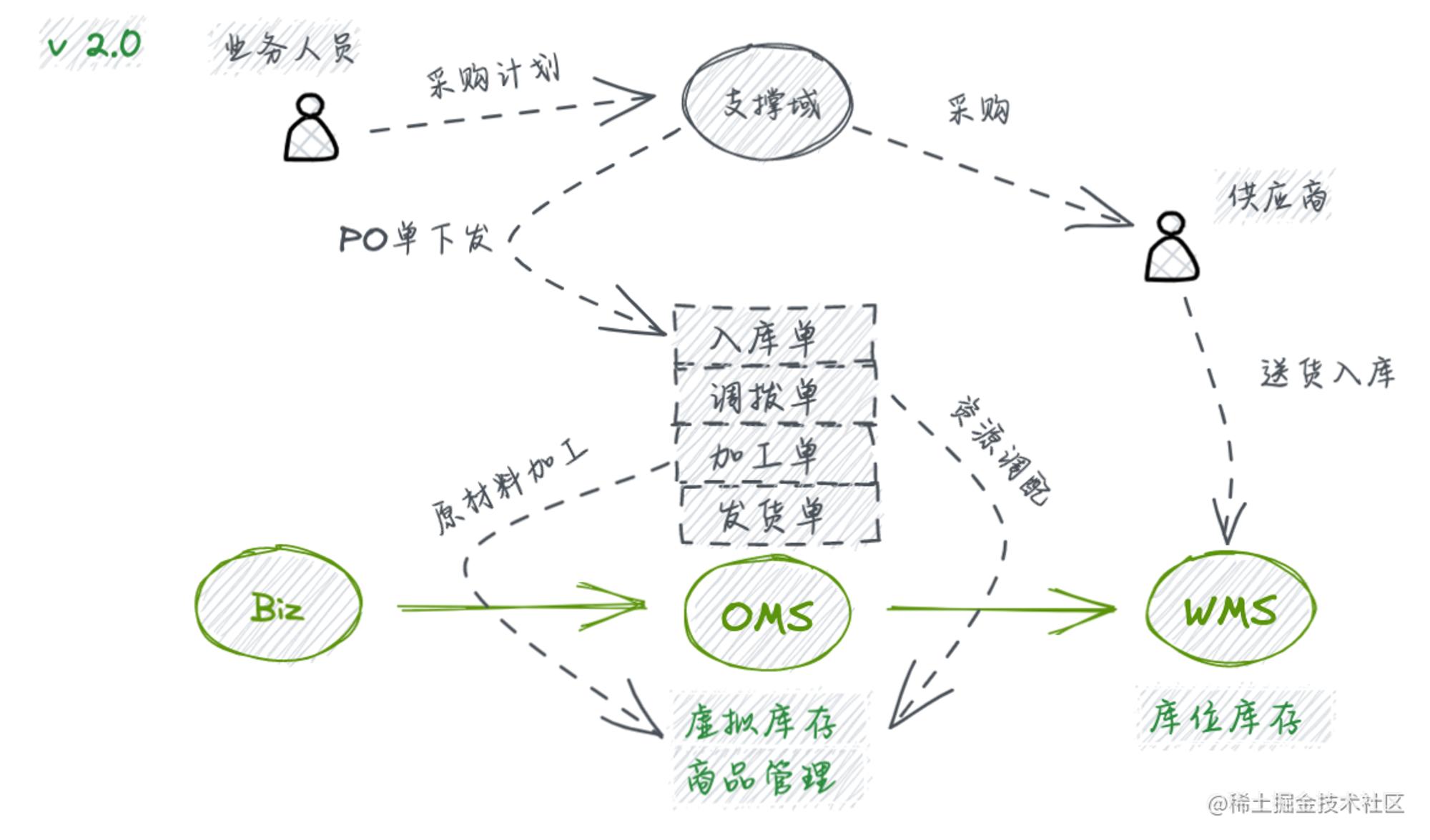
待业务完成原始积累,会进入一个由低阶转向高阶的业务转变。对系统的能力诉求已经不再仅限于朴素的发货履约业务支持,而是转向基于面向库存成本控制、资源调配等更复杂的系统能力以期实现业务利益的最大化。
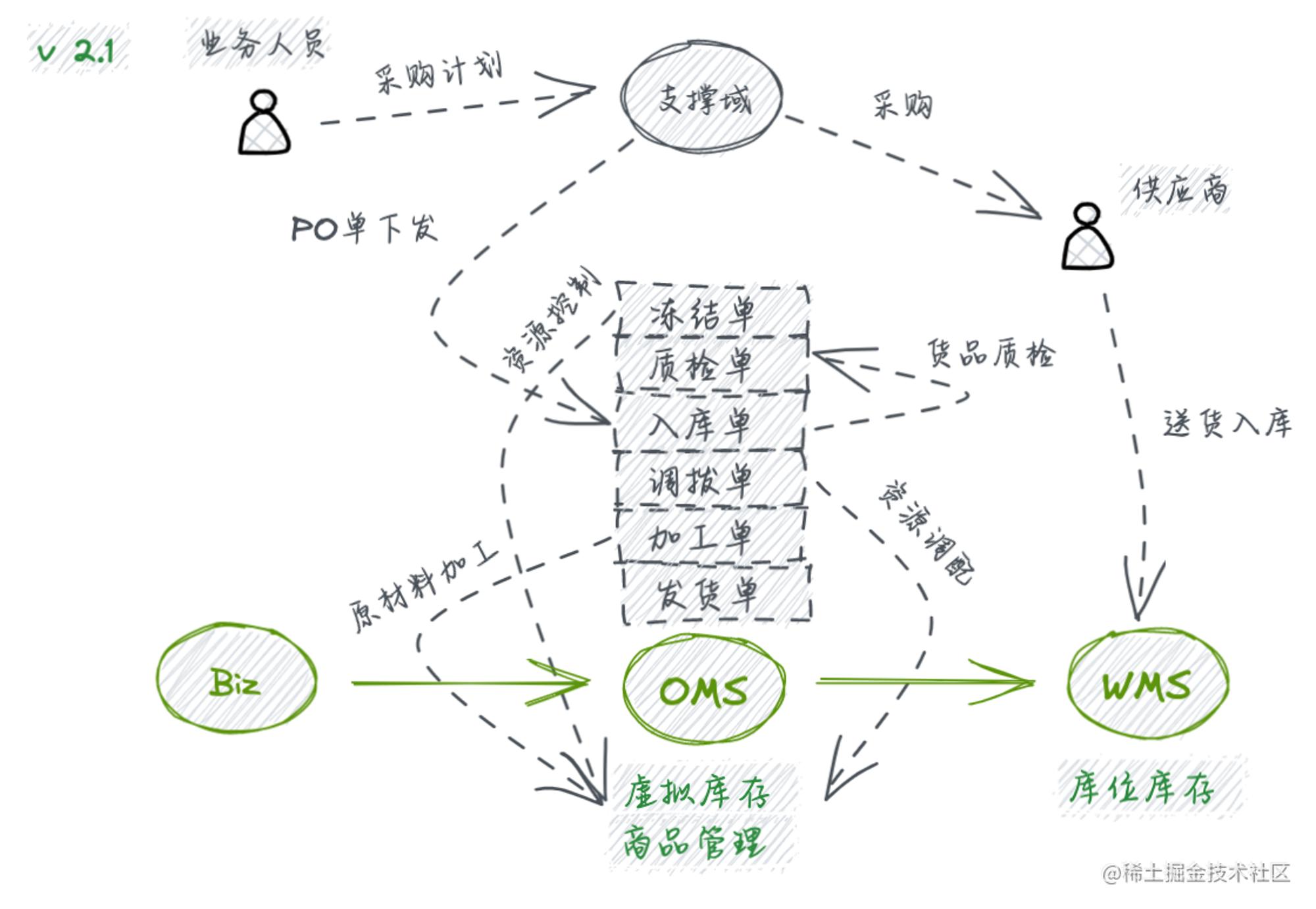
综上功能演进,都是基于供给业务关系的升级,在业务进入稳定期后,会越来越贴近供应链“降本、提效”的核心命题,于是开始做货品质检把控、履约时效监测等一系列环绕增强。此时,系统也适时迎来了从1.0到2.0的蜕变机会,不同以往的单据(Order) 独立核心构成,OMS的要素已经丰富到单据(Order) 、库存(Inventory) 、商品(Goods) 来组织构建,梳理角色定位如下:
| 核心要素 | 角色定位 |
|---|---|
| 单据 | 代表供应业务关系 |
| 库存 | 代表可供应能力 |
| 商品 | 代表可供应品类 |
多模块构建系统,核心在于对独立模块以及模块间关系的正确认识。 正确的认识才有正确的设计以及最终的正确实践。调拨、加工、冻结、履约等供给业务关系映射到系统功能的落地其实就是针对商品库存的操作。基于此,我们分析了各要素在看似复杂差异化的业务形态下的联动关系,如下:
| 业务形态 | 单据、库存、商品关系 | 示意图 |
|---|---|---|
| 入库业务 | 同一个商品的库存做增加 | 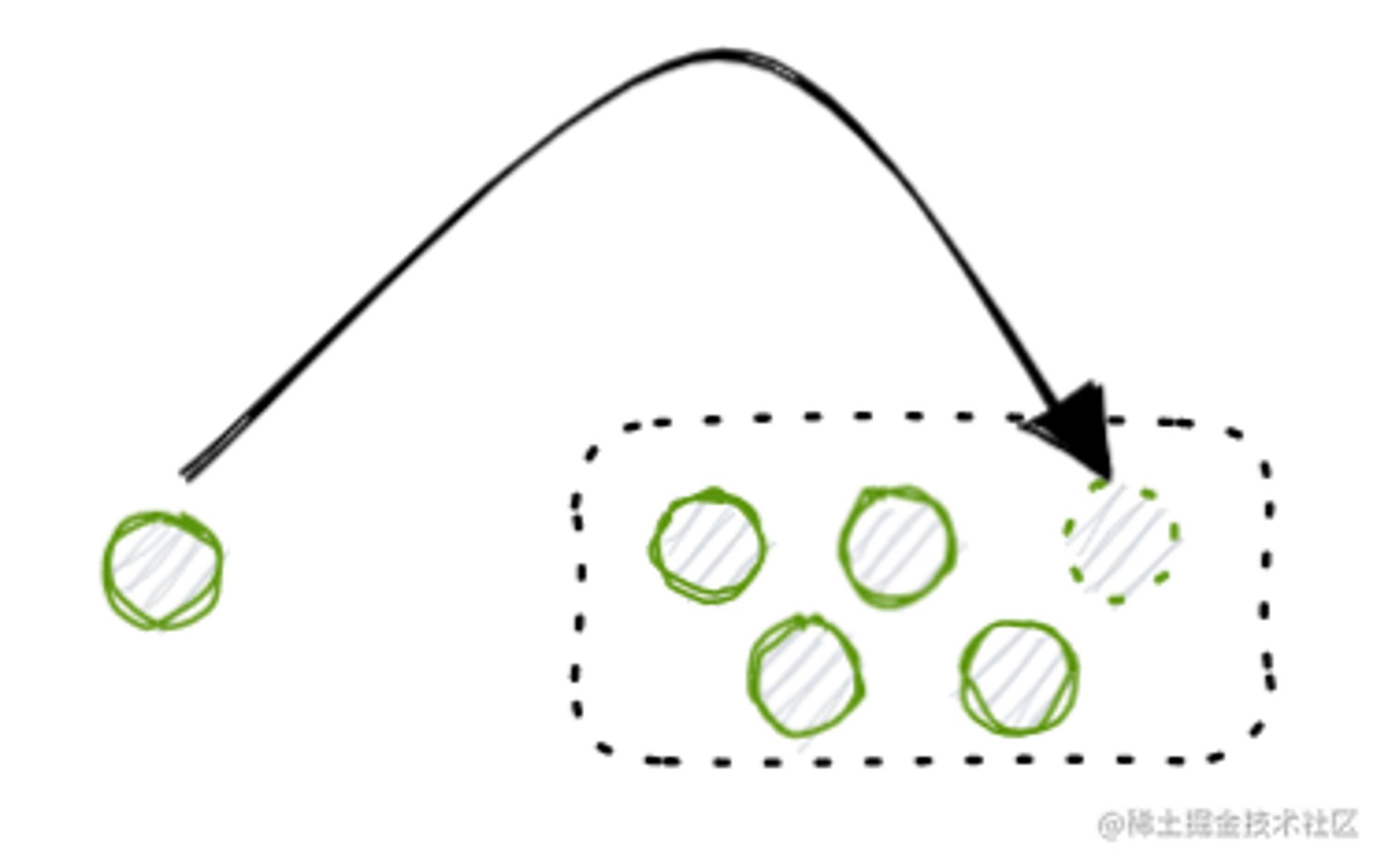 |
| 履约业务 | 一到多个商品的库存做扣减 | 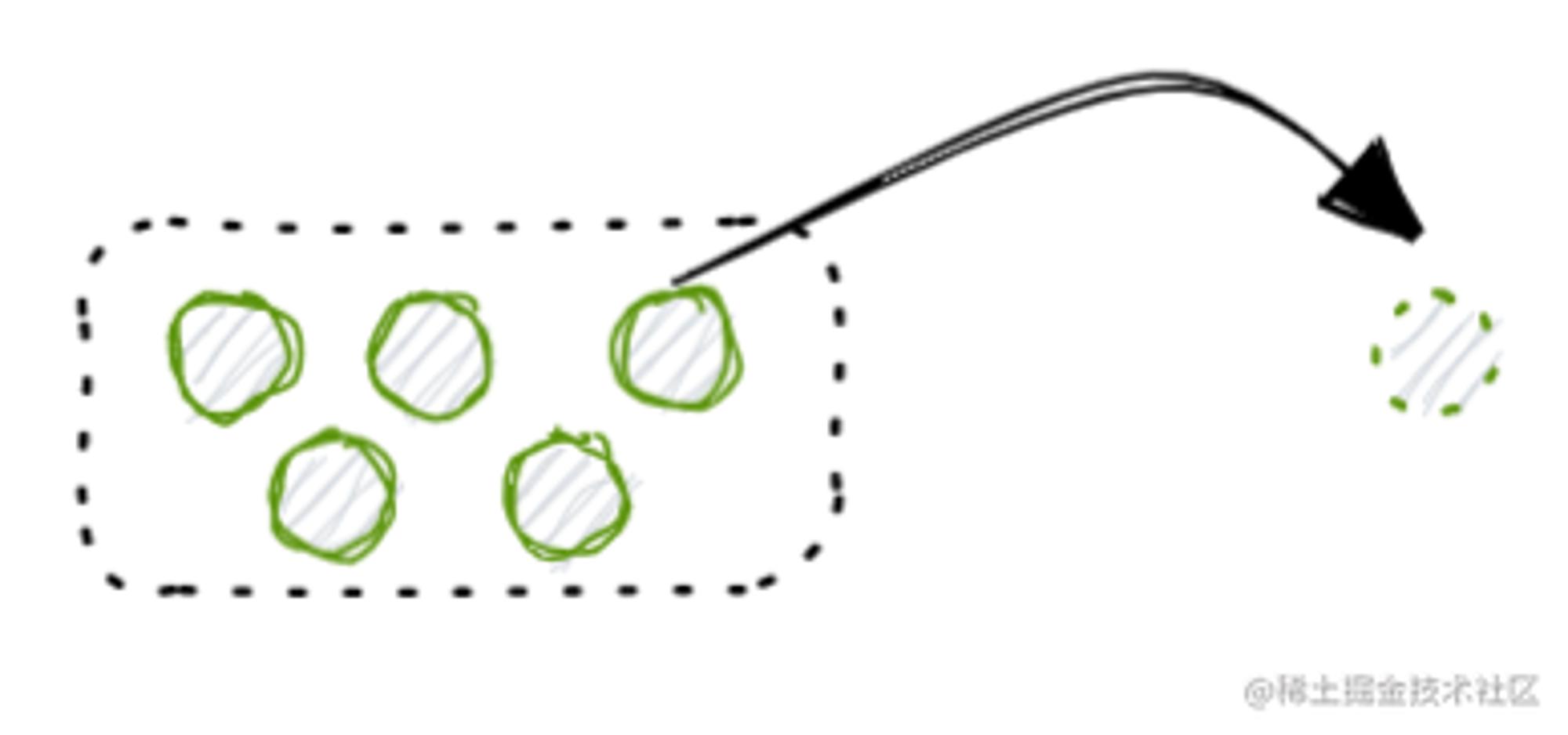 |
| 调拨业务 | 一到多个商品的库存做增加 一到多个商品的库存做扣减 | 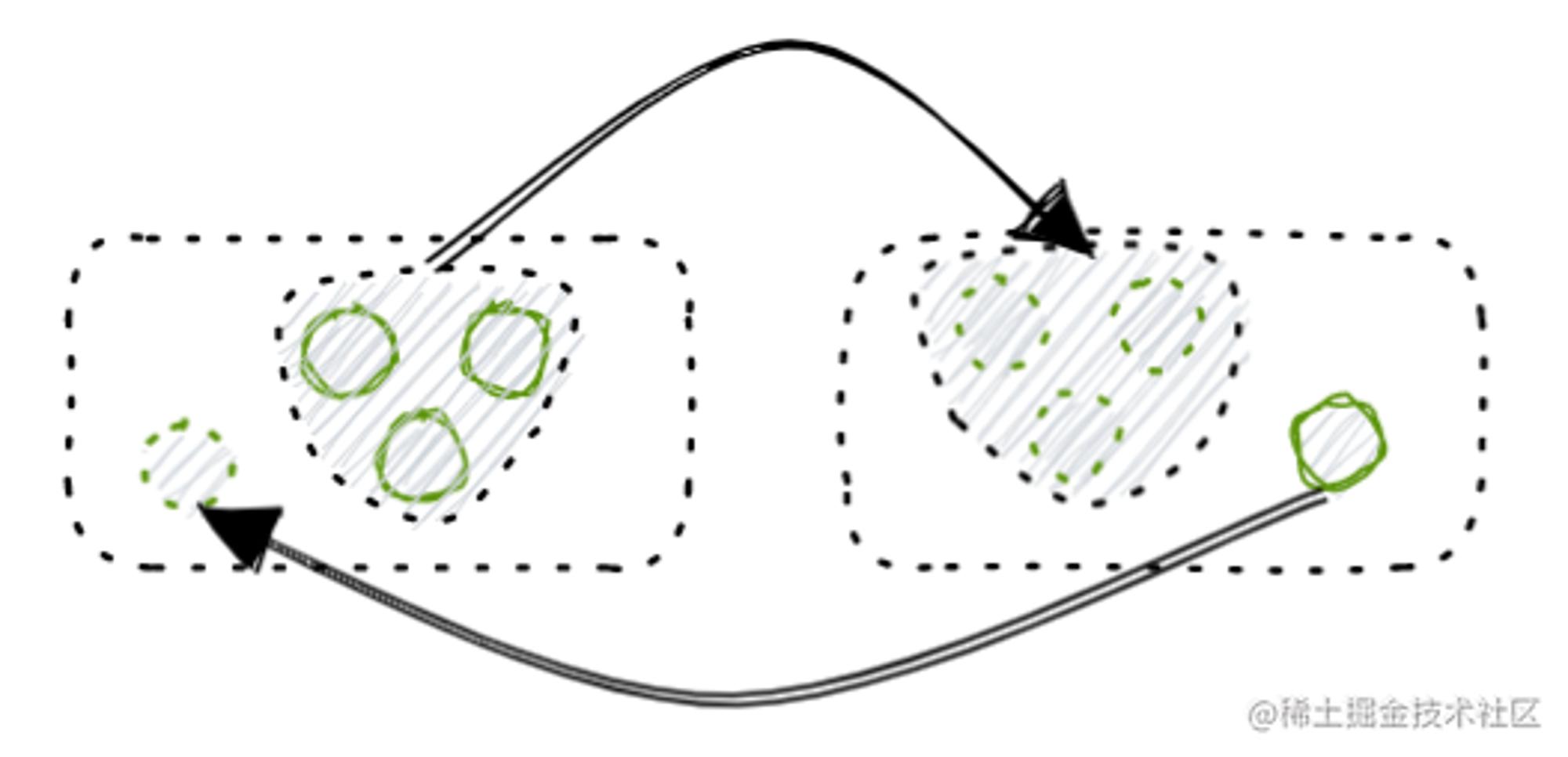 |
| 加工业务 | 多个商品的库存做扣减 一个商品的库存做增加 | 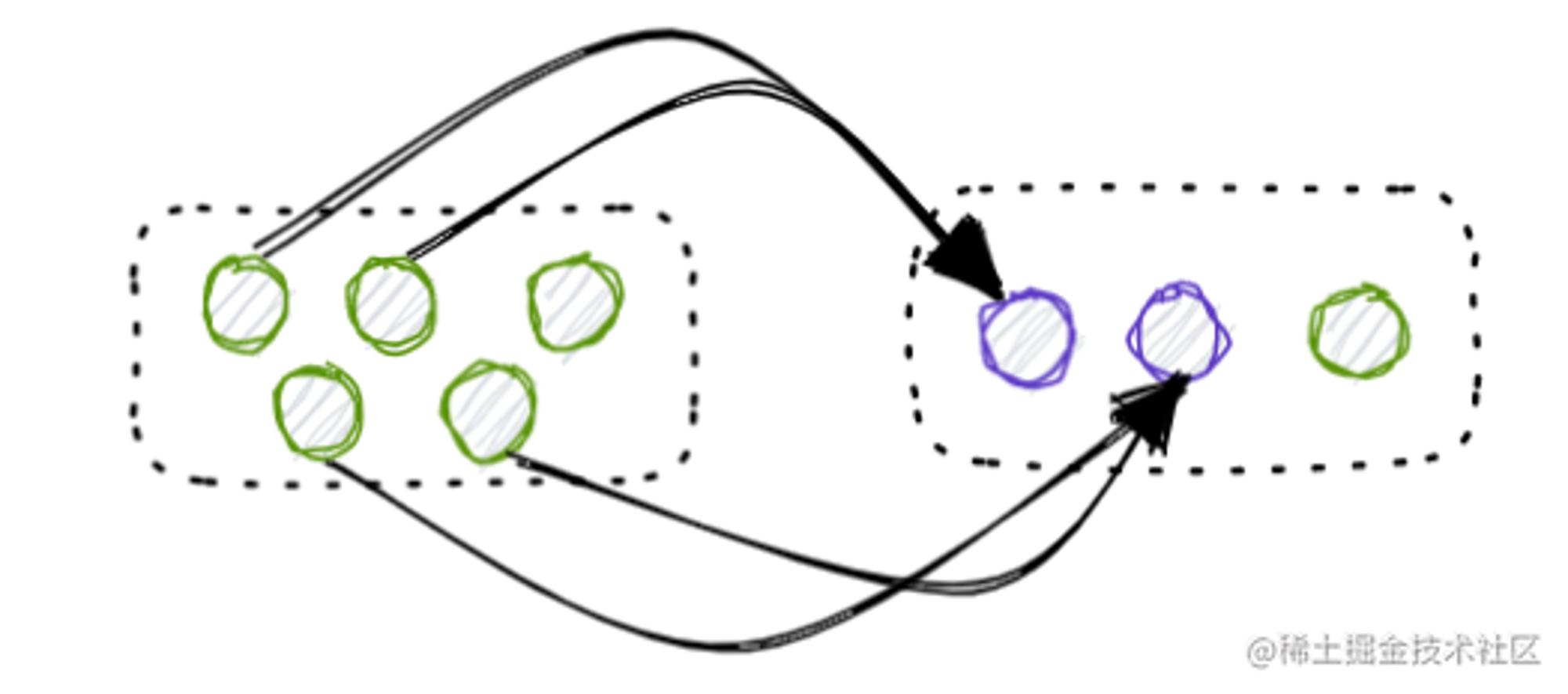 |
| 冻结业务 | 对一到多个商品的库存做锁定 | 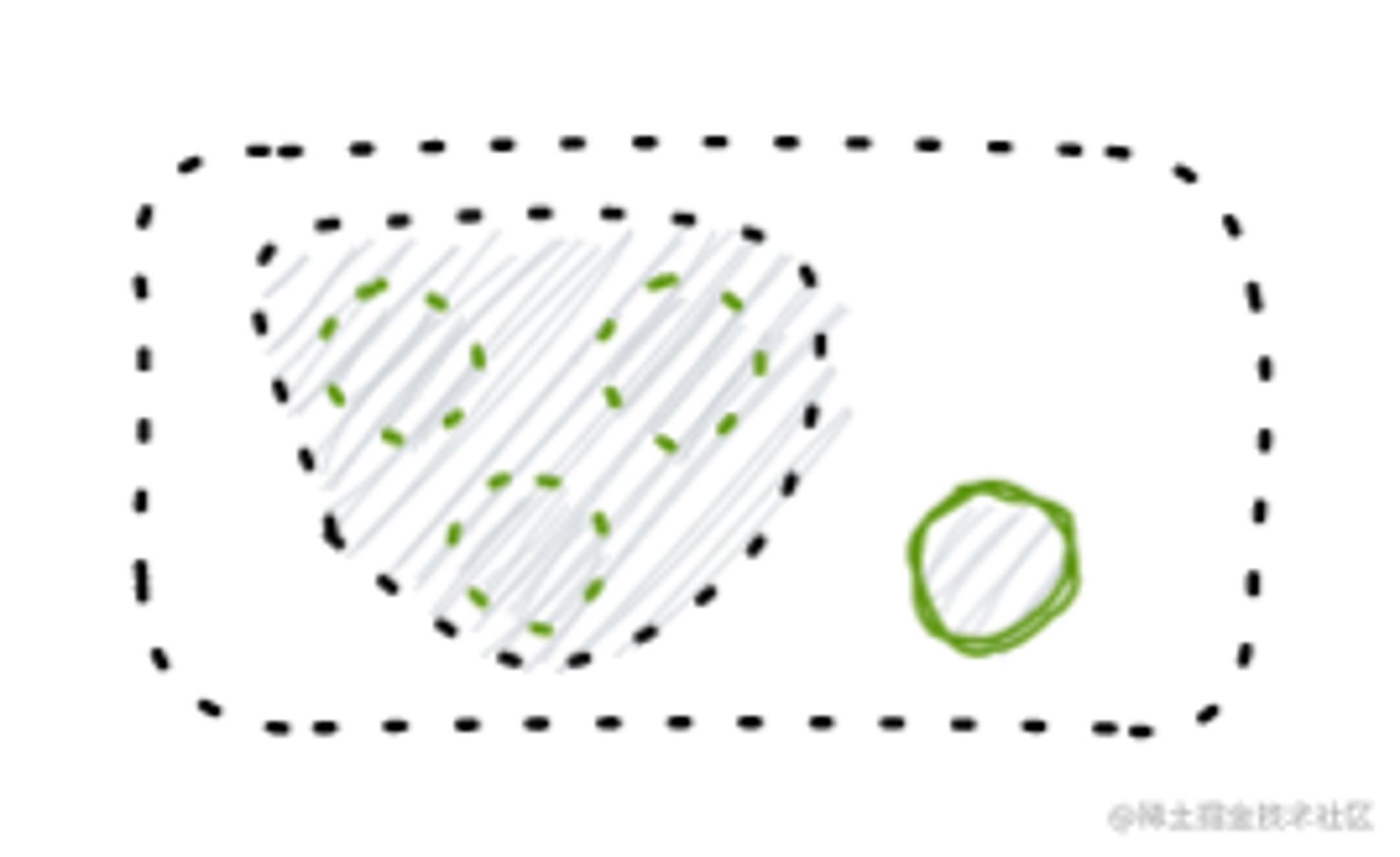 |
可以看到,基于供应关系的业务本质都是在基于库存调配流动来完成业务动作,只要抓到这个线索,后续设计就会豁然开朗了。基于供应关系业务的扩展一般就是业务与库存关系的扩展,单据就是业务的载体,我们整合了所有依赖单据驱动的上游各异的业务,统一收口到单据服务进行管理和迭代维护,减少了应用间的复杂度和未来扩展的实现成本,也天然地避免了未来由于没有收口复杂度带来的逻辑关系解释成本,业务的差异性体现在具体单据模型上,而与库存关系的变化永远封装在单据服务的通用实现逻辑上。
3.2 库存管理演进
一般库存分层模型分布,如下:
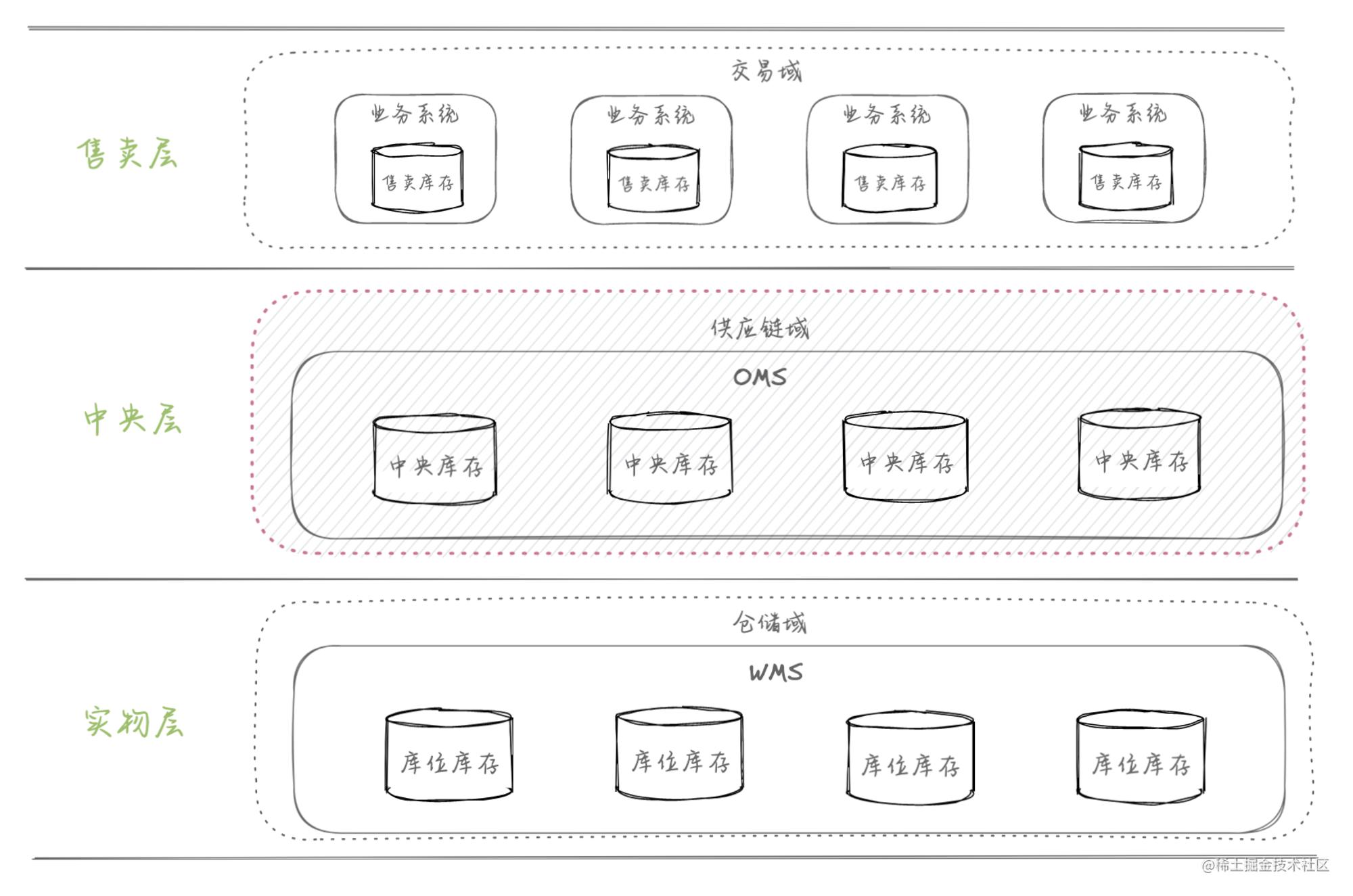
关于库存模型的划分是一个理论性课题,要结合业务复杂度来构建和拆分,具体怎么分、分多细是不能一概而论的。越是精细化的库存管理,牵连的复杂度越高,技术实现的难度也越大,不必照本宣科,因地制宜,存在即合理。
| 库存层级 | 库存类型 | 核心职能 |
|---|---|---|
