当前位置:网站首页>A brief history of neural network
A brief history of neural network
2022-06-11 01:48:00 【Captain xiaoyifeng】
I learned notes for two days , Muddle through , Please don't correct me ( you 're right I will study further in the future Now let's get a rough idea of )
neural network , It can be regarded as a black box that can fit any function , The following is a very brief history of neural networks and some knowledge points .
Main reference :https://blog.csdn.net/ibelieve8013/article/details/88323271
https://blog.csdn.net/zhaojc1995/article/details/80572098
https://www.zhihu.com/question/34681168/answer/84061846
https://zhuanlan.zhihu.com/p/49271699
https://blog.csdn.net/weixin_42111770/article/details/84338768
https://blog.csdn.net/stdcoutzyx/article/details/53151038
perceptron
The 1950s and 1960s ( Imagine the computer at that time ) The resulting perceptron is the rudiment of a neural network , Have an input layer , An output layer , A hidden layer ( Middle layer ), Used to classify 、 Fitting, etc .
But I found that this encountered some complex functions ( Piecewise functions ) When , Basically no effect .
Multilayer perceptron
At this time, multi-layer perceptron appeared , Is to increase the number of hidden layers , use sigmoid or tanh The equal continuous function simulates the response of neurons to excitation ( Increase discrete response , Increase nonlinearity ), Back propagation is used in the training algorithm BP Algorithm . And the big guys found , The more the number of , The more complex functions can be fitted .
At this time, multiple perceptron is also called neural network ,NN(neural network).
however , They also found that as the number of layers increased , Because the gradient disappears , On the contrary, it is easy to fall into the local optimal solution , A model with fewer layers is better than a model with more layers .
The gradient disappears
Because of the adoption of BP Algorithm back propagation , The effect of error propagation is decreasing layer by layer , However, the degree of changing parameters in the gradient descent method is positively related to the gradient , So when there are many layers , Parameter changes are difficult to affect the parameters of the previous layers .
An unscientific example is the modification and calculation of parameters n Second order compound derivative ,n The smaller it is , The more obvious the influence between the front and rear parameters .n Too big , Causes the gradient to disappear ( such as 0.1 Five times ) Or an explosion ( such as 1.2 Five times ).
DNN(Deep Neural Network)
In about 2006 In the year , The method of pre training extends the neural network to 6、7 layer , From then on, a wave of in-depth learning has started .
ReLU Wait for the transfer function to replace sigmoid, It overcomes the problem of gradient vanishing , Formed today DNN The basic form of .
Preliminary training
Now pre training usually refers to training a large number of general samples to get the model , After the pre training, the model can be transferred and trained to obtain higher accuracy .
For example, Google pre training inception Model , Hidden layer can extract image features better , I can transfer and train into binary classifiers of apples and pears .
The pre training mentioned above is Layer by layer greedy pre training , That is, every layer of training , Fix the layer parameters , Then add another layer , Train for a new level .
Relu advantage
Use sigmoid tanh When making the activation function , Large amount of computation , When calculating the error gradient by back propagation , The amount of derivation calculation is also very large .
sigmoid tanh Functions tend to saturate , The gradient disappears , That is, when it approaches convergence , Too slow to change , Cause information loss .
Relu It will make some neurons output 0, Cause sparsity , It not only alleviates over fitting , It is also closer to the real neuron activation model .
Narrow the gap between pre training and pre training
Disadvantages of full connection
Especially in the face of deep learning of images , Fully connected neural networks have many disadvantages
First of all, there is a large amount of calculation , If each pixel is used as the node of the input layer , Then a hidden layer has many nodes , Many edges can be generated , This caused the Expansion of parameters .
Then full connection can easily lead to Over fitting , That is, the local features of some samples are transformed into global features .
Regularization
Regularization is a method to reduce over fitting .
