当前位置:网站首页>Redis入门完整教程:HyperLogLog
Redis入门完整教程:HyperLogLog
2022-07-04 22:29:00 【谷哥学术】
HyperLogLog并不是一种新的数据结构(实际类型为字符串类型),而
是一种基数算法,通过HyperLogLog可以利用极小的内存空间完成独立总数
的统计,数据集可以是IP、Email、ID等。HyperLogLog提供了3个命令:
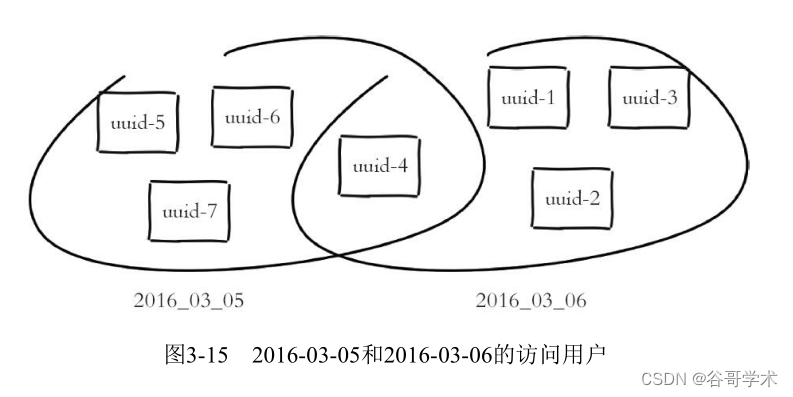
pfadd、pfcount、pfmerge。例如2016-03-06的访问用户是uuid-1、uuid-2、
uuid-3、uuid-4,2016-03-05的访问用户是uuid-4、uuid-5、uuid-6、uuid-7,如
图3-15所示。
注意
HyperLogLog的算法是由Philippe
Flajolet(https://en.wikipedia.org/wiki/Philippe_Flajolet)在The analysis of a
near-optimal cardinality estimation algorithm这篇论文中提出,读者如果有兴趣
可以自行阅读。
1.添加
pfadd key element [element … ]
pfadd用于向HyperLogLog添加元素,如果添加成功返回1:
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
2.计算独立用户数
pfcount key [key … ]
pfcount用于计算一个或多个HyperLogLog的独立总数,例如
2016_03_06:unique:ids的独立总数为4:
127.0.0.1:6379> pfcount 2016_03_06:unique:ids
(integer) 4
如果此时向2016_03_06:unique:ids插入uuid-1、uuid-2、uuid-3、uuid-
90,结果是5(新增uuid-90):
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-90"
(integer) 1
127.0.0.1:6379> pfcount 2016_03_06:unique:ids
(integer) 5
当前这个例子内存节省的效果还不是很明显,下面使用脚本向
HyperLogLog插入100万个id,插入前记录一下info memory:
127.0.0.1:6379> info memory
# Memory
used_memory:835144
used_memory_human:815.57K
... 向 2016_05_01:unique:ids 插入 100 万个用户,每次插入 1000 条:
elements=""
key="2016_05_01:unique:ids"
for i in `seq 1 1000000`
do
elements="${elements} uuid-"${i}
if [[ $((i%1000)) == 0 ]];
then
redis-cli pfadd ${key} ${elements}
elements=""
fi
done
当上述代码执行完成后,可以看到内存只增加了15K左右:
127.0.0.1:6379> info memory
# Memory
used_memory:850616
used_memory_human:830.68K
但是,同时可以看到pfcount的执行结果并不是100万:
127.0.0.1:6379> pfcount 2016_05_01:unique:ids
(integer) 1009838
可以对100万个uuid使用集合类型进行测试,代码如下:
elements=""
key="2016_05_01:unique:ids:set"
for i in `seq 1 1000000`
do
elements="${elements} "${i}
if [[ $((i%1000)) == 0 ]];
then
redis-cli sadd ${key} ${elements}
elements=""
fi
done
可以看到内存使用了84MB:
127.0.0.1:6379> info memory
# Memory
used_memory:88702680
used_memory_human:84.59M
但独立用户数为100万:
127.0.0.1:6379> scard 2016_05_01:unique:ids:set
(integer) 1000000
表3-6列出了使用集合类型和HperLogLog统计百万级用户的占用空间对
比。

可以看到,HyperLogLog内存占用量小得惊人,但是用如此小空间来估
算如此巨大的数据,必然不是100%的正确,其中一定存在误差率。Redis官
方给出的数字是0.81%的失误率。
3.合并
pfmerge destkey sourcekey [sourcekey ...]