| 售卖库存 | 虚拟库存 | 对真实货品库存的抽象,单纯地为业务提供计数能力,数据准确性的要求视业务情况而定,可以严格匹配或不严格匹配 |
| 中央库存 | 虚拟库存 | 对真实货品库存的抽象,除了计数能力外,还充满了业务映射到库存能力的差异化,具备更强的可塑性,能够适配和支持业务编排 |
| 库位库存 | 实物库存 | 真实货品库存,较为单一、正确的计数能力 |
库存的管理,主要是对库存账户体系的管理,库存账户模型的设计很重要,合理的数据存储能够支持较为广泛、复杂的业务诉求。
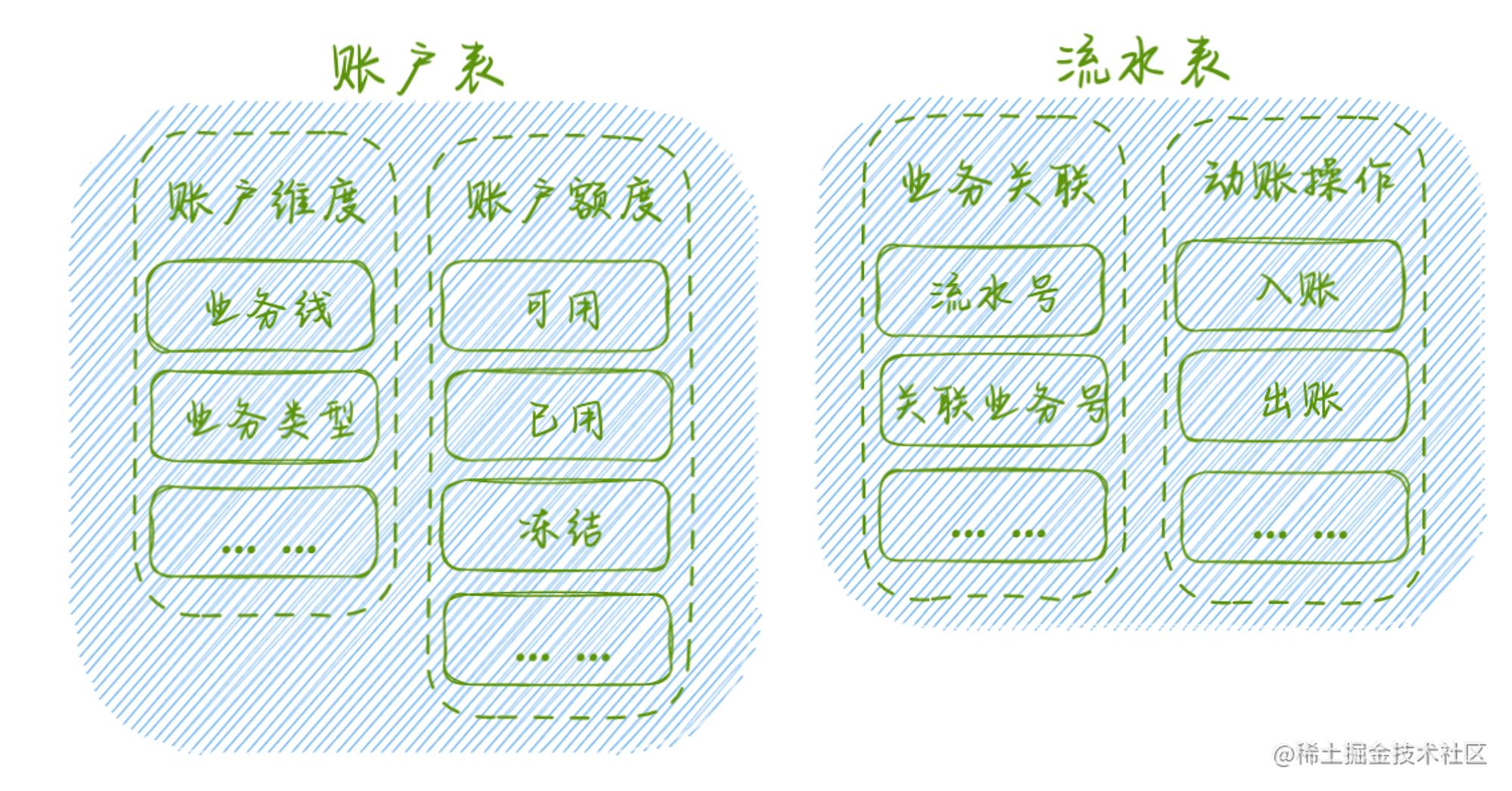
先来看下一般交易模式下账户模型的模型设计,主要包含账户表和流水表。
账户表 主要负责记录体现交易属性的 营收数据;其次是业务辨识度相关的 业务数据 流水表 主要记录动账操作相关 流水记录,如额度、资金动向等;其次涵盖了产生本次动账相关的 业务数据
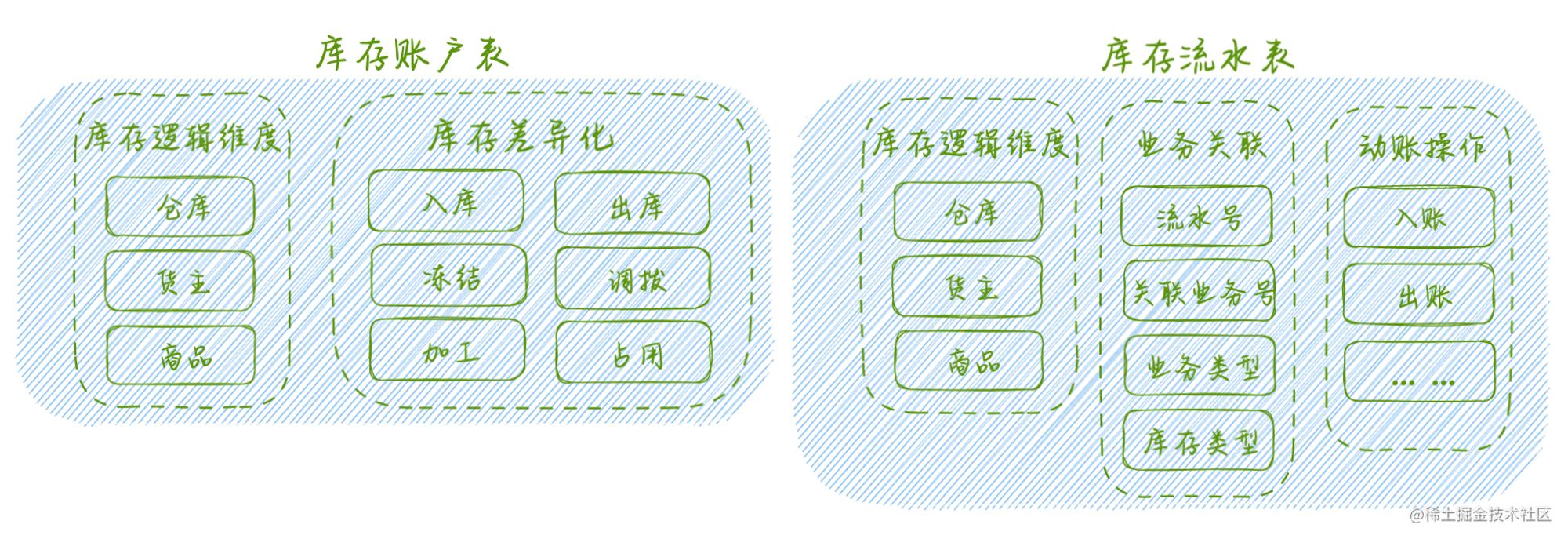
最初的库存模型和一般的账户并没有太大差别,随着对库存维度化、动态库存管理等迭代实现,最终形成了演化版的库存账户表和库存流水表。
库存账户表 库存逻辑维度和账户维度类似,是拆分用户逻辑维度的标识字段,这里按照 仓库、货主、商品维度丰富了库存存储的差异化诉求;相比于纯交易属性关注的收支字段,这里按照业务诉求将收支这“一出一入”进行了更为细颗粒度的拆分使其具有更为多样化的表达和存储能力 库存流水表 与一般账户流水表没有太大差别,同步继承了账户维度和细颗粒度的存储映射。流水表有两个核心功能,一是做动账记录,二是做业务防重来支持幂等性
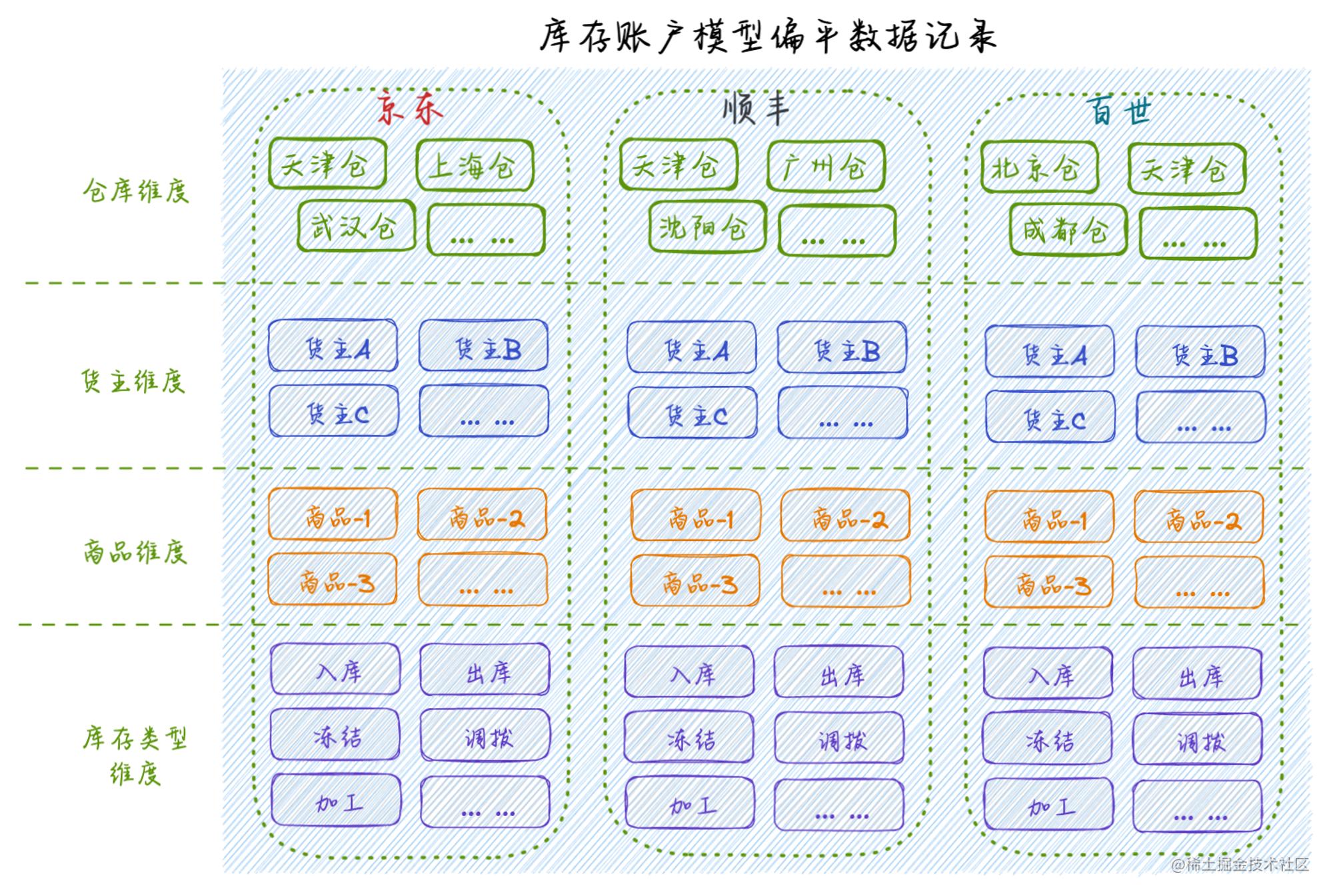
我们将库存账户模型进行了业务维度的横向拆分,同业务维度可以纵向排列组合,使其具备了网格化扁平数据如图所示,每一条库存数据字段就像一个个灵活、干练的积木块,对于上游业务的能力支持是通过原子化的排列组合完成的,组合后偏平数据的表达能力非常丰富且生动,特别是在后续动态库存、业务差异化映射到库存差异化以及库存监控上都能做到较好支持。
4. 一般功能设计
4.1 关联数据映射
在OMS以供应关系为驱动的单据业务中,从上游到下游的参与方依次是用户(Users) 、业务系统(Business) 、订单管理系统(OMS) 、仓储管理系统(WMS) 。

| 层级 | 数据角色 | 过程 |
|---|---|---|
| 业务层 - Business | 数据生产者 | 节点 |
| 订单管理 - OMS | 数据消费者、分发者、组装者 | 中介 |
| 仓储管理 - WMS | 数据消费者 | 末端 |
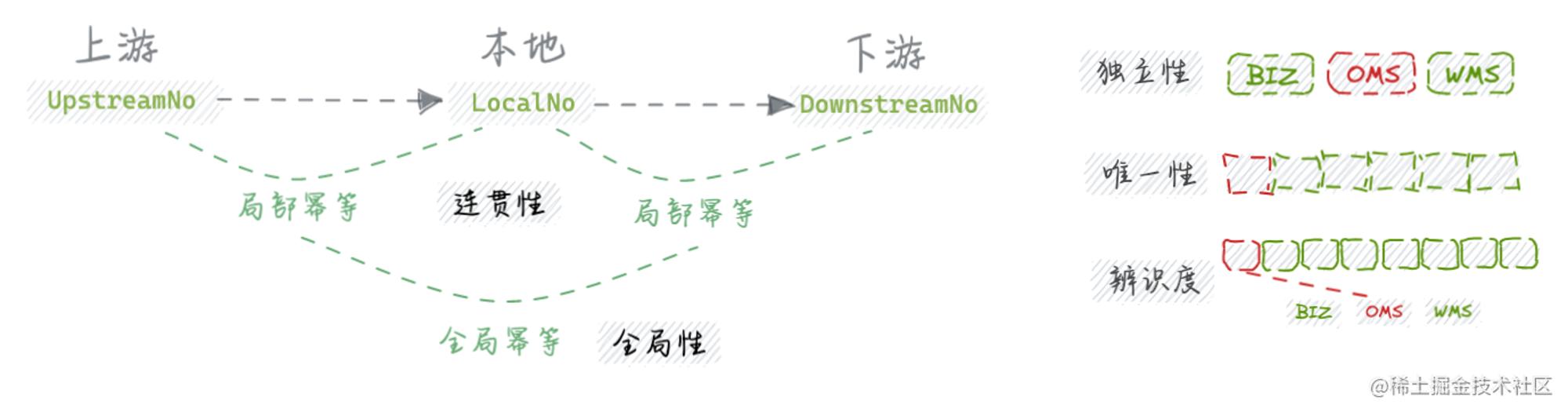
每一层级各司其职,以简单职责的设计思路来说,无论业务链路多长、参与方有多广,对于OMS自身来说只需要维护好直接产生业务联系的Business系统、WMS交互关系即可,也就是常说的狭隘上下游或相对父子节点,数据维护的范围也基于此,作为点对点的交互,上游都可以视为数据生产者,下游都为数据消费者,局部的串联可以完整拼接出整体链条。
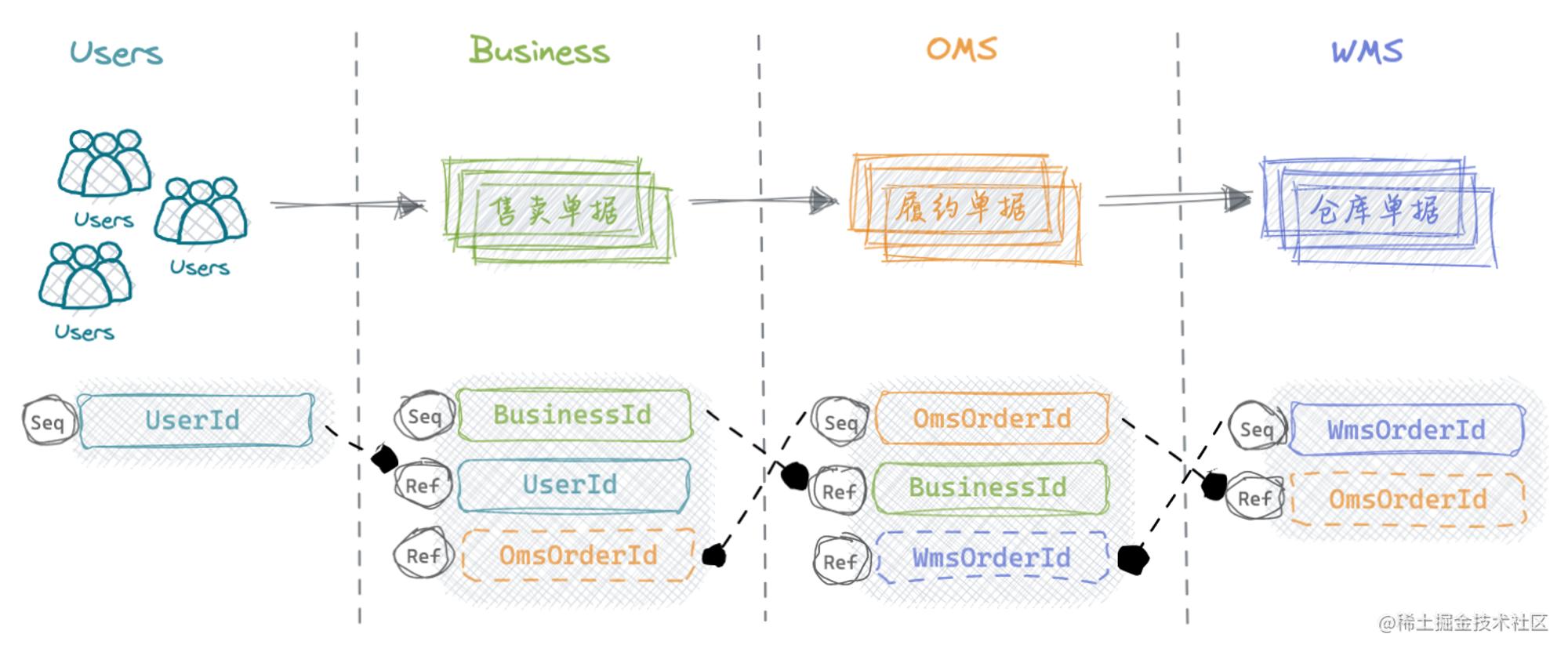