There are four main regularization methods in neural networks :
1. Stop early (eary stopping): For example, we can set the maximum number of rounds of training
2. Weight falloff : Reduce the weight of useless edges
3.droupout: Delete some node units during each training , This will make the network structure simple , The training process has also become simpler . Its definition is if you delete a layer during the training phase p% node , Then the weight of neurons in this layer should also be attenuated during training p%.
4. Network structure : such as CNN
CNN
Convolution neural network is characterized by the introduction of convolution layer (…) Through convolution kernel and the connection between each layer , By determining the number of convolution kernels , Then convolute layer by layer , Achieve the function of feature extraction .
In this case , The number of nodes is only related to the number of convolution layers and convolution kernels , It greatly reduces the amount of calculation .
CNN And pooling (pooling layer ) To integrate features ( The data gets smaller ), Eliminate useless features , Reduce the amount of calculation .
CNN It plays an important role in image processing and speech recognition .
RNN
DNN Another drawback is that time series cannot be recognized , At this time, a cyclic neural network appears (Recurrent Neural Network,RNN)
In fully connected neural networks and CNN in , The influence between layers can only be transferred from the current layer to the next layer , So they are also called Feedforward neural networks (feedforward neural network,FNN)
RNN Hidden layer in , Each layer node can be connected to itself , That is, the weight depends on the current moment t The input of also depends on the previous moment t-1 The input of ( Does it look like a Markov chain ).
Because there is a time relationship between the words of a language , Context .
And for example CNN in , Input of different pictures , There is no mutual influence on their output , But its parallel operation runs very fast .
( Of course, context can also be affected by the following input , So there are two ways RNN And neural networks )
From a timeline perspective , Over time , It seems that the gradient will disappear , But on the whole , Context has a great influence on the similarity .
But in order to eliminate the problem of gradient descent , Long - and short-term memory units have emerged LSTM, The time memory function is realized through the switch of the door , And prevent the gradient from disappearing .
seq2seq
namely Sequence to Sequence, This is a RNN The most important variant , Because general neural networks are single input single output , The translation of sentences may be multiple input and single output , Single input multiple output and other forms , We also don't know which node should output , Which node should not output , So we used it seq2seq Model . This is a kind of Encoder-Decoder Model

It's the one on the left RNN Code formation c,c Through... On the right RNN Decode to form output .
BPTT
BPTT(back-propagation through time) It's for training RNN The algorithm of , This is along the time version BP Algorithm
So refer to the previous , This will also cause the gradient to disappear .
LSTM
LSTM(long short-term memory) Using the idea of door , It is about creating a new parameter c,c Determine the state of the cell , adopt softmax( Approximation can be achieved without 0 namely 1) Gate circuit composed of , Decide whether to report cell status , Do you want to add the newly read data to the cell state .
Write here , The timeline is starting to mess up .
I will probably start from NLP And image recognition ( object detection ) Talk about the latest knowledge .
NLP
transformer,bert、gpt
NLP Common tasks
One is sequence annotation , This is the most typical NLP Mission , For example, Chinese word segmentation , Part of speech tagging , Named entity recognition , Semantic role tagging can be classified into this kind of problems , Its characteristic is that each word in the sentence requires the model to give a classification category according to the context .
The second category is classification tasks , For example, our common text classification , Emotional computing and so on can fall into this category . Its characteristic is that no matter how long the article is , Give a general classification .
The third type of task is sentence relation judgment , such as Entailment,QA, Semantic rewriting , Natural language reasoning and other tasks are based on this model , It is characterized by giving two sentences , The model judges whether two sentences have some semantic relationship .
The fourth type is generative tasks , For example, machine translation , Text in this paper, , Write poems and sentences , Looking at pictures, talking, etc. all belong to this category . Its feature is that after entering the text content , You need to generate another paragraph of text by yourself .
Word Embedding
The word vector , Use a vector to express the probability that a word will appear after this sentence , This is a tool for predicting words . The early ones were used to generate Word Embedding There are NNLM, at that time NNLM Just want to get the predicted results , and word Embedding It's a by-product , Then there was Word2Vec, And then there was Glove, Specially generated Word Embedding.