pfmerge可以求出多个HyperLogLog的并集并赋值给destkey,例如要计算
2016年3月5日和3月6日的访问独立用户数,可以按照如下方式来执行,可以
看到最终独立用户数是7:
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
127.0.0.1:6379> pfadd 2016_03_05:unique:ids "uuid-4" "uuid-5" "uuid-6" "uuid-7"
(integer) 1
127.0.0.1:6379> pfmerge 2016_03_05_06:unique:ids 2016_03_05:unique:ids
2016_03_06:unique:ids
OK
127.0.0.1:6379> pfcount 2016_03_05_06:unique:ids
(integer) 7
HyperLogLog内存占用量非常小,但是存在错误率,开发者在进行数据
结构选型时只需要确认如下两条即可:
·只为了计算独立总数,不需要获取单条数据。
·可以容忍一定误差率,毕竟HyperLogLog在内存的占用量上有很大的优
势。
边栏推荐
猜你喜欢
2022-07-04:以下go语言代码输出什么?A:true;B:false;C:编译错误。 package main import “fmt“ func main() { fmt.Pri
Li Kou 98: verify binary search tree

攻防世界 misc 高手进阶区 a_good_idea
【室友用一局王者荣耀的时间学会了用BI报表数据处理】
![[Yugong series] go teaching course 003-ide installation and basic use in July 2022](/img/65/b36ca239e06a67c01d1eb0b4648f71.png)
[Yugong series] go teaching course 003-ide installation and basic use in July 2022
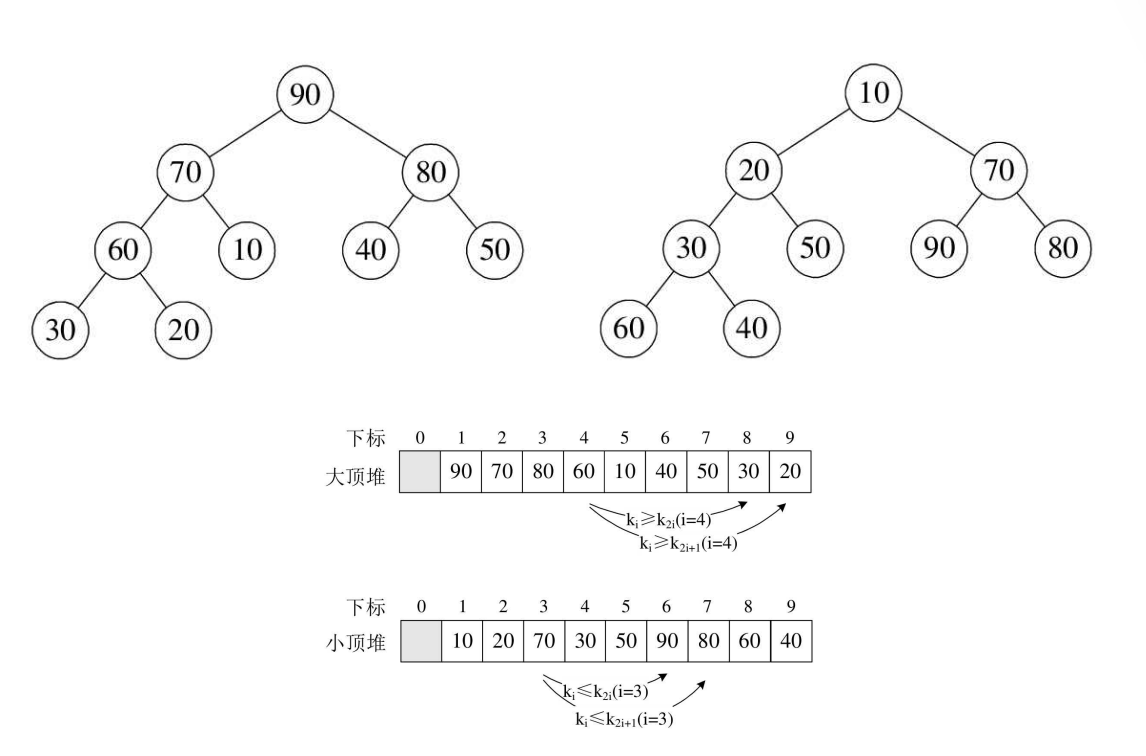
Detailed explanation of heap sort code

It is said that software testing is very simple, but why are there so many dissuasions?
[the 2023 autumn recruitment of MIHA tour] open [the only exclusive internal push code of school recruitment eytuc]
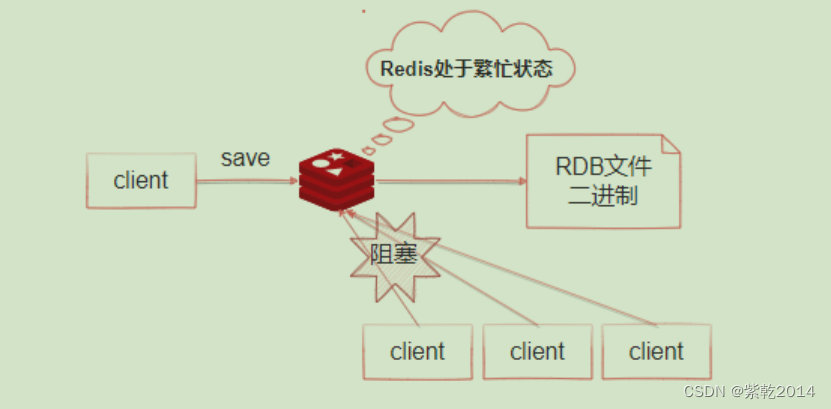
