当前位置:网站首页>机器学习笔记 - 互信息Mutual Information
机器学习笔记 - 互信息Mutual Information
2022-07-04 21:23:00 【坐望云起】
1、概述
遇到一个新的数据集时重要的第一步是使用特征效用指标构建排名,该指标是衡量特征与目标之间关联的函数。然后,您可以选择一小部分最有用的功能进行初始开发。
我们将使用的度量称为“互信息”。互信息很像相关性,因为它衡量两个量之间的关系。互信息的优点是它可以检测任何一种关系,而相关性只检测线性关系。
互信息是一个很好的通用指标,在功能开发开始时特别有用,因为您可能还不知道要使用哪种模型。
互信息易于使用和解释,计算效率高,理论上有根据,抗过拟合,并且能够检测任何类型的关系。
2、相互信息及其衡量标准
互信息描述了不确定性方面的关系。 两个量之间的互信息 (MI) 是衡量一个量的知识减少另一个量的不确定性的程度。 如果你知道一个特性的价值,你会对目标更有信心吗?
这是 Ames Housing 数据中的一个示例。 该图显示了房屋的外观质量与其售价之间的关系。 每个点代表一所房子。
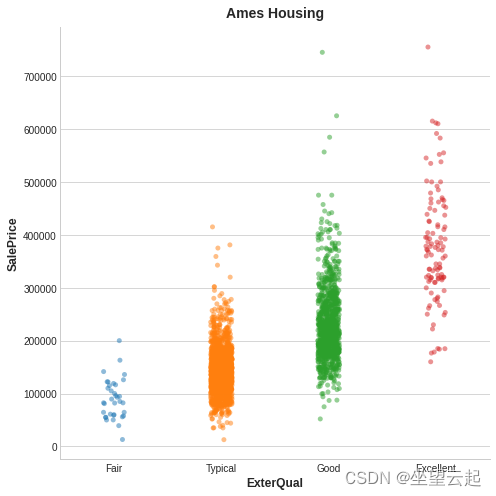
从图中我们可以看出,知道 ExterQual 的值应该会让你对对应的 SalePrice 更加确定——ExterQual 的每个类别都倾向于将 SalePrice 集中在一定的范围内。 ExterQual 与 SalePrice 的互信息是采用 ExterQual 的四个值时 SalePrice 中不确定性的平均减少。 例如,由于 Fair 的出现频率低于典型,因此 Fair 在 MI 得分中的权重较小。
我们所说的不确定性是使用信息论中称为“熵”的量来衡量的。变量的熵大致意味着:“你需要多少是或否的问题来描述这种情况的发生 变量,平均而言。”你要问的问题越多,你对变量的不确定性就越大。相互信息是你期望特征回答多少关于目标的问题。
3、解释互信息分数
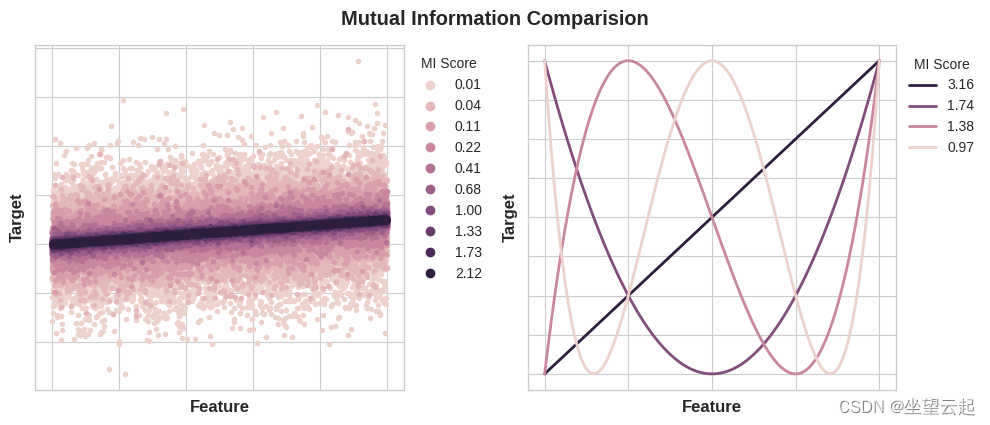
数量之间的最小可能互信息为 0.0。 当 MI 为零时,这些数量是独立的:两者都无法告诉您关于对方的任何信息。 相反,理论上 MI 没有上限。 在实践中,虽然高于 2.0 左右的值并不常见。 (互信息是一个对数量,所以它增加得很慢。)
下图将让您了解 MI 值如何对应于特征与目标的关联类型和程度。
以下是应用互信息时要记住的一些事项:
MI 可以帮助您了解一个特征作为目标预测因子的相对潜力,并单独考虑。
在与其他功能交互时,一个功能可能会提供非常丰富的信息,但单独的信息量可能不是很大。 MI 无法检测特征之间的交互。 它是一个单变量指标。
功能的实际用途取决于您使用它的模型。 一个特征只有在它与目标的关系是你的模型可以学习的关系时才有用。 仅仅因为一个特征具有高 MI 分数并不意味着您的模型将能够使用该信息做任何事情。 您可能需要先转换特征以公开关联。
4、示例 - 1985 年的汽车
汽车数据集由 1985 年的 193 辆汽车组成。 该数据集的目标是根据汽车的 23 个特征(例如品牌、车身样式和马力)来预测汽车的价格(目标)。 在本例中,我们将对具有互信息的特征进行排名,并通过数据可视化研究结果。
Automobile Dataset | KaggleDataset consist of various characteristic of an auto
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
plt.style.use("seaborn-whitegrid")
df = pd.read_csv("../input/fe-course-data/autos.csv")
df.head()
MI 的 scikit-learn 算法处理离散特征与连续特征不同。 根据经验,任何必须具有 float dtype 的东西都不是离散的。 通过给它们一个标签编码,可以将分类(对象或分类 dtype)视为离散的。
X = df.copy()
y = X.pop("price")
# Label encoding for categoricals
for colname in X.select_dtypes("object"):
X[colname], _ = X[colname].factorize()