This generated vector has a drawback , Just can't handle polysemy well . The main reason is that the sample takes two words before and after the training .( I don't know , Casually )
CBOW
Word2Vec There is a training method , It's called CBOW, Is to deduct a word from a sentence , Then predict the value
ELMO
ELMO It brings a concise approach to the defect of polysemous words , Is to get the meaning of the word to be output through the context semantics , Adjust it dynamically Word Embedding A weight
In fact, it uses two-way LSTM
ELMO A typical two-stage process , The first stage is to use language model for pre training ; The second stage is in the downstream task , From the pre training network, extract the corresponding words of each layer of the network Word Embedding As a new feature added to the downstream mission .
LSTM And then be transformer Beat , therefore ELMO Not very hot
transformer and Attention Model
Here's the point , Attention mechanism is the concept of comparative fire .
transformer yes Google The given feature extractor , At this time, it's time to return to the main line that was broken in the front .
Again Encoder-Decoder
Understand it in the words of zhangjunlin :Encoder-Decoder It's an innovative game killer , On the one hand, as mentioned above , You can make different model combinations , On the other hand, it has many application scenarios , For example, for machine translation ,<X,Y> It is a sentence corresponding to different languages , such as X It's an English sentence ,Y Is the corresponding Chinese sentence translation . Another example is the text summary ,X It's an article ,Y Is the corresponding summary ; Another example is the dialogue robot ,X Is someone's words ,Y It is the response of the dialogue robot ; Another example …… All in all , That's too much
Attention Model
Then there is the attention mechanism , From the perspective of psychology and Neuroscience , When human beings face a picture , First, look at the whole thing , Then determine the focus of attention , To suppress other places . Personal understanding is a word apple Translate it into apple in a long sentence , More sentences are determined by other words , Or does it decide ,attention model The alignment between input and target is achieved , It points out that apple Apple is decisive . In the previous model , The influence of context on the word itself is possible . above seq2seq Is equivalent to the distraction model .
So this is the introduction attention model Of Encoder-Decoder Sketch Map 
How to generate the distribution of attention , It can be explained in the figure below 
Is through a function F, From each input word h j h_j hj And the previous output
State of H i − 1 H_{i-1} Hi−1 Calculate each word and Y i Y_i Yi Probability of alignment between .
advantage
transformer both rnn Parallel computing advantages not available , And then there is cnn( stay NLP Not commonly used ) The advantage of capturing long-distance features .
GPT
gpt It is used. transformer A one-way network . then GPT If you want to transform downstream tasks , It needs to be transformed according to the method shown in the figure , Make the input conform to the structure .
Dig a hole , Learn first bert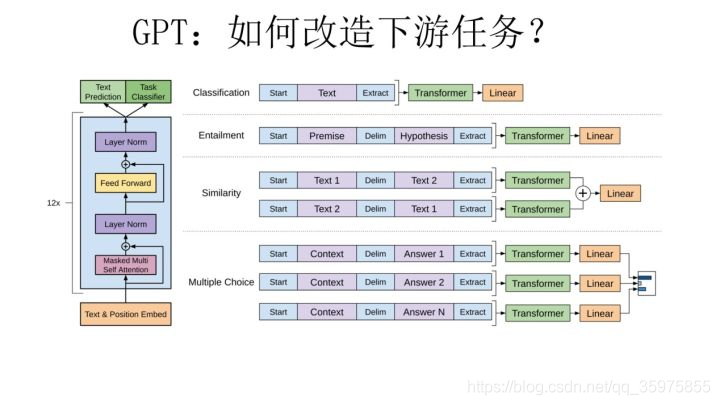
bert
bert Two stages are also used , and GPT The biggest difference is that it is bidirectional .