Persistence mechanism of redis
Close system call analysis - Performance Optimization
![[the 2023 autumn recruitment of MIHA tour] open [the only exclusive internal push code of school recruitment eytuc]](/img/5b/35d855520741ac50507c2ff00cef97)
随机推荐
In Linux, I call odspcmd to query the database information. How to output silently is to only output values. Don't do this
集群的概述与定义,一看就会
新版判断PC和手机端代码,手机端跳转手机端,PC跳转PC端最新有效代码
POM in idea XML dependency cannot be imported
LOGO特訓營 第三節 首字母創意手法
Solana chain application crema was shut down due to hacker attacks
The Sandbox 和数字好莱坞达成合作,通过人力资源开发加速创作者经济的发展
Detailed explanation of heap sort code
剑指 Offer 65. 不用加减乘除做加法
How to reset the password of MySQL root account
Interview essential leetcode linked list algorithm question summary, whole process dry goods!
Embedded development: skills and tricks -- seven skills to improve the quality of embedded software code
攻防世界 MISC 进阶区 hong
How to manage 15million employees easily?
PHP short video source code, thumb animation will float when you like it
不同环境相同配置项的内容如何diff差异?
Unity修仙手游 | lua动态滑动功能(3种源码具体实现)
Practice and principle of PostgreSQL join
达梦数据凭什么被称为国产数据库“第一股”?
SPSS installation and activation tutorial (including network disk link)