对于每一个提供服务业务能力的系统来说,都需要一个上游业务发起的凭证,以此来回溯过程数据。对于单据业务来说,单号(OrderId) 就是这个凭证,系统间需要存储、交互各自单号凭证来完成业务传递。基于此,我们的单据数据必然要存储上游单据号,单据号代表点对点业务关系是具有独立性的,为了在错综复杂的交互中保持独立性势必要求每个业务系统产生的单号具备一定的唯一性,因此自身系统也需要产生新的单据号来传递到下游,并且维护好上游到自身、自身到下游的一连串数据映射关系。
值得一提的是,有些业务系统只能支持本地单号回溯,有些则全支持,这大概与其存储实现有一定关系。试想,如果是单库单表存储,那么两个索引足以解决全部检索诉求;如果是分库分表存储,只能由一个字段进行数据切分,而其他字段不能实现数据路由的功能因此不可查询,但基于此,引入ES宽表、额外维护映射关系也可以解决。
综上所述,上游下发的单据号凭证和自身关联的业务单号是一定要保存的,而下游单据号可以视情况选择性存储,如下游不提供回执单号或不支持回溯;倘若提供,建议都保存。特别地,关联数据彼此除了映射关系唯一,其他都应该保证自身的独立性、隔离性。相比而言,像全链路的LogId目的是减少翻译,一针串所有,而业务数据是对内透明、对外封闭的,引入转换成本换来的是业务隔离、减少耦合夹带的副作用。
4.2 状态数据隔离
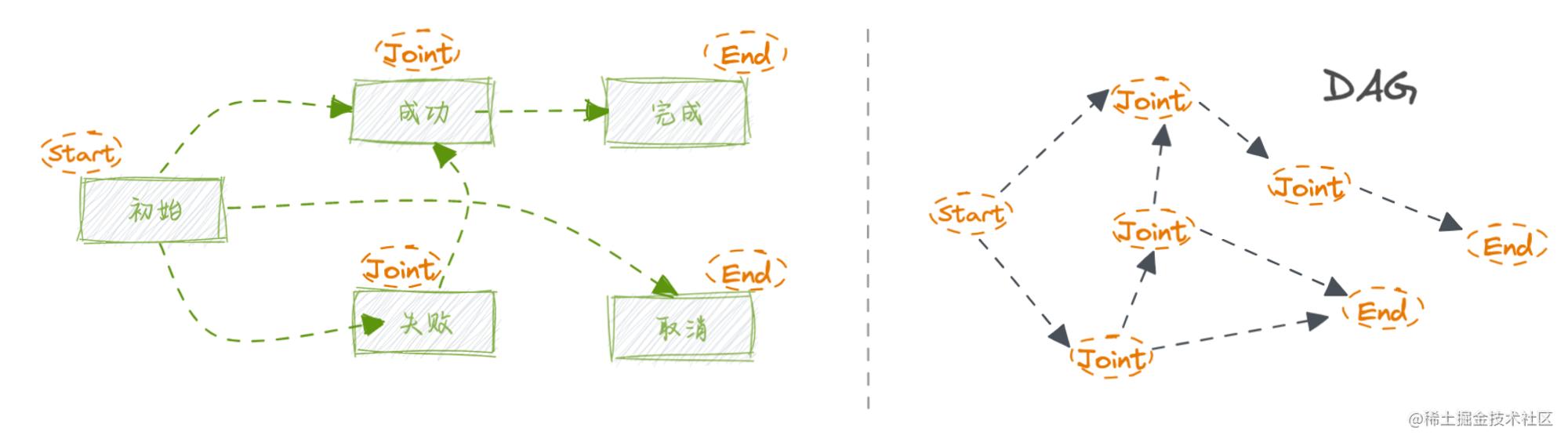
状态机是开发过程中常遇到的,一般状态机都会定义开始节点、过程节点、终止节点,大多数状态机都是一个有向无环图,基于可寻址路径进行驱动。这里归纳技术设计上几种常见的状态机存在形式:
| 存在形式 | 状态枚举 |
|---|---|
| 数据状态 | 有效、无效 |
| 业务状态 | 初始、成功、失败、完成 |
| 分布式事务状态 | 准备、成功、失败 |
据此,我们来完成对一个业务事实表的状态数据设计,如下:
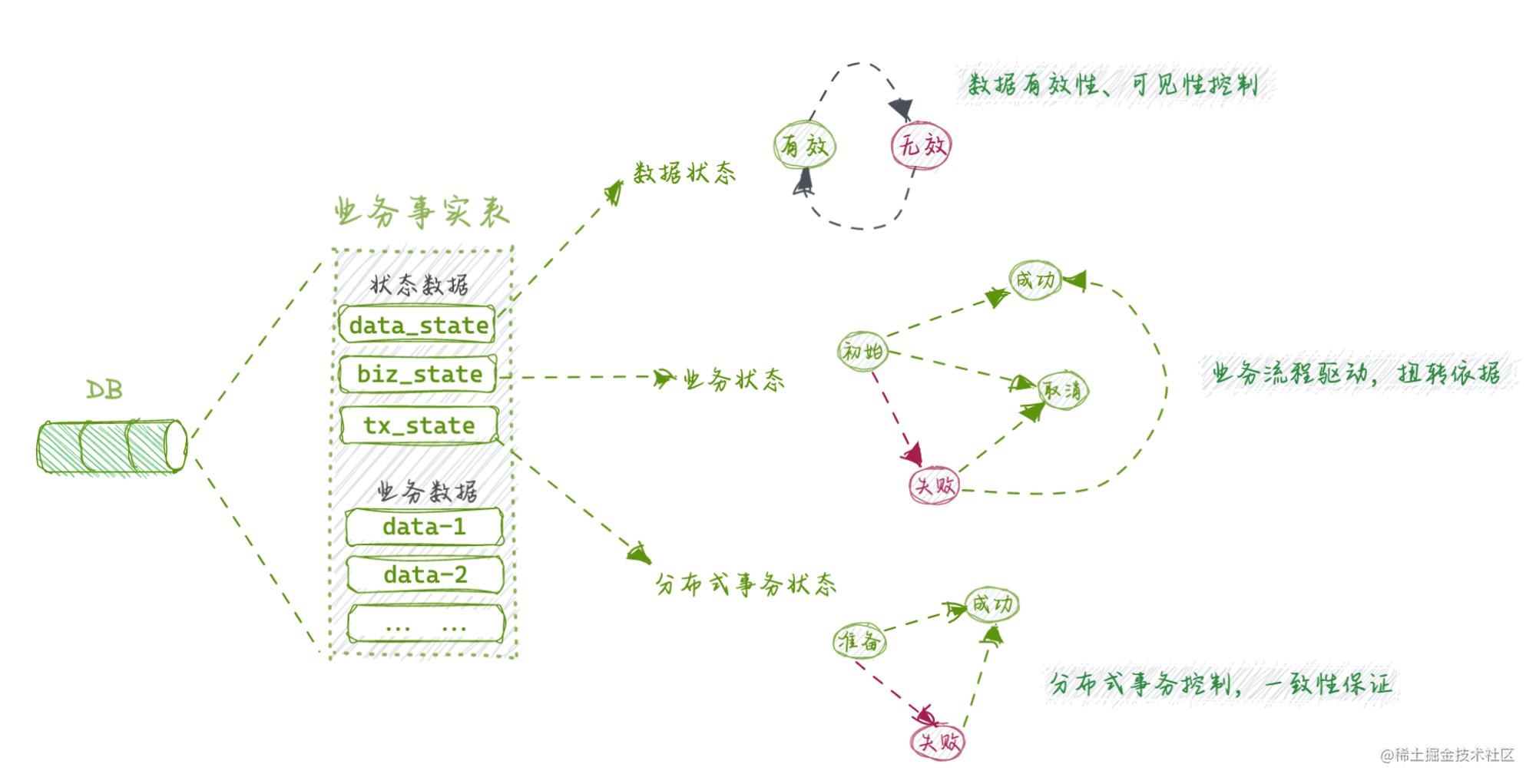
所有的事实表都天然地存储业务数据,具体存储状态数据的颗粒度要看其所承载的功能复杂度来考虑和设计。
所有记录都应当有 数据状态,它可以担任常说的逻辑删除标志,以此来控制可见性、有效性 当事实表关联了 业务状态,必然要增加存储字段,同时也承载了一个标准的 状态机业务的关联 在微服务架构下,分布式事务非常普遍,当事实表也加入到分布式事务作为本地事务表存在时,也需要维护 分布式状态
此时在最复杂场景下,业务事实表存储了多个状态数据,具备了多个状态机功能,这里的复杂度仅仅是单个服务内单个业务视角下的,如果鸟瞰全局可能是一个更复杂更丰富的状态机集群,如下:
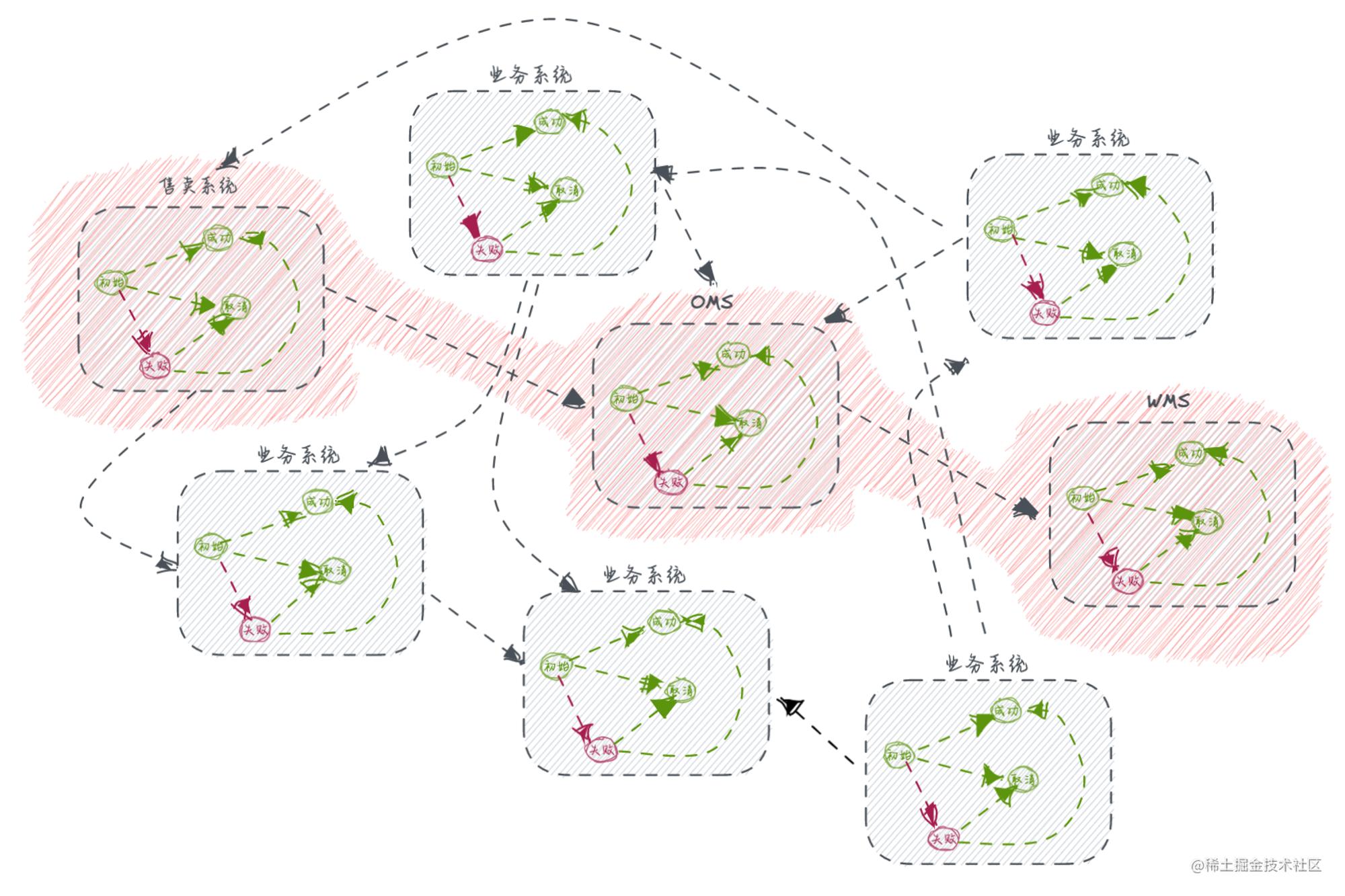
良好地识别、拆分、维护状态数据,可以在逻辑实现上充分解耦。常见的不良设计就是:一个State行天下。数据状态、业务状态、分布式状态等状态数据过度耦合,当设计初期通过一个字段解决了复杂状态数据的存储,定义好1-xxx、2-xxx、3-xxx,遇到迭代增加状态机状态枚举或变更需求才发现迭代维护困难且很丑陋。
4.3 分布式事务业务化

关于分布式事务的实现方案有很多,基于实现简单、理解简单、维护简单,我们选择了本地事务表 + 定时补偿的方式来完成参与各方数据的最终一致性。具体的交互过程如下:
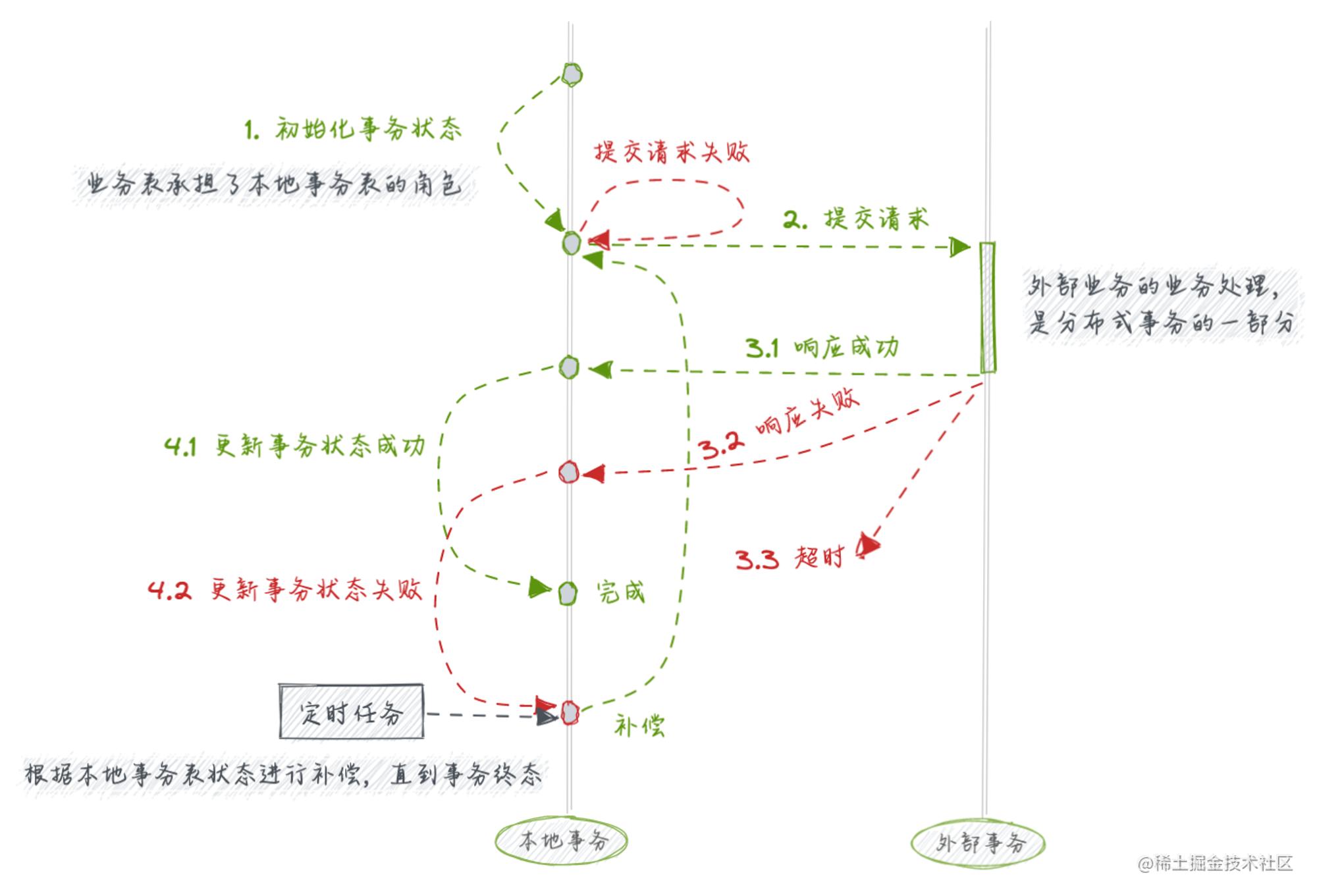
