当前位置:网站首页>Hands on deep learning (41) -- Deep recurrent neural network (deep RNN)
Hands on deep learning (41) -- Deep recurrent neural network (deep RNN)
2022-07-04 09:41:00 【Stay a little star】
List of articles
This section is very simple , Is in the RNN The concept of layer is added on the basis of , After all, what we discussed before RNN、GRU and LSTM We all discuss it on the basis of single-layer neural network
One 、 Deep loop neural network
up to now , We only discuss recurrent neural networks with a one-way hidden layer . among , The interaction between implicit variables and observations and specific functional forms is quite arbitrary . As long as we can model different interaction types with enough flexibility , This is not a big problem . However , For a single layer , This can be quite challenging . In the case of linear models , We solve this problem by adding more layers . And in a recurrent neural network , Because we first need to decide how and where to add additional nonlinearity , So this problem is a little tricky .
in fact , We can stack multilayer recurrent neural networks together , Through the combination of several simple layers , A flexible mechanism . especially , The data may be related to the stacking of different layers . for example , We may want to maintain the relevant financial market conditions ( Bear market or bull market ) High level data available for , At the bottom, only short-term time dynamics are recorded .
The following is a list with L L L A deep recurrent neural network with hidden layers , Each hidden state is continuously transferred to the next time step of the current layer and the current time step of the next layer .( The interesting thing is that you will be the former RNN The picture is compared with it , You can find H 1 ( 1 ) 、 H 2 ( 1 ) H^{(1)}_1、H^{(1)}_2 H1(1)、H2(1) They are the corresponding outputs before , Now it just becomes the input of the next layer of neurons )

Two 、 Functional dependencies
We can formalize the functional dependencies in the deep architecture , This structure is made up of L L L A hidden layer . Let's say we're in the time step t t t There is a small batch of input data X t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d( Sample size : n n n, Number of inputs in each sample : d d d). meanwhile , take l t h l^\mathrm{th} lth Hidden layer ( l = 1 , … , L l=1,\ldots,L l=1,…,L) The hidden state of is set to H t ( l ) ∈ R n × h \mathbf{H}_t^{(l)} \in \mathbb{R}^{n \times h} Ht(l)∈Rn×h( Number of hidden units : h h h), The output layer variable is set to O t ∈ R n × q \mathbf{O}_t \in \mathbb{R}^{n \times q} Ot∈Rn×q( Output number : q q q). Set up H t ( 0 ) = X t \mathbf{H}_t^{(0)} = \mathbf{X}_t Ht(0)=Xt, The first l l l The hidden state of a hidden layer uses the activation function ϕ l \phi_l ϕl The expression of is as follows :
H t ( l ) = ϕ l ( H t ( l − 1 ) W x h ( l ) + H t − 1 ( l ) W h h ( l ) + b h ( l ) ) , \mathbf{H}_t^{(l)} = \phi_l(\mathbf{H}_t^{(l-1)} \mathbf{W}_{xh}^{(l)} + \mathbf{H}_{t-1}^{(l)} \mathbf{W}_{hh}^{(l)} + \mathbf{b}_h^{(l)}), Ht(l)=ϕl(Ht(l−1)Wxh(l)+Ht−1(l)Whh(l)+bh(l)),
among , The weight W x h ( l ) ∈ R h × h \mathbf{W}_{xh}^{(l)} \in \mathbb{R}^{h \times h} Wxh(l)∈Rh×h and W h h ( l ) ∈ R h × h \mathbf{W}_{hh}^{(l)} \in \mathbb{R}^{h \times h} Whh(l)∈Rh×h And offset b h ( l ) ∈ R 1 × h \mathbf{b}_h^{(l)} \in \mathbb{R}^{1 \times h} bh(l)∈R1×h Is the first l l l Model parameters for multiple hidden layers . Last , The calculation of the output layer is only based on l l l The final hidden state of the hidden layer :
O t = H t ( L ) W h q + b q , \mathbf{O}_t = \mathbf{H}_t^{(L)} \mathbf{W}_{hq} + \mathbf{b}_q, Ot=Ht(L)Whq+bq,
among , The weight W h q ∈ R h × q \mathbf{W}_{hq} \in \mathbb{R}^{h \times q} Whq∈Rh×q And offset b q ∈ R 1 × q \mathbf{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q Are the model parameters of the output layer .
Like multi-layer perceptron , Number of hidden layers L L L And the number of hidden cells h h h It's all super parameters . in other words , They can be adjusted or specified by us . in addition , Use the hidden state of gated cycle unit or long-term and short-term memory network to replace depth RNN Calculate the hidden state in , Deep gated recurrent neural networks can be easily obtained ( Mu Shen said in the course to use LSTM and GRU It depends on my hobbies , There is no essential difference , Of course, there are more NB Of transformer Can be applied ), After all Attention is all you need Not for fun .
3、 ... and 、 Introduction and Implementation
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
Downloading ../data/timemachine.txt from http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt...
3.1 Network construction
# Hyperparametric architecture decision and single layer lstm In the same way , You need to select the same number of inputs and outputs , Hidden cells are set to 256, Just one more hidden layer
vocab_size,num_hiddens,num_layers = len(vocab),256,2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layers = nn.LSTM(num_inputs,num_hiddens,num_layers)
model = d2l.RNNModel(lstm_layers,len(vocab))
model = model.to(device)
3.2 Training and Forecasting
num_epochs,lr=500,2
d2l.train_ch8(model,train_iter,vocab,lr,num_epochs,device)
perplexity 1.0, 161938.1 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
traveller with a slight accession ofcheerfulness really thi
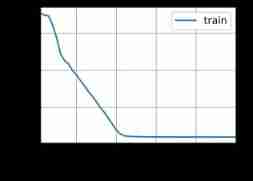
Four 、 summary
- In deep recurrent neural networks , The information of the hidden state is transferred to the next time step of the current layer and the current time step of the next layer
- There are many different styles of deep loop neural networks , Such as LSTM、GRU Or classic RNN The Internet . These models are advanced in the deep learning framework API cover
- In general, two words , depth RNN It takes a lot of work ( Learning rate adjustment 、 trim ) To ensure proper convergence , The initialization of the model also needs to be very careful
- The two-tier model above is 200 individual epoch It basically converges when , The previous single-layer model is almost 300 individual epoch Will converge when . Multilayer adds nonlinearity , It accelerates convergence but also increases the risk of over fitting . It is not usually used in particularly deep RNN The Internet
边栏推荐
- Latex download installation record
- Development trend and market demand analysis report of high purity tin chloride in the world and China Ⓔ 2022 ~ 2027
- Solution to null JSON after serialization in golang
- SSM online examination system source code, database using mysql, online examination system, fully functional, randomly generated question bank, supporting a variety of question types, students, teache
- Leetcode (Sword finger offer) - 35 Replication of complex linked list
- Write a jison parser from scratch (3/10): a good beginning is half the success -- "politics" (Aristotle)
- Explanation of for loop in golang
- Reload CUDA and cudnn (for tensorflow and pytorch) [personal sorting summary]
- Golang defer
- Markdown syntax
猜你喜欢