The training method is two-way , But not in the forward and reverse directions transformer, Instead, it adopted CBOW, Dig up words and fill in the blanks .
CV
Convolutional neural networks AlexNet、ZF Net、VGGNet、Inception、ResNet
object detection RCNN,Fast RCNN,Faster RCNN,YOLO,SSD
CNN
Gradually began to understand , Start copying
LeNet-5
One of the earliest CNN One of , Have a convolution layer 、 Pooling layer 、 Fully connected layer
AlexNet
LeNet-5 Applied to handwritten digits after birth , But the accuracy rate is not high because of the artificial local characteristics .2012 year ,AlexNet stay ImageNet Won the championship in the image classification task competition , Set the Thames a great coup , Since then, it has created an unprecedented climax of deep neural network .
AlexNet Advantage lies in :
The nonlinear activation function is used ReLU
Put forward LRN(Local Response Normalization), Local response normalization ,LRN It is generally used after activating and pooling functions , Create a competitive mechanism for the activity of local neurons , Make the response relatively large and the pair value relatively larger , And inhibit other neurons with smaller feedback , It enhances the generalization ability of the model
Use CUDA Training of accelerated depth neural convolution network , utilize GPU Powerful parallel computing power , When dealing with neural network training, a lot of matrix operations
stay CNN Maximum pooling using overlap in ,AlexNet All use maximum pooling , Avoid the blurring effect of average pooling .AlexNet The step size is smaller than that of the pool core , In this way, there will be overlap and coverage between the outputs of the pooling layer , Enhance the richness of features .
Increase the use of data (data agumentation) and Dropout Prevent over fitting .
【 Data augmentation 】 Randomly from 256 256 In the original image 224 224 Size area , It's equivalent to an increase in 2048 Times the amount of data ;
【Dropout】AlexNet Use in the next three fully connected layers Dropout, Ignore some neurons at random , To avoid over fitting the model .
ZF Net
Propose deconvolution , Visual convolution operation
VGG Net
Feature extraction using stacked small convolution kernel
inception
The most direct way to improve the performance of deep neural networks is to increase their size , Not just depth ( Network layers ), It also includes its width , That is, the number of units in each layer . But this simple and direct solution has two major drawbacks , Larger networks mean more parameters , It makes the network easier to over fit , It will also lead to the increase of computing resources . After much consideration , Considering that clustering sparse matrices into relatively dense subspaces tends to optimize sparse matrices , Therefore, it is proposed that inception structure .
inception The idea is to use convolution kernels of different sizes .
v2 Put forward Batch Normalization, Project data onto (0,1), And normal distribution , Faster convergence ; Remove Dropout and LRN; Speed up learning
v3 Put forward Factorization into small convolutions Thought , Split the larger two-dimensional convolution into two smaller one-dimensional convolutions
v4 Integrated ResNet
ResNet
Deep residual network , By building a system that can skip one or more layers “shortcut connection”, To reduce network degradation after deepening ( Because of over fitting ) The phenomenon of 
object detection
IoU
detection result (detection result) And the real value (Ground Truth) Their union on the intersection of
NMS
Non maximum suppression NMS(Non-maximum suppression) Used to remove some boxes , When many boxes overlap, select the one with higher scores .

fine-tuning
fine-tuning , Because the data set is not big enough , adopt retrain Existing models , Use existing models as feature extractors , To create a new model .
crop and warp
crop It is cut directly according to the size ,warp Is to scale after cropping .
You can see crop/warp This kind of pretreatment will make the object either incomplete or distorted , Obviously, it will affect the recognition accuracy
Region of interest(RoI) pooling layer
Principle dig a pit
RoI It is widely used in target detection , It is mainly used to maximize the pool size of irregular input (max pooling) Convert to a fixed size feature map .