众所周知,本地事务的实现是容易、可靠的,而分布式事务是复杂的、不可靠的。 一言以蔽之,分布式事务要做的就是在不可靠的环境下,通过可靠的方式,把多个可靠的本地事务完成。
针对大量设计实践归纳,发现业务环境下的分布式事务如下特点:
参与者 并不像运维集群节点那样多,一般两到三个左右,如果你的服务中出现过多的业务参与者,可以反思改进下实现方式降低复杂度,或者遇到的问题根本就不是一个分布式事务可以解决的问题范畴 协调者 一般由某个参与者来扮演,而不太需要引入一个第三方工具来进行维护、驱动进行标准的 2PC、3PC的交互可靠方式 本地事务是可靠的,但是多个可靠的本地事务就变得不可靠,这里使用的 本地事务表(Local Transaction Table)就是可靠的本地事务;而治理不可靠的方式还是依赖可靠的本地事务进行重试补偿(Retry-Compensate),这里的治理方式也可以是事务消息等无逆向 对于大多数请求而言,只要能进行到本地事务表写入本地日志这一步,说明事先已经是充分核验的结果,最终目的都是朝着实现请求进行的,这点对于分布式事务方案的选择和实现非常重要!分布式事务本身就是一个状态机的实现,无逆向代表着它是一个 有向无环图,只需要提供持续驱动的动力就可以保证最终一致的目的,无需考虑诸多分叉问题,实现比有环图要容易很多,复杂度呈几何级别简化
4.4 幂等改造
防重设计中,幂等值的生成、校验幂等的方式是最为重要的部分,一般业务关系中表达幂等唯一载体的可以是流水号、业务单号等。
幂等值的生成方式,列举如下:
| 方案 | 生成方式 | 特点 | 不足 |
|---|---|---|---|
| 分布式ID | UUID | 全局唯一 | 特征不明显 |
| 拼接 | CONTACT(X,Y) | 可填充特征数据,局部唯一 | |
| 自增 | INCREMENT(ID) | 全局唯一 | 数据单调 |
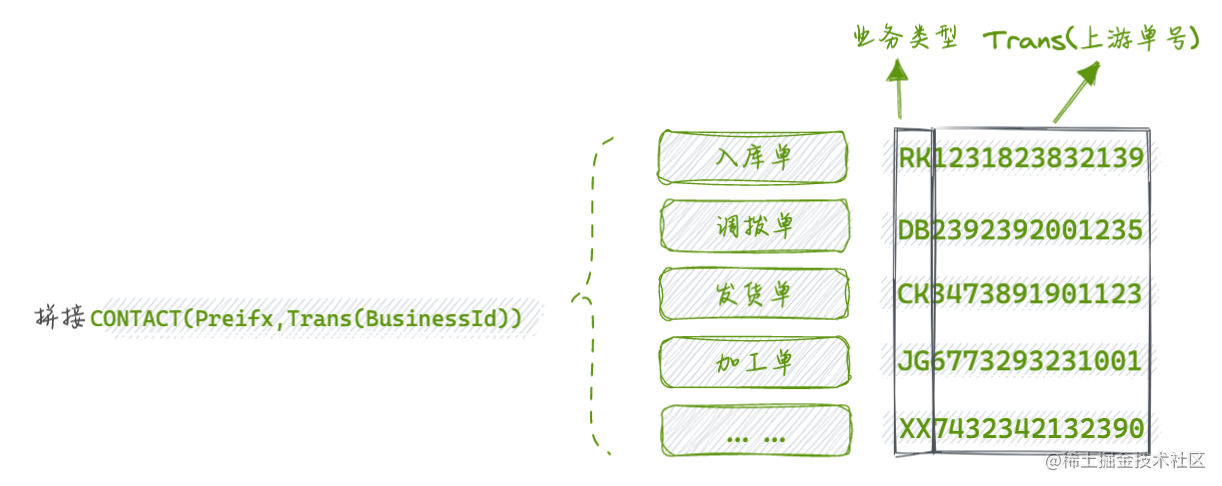
大部分场景下,盲选UUID即可。而OMS基于自身业务的特点选择了增强版的拼接方式来实现单号的生成,即CONTACT(Prefix,Trans(BusinessId))的方式。
由于业务识别数据特征的诉求,单据以代表具体业务的字母开头,后半部分是体现唯一性的幂等值即单号,由于业务的特殊诉求要支持同一单号业务下单、取消、再下单这种循环式操作,避免重试或并发产生业务后带来的一对多单号逃逸防重等问题,选择以上游单号作为生成单号的因子进行一对一映射转换,既保证单号的本地独立性和唯一性,又支持循环操作下的天然防重性。
校验幂等的方式主要是依赖数据库唯一性校验、缓存进行拦截的。利用数据库的可靠性校验做逻辑兜底和最终依据,引入缓存层来协助防重是一种保护数据库的手段,但是也引入了维护两份校验幂等数据的复杂度,需要充分考虑幂等数据的过期失效问题,处理不当容易导致业务停滞,大部分场景下是不太需要引入缓存层设计来增加这层复杂度的,可以想想在业务研发中什么样的场景会产生如此巨大的幂等并发呢?
举例一个需要考虑设计健壮性的场景:设置幂等的流程是先缓存判断,已经被设置则阻塞,没有被配置则进行配置,这里缓存实现的幂等其实就是一把分布式锁,然后再通过数据库幂等判断,处理完业务后我们可以把该缓存的时间保持大于业务再次产生幂等的最晚时间后再淘汰,比如做用户每日签到的防重复可以设置为大于当天时间后再淘汰,一般的我们会多预留一些时间窗口以使得边界情况完全覆盖。问题一般容易出现在缓存层幂等设置成功,业务处理失败,但是由于不可抗因素缓存没有及时移除,仍然对失败业务进行拦截防重从而导致业务停滞阻塞。