# All discrete features should now have integer dtypes (double-check this before using MI!)
discrete_features = X.dtypes == int
Scikit-learn 在其 feature_selection 模块中有两个互信息度量:一个用于实值目标(mutual_info_regression),一个用于分类目标(mutual_info_classif)。 我们的目标,价格,是真实价值的。 下一个单元计算我们的特征的 MI 分数,并将它们包装在一个数据框中。
from sklearn.feature_selection import mutual_info_regression
def make_mi_scores(X, y, discrete_features):
mi_scores = mutual_info_regression(X, y, discrete_features=discrete_features)
mi_scores = pd.Series(mi_scores, name="MI Scores", index=X.columns)
mi_scores = mi_scores.sort_values(ascending=False)
return mi_scores
mi_scores = make_mi_scores(X, y, discrete_features)
mi_scores[::3] # show a few features with their MI scorescurb_weight 1.486440
highway_mpg 0.950989
length 0.607955
bore 0.489772
stroke 0.380041
drive_wheels 0.332973
compression_ratio 0.134799
fuel_type 0.048139
Name: MI Scores, dtype: float64现在是一个条形图,可以让比较更容易:
def plot_mi_scores(scores):
scores = scores.sort_values(ascending=True)
width = np.arange(len(scores))
ticks = list(scores.index)
plt.barh(width, scores)
plt.yticks(width, ticks)
plt.title("Mutual Information Scores")
plt.figure(dpi=100, figsize=(8, 5))
plot_mi_scores(mi_scores)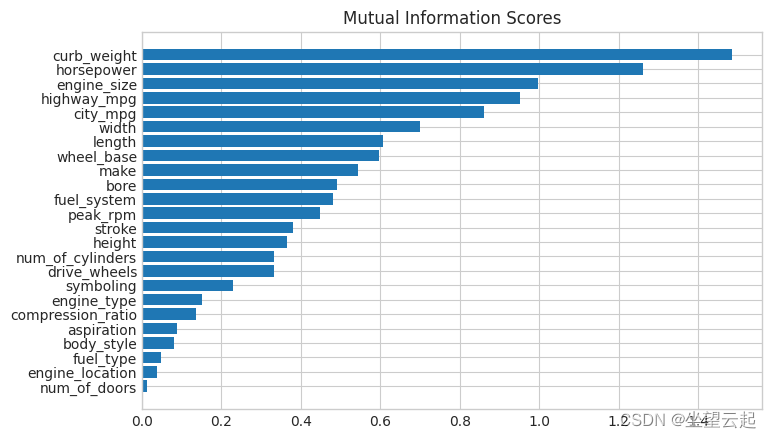
数据可视化是实用程序排名的一个很好的后续。 让我们仔细看看其中的几个。
正如我们所预料的那样,高分的curb_weight特征与目标价格有很强的关系。
sns.relplot(x="curb_weight", y="price", data=df);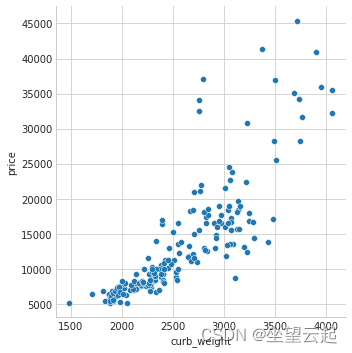
Fuel_type 特征具有相当低的 MI 分数,但从图中我们可以看出,它清楚地区分了马力特征内具有不同趋势的两个价格人群。 这表明fuel_type 贡献了一种交互作用,而且可能并非不重要。 在从 MI 分数确定一个特性不重要之前,最好调查任何可能的交互影响——专业领域内的知识可以在这里提供很多指导。
sns.lmplot(x="horsepower", y="price", hue="fuel_type", data=df);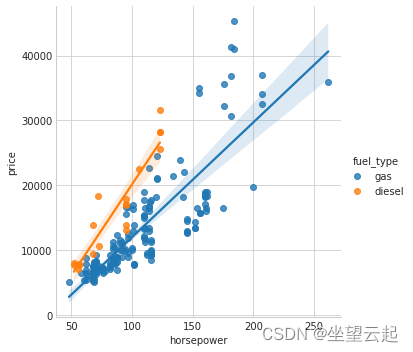
数据可视化是对特征工程工具箱的重要补充。 除了诸如互信息之类的实用指标外,此类可视化可以帮助您发现数据中的重要关系。
边栏推荐
- Operation of adding material schedule in SolidWorks drawing
- Application practice | Shuhai supply chain construction of data center based on Apache Doris
