当前位置:网站首页>Apache Iceberg 中三种操作表的方式
Apache Iceberg 中三种操作表的方式
2020-11-09 07:35:00 【osc_tjee7sjs】
在 Apache Iceberg 中有很多种方式可以来创建表,其中就包括使用 Catalog 方式或者实现 org.apache.iceberg.Tables 接口。下面我们来简单介绍如何使用。.
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号: iteblog_hadoop
使用 Hive catalog
从名字就可以看出,Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它的实现类为 org.apache.iceberg.hive.HiveCatalog,下面是通过 sparkContext 中的 hadoopConfiguration 来获取 HiveCatalog 的方式:
import org.apache.iceberg.hive.HiveCatalog;
Catalog catalog = new HiveCatalog(spark.sparkContext().hadoopConfiguration());Catalog 接口里面定义了操作表的方法,比如 createTable, loadTable, renameTable, 以及 dropTable。如果想创建表,我们需要定义 TableIdentifier,表的 Schema 以及分区的信息,如下:
import org.apache.iceberg.Table;
import org.apache.iceberg.catalog.TableIdentifier;
import org.apache.iceberg.PartitionSpec;
import org.apache.iceberg.Schema;
TableIdentifier name = TableIdentifier.of("default", "iteblog");
Schema schema = new Schema(
Types.NestedField.required(1, "id", Types.IntegerType.get()),
Types.NestedField.optional(2, "name", Types.StringType.get()),
Types.NestedField.required(3, "age", Types.IntegerType.get()),
Types.NestedField.optional(4, "ts", Types.TimestampType.withZone())
);
PartitionSpec spec = PartitionSpec.builderFor(schema).year("ts").bucket("id", 2).build();
Table table = catalog.createTable(name, schema, spec);使用 Hadoop catalog
Hadoop catalog 不依赖 Hive MetaStore 来存储元数据,其使用 HDFS 或者类似的文件系统来存储元数据。注意,文件系统需要支持原子的重命名操作,所以本地文件系统(local FS)、对象存储(S3、OSS等)来存储 Apache Iceberg 元数据是不安全的。下面是获取 HadoopCatalog 例子:
import org.apache.hadoop.conf.Configuration;
import org.apache.iceberg.hadoop.HadoopCatalog;
Configuration conf = new Configuration();
String warehousePath = "hdfs://www.iteblog.com:8020/warehouse_path";
HadoopCatalog catalog = new HadoopCatalog(conf, warehousePath);和 Hive catalog 一样,HadoopCatalog 也是实现 Catalog 接口的,所以其也实现了表的各种操作方法,包括 createTable, loadTable, 以及 dropTable。下面是使用 HadoopCatalog 来创建 Iceberg 的例子:
import org.apache.iceberg.Table;
import org.apache.iceberg.catalog.TableIdentifier;
TableIdentifier name = TableIdentifier.of("logging", "logs");
Table table = catalog.createTable(name, schema, spec);使用 Hadoop tables
Iceberg 也支持存储在 HDFS 目录中的表。和 Hadoop catalog 一样,文件系统需要支持原子的重命名操作,所以本地文件系统(local FS)、对象存储(S3、OSS等)来存储 Apache Iceberg 元数据是不安全的。这种方式存储的表并不支持表的各种操作,比如不支持 renameTable。下面是获取 HadoopTables 的例子:
import org.apache.hadoop.conf.Configuration;
import org.apache.iceberg.hadoop.HadoopTables;
import org.apache.iceberg.Table;
Configuration conf = new Configuration():
HadoopTables tables = new HadoopTables(conf);
Table table = tables.create(schema, spec, table_location);在 Spark 中,其支持 HiveCatalog、HadoopCatalog 以及 HadoopTables 方式来创建、加载表。如果传入的表不是一个路径,则选择 HiveCatalog,否则 Spark 将推断出表是存储在 HDFS 上的。
当然,Apache Iceberg 表元数据存储地方是可插拔的,所以我们完全可以自定义元数据存储的方式,比如 AWS 就给社区提了一个 issue,其把 Apache Iceberg 中的元数据存储到 glue 里面,参见 #1633、#1608。
本博客文章除特别声明,全部都是原创!转载本文请加上:转载自过往记忆(https://www.iteblog.com/)
本文链接: 【Apache Iceberg 中三种操作表的方式】(https://www.iteblog.com/archives/9886.html)
版权声明
本文为[osc_tjee7sjs]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4410409/blog/4708492
边栏推荐
- 教你如何 分析 Android ANR 问题
- Factory pattern pattern pattern (simple factory, factory method, abstract factory pattern)
- FC 游戏机的工作原理是怎样的?
- When we talk about data quality, what are we talking about?
- Share API on the web
- STC转STM32第一次开发
- 无法启动此程序,因为计算机中丢失 MSVCP120.dll。尝试安装该程序以解决此问题
- 操作系统之bios
- 23张图,带你入门推荐系统
- 卧槽,这年轻人不讲武德,应届生凭“小抄”干掉5年老鸟,成功拿到字节20Koffer
猜你喜欢
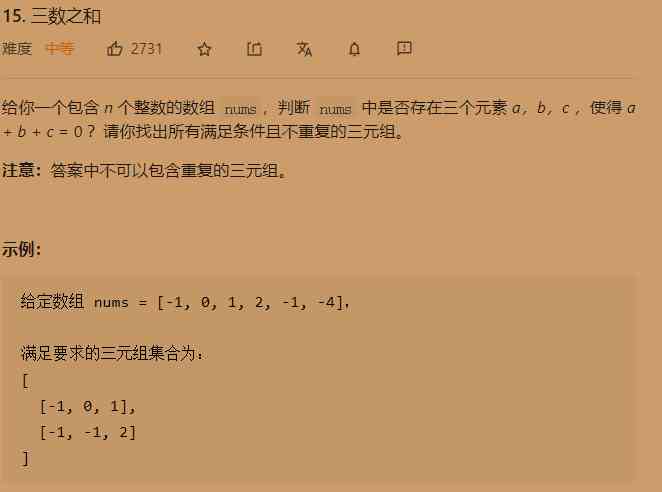
Leetcode-15: sum of three numbers
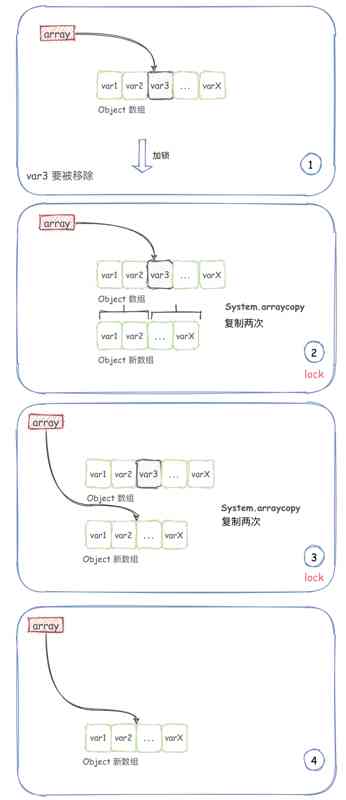
Copy on write collection -- copyonwritearraylist
几行代码轻松实现跨系统传递 traceId,再也不用担心对不上日志了!