4.5 防重键扩展
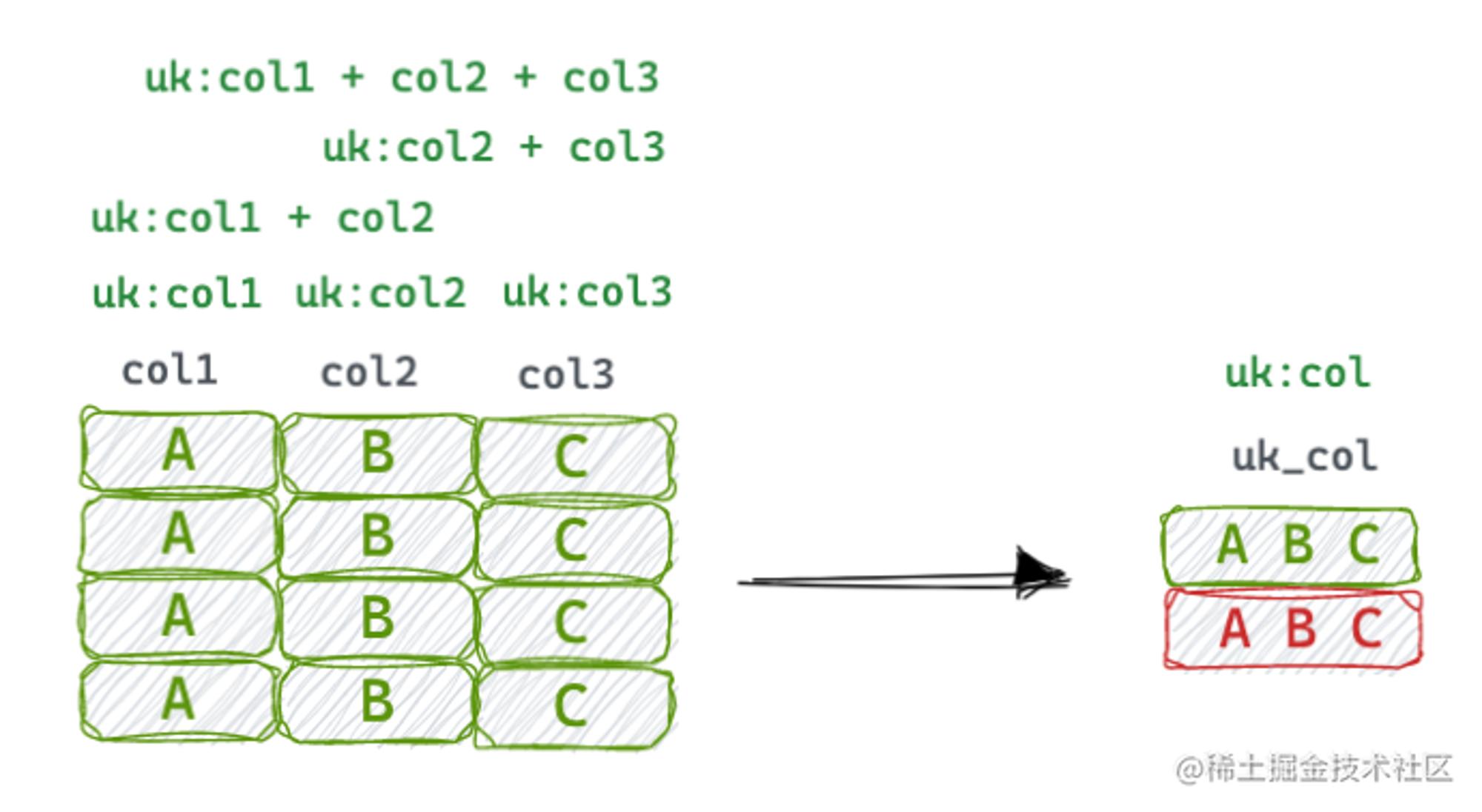
设置数据库防重键是数据防重的有效手段,一般会选取一个字段增加Unique Key来达到目的,实践经验发现,这样的设置没有错误但扩展性不够好。
在库存流水中也有这样的场景,期初是通过一个关联动账的业务流水号BizId作为Unique Key的,随着业务的扩展,要支持多仓库、多货主维度的库存动账能力,基于此防重逻辑也要支持多维度,比较Tricky的一种迭代是对代表多维度的多个Column进行联合设置生成新的Unique Key,此时可以看到,Unique Key产生了冗余和膨胀逐渐变得难以维护。
较为推荐且扩展性较好的一种实现Unique Key的方式是,维护一个职责单一的Unique Column,幂等值通过规则来拼接填入,把幂等规则潜在的复杂性、变化置于此字段之外。
4.6 动态库存挑战

当只有一张储蓄银行卡时,我对银行卡的要求仅仅只需要看看入账、出账情况,最关心的是余额。然而当拥有了多家的多张银行卡,且同时开通了信贷、储蓄、理财等多种功能时,理解、操作成本便陡然上升了。这也适用于业务中遇到的动态库存管理问题,此时,库存不再是一个固定字段而是多字段作用计算后的结果,相关的库存判断、调整逻辑的复杂度也随之而来。
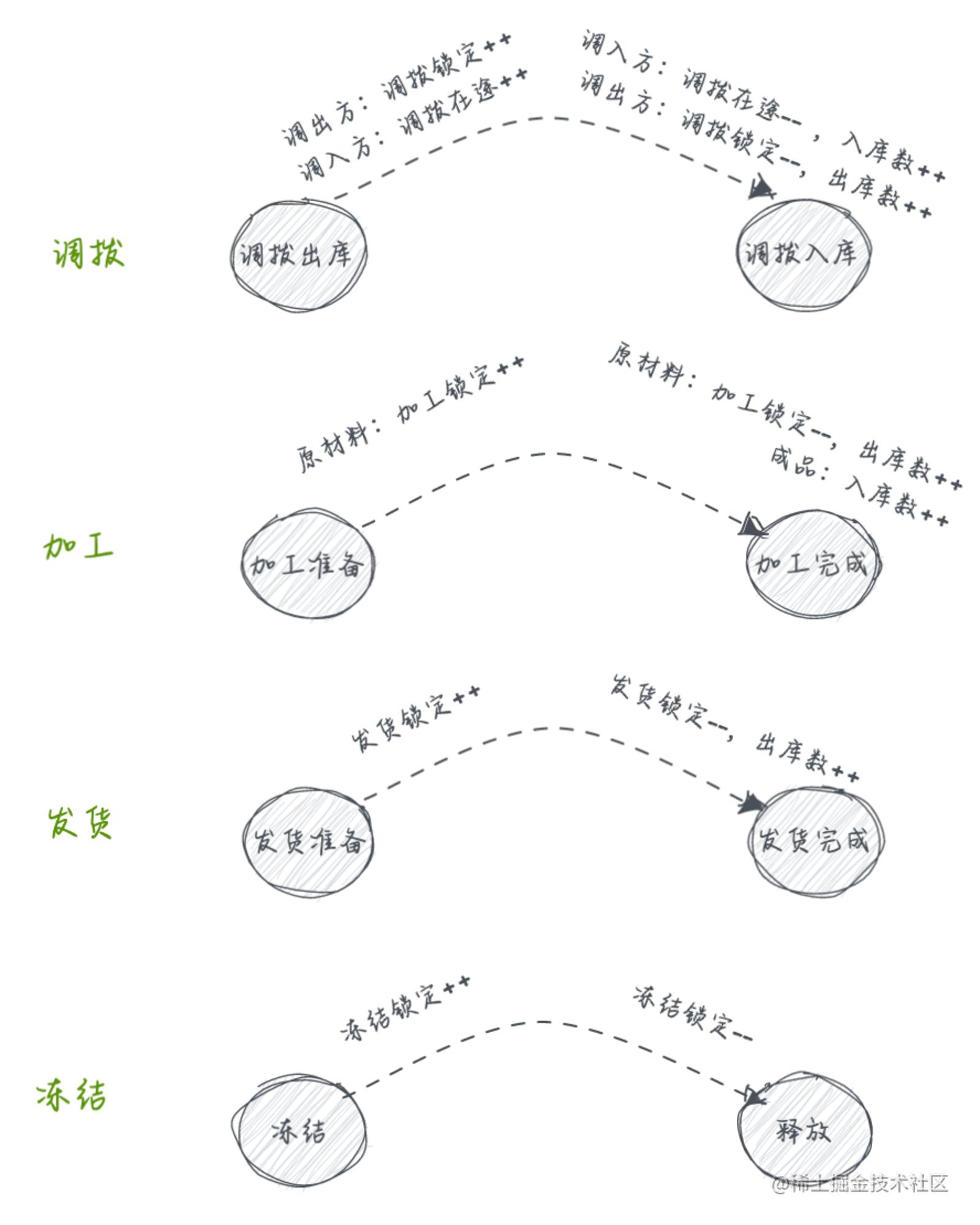
由于业务的多样性,库存的扣减不再是单纯的加加减减原子操作,我们需要抛开业务属性来找到库存变化影响可用库存的规律本质进行适配,如下:
| 动账类型 | 动账逻辑 | 防御性设计 | 恒成立设计 |
|---|---|---|---|
| 增加 | 按需增加 | 不需要 | 可用库存 ≥ 0 |
| 扣减 | 按需扣减 | 扣减库存数 ≥ 扣减数 | 可用库存 ≥ 0 |
| 增扣抵消 | 按需增扣 | 扣减库存数 ≥ 扣减数 | 可用库存 ≥ 0 |
5. 典型问题
5.1 状态机跳跃
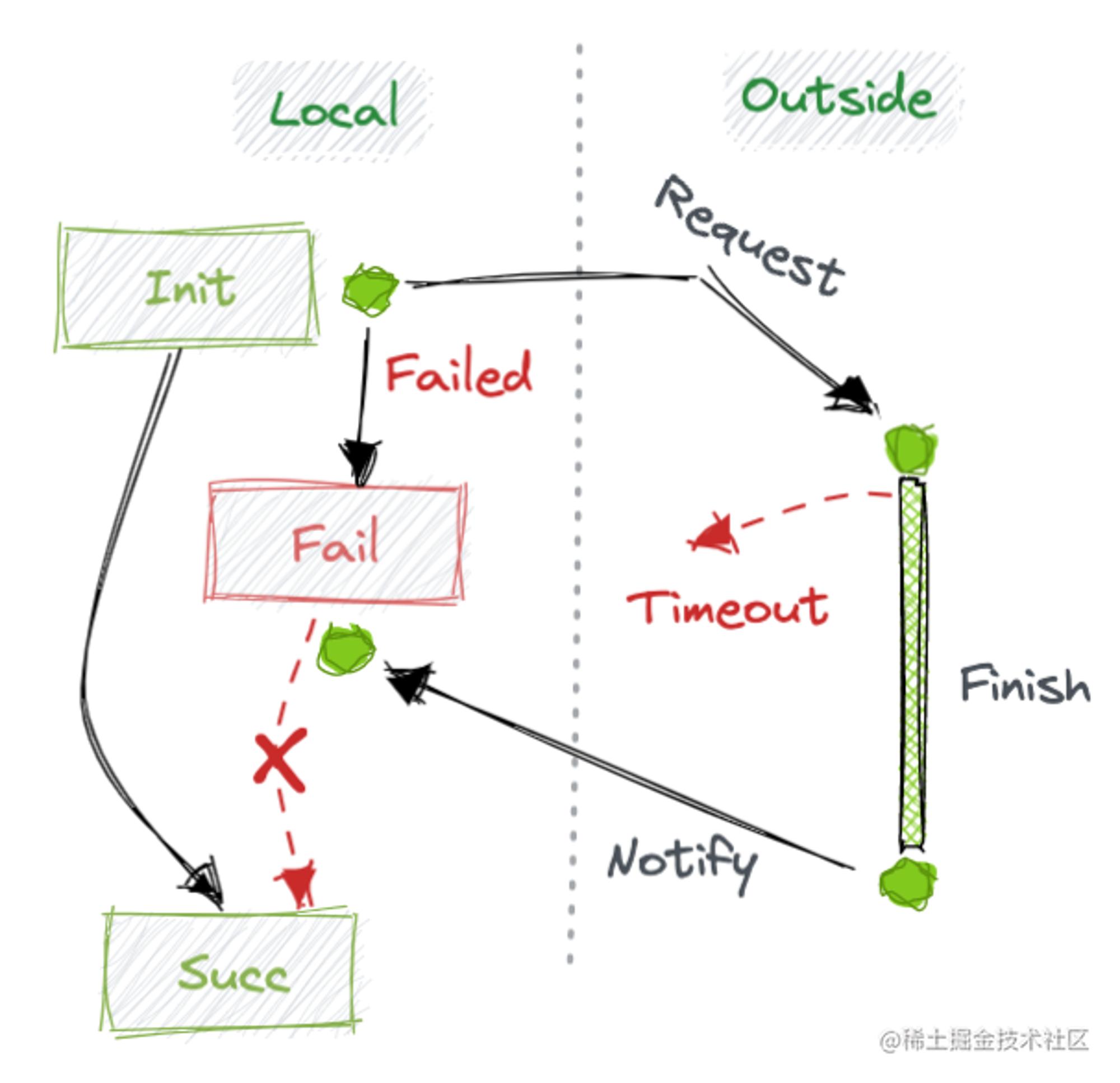
问题主要出现在调用外部接口失败恶化的场景,有可能下游收到请求只是网络原因上游没有收到ACK,状态机处于失败节点停留,若此时上游发起重试会板正此状态为成功且下游幂等;若没有发起重试,业务完成后外部会回调驱动状态机进行到下一节点,而此时状态机不能理解失败到跳跃节点的执行路径进行拒绝,导致状态机无法正常驱动,导致卡死问题出现。
关于状态机的执行路径,不应只考虑正常路径,还要充分思考异常路径问题,因为状态机一旦未按照我们的预期执行说明我们的设计是不完整的,需要充分评估各类卡点,保证永远会有来源能驱动状态机流转实现自治和逻辑自洽。
5.2 秒杀架构合理性
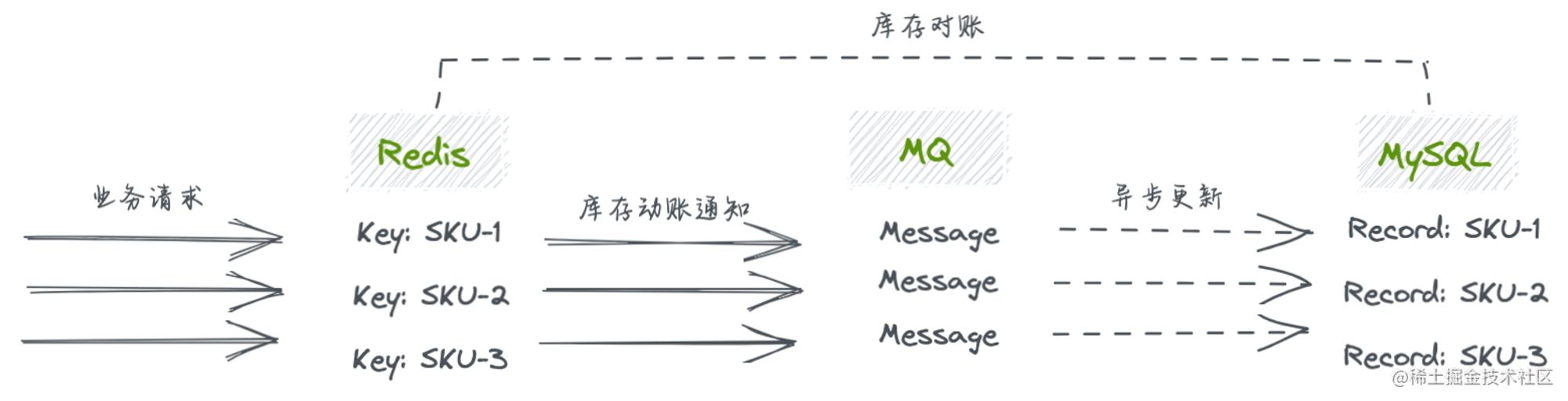
