当前位置:网站首页>基于LSTM模型实现新闻分类
基于LSTM模型实现新闻分类
2022-07-01 21:32:00 【拼命_小李】
1、简述LSTM模型
LSTM是长短期记忆神经网络,根据论文检索数据大部分应用于分类、机器翻译、情感识别等场景,在文本中,主要使用tensorflow及keras,搭建LSTM模型实现新闻分类案例。(只讨论和实现其模型的应用案例,不去叙述起实现原理)
2、 数据处理
需要有新闻数据和停用词文档做前期的数据准备工作,使用jieba分词和pandas对初始数据进行预处理工作,数据总量为12000。初始数据集如下图:

首先读取停用词列表,其次使用pandas对数据文件读取,使用jieba库对每行数据进行分词及停用词的处理,处理代码如下图:
def get_custom_stopwords(stop_words_file):
with open(stop_words_file,encoding='utf-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
cachedStopWords = get_custom_stopwords("stopwords.txt")
import pandas as np
import jieba
data = np.read_csv("sohu_test.txt", sep="\t",header=None)
lable_dict = {v:k for k,v in enumerate(data[0].unique())}
data[0] = data[0].map(lable_dict)
def chinese_word_cut(mytext):
return " ".join([word for word in jieba.cut(mytext) if word not in cachedStopWords])
data[1] = data[1].apply(chinese_word_cut)
data3、文本数据向量化
设置模型初始参数batch_size:每轮的数据批次,class_size:类别,epochs:训练轮数,num_words:最常出现的词的数(该变量在进行Embeding的时候需要填入词汇表大小+1),max_len :文本向量的维度,使用Tokenizer实现向量构建并作padding
batch_size = 32
class_size = 12
epochs = 300
num_words = 5000
max_len = 600
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing import sequence
tokenizer = Tokenizer(num_words=num_words)
tokenizer.fit_on_texts(data[1])
# print(tokenizer.word_index)
# train = tokenizer.texts_to_matrix(data[1])
train = tokenizer.texts_to_sequences(data[1])
train = sequence.pad_sequences(train,maxlen=max_len)4、模型搭建
使用train_test_split对数据集进行数据拆分,并搭建模型
from tensorflow.keras.layers import *
from tensorflow.keras import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras import optimizers
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import ModelCheckpoint
import numpy as np
lable = np_utils.to_categorical(data[0], num_classes=12)
X_train, X_test, y_train, y_test = train_test_split(train, lable, test_size=0.1, random_state=200)
model = Sequential()
model.add(Embedding(num_words+1, 128, input_length=max_len))
model.add(LSTM(128,dropout=0.2, recurrent_dropout=0.2))
# model.add(Dense(64,activation="relu"))
# model.add(Dropout(0.2))
# model.add(Dense(32,activation="relu"))
# model.add(Dropout(0.2))
model.add(Dense(class_size,activation="softmax"))
# 载入模型
# model = load_model('my_model2.h5')
model.compile(optimizer = 'adam', loss='categorical_crossentropy',metrics=['accuracy'])
checkpointer = ModelCheckpoint("./model/model_{epoch:03d}.h5", verbose=0, save_best_only=False, save_weights_only=False, period=2)
model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs=epochs, batch_size=batch_size, callbacks=[checkpointer])
# model.fit(X_train, y_train, validation_split = 0.2, shuffle=True, epochs=epochs, batch_size=batch_size, callbacks=[checkpointer])
model.save('my_model4.h5')
# print(model.summary())训练过程如下图所示:

5、模型训练结果可视化
import matplotlib.pyplot as plt
# 绘制训练 & 验证的准确率值
plt.plot(model.history.history['accuracy'])
plt.plot(model.history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# 绘制训练 & 验证的损失值
plt.plot(model.history.history['loss'])
plt.plot(model.history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()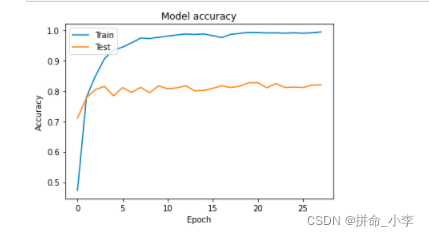
6、模型预测
text = "独家新闻 章子怡 机场 暴走 奔 情郎 图 提要 6 月 明星 充实 一边 奉献 爱心 积极参与 赈灾 重建 活动 "
text = [" ".join([word for word in jieba.cut(text) if word not in cachedStopWords])]
# tokenizer = Tokenizer(num_words=num_words)
# tokenizer.fit_on_texts(text)
seq = tokenizer.texts_to_sequences(text)
padded = sequence.pad_sequences(seq, maxlen=max_len)
# np.expand_dims(padded,axis=0)
test_pre = test_model.predict(padded)
test_pre.argmax(axis=1)
7、代码下载
边栏推荐
- Gaussdb (for MySQL):partial result cache, which accelerates the operator by caching intermediate results
- Target detection - Yolo series
- leetcode刷题:二叉树02(二叉树的中序遍历)
- 杰理之、产线装配环节【篇】
- 4. 对象映射 - Mapping.Mapstercover
- Penetration tools - trustedsec's penetration testing framework (PTF)
- 寫博客文檔
- 随机头像大全,多分类带历史记录微信小程序源码_支持流量主
- tensorflow 张量做卷积,输入量与卷积核维度的理解
- 【Opencv450】HOG+SVM 与Hog+cascade进行行人检测
猜你喜欢






随机推荐
芭比Q了!新上架的游戏APP,咋分析?
4. 对象映射 - Mapping.Mapstercover
burpsuite简单抓包教程[通俗易懂]
ngnix基础知识
打出三位数的所有水仙花数「建议收藏」
Big factories are wolves, small factories are dogs?
Test of NSI script
寫博客文檔
人才近悦远来,望城区夯实“强省会”智力底座
MySQL数据库驱动(JDBC Driver)jar包下载
There are four ways to write switch, you know
【级联分类器训练参数】Training Haar Cascades
面试题:MySQL的union all和union有什么区别、MySQL有哪几种join方式(阿里面试题)[通俗易懂]
东哥套现,大佬隐退?
leetcode刷题:二叉树03(二叉树的后序遍历)
【Leetcode】最大连续1的个数
【商业终端仿真解决方案】上海道宁为您带来Georgia介绍、试用、教程
杰理之、产线装配环节【篇】
Entering Ruxin Town, digital intelligence transformation connects "future community"
js如何获取集合对象中某元素列表