当前位置:网站首页>Implementing pytorch style deep learning framework similartorch with numpy
Implementing pytorch style deep learning framework similartorch with numpy
2022-06-12 13:22:00 【Kun Li】
https://github.com/kaszperro/slick-dnn https://github.com/kaszperro/slick-dnn
https://github.com/kaszperro/slick-dnn
Project git Address :https://github.com/leeguandong/SimilarWork
according to torch Based on numpy Deep learning framework , No matter tensorflow still pytorch, The principles of the framework are similar , It's just that there are differences in the design of static graph and dynamic graph , But back propagation is similar . I refer to pytorch stay similartorch Added in autograd,nn,utils and tensor These four main parts , among autograd Mainly automatic differentiation , Back propagation , But unlike static graphs , First of all graph Search on operation(session), Combined with the optimizer, the gradient of back propagation is calculated ,nn The main ones are functional and modules,modules About... Will be defined in Module The container of , It allows you to build in different ways model, such as sequential The way , stay functional It's about modules in class Function form of , Of course, the definition is class We must realize forward and backward Method , Both are calculated automatically in automatic differentiation ,tensor It is the carrier of all data entering the framework , It can work with numpy Switch directly , The default is not to calculate the gradient ,utils Time is mainly to define data The iterator , Iterators include dataset and dataloader Two kinds of .
Tensor The definition of ,tensor It's the carrier of data , It is the core data structure in deep learning , The core is backward attribute ,tensor The definition itself is quite complicated , There are relatively many attributes .
import numpy as np
from typing import Type
from .nn import Add, Subtract, Multiply, Divide, Power, Positive, Negative, MatMul, SwapAxes
from .autograd import Autograd
class Tensor(object):
def __init__(self, data: np.array, requires_grad=False):
self.data = data
self.requires_grad = requires_grad
self.grad = None
if requires_grad:
self.grad = np.zeros_like(self.data, dtype=np.float32)
self.backward_function = None
self.backward_tensor = []
self.shape = self.data.shape
def backward(self, grad=np.array([1])):
if self.requires_grad:
self.grad = grad + self.grad
sum_ax = tuple(range(len(self.grad.shape) - len(self.data.shape)))
self.grad = np.sum(self.grad, sum_ax)
if self.backward_function is not None:
accumulated = self.backward_function(grad)
if len(self.backward_tensor) == 1:
accumulated = accumulated,
for bv, ac in zip(self.backward_tensor, accumulated):
bv.backward(ac)
@classmethod
def _op(cls, Op: Type[Autograd], *input_vars):
f = Op()
return f(*input_vars)
def __str__(self):
return "<Tensor>\n" + self.data.__str__()
def __add__(self, other):
from .nn import Add
return self._op(Add, self, other)
def __radd__(self, other):
return self._op(Add, other, self)
def __sub__(self, other):
return self._op(Subtract, self, other)
def __rsub__(self, other):
return self._op(Subtract, other, self)
def __matmul__(self, other):
return self._op(MatMul, self, other)
def __rmatmul__(self, other):
return self._op(MatMul, other, self)
def __mul__(self, other):
return self._op(Multiply, self, other)
def __rmul__(self, other):
return self._op(Multiply, other, self)
def __copy__(self):
""" Copy the current Tensor Of grad,data,requires_grad, If the current Tensor There is no gradient , The gradient of None
:return:
"""
copy = Tensor(np.copy(self.data), requires_grad=self.requires_grad)
try:
copy.grad[:] = self.grad[:]
except:
pass
return copy
def copy(self):
return self.__copy__()
def numpy(self):
return self.data.copy()
def __len__(self):
return len(self.data)
@property
def size(self):
return self.data.size
@property
def ndim(self):
return self.data.ndim
@property
def shape(self):
return self.data.shape
@property
def T(self):
pass
def swapaxes(self, axis1, axis2):
return SwapAxes(axis1, axis2)(self)
nn modular , stay similartorch There are mainly two parts in the book , The first part is modules modular , The second part is functional, That's right modules The classes inside are encapsulated in functions . stay modules It includes activation, Containers sequential,conv,flatten,img2col,init,linear,loss,pooling And base classes Modules,similartorch.ones Equal basic functions and add,matmul This basic operator .
mathematical: Some commonly used calculation functions are defined , such as add,mul These commonly used , Inherited from Autograd, In fact, we can do it again operation Class inheritance autograd Of , Realized forward and backward Method . Actually numpy There are also these methods , But after the framework definition is used again , Write again backward After method , You can use repackaging when reconfiguring the model backward The framework defines the method , In back propagation , You can link to math The derivative of the method , The words written in this way are similar tf1 Decoupling the depth of the operator layer , You can piece together the functions you want , It can also be in nn Define the desired function in , direct writing backward Method , In this case, the granularity of the operator is coarser , Not particularly flexible .