可能难以想象,一个供应链OMS系统的库存动账流程在过去很长一段时间是围绕秒杀架构来设计和实现的,数据主要存储在Redis中,而MySQL更多扮演的是一个数据副本的角色,数据的准确性要在缓存和数据库之间进行对齐,数据库甚至没有动账防重。 简单而言,秒杀架构的应用场景是面向高并发业务的,它放弃了对数据一致性甚至准确性来换取性能收益和用户体验。 对于一个ToB业务系统来说,一方面并不会有ToC业务那样火爆的尖刺时刻带来的流量冲击,最为核心的是对数据准确性和一致性的要求,比如要进行入库采购、发货履约、资源调配、临时冻结等业务,都依赖有确切的库存能力来提供业务决策;另一方面是缓存数据的可靠性、容错性并不高,不能百分之百保证持久化,再者,K-V结构的数据结构在关系表达能力上非常逊色,无法提供完备的事务能力,这是一个做技术方案选型时必须了然于胸的重点。 OMS对库存维度、动账差异化、动态库存的诉求是多方面的,在之后的迭代中,技术方案转向MySQL进行库存数据的可靠存储保证数据安全性,充分利用事务特性联动账户表和动账流水表进行业务防重,横切业务维度支持数据差异化下的排列组合,且在业务扩展后不必受限于K-V的单一映射限制,也不存在数据清理、转换、迁移的成本投入。
5.3 应用级脏读陷阱
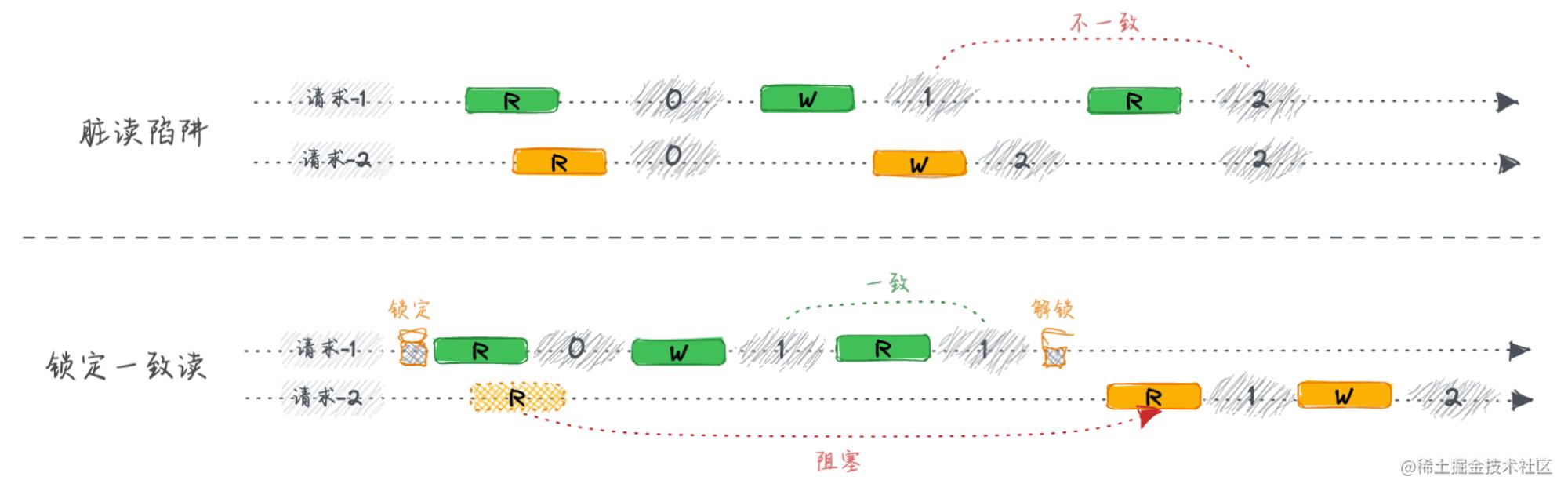
脏读问题一般是因为数据在不同可见性下的隔离策略导致的,大多数情况下都可以选择合适的隔离策略来完成数据读写。在应用级的读写调用中也要特别注意使用不当导致的问题,如提交读请求后做业务判断,然后再去做写请求完成后续业务,这一读一写就是典型的非原子操作,并不能实现锁定一致读的效果,这种锁定资源完成读写的诉求应当封装在原子服务内进行能力输出。类似地变种场景还有,封装了原子能力在单服务输出,但是又提出批量数据要求,外部业务并不能简单地依靠批量调用完成多频次单原子服务能力的原子效果。
曾经糟糕的设计是,履约单下推到仓时要校验有足额库存,原场景是读一次实时库存,然后校验足额履约单会创建再调用推单完成下推,下推接口还会校验一遍实时库存。其实这种设计大部分情况下没有什么问题,不妥的地方在于批量发同源货品做下推就会有少量的业务读到可用库存实际再推单时已经被消耗导致下推失败,由于第一次读接口有效则履约单已完成创建,再下推则只能标记履约单下推失败,依靠重试任务驱动履约单状态机完成业务,且历史各种原因下推失败单据会在一个大池子处理,既增加处理任务的压力,又影响履约效率。较为合理的处理方式是统一收口在下推接口即可,但是下推接口需要提供未足额库存的差异化原因给上游做业务联动和反馈,这样便减少一次读接口消耗,又保证业务的读写一致性,还有一个系统职责单一的收益,那就是库存不足便不会创建起履约单,也就是不会向上游反馈本次业务结果是成功的,那么该业务的驱动便会交回上游处理和把控,减轻自身系统复杂性,优化对业务时效敏感的系统考核统计与不必要的解释成本。
5.4 区别OLAP和OLTP
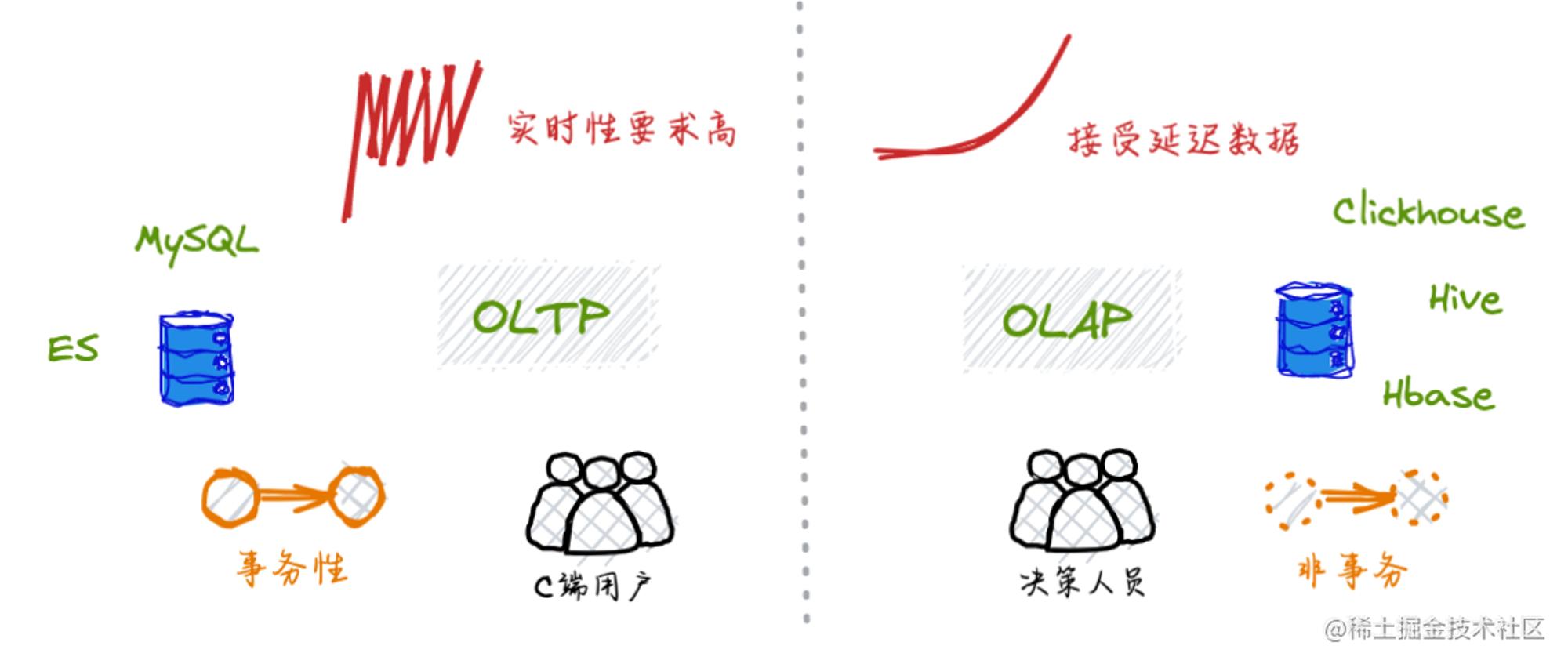
作为一个业务研发同学,关于数据相关的技术栈基本就是mysql、es这些,因此在接到数据相关需求如统计、监控等业务功能时,会受限于技术视野和认知在设计开发环节更多地将此类需求的技术方案依附在mysql、es等数据源上进行设计和交付。当接触到一些OLAP需求时需要开阔一些技术栈视野,可以更多地将技术方案设计依附在clickhouse、hive这些大数据平台相关的数据源。适时地将应用层、数据层按需剥离,各司其职,有效发挥各自优势。