2022-2028 global small batch batch batch furnace industry research and trend analysis report
2022-2028 global special starch industry research and trend analysis report
After unplugging the network cable, does the original TCP connection still exist?
165 webmaster online toolbox website source code / hare online tool system v2.2.7 Chinese version

How to batch change file extensions in win10
Log cannot be recorded after log4net is deployed to the server
The child container margin top acts on the parent container
2022-2028 global tensile strain sensor industry research and trend analysis report

JDBC and MySQL database
PHP is used to add, modify and delete movie information, which is divided into foreground management and background management. Foreground users can browse information and post messages, and backgroun
随机推荐
MySQL transaction mvcc principle
Flutter tips: various fancy nesting of listview and pageview
Matlab tips (25) competitive neural network and SOM neural network
直方图均衡化
Global and Chinese market of sampler 2022-2028: Research Report on technology, participants, trends, market size and share
libmysqlclient. so. 20: cannot open shared object file: No such file or directory
Sort out the power node, Mr. Wang he's SSM integration steps
Report on the development trend and prospect trend of high purity zinc antimonide market in the world and China Ⓕ 2022 ~ 2027
Les différents modèles imbriqués de listview et Pageview avec les conseils de flutter
C语言指针面试题——第二弹
Global and Chinese markets of thrombography hemostasis analyzer (TEG) 2022-2028: Research Report on technology, participants, trends, market size and share
How web pages interact with applets
Reading notes of how the network is connected - understanding the basic concepts of the network (I)
You can see the employment prospects of PMP project management
Write a jison parser from scratch (6/10): parse, not define syntax
Global and Chinese market of planar waveguide optical splitter 2022-2028: Research Report on technology, participants, trends, market size and share
Tkinter Huarong Road 4x4 tutorial II
How to display √ 2 on the command line terminal ̅? This is actually a blog's Unicode test article
2022-2028 global elastic strain sensor industry research and trend analysis report
Leetcode (Sword finger offer) - 35 Replication of complex linked list