RCNN
RCNN Use a single image Selective Search Extract multiple regions to identify
For image zooming ,RCNN use warp
Selective Search
Is to merge the algorithm by level (Hierarchical Grouping), First use the paper “Efficient Graph-Based Image Segmentation” The method in generates some initial small areas , Then the greedy algorithm is used to merge the regions together : First, calculate the similarity between all adjacent regions ( By color , texture , Coincidence , Size and other similarity ), Merge the two most similar regions , Then recalculate the similarity between adjacent regions , Merge similar regions until the whole image becomes a region
fast RCNN
The whole convolution is used first , Reuse Selective Search The segmented part is mapped to the feature layer , To achieve the purpose of segmentation feature extraction
Then the image scaling is used SPP Algorithm
SPP
Space Pyramid pooling SPP(Spatial Pyramid Pooling), It can output pictures of different sizes in the same size .
Faster RCNN
Cancel Selective Search Division , use RPNs Division , More efficient , Simultaneous introduction anchor box
RPNs
Area generation network Region Proposal Networks(RPNs)
1) Determine whether the object or the background , In this paper, non maximum suppression is used (nms) Methods , Set up IoU by 0.7 The threshold of , That is, only the coverage rate does not exceed 0.7 Of the local maximum fraction of box( A coarse sieve ). Finally, about 2000 individual anchor, And then before you take it N individual box( such as 300 individual ) to Fast-RCNN. My understanding is that IOU( Intersection and union ratio with truth value )>0.7 For objects , It is a positive sample ,IOU<0.3 In the background , It is a negative sample . In the paper RPN When training online , Only the above two categories are used , With the truth box IoU Be situated between 0.3 and 0.7 Of anchor Not used .
2) Coordinate correction , The regression problem , That is to find the original anchor Mapping to the truth box , This can be achieved by panning and zooming , When anchor Close to the truth box , It is considered that this transformation is a linear transformation , You can use a linear regression model to fine tune . After getting each candidate region anchor After modifying the parameters , We can calculate the exact anchor, And then according to the object's area score from big to small pairs get anchor Sort , Then bring up something very small in width or height anchor( Get other filter conditions ), And then through non maximum suppression , Take before Top-N Of anchors, And then as a proposals( Candidate box ) Output , Send to RoI Pooling layer .
Reference resources :https://zhuanlan.zhihu.com/p/138515680
YOLO
Dig a hole dig a hole
YOLO The core idea is to use the whole graph as the input of the network , Return directly to the output layer bounding box The location and bounding box Category .
Every grid should predict B individual bounding box, Every bounding box In addition to going back to where you are , And with a prediction confidence value . This confidence Represents the predicted box contains object And this box How accurate and dual information is predicted , The value is calculated as follows : If there is object Fall on one grid cell in , The first one is 1, Otherwise take 0. The second is the prediction bounding box And the actual groundtruth Between IoU value .
Every bounding box To predict (x, y, w, h)( Position, length and width ) and confidence common 5 It's worth , Each grid also predicts a category information , Write it down as C class . be SxS Grid (s) , Every grid should predict B individual bounding box And predict C individual categories. Output is S x S x (5*B+C) One of the tensor.
YOLO It's using end-to-end Training , That is, end-to-end learning , One end is picture input , At one end is the output of box size, position and object category , This is a whole network .
Although each lattice can be predicted B individual bounding box, But when training , We just want one of every kind of object bounding box, So I choose and ground truth Of IoU The highest value bounding box As object detection output , That is, each grid can only predict one object at most , So if the grid contains multiple objects , Only one can be detected . This is also YOLO A disadvantage of .
SSD
Than faster rcnn fast Than YOLO accurate
Dig a hole , Reinforcement learning .
Dig a hole , Against generative networks .
GAN
Countermeasure generation network or generative countermeasure network (Generative Adversarial Net,GAN). This is very interesting , The process of a game between the network that generates data and the network that judges data .
Many of the models given before are Discriminative Model, It's discrimination 、 distinguish 、 The process of fitting , and GAN yes Generative Model, It's from scratch , Such as removing mosaics , Generate a new picture , Migration style, etc .