俗话说,工欲善其事必先利其器。如果手里的金刚钻不行,也做不出来什么特别好的瓷器活。没有相关技术储备,做出来的技术方案很扭曲,过程很吃力,可维护性差,最后交付效果、性能都不理想,即使后续优化也是补丁上打补丁或者只能重做,治标不治本。技术选型选得好、选得准,技术方案才能更合理,实现和交付才更游刃有余。
6. 总结
系统是演进的过程
“一口吃不了胖子,胖子也不是一天吃起来的”。 系统是为业务服务的,业务并不是预言家,自己看不到未来更看不到尽头,所以依附在业务上构建的系统永远拿不到设计师给你提供的图纸,技术领域所涵盖的架构、模块、功能等一定也是渐进明细的过程,不要想着套个什么“亿级流量架构”、“DDD”就解决所有困惑高枕无忧了。《淘宝技术这十年》用全篇的故事线条输出,提到最为核心的一点就是 “演进” 。
谁都不可能在设计和实现上一剑封喉,难能可贵的是那些每一次都面向可扩展、对未来变更友好的设计,让一切演进都可以高效迭代,驾驭这种顶层设计思维是应对未知变化最实在、最接近实践的指导。
复杂设计的思考
“年少轻狂爱追梦,一心只想搞重构”。 软件设计是一个很迷人的东西,每个人的技术背景、项目积累、认知程度、成长路径都非常独立和不同,因此会出现形态各异的工程实践。可读性好、逻辑清晰的系统是让人欣喜并乐道的,而复杂到原作者都讲不清的“生态”是难以让人接受的。试想下,设计一个逆天复杂的工程实践的初衷究竟为何呢?从步入这个行业接手过的系统平均生命周期能持续多久?业务形态真的复杂到需要搞一套轮子甚至Framework来支持吗?设计技术方案的出发点是围绕挖掘到的PRD真实诉求还是围绕你难以忘怀的技术想练练手?
好的出发点和技术方案应该是业务需要什么系统能力,通过组织有效、完善的技术手段实现它,而不是夹带“技术私心”偏执地去强硬实践,非要弄一头大象驮蚂蚁,搞出沾沾自喜的名堂,以为表面光鲜的是大象,其实蚂蚁才是决定生死的一切,最后蚂蚁没养起来,全用来喂大象了。我曾走入过这种“复杂设计”的误区,也被其他走入这种误区的应用深深触痛过。
技术需要返璞归真
“看山还是山,看水还是水”。 曾经迷恋从架构理论入手提升,照猫画虎搞了很多四不像的技术方案,现实镜子会一次次照出自己的丑陋,这是负债也是收获。反向积累能彻实明白,没有扎实的积累一切高大上都是形而上学,应当脚踏实地,从通用的技术栈出发,深入细枝末节,打牢基础。工程是一门理论与实践紧密结合的科学,需要从理论出发,在实践中试错求得更深刻的认知,从实践中形成自己的知识树和心得体会,自然地获得触类旁通和成长,一点一滴地从量变转换为质变。
边栏推荐
- Stealing others' vulnerability reports and selling them into sidelines, and the vulnerability reward platform gives rise to "insiders"
- JS卡牌样式倒计时天数
- redis发布订阅的使用
- 每日一题-LeetCode1200-最小绝对差-数组-排序
- Remember to build wheels repeatedly at one time (the setting instructions of obsidian plug-in are translated into Chinese)