import numpy as np
from similartorch.autograd import Autograd
class Add(Autograd):
def forward(self, ctx, x, y):
return x + y
def backward(self, ctx, grad):
return grad, grad
class Subtract(Autograd):
def forward(self, ctx, x, y):
return x - y
def backward(self, ctx, grad):
return grad, -grad
class MatMul(Autograd):
def forward(self, ctx, x, y):
ctx.save_for_back(x, y)
return x @ y
def backward(self, ctx, grad: np.array):
t1, t2 = ctx.data_for_back
grad1 = grad @ np.swapaxes(t2, -1, -2)
grad2 = np.swapaxes(t1, -1, -2) @ grad
return grad1, grad2
class Multiply(Autograd):
def forward(self, ctx, x, y):
ctx.save_for_back(x, y)
return x * y
def backward(self, ctx, grad: np.array):
t1, t2 = ctx.data_for_back
return grad * t2, grad * t1
class Assign(Autograd):
def forward(self, ctx, x):
return x
def backward(self, ctx, grad):
return None
class Divide(Autograd):
def forward(self, ctx, x, y):
ctx.save_for_back(x, y)
return x / y
def backward(self, ctx, grad):
t1, t2 = ctx.data_for_back
grad1 = grad / t2
grad2 = -grad1 * (t1 / t2)
return grad1, grad2
class Negative(Autograd):
def forward(self, ctx, x):
return -x
def backward(self, ctx, grad):
return -grad
class Positive(Autograd):
def forward(self, ctx, x):
return np.positive(x)
def backward(self, ctx, grad):
return np.positive(grad)
class Power(Autograd):
def forward(self, ctx, x, y):
ctx.save_for_back(x, y)
return x ** y
def backward(self, ctx, grad):
t1, t2 = ctx.data_for_back
grad1 = grad * t2 * (t1 ** np.where(t2, (t2 - 1), 1))
grad2 = grad * (t1 ** t2) * np.log(np.where(t1, t1, 1))
return grad1, grad2
# --------------------------------------------------------------------------------
class Exp(Autograd):
def forward(self, ctx, x):
ctx.save_for_back(x)
return np.exp(x)
def backward(self, ctx, grad):
t1, _ = ctx.data_for_back
return grad * np.exp(t1)
class Log(Autograd):
def forward(self, ctx, x):
return np.log(x)
def backward(self, ctx, grad):
t1, _ = ctx.data_for_back
return grad / t1
activation: The definitions of classes and functions are the same as those above mathematical Somewhat different ,mathematical Most of the methods provided are still tensor Methods , All the data in the framework is Tensor, Therefore, the attribute method can be used directly ,activation and module neutralization functional The method in is corresponding to , stay pytorch in functional Functions in are provided to classes to do forward Methods , But in similartorch It mainly implements forward Method ,functional Itself is just an instantiation of a class method .
import numpy as np
from similartorch.autograd import Autograd
class ReLU(Autograd):
def forward(self, ctx, x):
ctx.save_for_back(x)
return np.clip(x, a_min=0, a_max=None)
def backward(self, ctx, grad):
t, = ctx.data_for_back
return np.where(t < 0, 0, grad)
class Sigmoid(Autograd):
def forward(self, ctx, x):
sig = 1 / (1 + np.exp(-x))
ctx.save_for_back(sig)
return sig
def backward(self, ctx, grad):
sig, = ctx.data_for_back
return sig * (1 - sig) * grad
class Softmax(Autograd):
def forward(self, ctx, x):
softm = np.exp(x) / np.sum(np.exp(x), axis=-1, keepdims=True)
ctx.save_for_back(softm)
return softm
def backward(self, ctx, grad):
softm, = ctx.data_for_back
return grad * softm * (1 - softm)
class Softplus(Autograd):
def forward(self, ctx, x):
ctx.save_for_back(1 + np.exp(-x))
return np.log(1 + np.exp(-x))
def backward(self, ctx, grad):
softp, = ctx.data_for_back
return grad / softp
class Softsign(Autograd):
def forward(self, ctx, x):
ctx.save_for_back(1 + np.abs(x))
return x / (1 + np.abs(x))
def backward(self, ctx, grad):
softs, = ctx.data_for_back
return grad / softs
class ArcTan(Autograd):
def forward(self, ctx, x):
ctx.save_for_back(x)
return np.arctan(x)
def backward(self, ctx, grad):
t, = ctx.data_for_back
return grad / (t * t + 1)
class Tanh(Autograd):
def forward(self, ctx, x):
tanh = np.tanh(x)
ctx.save_for_back(tanh)