- 开源之夏专访|Apache IoTDB社区 新晋Committer谢其骏
- Flutter 返回按钮的监听
- 应用实践 | 蜀海供应链基于 Apache Doris 的数据中台建设
- WGCNA analysis basic tutorial summary
- How much is the minimum stock account opening commission? Is it safe to open an account online
- Kubedm initialization error: [error cri]: container runtime is not running
- GTEST from ignorance to skillful use (1) GTEST installation
- Redis 排查大 key 的3种方法,优化必备
猜你喜欢

How was MP3 born?
QT - double buffer plot
Bookmark

创客思维在高等教育中的启迪作用

Methods of improving machine vision system
![[public class preview]: basis and practice of video quality evaluation](/img/fd/42b98a08b5a0fd89c119f1d1a8fe1b.png)
[public class preview]: basis and practice of video quality evaluation
WGCNA analysis basic tutorial summary

At the right time, the Guangzhou station of the city chain science and Technology Strategy Summit was successfully held
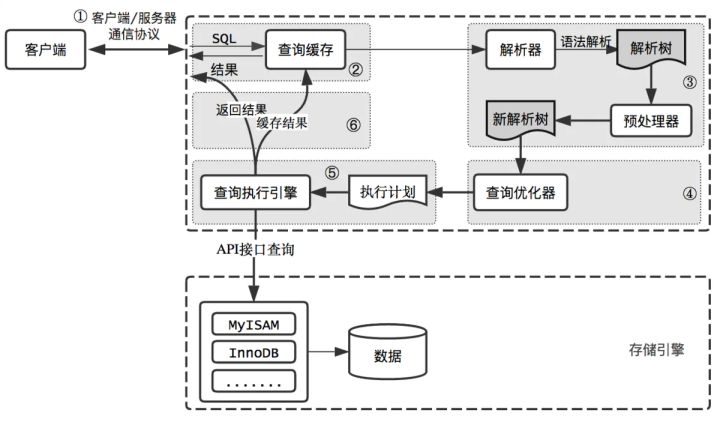
How is the entered query SQL statement executed?
做BI开发,为什么一定要熟悉行业和企业业务?
随机推荐
Kubeadm初始化报错:[ERROR CRI]: container runtime is not running
历史最全混合专家(MOE)模型相关精选论文、系统、应用整理分享
挖财学院股票开户安全吗?开户只能在挖财开户嘛?
Redis has three methods for checking big keys, which are necessary for optimization
Jerry's ad series MIDI function description [chapter]
Master the use of auto analyze in data warehouse
Flutter 返回按钮的监听
【活动早知道】LiveVideoStack近期活动一览
[wechat applet] collaborative work and release
Cadeus has never stopped innovating. Decentralized edge rendering technology makes the metauniverse no longer far away
开户哪家券商比较好?网上开户安全吗
Keep on fighting! The city chain technology digital summit was grandly held in Chongqing
Maya lamp modeling
MP3是如何诞生的?
Flink1.13 SQL basic syntax (I) DDL, DML
Jerry added the process of turning off the touch module before turning it off [chapter]
Shutter textfield example
Cloudcompare & open3d DBSCAN clustering (non plug-in)
Bookmark
Numpy vstack and column_ stack