A person , He can see , listen , Smell and feel the world , It's called Discriminative, He can also say , draw , Think of something new , This is it. Generative.
other
Some knowledge points
precision/recall
This is the indicator for the second classification .
Positive and Negative It is the positive and negative category of prediction results
TRUE FALSE Is the prediction result right or wrong
So we have that confusion matrix 
precision That is, the proportion of the number of correctly predicted pictures to the total number of positive category predictions
p r e c i s i o n = T P T P + F P precision=\frac{TP}{TP+FP} precision=TP+FPTP
recall The number of positive category pictures predicted as positive category pictures in all labeled positive category pictures is determined ( From a dimensioning point of view , How many were recalled )
r e c a l l = T P T P + F N recall=\frac{TP}{TP+FN} recall=TP+FNTP
batch size
The smallest unit for calculating the gradient
If it is too large, the system memory can not bear
If the gradient is too small, the randomness is strong , Easy to disturb
边栏推荐
- 字节北京23k和拼多多上海28K,我该怎么选?
- 关于CS-3120舵机使用过程中感觉反应慢的问题
- Threejs: how to get the boundingbox of geometry?
- [Li mu] how to read papers [intensive reading of papers]
- LeetCode 1010 Pairs of Songs With Total Durations Divisible by 60 (hash)
- [path planning] week 1: Path Planning open source code summary (ROS) version
- I was so excited about the college entrance examination in 2022
- [recommended by Zhihu knowledge master] castle in UAV - focusing on the application of UAV in different technical fields
- 【云原生 | Kubernetes篇】Ingress案例实战
- 卡尔曼滤波(KF)、拓展卡尔曼滤波(EKF)推导
猜你喜欢

Px4 installation tutorial (VI) vertical fixed wing (tilting)

从解读 BDC 自动生成的代码谈起,讲解 SAPGUI 的程序组成部分试读版

Using MySQL database in nodejs
对象存储 S3 在分布式文件系统中的应用

关于概率统计中的排列组合
![[ongoing update...] 2021 National Electronic Design Competition for college students (III) interpretation of the anonymous four axis space developer flight control system design](/img/63/3193186820215b9babc3d00e1ef20b.jpg)
[ongoing update...] 2021 National Electronic Design Competition for college students (III) interpretation of the anonymous four axis space developer flight control system design

Conda安装Pytorch后numpy出现问题
![[leetcode] delete duplicate Element II in the sorting linked list](/img/24/0f8e4a2d15732997c8eb8973669bf7.jpg)
[leetcode] delete duplicate Element II in the sorting linked list

threejs:流光效果封装

2.2. Ros+px4 simulation multi-point cruise flight - Square
随机推荐
Linux安装mysql数据库详解
小包子关于分红的思考
2021-02-03美赛前MATLAB的学习笔记(灰色预测、线性规划)
QGC ground station tutorial
晚餐阿帮的手艺
[Li mu] how to read papers [intensive reading of papers]
SAS principal component analysis (finding correlation matrix, eigenvalue, unit eigenvector, principal component expression, contribution rate and cumulative contribution rate, and data interpretation)
CSRF attack
2.2、ROS+PX4仿真多点巡航飞行----正方形
Px4 installation tutorial (VI) vertical fixed wing (tilting)
“看似抢票实际抢钱”,别被花式抢票产品一再忽悠
Leetcode 1116 print zero even odd (concurrent multithreading countdownlatch lock condition)
Project_ Visual analysis of epidemic data based on Web Crawler
Leetcode 665 non decreasing array (greedy)
SAS discriminant analysis (Bayes criterion and proc discrim process)
PX4从放弃到精通(二十四):自定义机型
1.3 introduction to ROS UAV
2021-2-14 gephi学习笔记
Bad RequestThis combination of host and port requires TLS.
[leetcode] merge K ascending linked lists