return tanh
def backward(self, ctx, grad):
tanh, = ctx.data_for_back
return (1 - tanh * tanh) * grad
loss modular
import numpy as np
from similartorch.autograd import Autograd
class MSELoss(Autograd):
def forward(self, ctx, target, input):
if target.shape != input.shape:
raise ValueError("wrong shape")
ctx.save_for_back(target, input)
return ((target - input) ** 2).mean()
def backward(self, ctx, grad):
target, input = ctx.data_for_back
batch = target.shape[0]
grad1 = grad * 2 * (target - input) / batch
grad2 = grad * 2 * (input - target) / batch
return grad1, grad2
class CrossEntropyLoss(Autograd):
def forward(self, ctx, target, input):
ctx.save_for_back(target, input)
input = np.clip(input, 1e-15, 1 - 1e-15)
return -target * np.log(input) - (1 - target) * np.log(1 - input)
def backward(self, ctx, grad):
target, input = ctx.data_for_back
batch = target.shape[0]
input = np.clip(input, 1e-15, 1 - 1e-15)
grad1 = grad * (np.log(1 - input) - np.log(input)) / batch
grad2 = grad * (- target / input + (1 - target) / (1 - input)) / batch
return grad1, grad2
pooling modular ,pooling This piece of backward It's simple ,maxpool Words , Just use mask remember max The largest position ,average If so, it is sufficient to assign the average value to all of them .
import numpy as np
from abc import ABC
from similartorch.autograd import Autograd, Context
from .img2col import Img2Col
class BasePool(Autograd, ABC):
def __init__(self, kernel_size, stride=1):
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
if isinstance(stride, int):
stride = (stride, stride)
self.kernel_size = kernel_size
self.stride = stride
@staticmethod
def _fill_col(to_fill, new_shape):
repeats = new_shape[-2]
ret = np.repeat(to_fill, repeats, -2)
ret = np.reshape(ret, new_shape)
return ret
class MaxPool2d(BasePool):
def forward(self, ctx: Context, input):
img_w = input.shape[-1]
img_h = input.shape[-2]
channels = input.shape[-3]
new_w = (img_w - self.kernel_size[0]) // self.stride[0] + 1
new_h = (img_h - self.kernel_size[1]) // self.stride[1] + 1
img_out = Img2Col.img2col_forward(self.kernel_size, self.stride, False, input)
maxed = np.max(img_out, -2)
ctx.save_for_back(img_out, input.shape, maxed.shape)
return np.reshape(maxed, (-1, channels, new_h, new_w))
def backward(self, ctx: Context, grad: np.array = None):
""" Cut into small pieces max, After the calculation, put shape Turn back
"""
reshaped_image, back_shape, maxed_shape = ctx.data_for_back
grad = np.reshape(grad, maxed_shape)
mask = (reshaped_image == np.max(reshaped_image, -2, keepdims=True))
new_grad = self._fill_col(grad, reshaped_image.shape)
new_grad = np.where(mask, new_grad, 0)
return Img2Col.img2col_backward(self.kernel_size, self.stride, back_shape, new_grad)
class AvgPool2d(BasePool):
def forward(self, ctx: Context, input):
img_w = input.shape[-1]
img_h = input.shape[-2]
channels = input.shape[-3]
new_w = (img_w - self.kernel_size[0]) // self.stride[0] + 1
new_h = (img_h - self.kernel_size[1]) // self.stride[1] + 1
img_out = Img2Col.img2col_forward(self.kernel_size, self.stride, False, input)
averaged = np.average(img_out, -2)
ctx.save_for_back(img_out, input.shape, averaged.shape)
return np.reshape(averaged, (-1, channels, new_h, new_w))
def backward(self, ctx, grad):
reshaped_image, back_shape, averaged_shape = ctx.data_for_back
grad = np.reshape(grad, averaged_shape)
new_grad = self._fill_col(grad, reshaped_image.shape) / (self.kernel_size[0] * self.kernel_size[1])
return Img2Col.img2col_backward(self.kernel_size, self.stride, back_shape, new_grad)
conv Layer and its inherited base class module,module No, backward Method , Inherited from module Of linear,sequential,conv None backward Method , These are actually higher order operators , Back propagation can often be spelled out by lower order operators , Therefore, for these operations, no backward In the form of .