- Why does invariant mode improve performance
- LeetCode 7. Integer inversion
- IIC (STM32)
- SolidWorks工程图添加材料明细表的操作
- uniapp 富文本编辑器使用
猜你喜欢
Y56. Chapter III kubernetes from entry to proficiency -- business image version upgrade and rollback (29)
PS竖排英文和数字文字怎么改变方向(变竖直显示)
UTF encoding and character set in golang
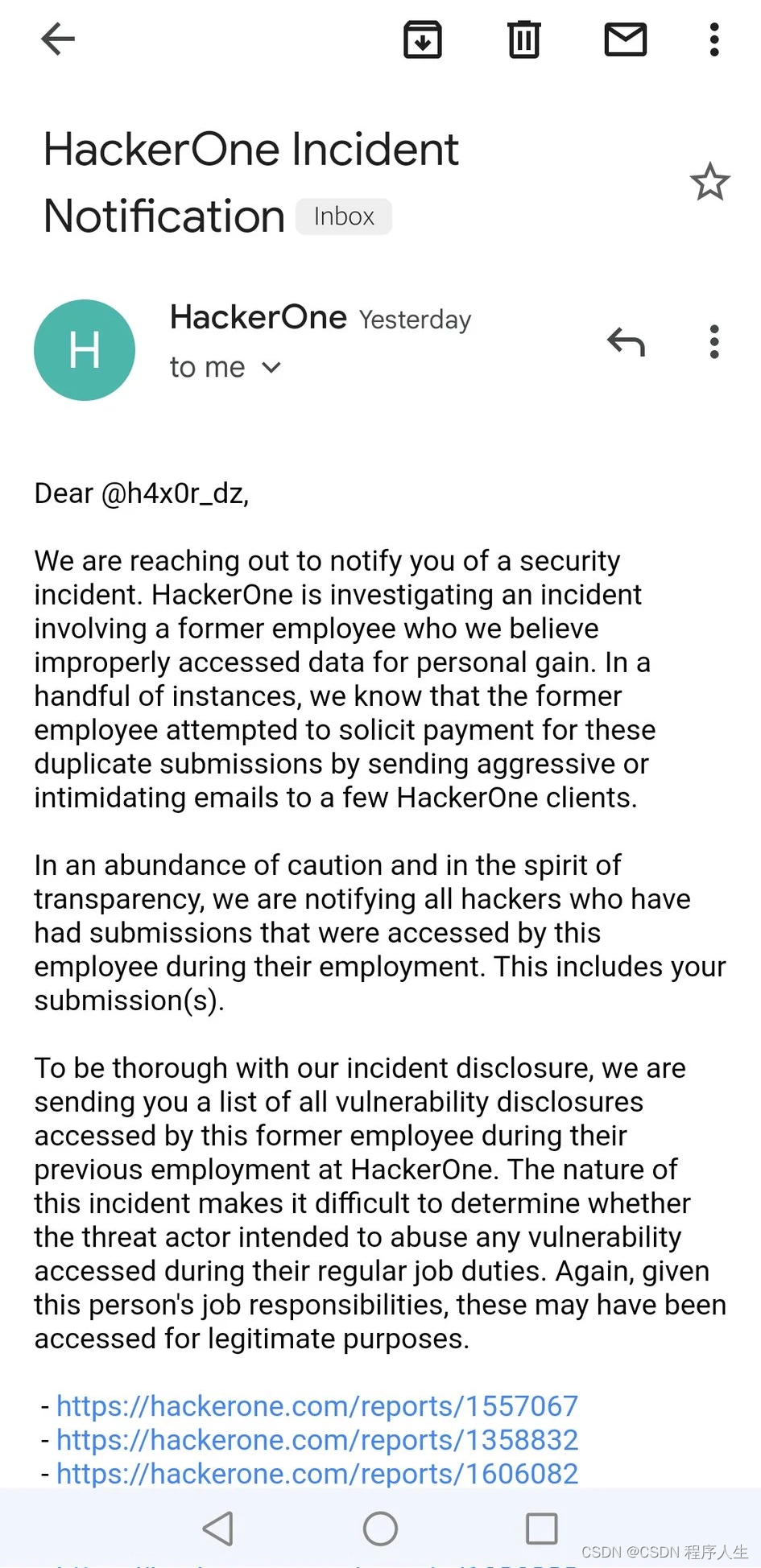
Stealing others' vulnerability reports and selling them into sidelines, and the vulnerability reward platform gives rise to "insiders"

迈动互联中标北京人寿保险
![[1200. Minimum absolute difference]](/img/fa/4ffbedd8f24c75a20d3eaeaf0430ae.png)
[1200. Minimum absolute difference]
Gobang go to work fishing tools can be LAN / man-machine
PS vertical English and digital text how to change direction (vertical display)
Can be displayed in CAD but not displayed in print

改善机器视觉系统的方法
随机推荐
测试用例 (TC)
Test case (TC)
colResizable.js自动调整表格宽度插件
LeetCode 7. Integer inversion
杰理之AD 系列 MIDI 功能说明【篇】
奋斗正当时,城链科技战略峰会广州站圆满召开
[observation] Lenovo: 3x (1+n) smart office solution, releasing the "multiplier effect" of office productivity
Quelques suggestions pour la conception de l'interface
华为ensp模拟器 DNS服务器的配置
[1200. Différence absolue minimale]
CAD中能显示打印不显示
acwing 3302. Expression evaluation
Redis:Redis配置文件相关配置、Redis的持久化
华为ensp模拟器 给路由器配置DHCP
冰河的海报封面
Foxit pdf editor v10.1.8 green version
numpy vstack 和 column_stack
Jerry's ad series MIDI function description [chapter]
The concept and application of hash table
网络命名空间