1. What does the operating system do?
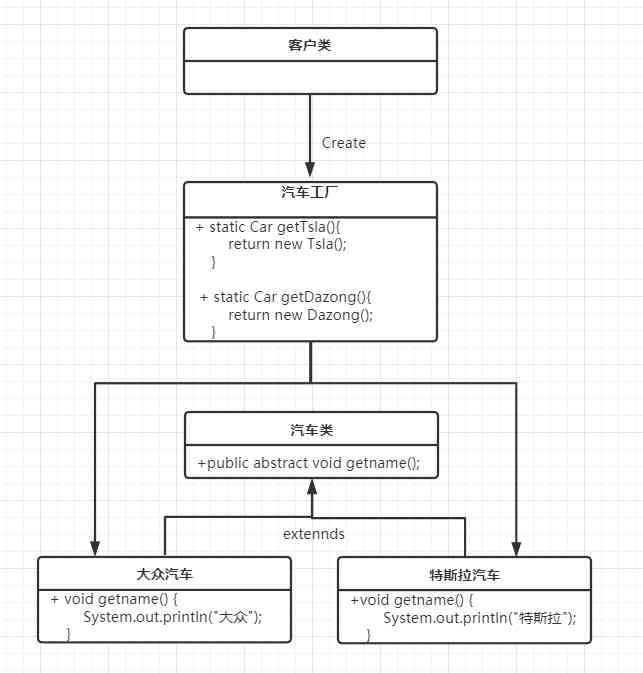
Factory Pattern模式(简单工厂、工厂方法、抽象工厂模式)
程序员都应该知道的URI,一文帮你全面了解

RabbitMQ快速入门详解
Android emulator error: x86 emulation currently requires hardware acceleration solution

c++11-17 模板核心知识(二)—— 类模板
How to analyze Android anr problems
随机推荐
自然语言处理(NLP)路线图 - kdnuggets
Pipedrive如何在每天部署50+次的情况下支持质量发布?
C + + adjacency matrix
A few lines of code can easily transfer traceid across systems, so you don't have to worry about losing the log!
Chapter 5 programming
Have you ever thought about why the transaction and refund have to be split into different tables
Common feature pyramid network FPN and its variants
Huawei HCIA notes
How does semaphore, a thread synchronization tool that uses an up counter, look like?
python生日贺卡制作以及细节问题的解决最后把python项目发布为exe可执行程序过程
Platform in architecture
你有没有想过为什么交易和退款要拆开不同的表
Android emulator error: x86 emulation currently requires hardware acceleration solution
When iperf is installed under centos7, the solution of make: * no targets specified and no makefile found. Stop
Programmers should know the URI, a comprehensive understanding of the article
Linked list
20201108编程练习——练习3
Exception capture and handling in C + +
几行代码轻松实现跨系统传递 traceId,再也不用担心对不上日志了!
Operation 2020.11.7-8