import math
import numpy as np
import similartorch
from similartorch import Tensor
from .img2col import Img2Col
from .module import Module
from . import init
class Conv2d(Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding=0, add_bias=True):
super(Conv2d, self).__init__()
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
if isinstance(stride, int):
stride = (stride, stride)
if isinstance(padding, int):
padding = (padding, padding)
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.add_bias = add_bias
self.weight = similartorch.rands([0, 0.05, (self.out_channels, self.in_channels,
self.kernel_size[0], self.kernel_size[1])], requires_grad=True)
if add_bias:
self.bias = similartorch.zeros(out_channels, np.float32, requires_grad=True)
self.register_parameter(("weight", self.weight), ("bias", self.bias))
else:
self.register_parameter(("weight", self.weight))
self.img2col = Img2Col(self.kernel_size, self.stride)
def reset_parameters(self):
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
def forward(self, input: Tensor) -> Tensor:
img2col = self.img2col(input)
output = self.weight.reshape(self.weight.shape[0], -1) @ img2col
img_w = input.shape[-1]
img_h = input.shape[-2]
new_w = (img_w - self.kernel_size[0]) // self.stride[0] + 1
new_h = (img_h - self.kernel_size[1]) // self.stride[1] + 1
batch_input = len(input.shape) == 4
if batch_input:
output_shape = (input.shape[0], self.out_channels, new_h, new_w)
else:
output_shape = (self.out_channels, new_h, new_w)
if self.add_bias:
output = (output.swapaxes(-1, 2) + self.bias).swapaxes(-1, -2)
return output.reshape(*output_shape)
import numpy as np
from abc import ABC, abstractmethod
from collections import OrderedDict
from similartorch.tensor import Tensor
class Module(ABC):
def __init__(self):
self._parameters = OrderedDict([])
def register_parameter(self, *var_iterable):
for var_name, var in var_iterable:
self._parameters.update({var_name: var})
def parameters(self) -> list:
return list(self._parameters.values())
def get_state_dict(self) -> OrderedDict:
return self._parameters
def load_state_dict(self, state_dict: OrderedDict):
for k, val in state_dict.items():
self._parameters[k].data = np.array(val)
@abstractmethod
def forward(self, *input) -> Tensor:
raise NotImplementedError
def __call__(self, *input) -> Tensor:
return self.forward(*input)
autograd Automatic differentiation module
from abc import ABC, abstractmethod
from similartorch.tensor import Tensor
class Context:
def __init__(self):
self.data_for_back = None
def save_for_back(self, *data):
self.data_for_back = tuple(data)
class Autograd(ABC):
def apply(self, *tensor_list):
ctx = Context()
forward_tensor = self.forward(ctx, *map(lambda v: v.data, tensor_list))
output_tensor = Tensor(forward_tensor, requires_grad=False)
output_tensor.backward_function = lambda x: self.backward(ctx, x)
output_tensor.backward_tensor = list(tensor_list)
return output_tensor
@abstractmethod
def forward(self, ctx, *tensor_list):
raise NotImplementedError
@abstractmethod
def backward(self, ctx, grad):
raise NotImplementedError
def __call__(self, *tensor_list):
return self.apply(*tensor_list)
Optimizer module
from abc import ABC, abstractmethod
class Optimizer(ABC):
def __init__(self, param_list: list):
self.param_list = param_list
self.state = {}
def zero_grad(self):
for param in self.param_list:
param.grad.fill(0)
@abstractmethod
def step(self):
raise NotImplementedError
import numpy as np
from .optimizer import Optimizer
class Adam(Optimizer):
def __init__(self, param_list: list, learning_rate=0.01, beta1=0.9, beta2=0.999, epsilon=1e-8):
super(Adam, self).__init__(param_list)
self.lr = learning_rate
self.beta1 = beta1
self.beta2 = beta2
self.eps = epsilon
@staticmethod
def initialize_state(state, param):
state["step"] = 0
state["m"] = np.zeros(param.grad.shape)
state["v"] = np.zeros(param.grad.shape)
def step(self):
for param in self.param_list:
if param.grad is None:
continue
if param not in self.state:
self.state[param] = {}
state = self.state[param]
if len(state) == 0:
self.initialize_state(state, param)
state["step"] += 1
state["m"] = self.beta1 * state["m"] + (1 - self.beta1) * param.grad
state["v"] = self.beta2 * state["v"] + (1 - self.beta2) * param.grad
m_hat = state["m"] / (1 - self.beta1 ** state["step"])
v_hat = state["v"] / (1 - self.beta2 ** state["step"])
param.data -= self.lr * m_hat / (np.sqrt(v_hat) + self.eps)
import numpy as np
from .optimizer import Optimizer
class SGD(Optimizer):
def __init__(self, param_list: list, learning_rate=0.01, momentum=0., decay=0.):
super(SGD, self).__init__(param_list)
self.lr = learning_rate
self.decay = decay
self.momentum = momentum
@staticmethod
def initialize_state(state, param):
state["v"] = np.zeros_like(param.grad)
def step(self):
for param in self.param_list:
if param.grad is None:
continue
if param not in self.state:
self.state[param] = {}
state = self.state[param]
if len(state) == 0:
self.initialize_state(state, param)
state["v"] = self.momentum * state["v"] - self.lr * param.grad
param.data += state["v"]
self.lr = self.lr / (1 + self.decay)
utils The module mainly writes some functions for data loading ,dataset and dataloader modular ,dataloader The main thing is to realize __iter__ and __next__ iterator , Some specific data loading classes include MNIST etc. .
Look at the big picture , Make a class torch Deep learning framework , pure numpy Realization , Automatic differentiation module autograd, Defines the core forward and backward, It's an abstract base class , It mainly defines the interface ,backward adopt backward_function To achieve , This layer is actually through the operator backward Method to implement , Operators are mostly inherited from Autograd, All of them are implemented forward and backward Method , The second is modules modular , stay nn in , These are the functions and classes needed to build the model ,optim It's the optimizer ,utils Is the method of data loading .
边栏推荐
- 实战 | 巧用位姿解算实现单目相机测距
- 深度学习的多个 loss 是如何平衡的?
- 创新实训(十一)开发过程中的一些bug汇总
- NVIDIA Jetson Nano Developer Kit 入门
- hudi 键的生成(Key Generation)
- Pytoch official fast r-cnn source code analysis (I) -- feature extraction
- unittest框架
- Help you with everything from the basics to the source code. Introduce the technology in detail
- 【云原生 | Kubernetes篇】Kubernetes 网络策略(NetworkPolicy)
- Introduction to application design scheme of intelligent garbage can voice chip, wt588f02b-8s
猜你喜欢

torch_ About the geometric Mini batch

IC chip scheme fs4062b for lithium battery charging with 5V boost to 12.6V

Openstack network

442个作者100页论文!谷歌耗时2年发布大模型新基准BIG-Bench | 开源

【刷题篇】超级洗衣机

There was an error installing mysql. Follow the link below to CMD
![Will the next star of PPT for workplace speech be you [perfect summary] at the moment](/img/11/ac67db2641f42ef3d09417b790feb8.png)
Will the next star of PPT for workplace speech be you [perfect summary] at the moment

嵌入式系统概述3-嵌入式系统的开发流程和学习基础、方法
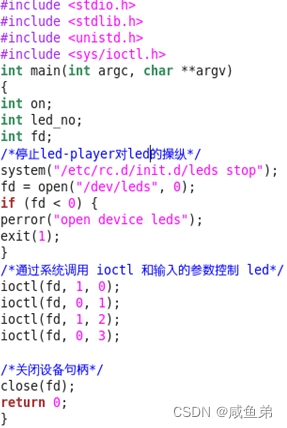
Embedded driver design
![Mui login database improvement and Ajax asynchronous processing [mui+flask+mongodb+hbuilderx]](/img/11/ce929f1cfbdcf245db9ee53bfe7a84.png)
Mui login database improvement and Ajax asynchronous processing [mui+flask+mongodb+hbuilderx]
随机推荐
大一女生废话编程爆火!懂不懂编程的看完都拴Q了
创新实训(十)高级界面美化
Eight misunderstandings are broken one by one (2): poor performance? Fewer applications? You worry a lot about the cloud!
R language Visual facet chart, hypothesis test, multivariable grouping t-test, visual multivariable grouping faceting bar plot, adding significance level and jitter points
嵌入式系统概述2-嵌入式系统组成和应用
Build an embedded system software development environment - build a cross compilation environment
Realization of Joseph Ring with one-way ring linked list
import torch_geometric 的Data 查看
Redis message queue repeated consumption
leetcode 47. Permutations II full permutations II (medium)
Openmax (OMX) framework
A brief introduction to Verilog mode
微信web开发者工具使用教程,web开发问题
嵌入式系统概述3-嵌入式系统的开发流程和学习基础、方法
Hardware composition of embedded system - introduction of embedded development board based on ARM
leetcode 47. Permutations II 全排列 II(中等)
嵌入式系統硬件構成-基於ARM的嵌入式開發板介紹
B站分布式KV存储混沌工程实践
【VIM】. Vimrc configuration, vundle and youcompleteme have been installed
[brush title] probability of winning a draw